| Paper | Model | Input | Parameter/Pnum | GPU |
|---|---|---|---|---|
| DiT-3D | Diffusion Transformers | Voxelized PC | ||
| PointFlow | AE flow-based | PointCloud | 1.61M | |
| FlowGAN | GAN flow-based | Single Image | N = 2500 | A40 45GB |
| BuilDiff | Diffusion models | Single Image | 1024 to 4096 | A40 45GB |
| CCD-3DR | CDPM | Single Image | 8192 | 3090Ti 24GB |
| SG-GAN | SG-GAN | Single Image | ||
| HaP | Diffusion+SMPL+DepthEstimation | Single Image | 10000 | 4x3090Ti |
Review
- Explainability of Vision Transformers: A Comprehensive Review and New Perspectives 关于视觉中使用 Transformer 的 Review
Generative approach(Img2PC)
Network Framework
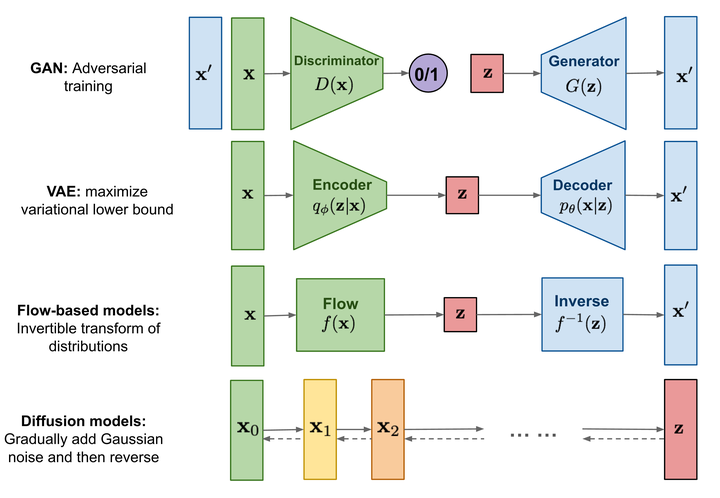
- GAN(generative adversarial networks) Wasserstein GAN (WGAN) 解决本质问题 | 莫烦Python
- VAE(variational auto-encoders)
- Auto-regressive models
- Normalized flows(flow-based models), PointFlow
