Datasets about 3D Reconstruction
3D 打印模型
Thingiverse - Digital Designs for Physical Objects
Custom Datasets
COLMAP + Blender(neuralangelo)
DTU
DTU Robot Image Data Sets | Data for Evaluating Computer Vision Methods etc.
- NeuS提供neus - Dropbox

1600x1200
在黑盒空间中,使用 6 轴工业机器人手部的结构光相机,structured light scanner 可以捕获所观察场景/对象的参考 3D 表面几何形状


我们的机器人的定位精度难以控制,但重复性非常高,随机性很小。这意味着多次运行相同的定位脚本,每次定位几乎都是相同的。为了解决这个定位问题,我们不直接使用(或报告)发送给机器人的相机位置,而是确定并报告我们获取的相对相机位置。这是通过 MatLab 的相机校准工具箱完成的。
BlenderMVS
YoYo000/BlendedMVS: BlendedMVS: A Large-scale Dataset for Generalized Multi-view Stereo Networks (github.com)
BlendedMVS: A Large-scale Dataset for Generalized Multi-view Stereo Networks (readpaper.com)
H ×W = 1536 × 2048

应用 3D 重建管道从精心选择的场景图像中恢复高质量的纹理网格。然后,我们将这些网格模型渲染为彩色图像和深度图。为了在训练期间引入环境照明信息,将渲染的彩色图像与输入图像进一步混合以生成训练输入
- Altizure 平台进行纹理网格重建,该软件将执行完整的 3D 重建管道并返回纹理网格和相机姿势作为最终输出
- 然后将网格模型渲染到每个相机视图点以生成渲染图像和渲染的深度图,渲染的深度图将用作 GT 深度图
- 由于渲染图像不包含与视图相关的照明,使用高通滤波器用于从渲染图像中提取图像视觉线索,而低通滤波器用于从输入中提取环境照明。最后线性混合生成混合图,混合图用作 GT 监督
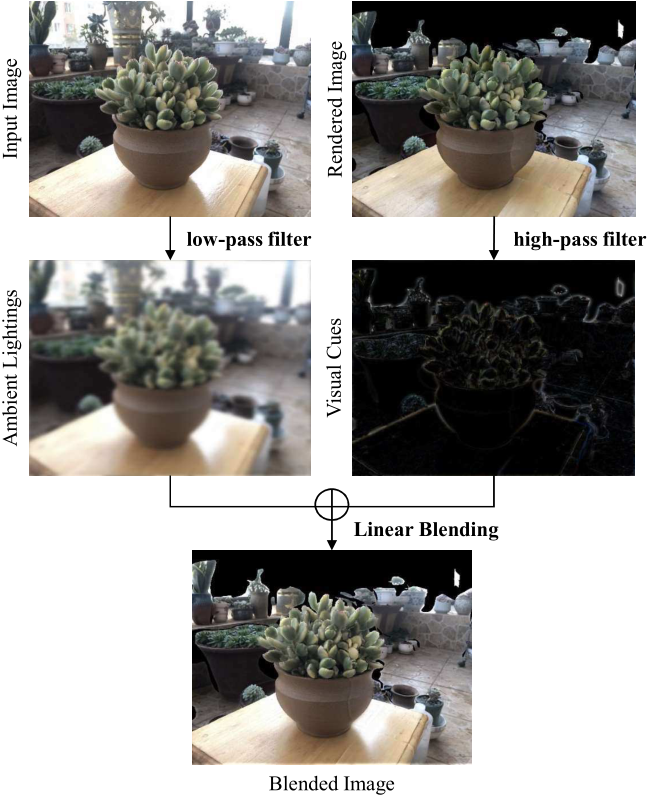
混合图像与输入图像具有相似的背景照明,同时继承了渲染图像的纹理细节。
与 DTU 数据集[2]不同的是,所有场景都由固定的机械臂捕获,BlendedMVS 中的场景包含各种不同的摄像机轨迹。非结构化摄像机轨迹可以更好地模拟不同的图像捕获风格,并能够使网络更一般化到真实世界的重建

