| Title | MVSNet: Depth Inference for Unstructured Multi-view Stereo |
|---|---|
| Author | Yao, Yao and Luo, Zixin and Li, Shiwei and Fang, Tian and Quan, Long |
| Conf/Jour | ECCV |
| Year | 2018 |
| Project | YoYo000/MVSNet: MVSNet (ECCV2018) & R-MVSNet (CVPR2019) (github.com) |
| Paper | MVSNet: Depth Inference for Unstructured Multi-view Stereo (readpaper.com) |
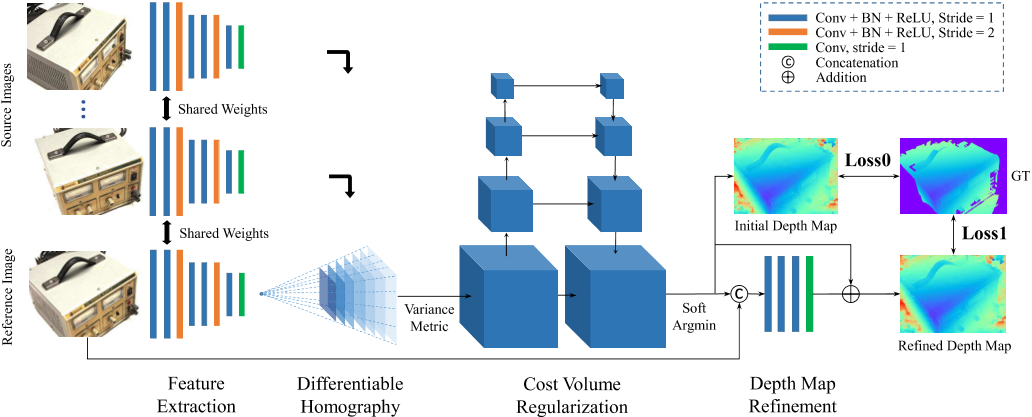
深度估计方法
Abstract
我们提出了一个端到端的深度学习架构,用于从多视图图像中推断深度图。在该网络中,我们首先提取深度视觉图像特征,然后通过可微单应性变形在参考摄像机截锥体上构建三维代价体。接下来,我们应用3D卷积对初始深度图进行正则化和回归,然后使用参考图像对其进行细化以生成最终输出。我们的框架灵活地适应任意n视图输入,使用基于方差的成本度量,将多个特征映射到一个成本特征。在大型室内DTU数据集上验证了所提出的MVSNet。通过简单的后处理,我们的方法不仅明显优于以前的最先进的技术,而且在运行时也快了好几倍。我们还在复杂的室外坦克和寺庙数据集上对MVSNet进行了评估,在2018年4月18日之前,我们的方法在没有任何微调的情况下排名第一,显示了MVSNet强大的泛化能力
Method
1 Image Features 通过CNN提取图片特征,共N张图片
2 Differentiable Homography 可微单应性deep features→feature volumes
第i个特征map与参考特征map在深度d之间的单应性$\mathrm{x}^{\prime}\sim\mathrm{H}_{i}(d)\cdot\mathbf{x},$
$\mathbf{H}_{i}(d)=\mathbf{K}_{i}\cdot\mathbf{R}_{i}\cdot\left(\mathbf{I}-\frac{(\mathbf{t}_{1}-\mathbf{t}_{i})\cdot\mathbf{n}_{1}^{T}}{d}\right)\cdot\mathbf{R}_{1}^{T}\cdot\mathbf{K}_{1}^{T}.$
General Homography正确的:$H=K_{i}(R_{i}R_{1}^{T}-\frac{(\mathbf{t}_{i}-R_{i}R_{1}^{T}\mathbf{t}_{1})\mathbf{n}_{1}^{T}}{d})K_{1}^{-1}.$
将其他图像的feature通过可微的单应变换,warp到参考图像相机前的这些平行平面上,构成一个3D的Feature Volume
将所有特征映射扭曲到参考相机的不同前平行平面,形成N个特征体$\{\mathbf{V}_i\}_{i=1}^N.$
3 Cost Metric 将多个特征体聚合为一个代价体feature volumes→Cost Volumes
$\mathbf{C}=\mathcal{M}(\mathbf{V}_1,\cdots,\mathbf{V}_N)=\frac{\sum\limits_{i=1}^N{(\mathbf{V}_i-\overline{\mathbf{V}_i})^2}}{N}$
4 Cost Volume Regularization cost volume经过一个四级的U-Net结构来生成一个probability volume
probability volume:每个深度下,每个像素的可能性大小
5 Depth Map
$\mathbf{D}=\sum_{d=d_{min}}^{d_{max}}d\times\mathbf{P}(d)$
Refinement:将深度图与原始图像串连成一个四通道的输入,经过神经网络得到深度残差,然后加到之前的深度图上从而得到最终的深度图
优化:$Loss=\sum_{p\in\mathbf{p}_{valid}}\underbrace{|d(p)-\hat{d}_i(p)|_1}_{Loss0}+\lambda\cdot\underbrace{|d(p)-\hat{d}_r(p)|_1}_{Loss1}$
Discussion
MVSNet的效率要高得多,重建一次扫描大约需要230秒(每个视图4.7秒)
MVSNet所需的GPU内存与输入图像大小和深度采样数有关。为了在原始图像分辨率和足够深度假设下对坦克和寺庙进行测试,我们选择Tesla P100显卡(16gb)来实现我们的方法。值得注意的是,DTU数据集上的训练和验证可以使用一个消费级GTX 1080ti显卡(11 GB)完成
局限:
1)提供的地面真值网格不是100%完整,因此前景后面的一些三角形会被错误地渲染到深度图中作为有效像素,这可能会影响训练过程。
2)如果一个像素在其他所有视图中都被遮挡,则不应用于训练。然而,如果没有完整的网格表面,我们就不能正确识别被遮挡的像素。我们希望未来的MVS数据集能够提供具有完整遮挡和背景信息的地真深度图。
Conclusion
我们提出了一个用于MVS重建的深度学习架构。提出的MVSNet将非结构化图像作为输入,并以端到端方式推断参考图像的深度图。MVSNet的核心贡献是将摄像机参数编码为可微单应词,在摄像机视台上构建代价体,架起了二维特征提取和三维代价正则化网络的桥梁。onDTU数据集证明,MVSNet不仅显著优于以前的方法,而且在速度上也提高了几倍。此外,MVSNet在没有任何微调的情况下,在坦克和庙宇数据集上产生了最先进的结果,这表明了它强大的泛化能力。