- DiT(Diffusion Transformers), DiT-3D
Flow-based: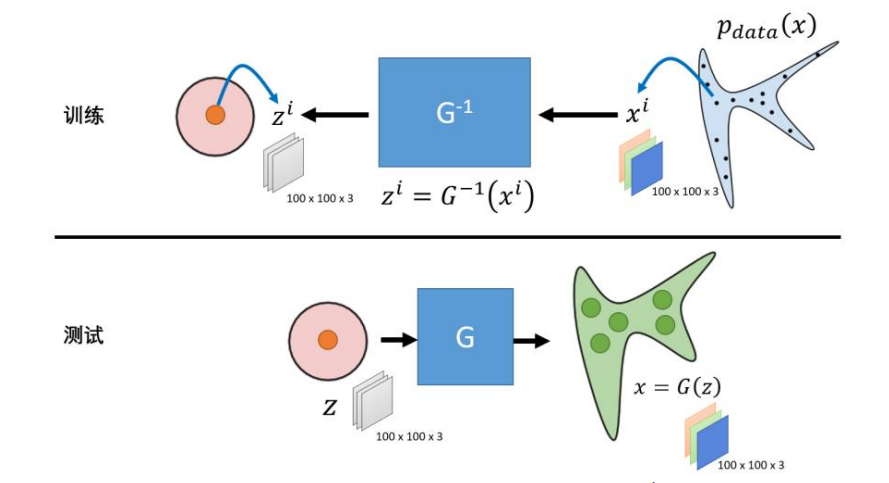

Loss
点云倒角距离 CD ↓
$\begin{aligned}\mathcal{L}_{CD}&=\sum_{y’\in Y’}min_{y\in Y}||y’-y||_2^2+\sum_{y\in Y}min_{y’\in Y’}||y-y’||_2^2,\end{aligned}$
推土距离 EMD (Earth Mover’s distance)↓
$\mathcal{L}_{EMD}=min_{\phi:Y\rightarrow Y^{\prime}}\sum_{x\in Y}||x-\phi(x)||_{2}$ , φ indicates a parameter of bijection.
Diffusion Models
DMV3D
DMV3D: Denoising Multi-View Diffusion Using 3D Large Reconstruction Mode (justimyhxu.github.io)
Diffusion Model + Triplane NeRF + Multi-view Image input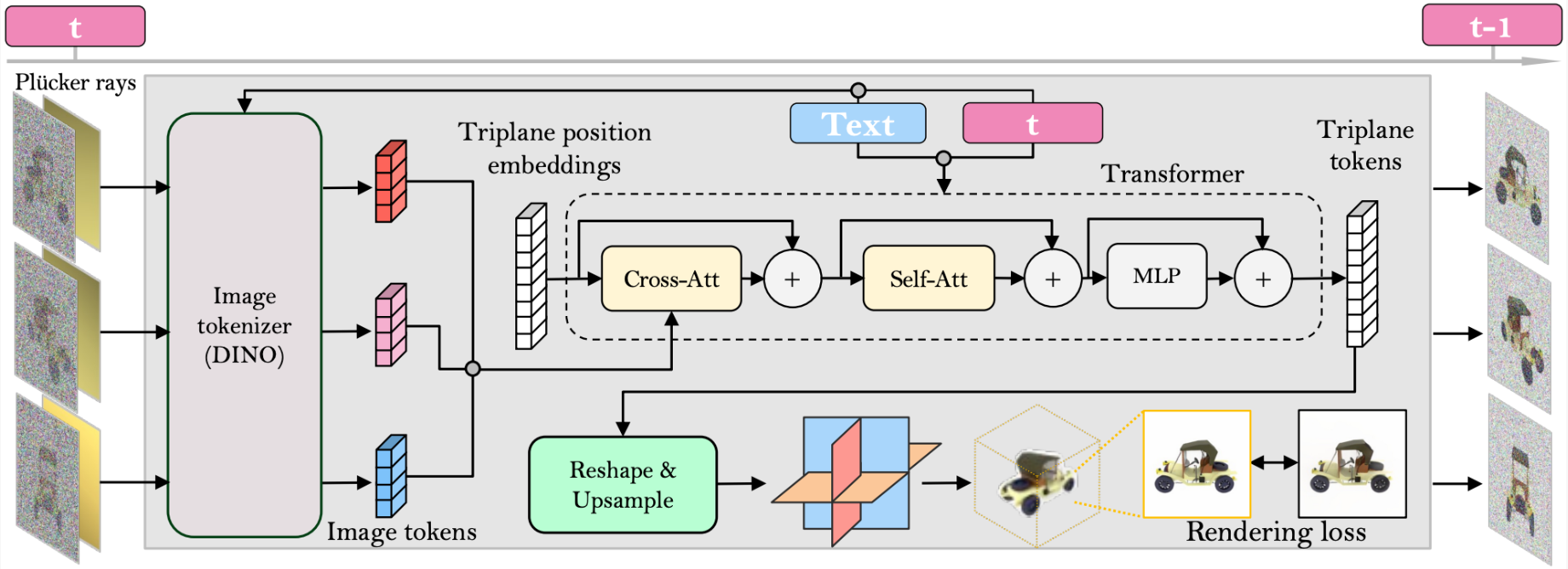
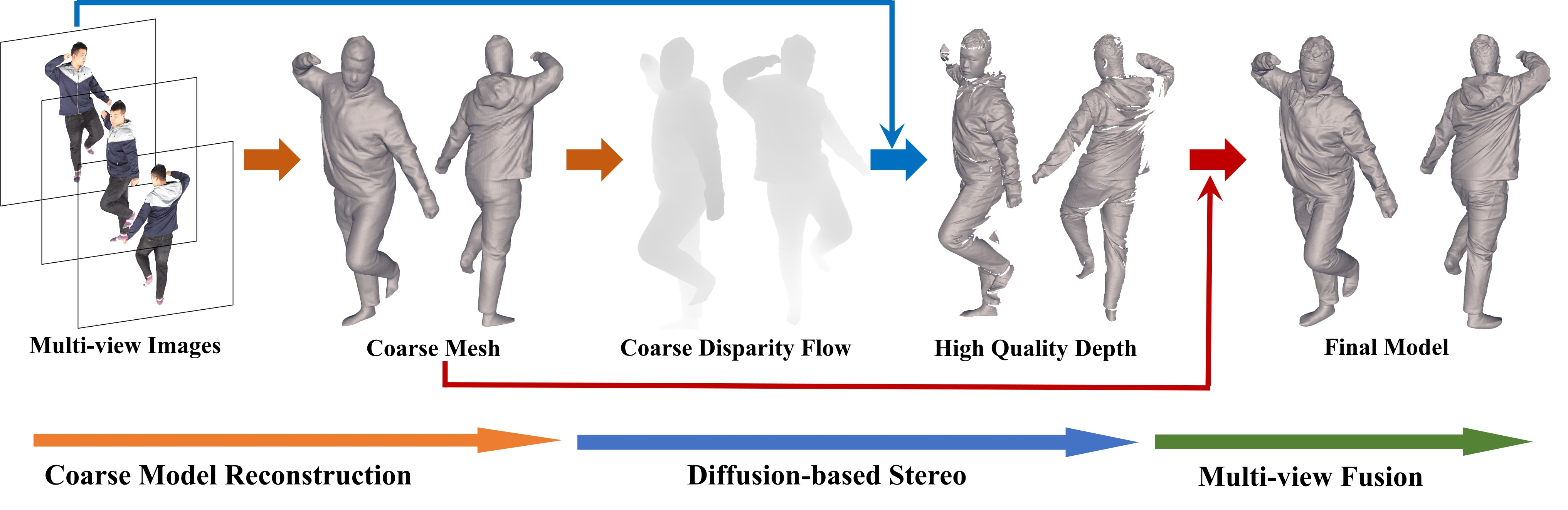
DiffuStereo
DiffuStereo Project Page (liuyebin.com)
多视图
DoubleField 粗网格估计 + Diffusion 生成高质量 Disparity Flow 和 Depth + ICP 配准(点云融合)
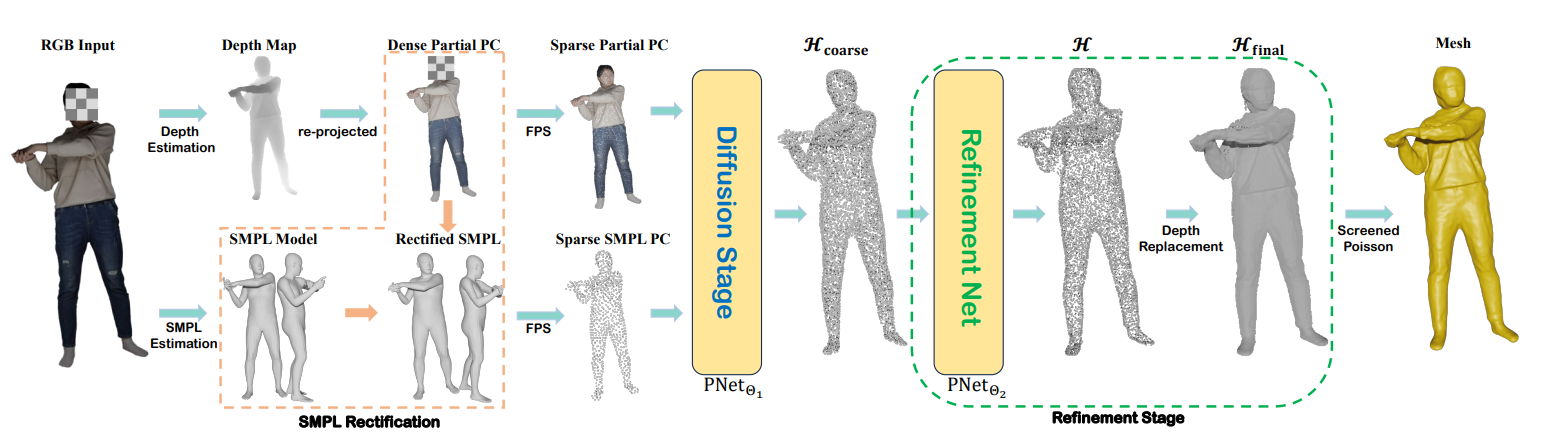
Human as Points(HaP)
yztang4/HaP (github.com)