Tanks and Temples
- 工业激光扫描仪(industrial laser scanner.)捕获的模型
- 高分辨率视频序列
ShapeSplat
ShapeSplat: A Large-scale Dataset of Gaussian Splats and Their Self-Supervised Pretraining
一个基于大型3D CAD模型渲染,经过光栅化,高斯裁剪的大型高斯物体数据集ShapeSplat。

Human Body
| Name | Link |
|---|---|
| 2K2K | ketiVision/2K2K (github.com) |
| ZJU-Mocap | neuralbody/INSTALL.md at master · zju3dv/neuralbody (github.com) |
| _People-Snapshot_ | People-Snapshot |
| THUman | THUmanDataset |
| THuman2.0 | ytrock/THuman2.0-Dataset (github.com) |
| THuman3.0 | fwbx529/THuman3.0-Dataset (github.com) |
| THUman4.0 | ZhengZerong/THUman4.0-Dataset (github.com) |
| THUman 来源 | Yebin Liu (刘烨斌) (liuyebin.com) |
| renderpeople | https://renderpeople.com/ |
| MVPHuman | MVP-Human |
| HuMMan | caizhongang/humman_toolbox: Toolbox for HuMMan Dataset (github.com) |
| CLOTH4D | AemikaChow/CLOTH4D (github.com) |
| DNA-Rendering | DNA-Rendering : A Diverse Neural Actor Repository for High-Fidelity Human-centric Rendering |
UltraStage:多视角和多光照条件下捕获的高质量的人体资源
SMPL、SMPL-X (mpg.de)
MVImgNet
A Large-scale Dataset of Multi-view Images

Objaverse-XL
Objaverse-XL is an open dataset of over 10 million 3D objects!
Objaverse-XL 由来自多个来源的 3D 对象组成,包括 GitHub、Thingiverse、Sketchfab、Polycam 和 Smithsonian Institution。