Human as Points: Explicit Point-based 3D Human Reconstruction from Single-view RGB Images(arxiv.org)
Human as Points—— Explicit Point-based 3D Human Reconstruction from Single-view RGB Images.pdf (readpaper.com)
深度估计+SMPL 估计得到两个稀疏点云,输入进 Diffusion Model 进行精细化生成
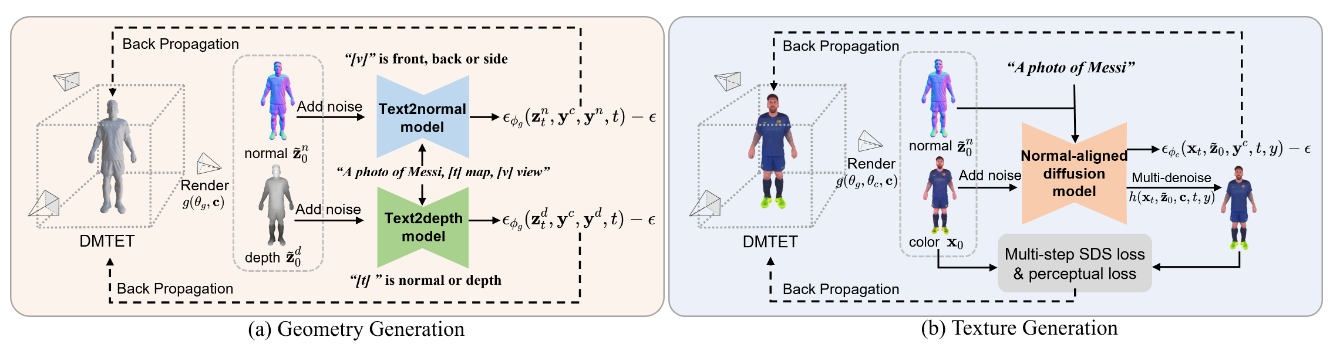
HumanNorm
BuilDiff
预计 2023.11 release
BuilDiff论文阅读笔记
weiyao1996/BuilDiff: BuilDiff: 3D Building Shape Generation using Single-Image Conditional Point Cloud Diffusion Models (github.com)
BuilDiff: 3D Building Shape Generation using Single-Image Conditional Point Cloud Diffusion Models (readpaper.com)
RODIN
RODIN Diffusion (microsoft.com)
Rodin: A Generative Model for Sculpting 3D Digital Avatars Using Diffusion (readpaper.com)
微软大数据集 + Diffusion + NeRF Tri-plane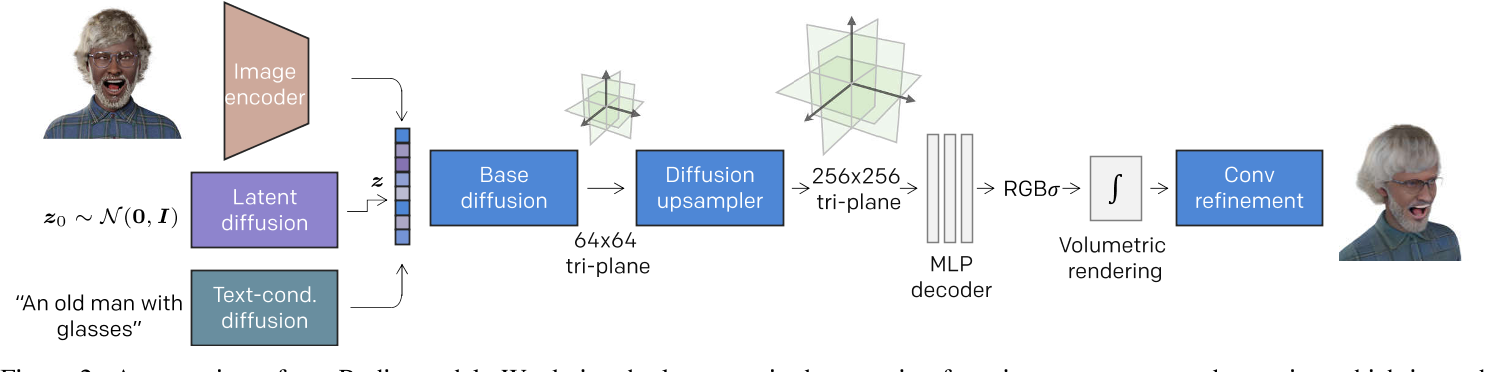
Single-Image 3D Human Digitization with Shape-Guided Diffusion
Single-Image 3D Human Digitization with Shape-Guided Diffusion
利用针对一般图像合成任务预先训练的高容量二维扩散模型作为穿着人类的外观先验
通过以轮廓和表面法线为条件的形状引导扩散来修复缺失区域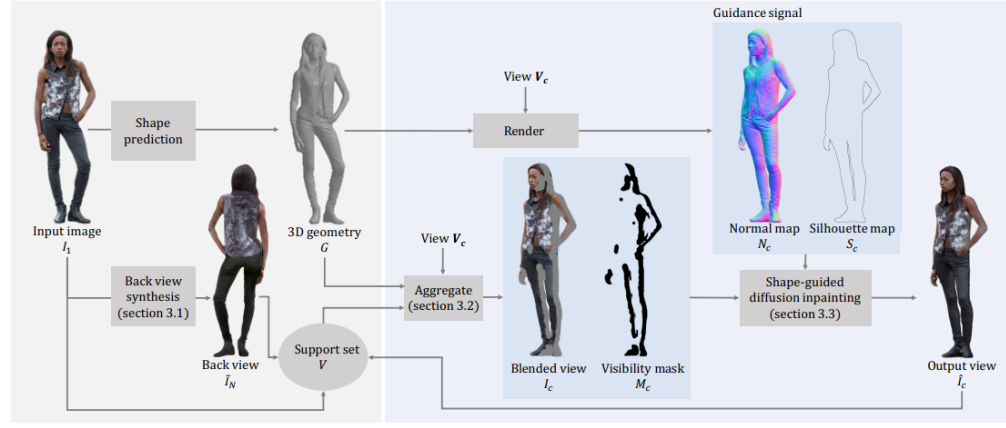
CCD-3DR
CCD-3DR: Consistent Conditioning in Diffusion for Single-Image 3D Reconstruction (readpaper.com)
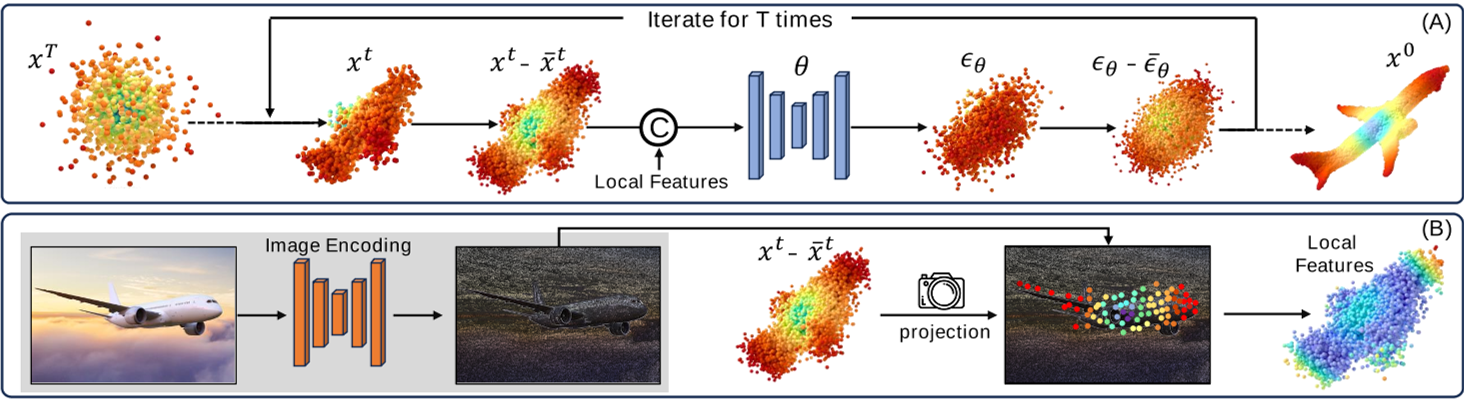
$PC^2$
PC2: Projection-Conditioned Point Cloud Diffusion for Single-Image 3D Reconstruction (lukemelas.github.io)
$PC^2$: Projection-Conditioned Point Cloud Diffusion for Single-Image 3D Reconstruction (readpaper.com)
相机位姿???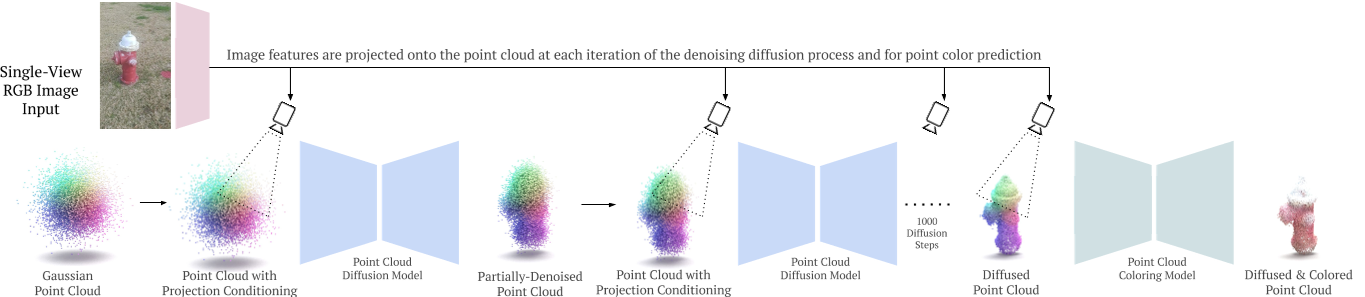
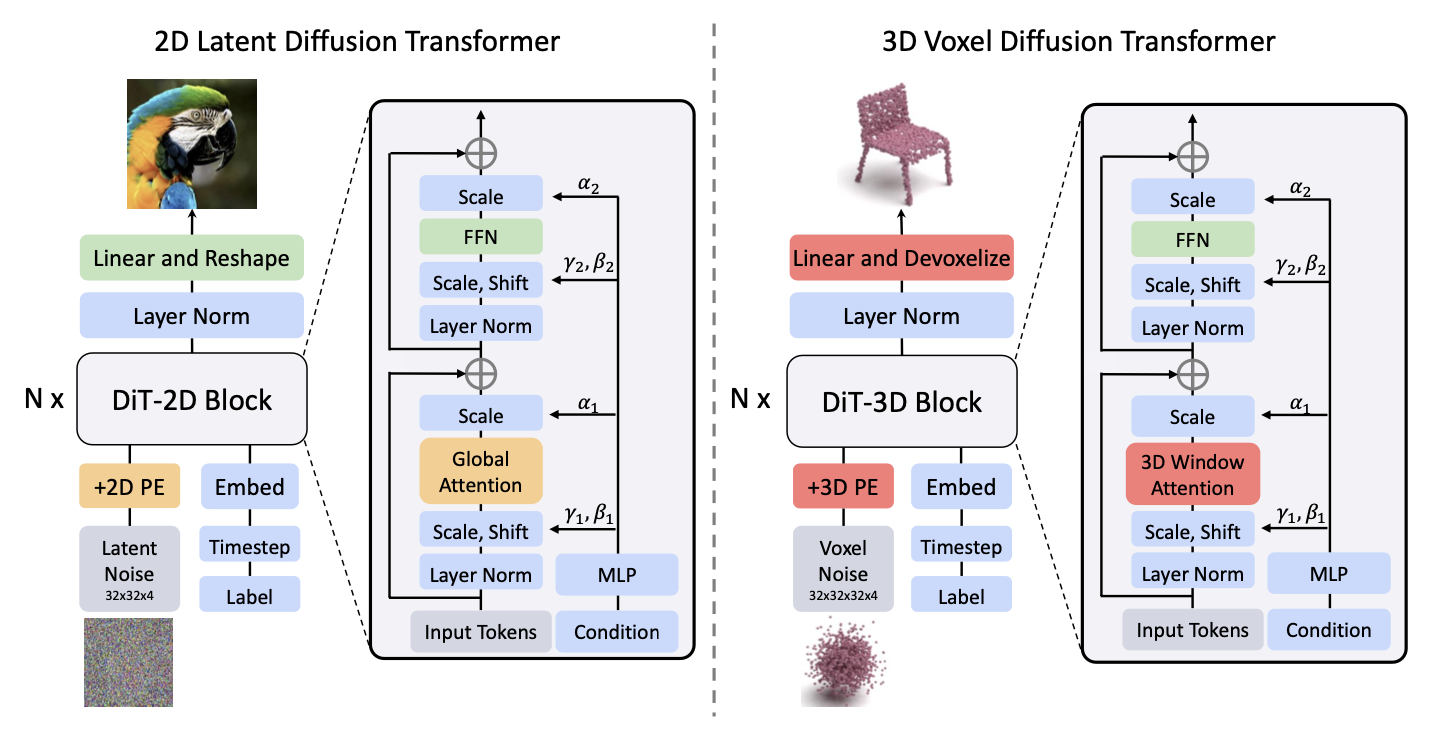
DiT-3D
DiT-3D论文阅读笔记
DiT-3D: Exploring Plain Diffusion Transformers for 3D Shape Generation
DiT-3D: Exploring Plain Diffusion Transformers for 3D Shape Generation (readpaper.com)
Make-It-3D
Make-It-3D: High-Fidelity 3D Creation from A Single Image with Diffusion Prior
DreamGaussian