G-buffer Objaverse
在 Objaverse 上使用 A10 的 TIDE 渲染器渲染了大约 2000 GPU 小时,产生了 30,000,000 张反照率、RGB、深度和法线贴图的图像。我们提出了一种用于高质量和高速数据集渲染的渲染框架。
ABC Dataset
A Big CAD Model Dataset
News | ABC Dataset (deep-geometry.github.io)
一百万个计算机辅助设计 (CAD) 模型的集合,用于研究几何深度学习方法和应用。每个模型都是显式参数化曲线和曲面的集合,为微分量、面片分割、几何特征检测和形状重建提供基本事实。对曲面和曲线的参数化描述进行采样可以生成不同格式和分辨率的数据,从而能够对各种几何学习算法进行公平比较
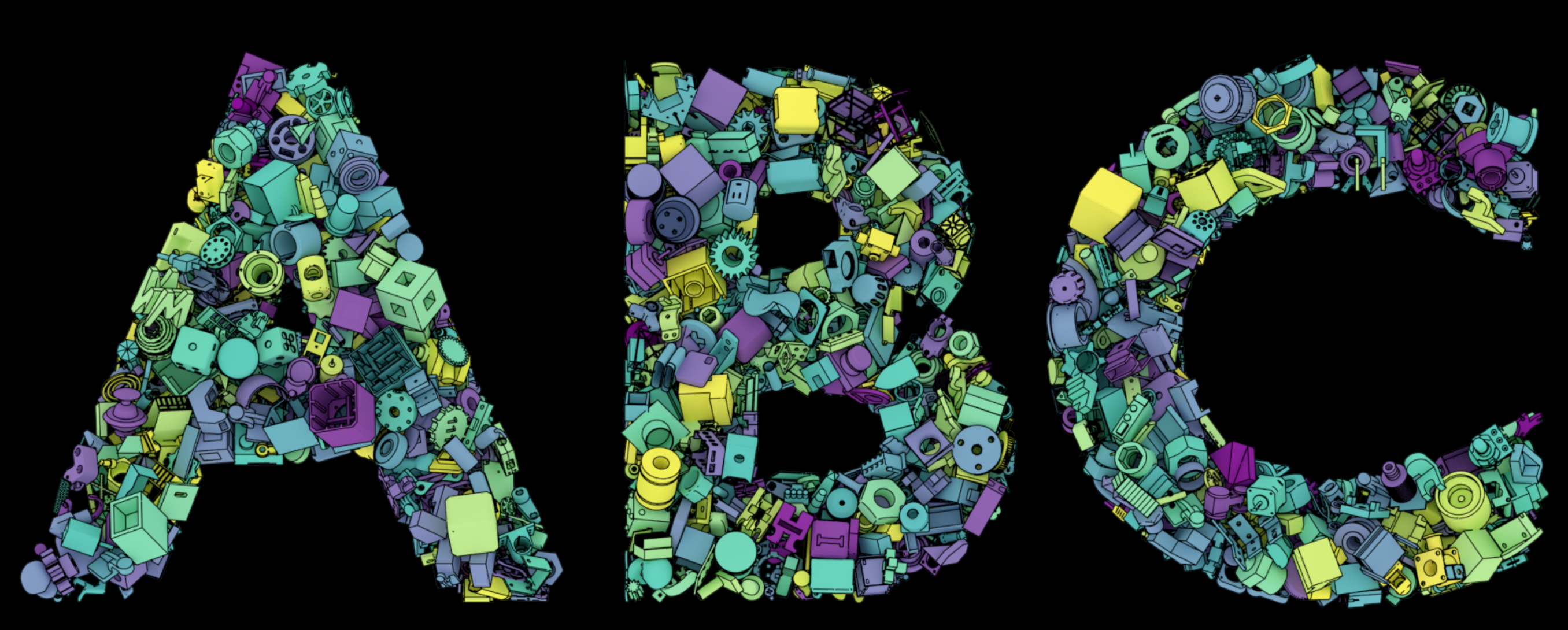
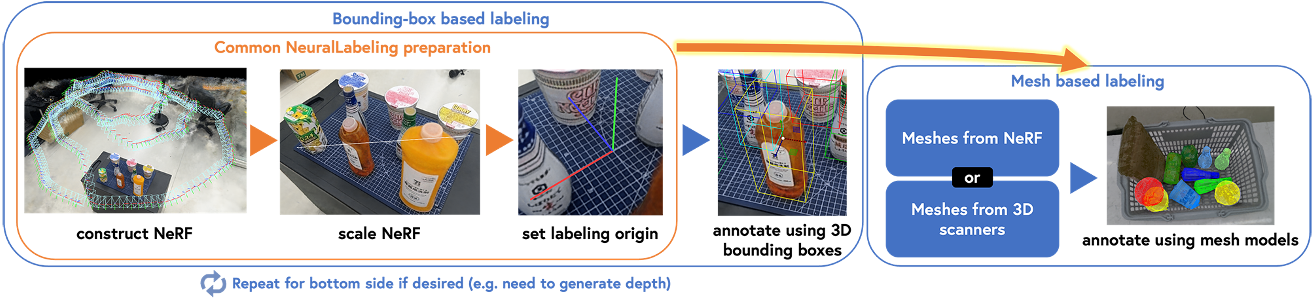
NeuralLabeling 工具箱
NeuralLabeling: A versatile toolset for labeling vision datasets using Neural Radiance Fields > NeuralLabeling: A versatile toolset for labeling vision datasets using Neural Radiance Fields (florise.github.io)
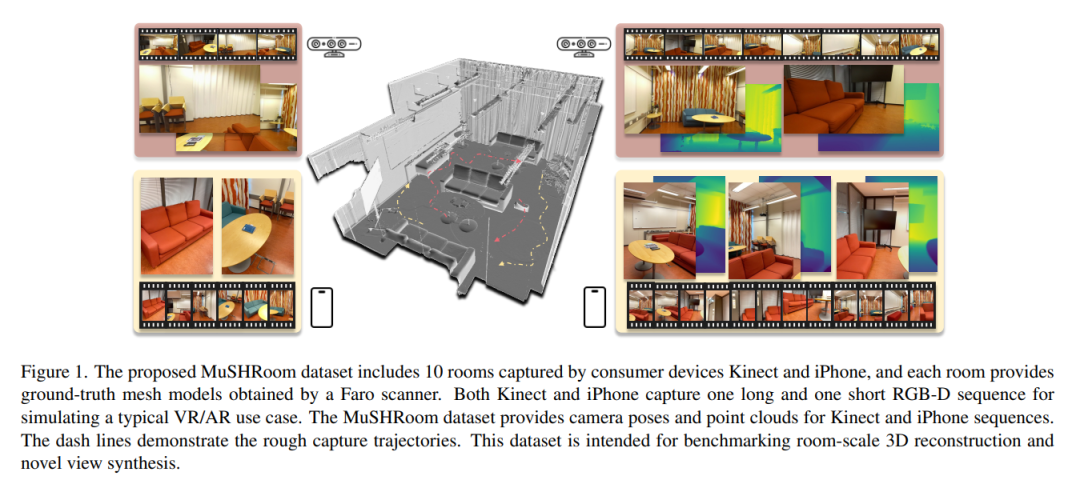