Gaussian Splatting + Diffusion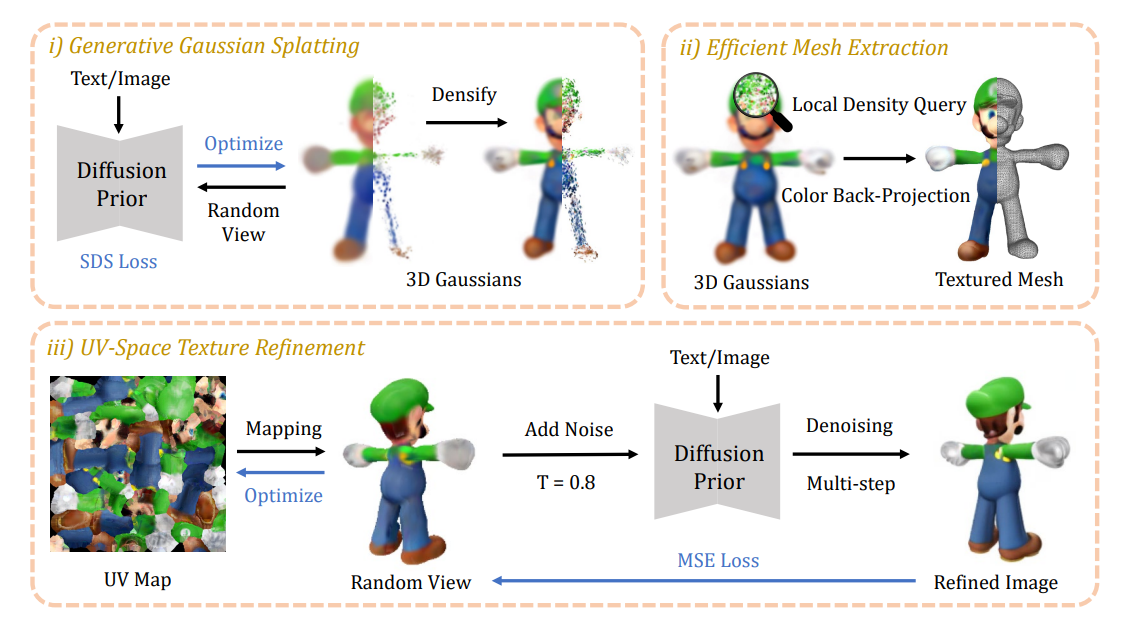
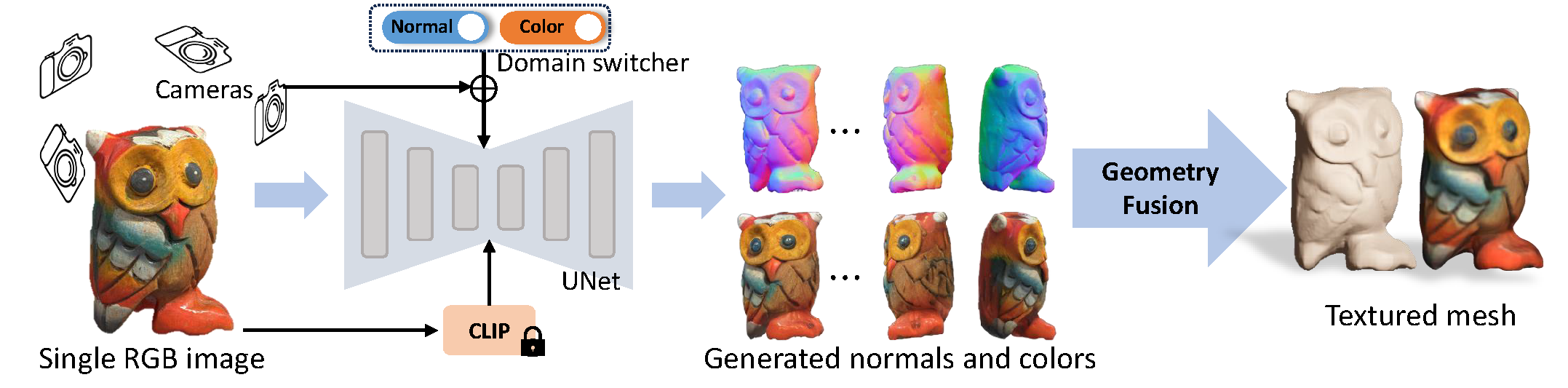
Wonder3D
Wonder3D: Single Image to 3D using Cross-Domain Diffusion (xxlong.site)
Diffusion 一致性出图 + Geometry Fusion (novel geometric-aware optimization scheme)
CLIP
对比语言-图片预训练模型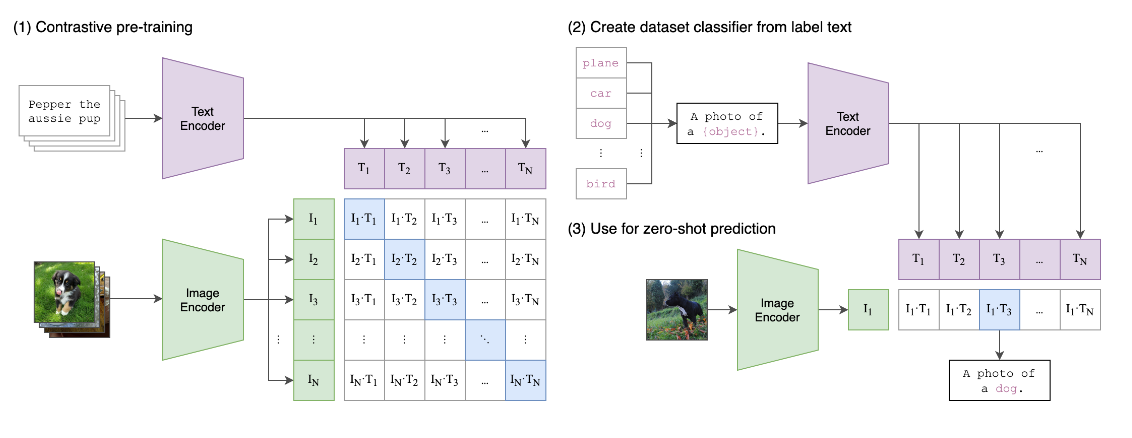
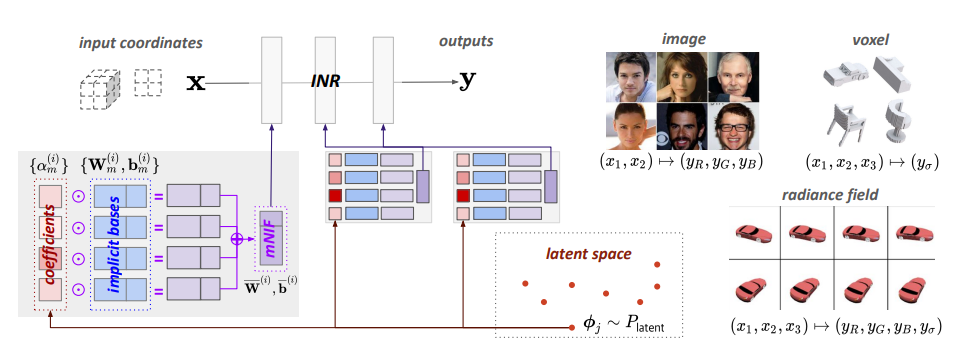
GenNeRF
Generative Neural Fields by Mixtures of Neural Implicit Functions (arxiv.org)
LDM3D-VR
LDM3D-VR: Latent Diffusion Model for 3D VR (arxiv.org)
视频演示T.LY URL Shortener
从给定的文本提示生成图像和深度图数据,此外开发了一个 DepthFusion 的应用程序,它使用生成的 RGB 图像和深度图来使用 TouchDesigner 创建身临其境的交互式 360°视图体验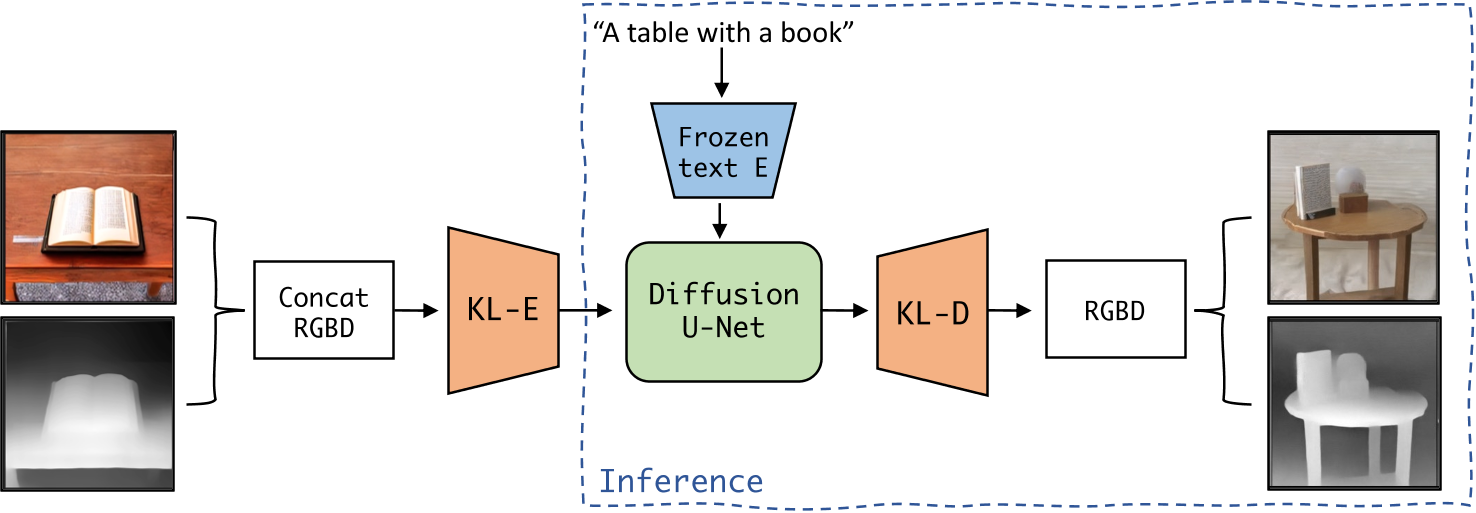
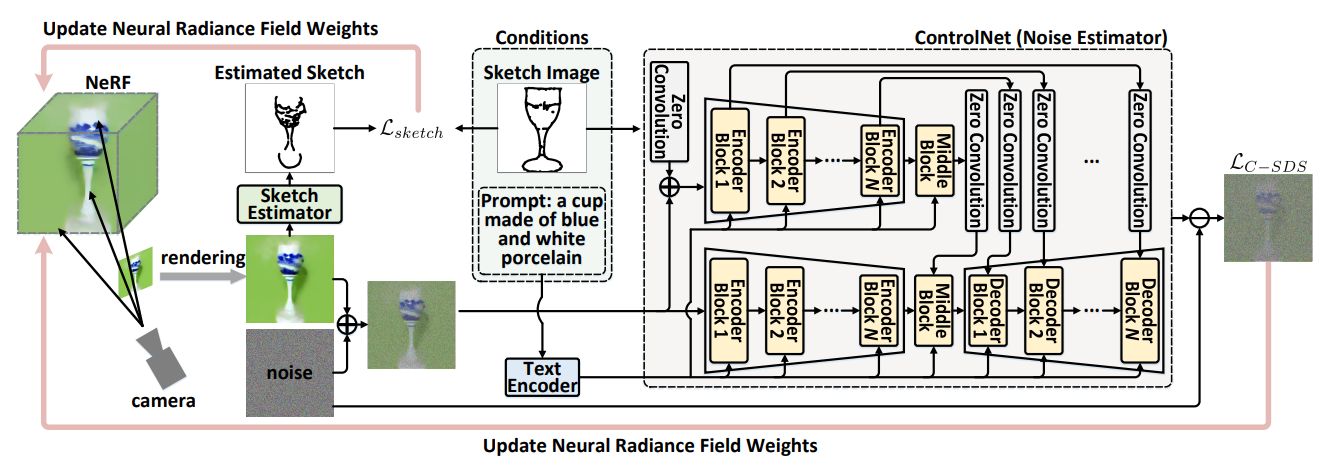
Control3D
Control3D: Towards Controllable Text-to-3D Generation
草图+文本条件生成 3D
Etc
Colored PC 3D Colored Shape Reconstruction from a Single RGB Image through Diffusion (readpaper.com)
GAN
3DHumanGAN
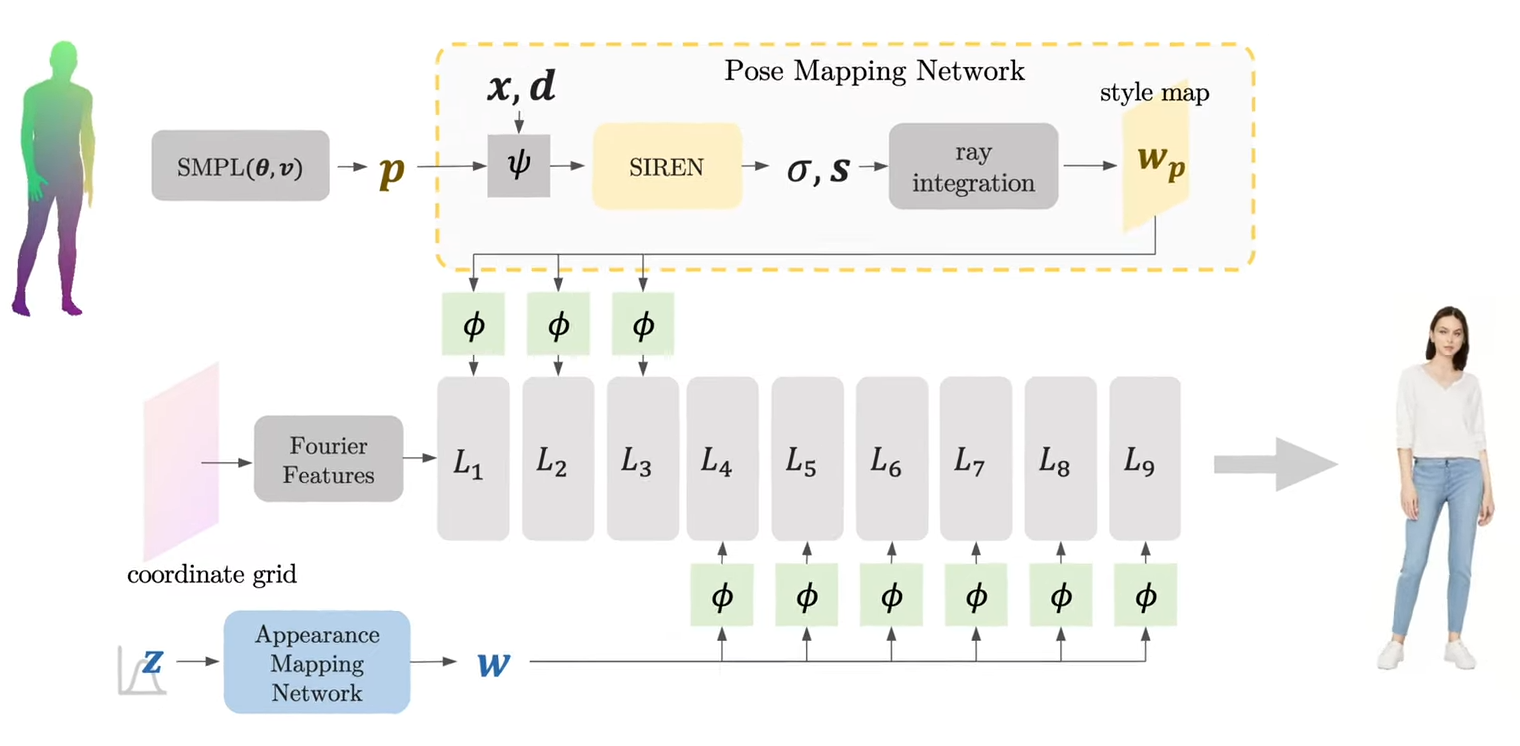
3DHumanGAN: 3D-Aware Human Image Generation with 3D Pose Mapping
多视图一致的人体照片生成
SE-MD
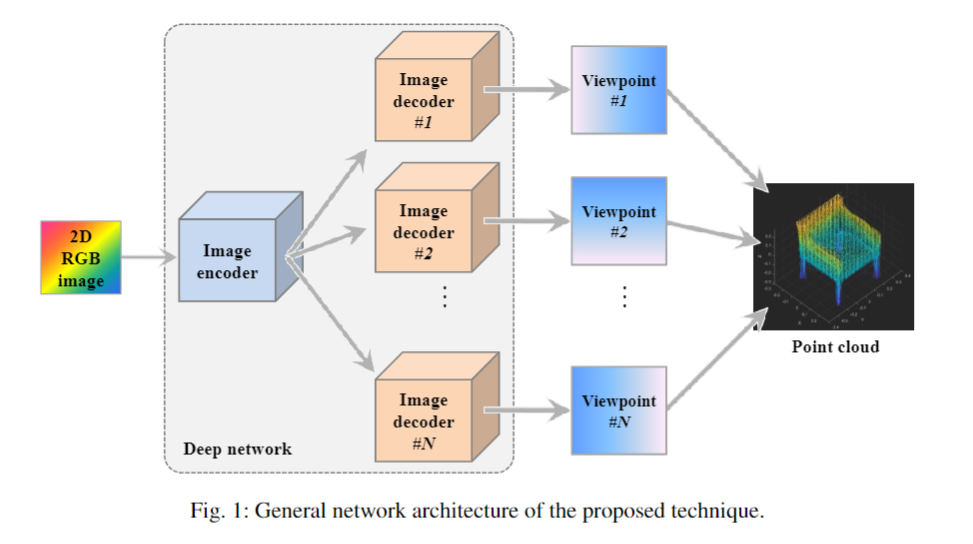
SE-MD: A Single-encoder multiple-decoder deep network for point cloud generation from 2D images. (readpaper.com)
单编码器—>多解码器
每个解码器生成某些固定视点,然后融合所有视点来生成密集的点云

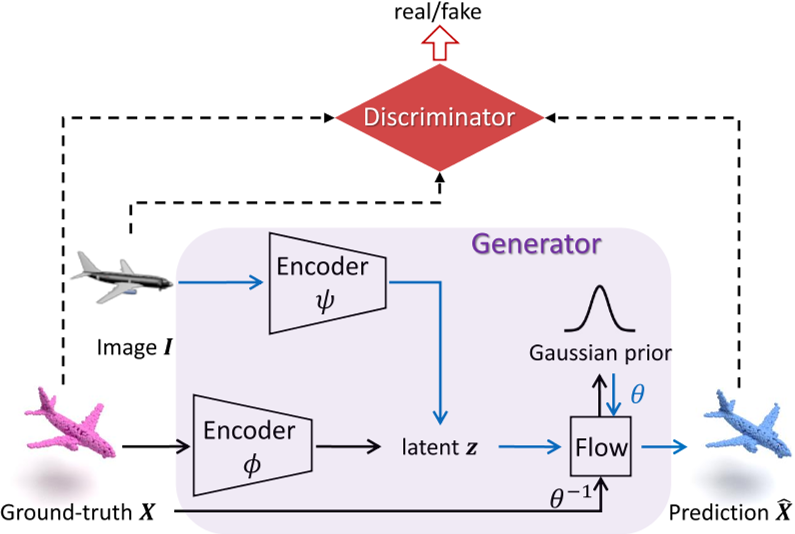
FlowGAN
FlowGAN论文阅读笔记
Flow-based GAN for 3D Point Cloud Generation from a Single Image (mpg.de)
Flow-based GAN for 3D Point Cloud Generation from a Single Image (readpaper.com)
SG-GAN
SG-GAN论文阅读笔记
SG-GAN: Fine Stereoscopic-Aware Generation for 3D Brain Point Cloud Up-sampling from a Single Image (readpaper.com)
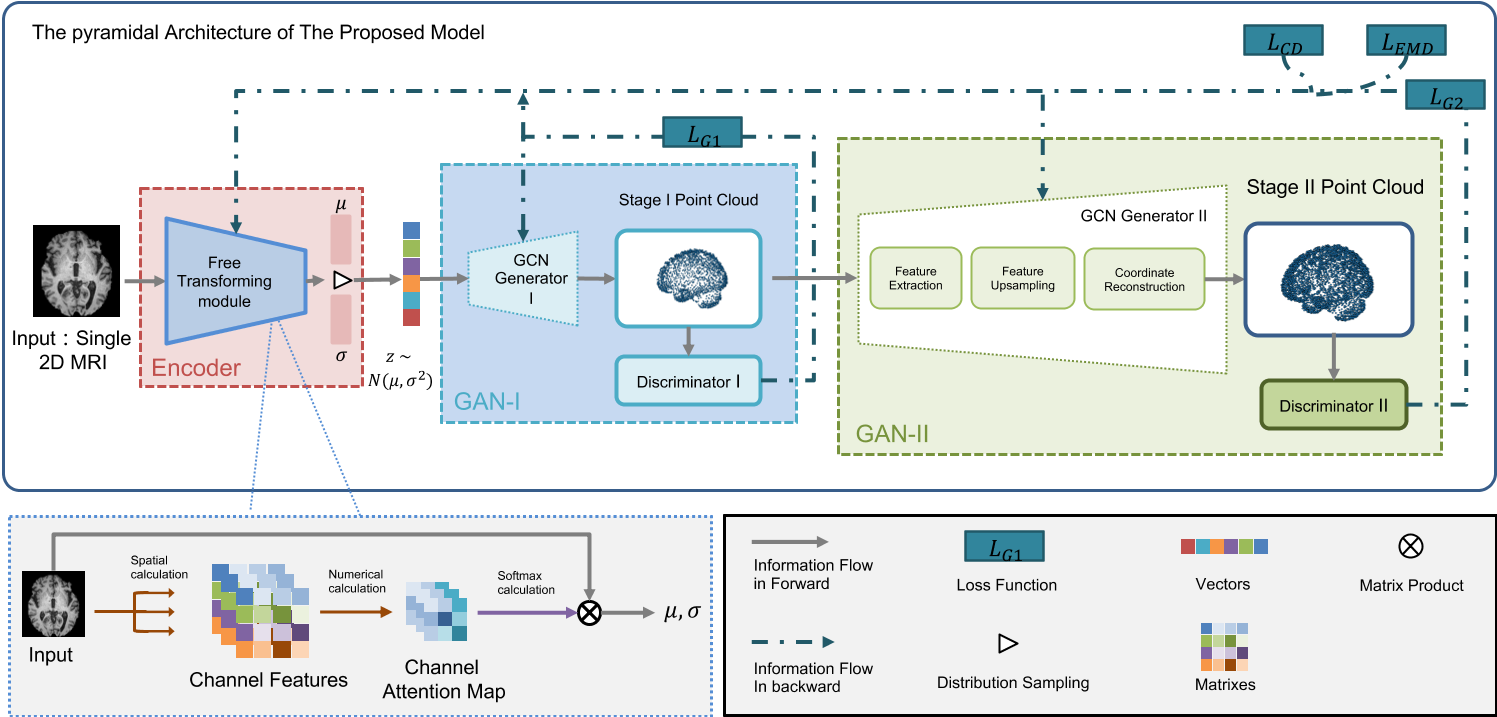
3D Brain Reconstruction and Complete
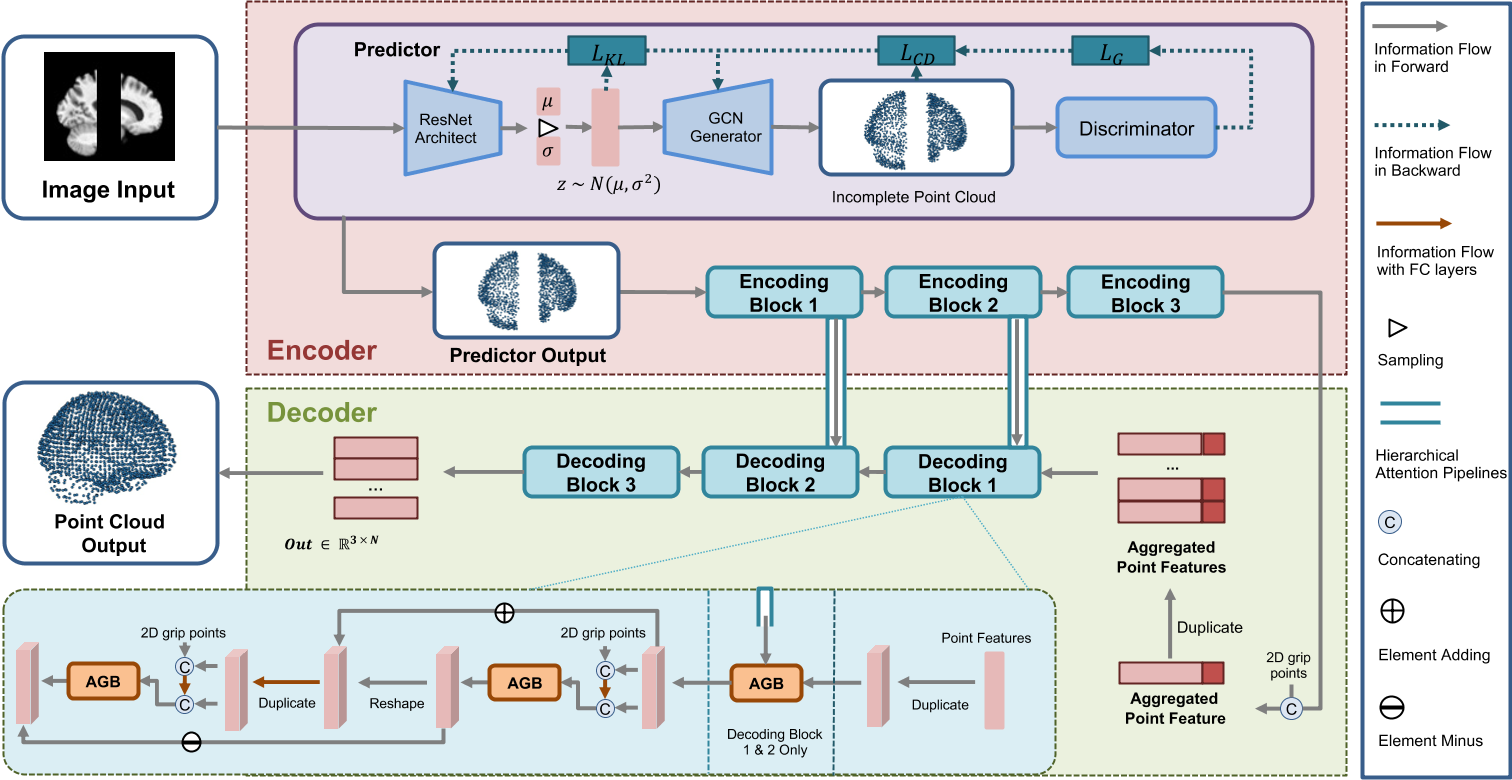
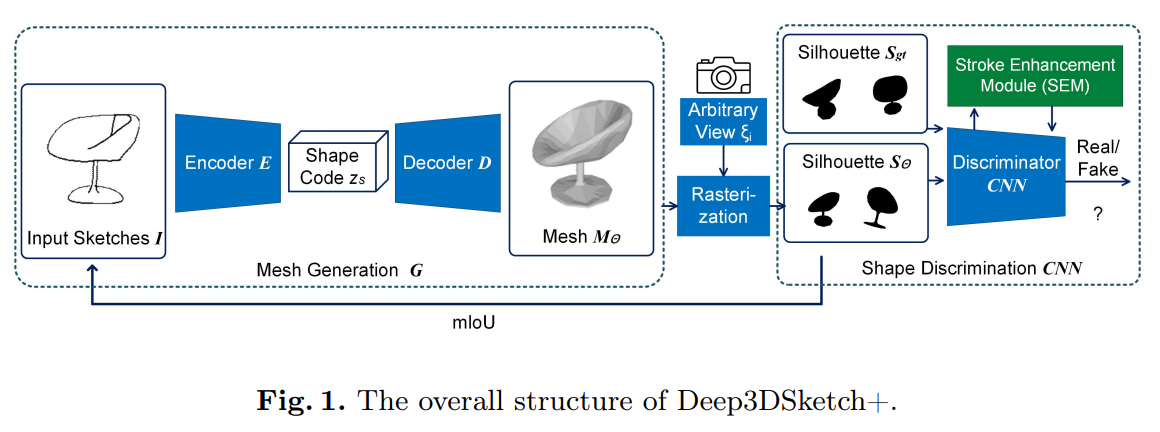
Deep3DSketch+