MuSHRoom
MuSHRoom: Multi-Sensor Hybrid Room Dataset for Joint 3D Reconstruction and Novel View Synthesis
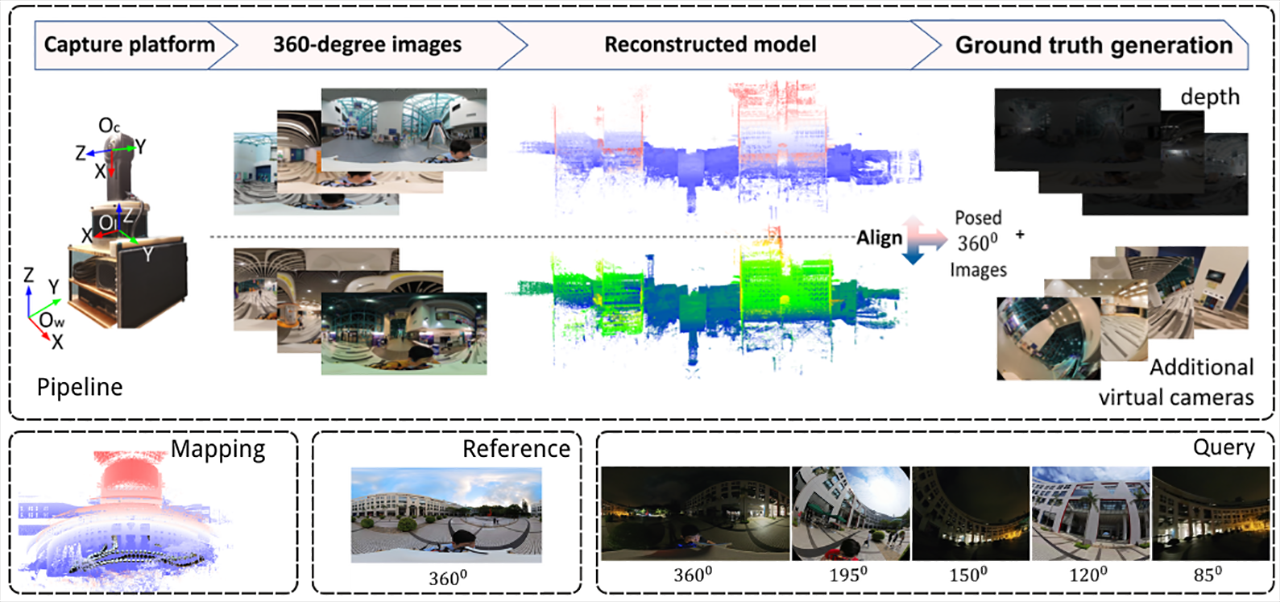
360Loc
室外大场景
Stable SFM
OpenMaterial
OpenMaterial: A Comprehensive Dataset of Complex Materials for 3D Reconstruction
用于全面分析NeRF和3DGS在challenging material条件下的重建和新视角合成任务表现。拥有1001个unique shape,295种material type,723个不同的lighting condition。含有丰富的reflection,refraction,和transmission的 scenario。
DL3DV-10K
DL3DV-10K/Dataset: News: the 10k dataset is ready for download.
现有的基于深度学习的 3D 视觉场景级数据集,要么限于合成环境,要么仅限于少量真实场景的选择,相当不足。为了解决这一关键差距,我们提出了 DL3DV-10K,这是一个大规模场景数据集,包含从 65 种兴趣点(POI)位置捕获的 10,510 个视频中的 5,120 万帧,涵盖了有界和无界场景,以及不同级别的反射、透明度和光照。