Deep3DSketch+: Rapid 3D Modeling from Single Free-Hand Sketches (readpaper.com)
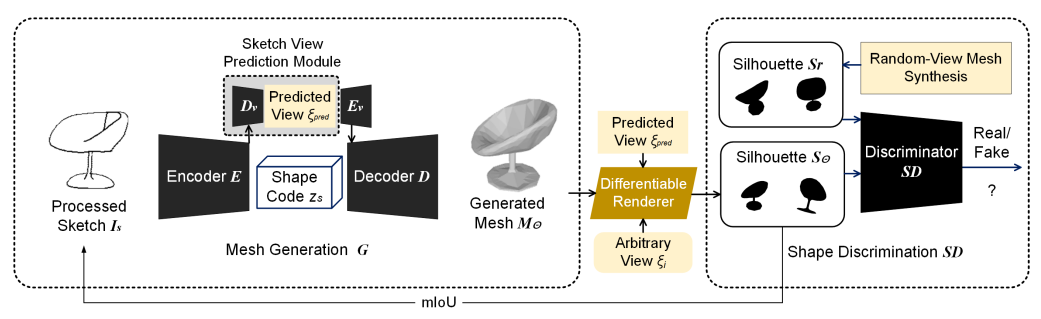
Reality3DSketch
[2310.18148] Reality3DSketch: Rapid 3D Modeling of Objects from Single Freehand Sketches (arxiv.Org)
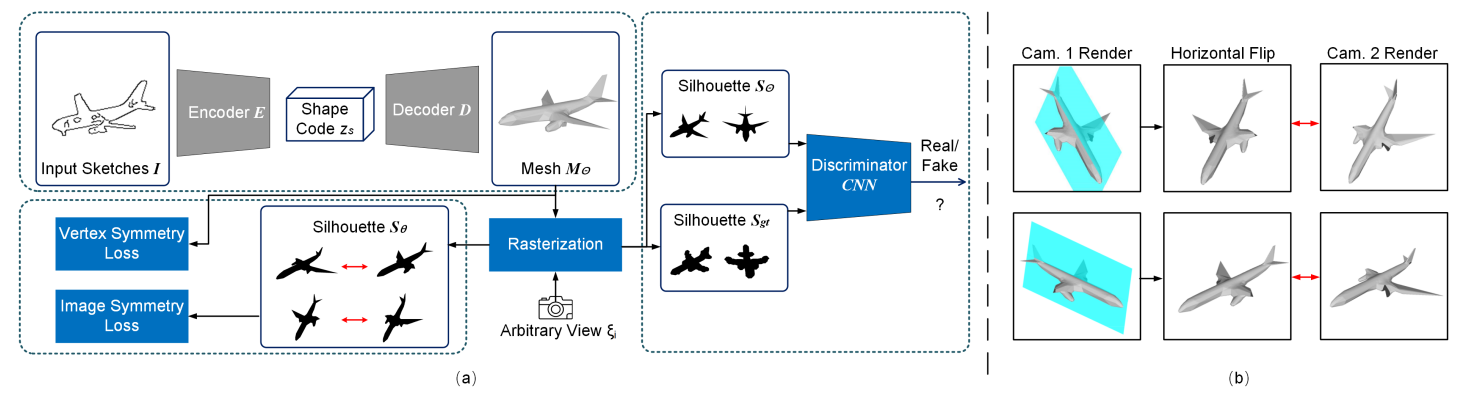
Deep3DSketch+\+
[2310.18178] Deep3DSketch++: High-Fidelity 3D Modeling from Single Free-hand Sketches (arxiv.Org)
GET3D
nv-tlabs/GET3D (github.com)
GET3D: A Generative Model of High Quality 3D Textured Shapes Learned from Images (nv-tlabs.github.io)
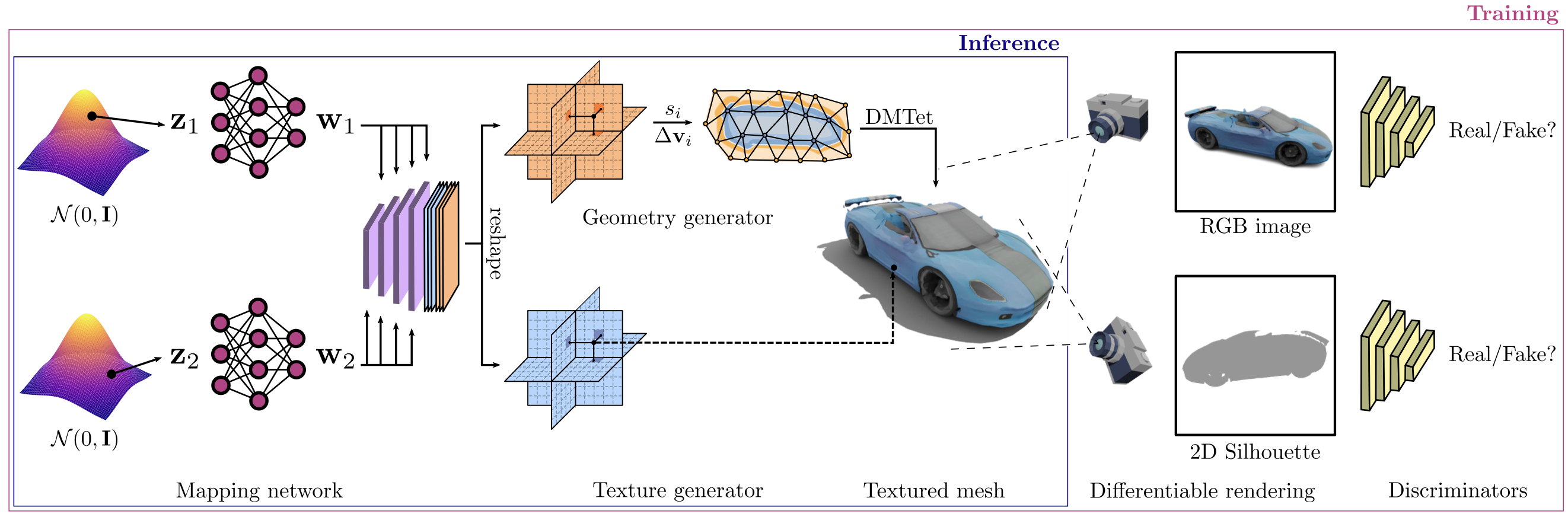
AG3D
AG3D: Learning to Generate 3D Avatars from 2D Image Collections (zj-dong.github.io)
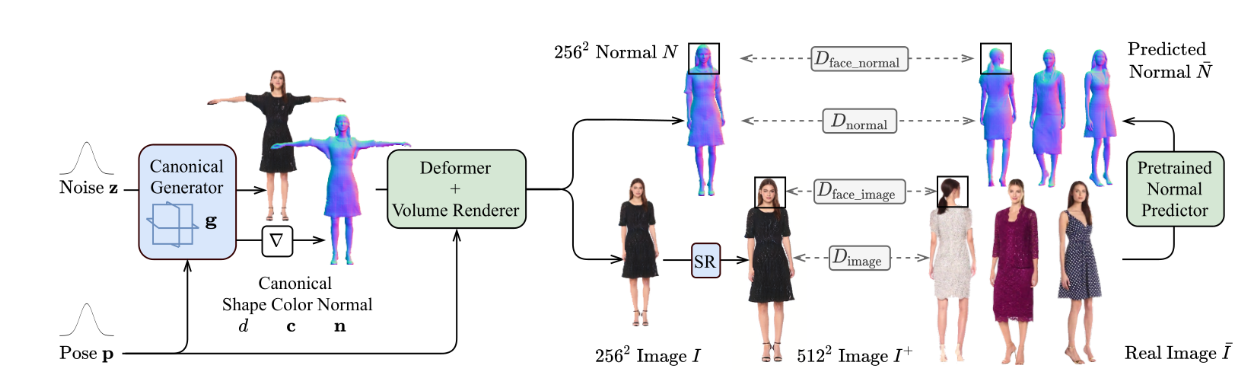
NFs (Normalizing Flows)
PointFlow
stevenygd/PointFlow: PointFlow : 3D Point Cloud Generation with Continuous Normalizing Flows (github.com)
PointFlow: 3D Point Cloud Generation with Continuous Normalizing Flows (readpaper.com)
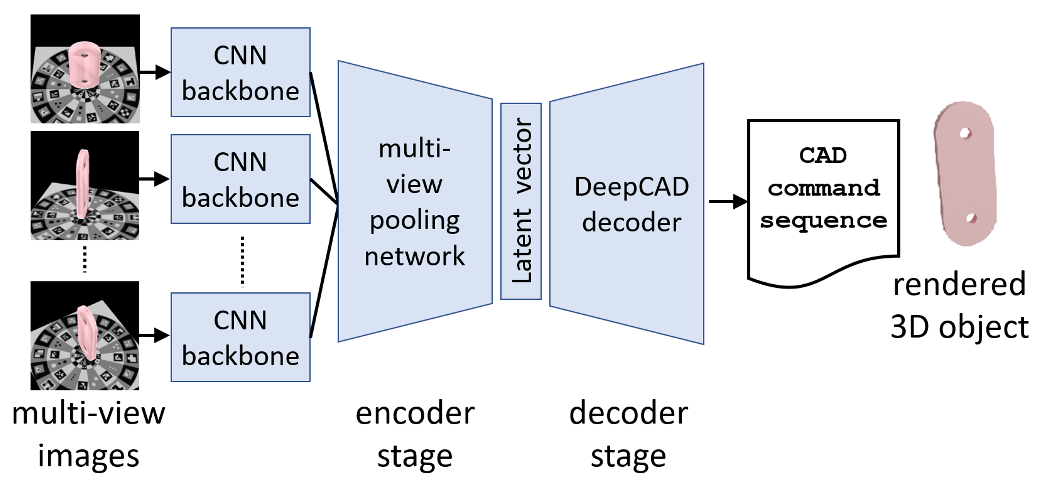
Other
Automatic Reverse Engineering
多视图图像生成 CAD 命令序列
局限性:
- CAD 序列的长度仍然局限于 60 个命令,因此只支持相对简单的对象
- 表示仅限于平面和圆柱表面,而许多现实世界的对象可能包括更灵活的三角形网格或样条表示
SimIPU
雷达点云+图片
3DRIMR
3DRIMR: 3D Reconstruction and Imaging via mmWave Radar based on Deep Learning. (readpaper.com)
MmWave Radar + GAN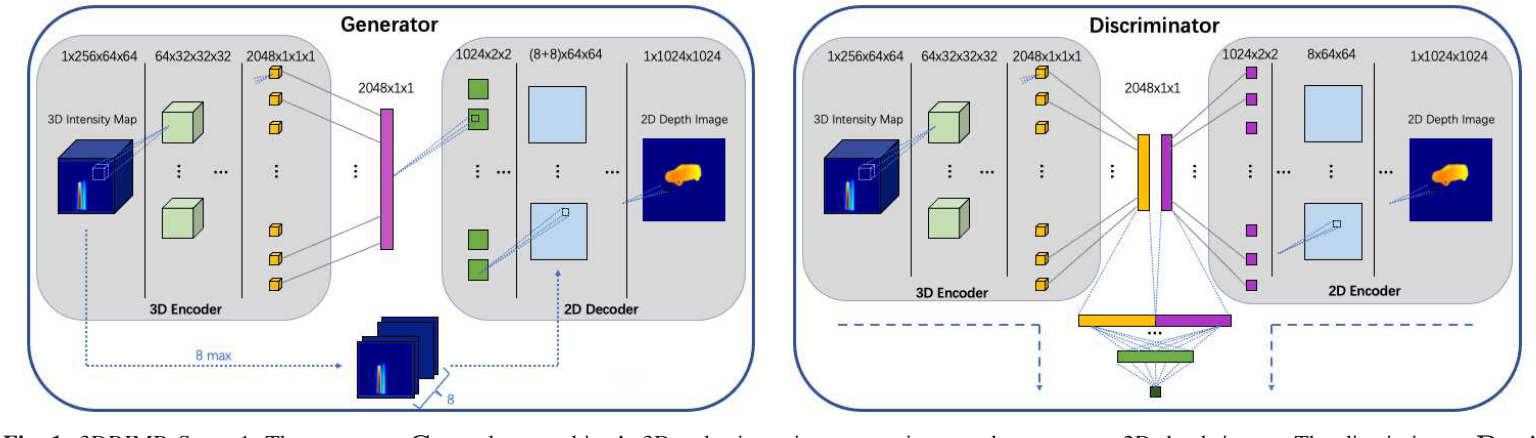
TransHuman
TransHuman论文阅读笔记
TransHuman: A Transformer-based Human Representation for Generalizable Neural Human Rendering (pansanity666.github.io)
ImplicitFunction(NeRF)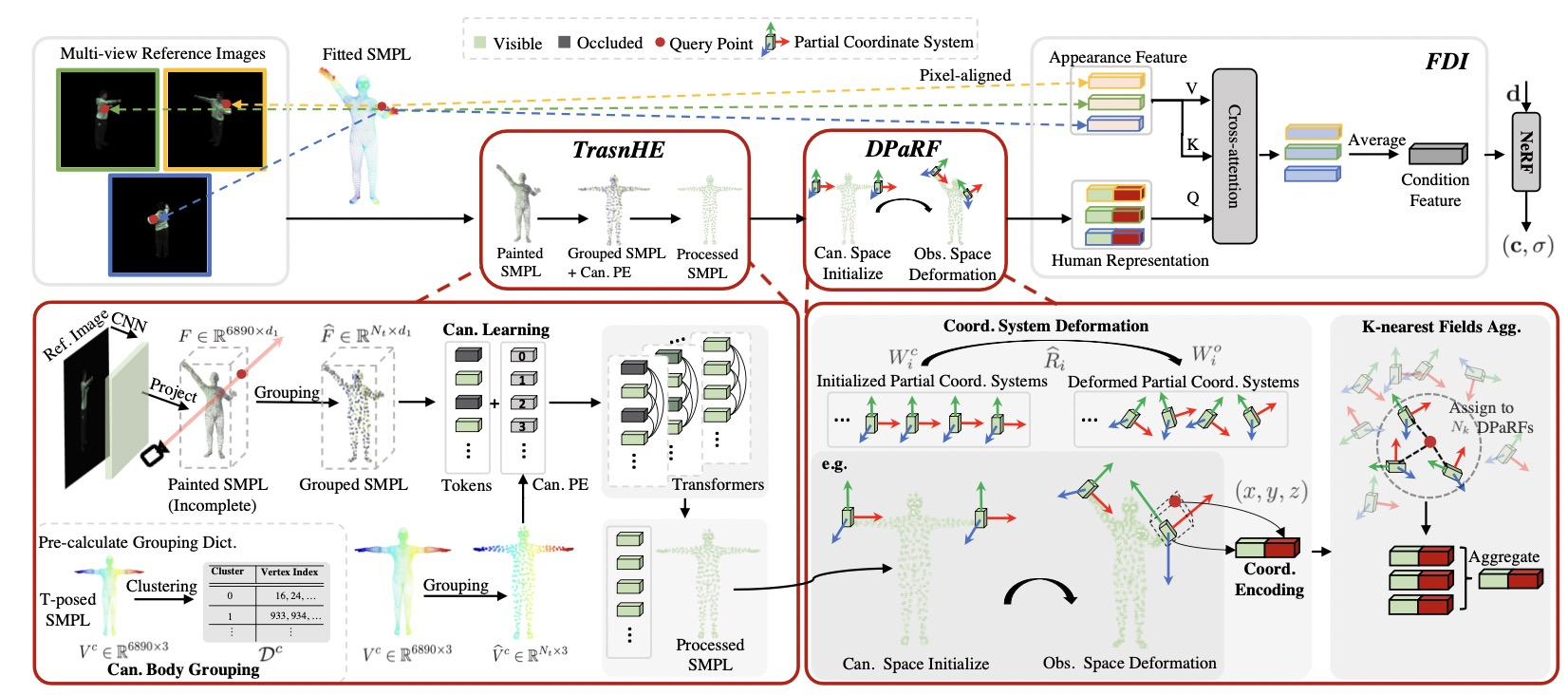
Nvdiffrec
网格优化比 mlp 优化难,速度慢 from NeRF wechat
- 还有一个 nvdiffrcmc,效果可能好一些 Shape, Light, and Material Decomposition from Images using Monte Carlo Rendering and Denoising
- 后续还有个 NeuManifold: Neural Watertight Manifold Reconstruction with Efficient and High-Quality Rendering Support,应该比 nvdiffrec 要好

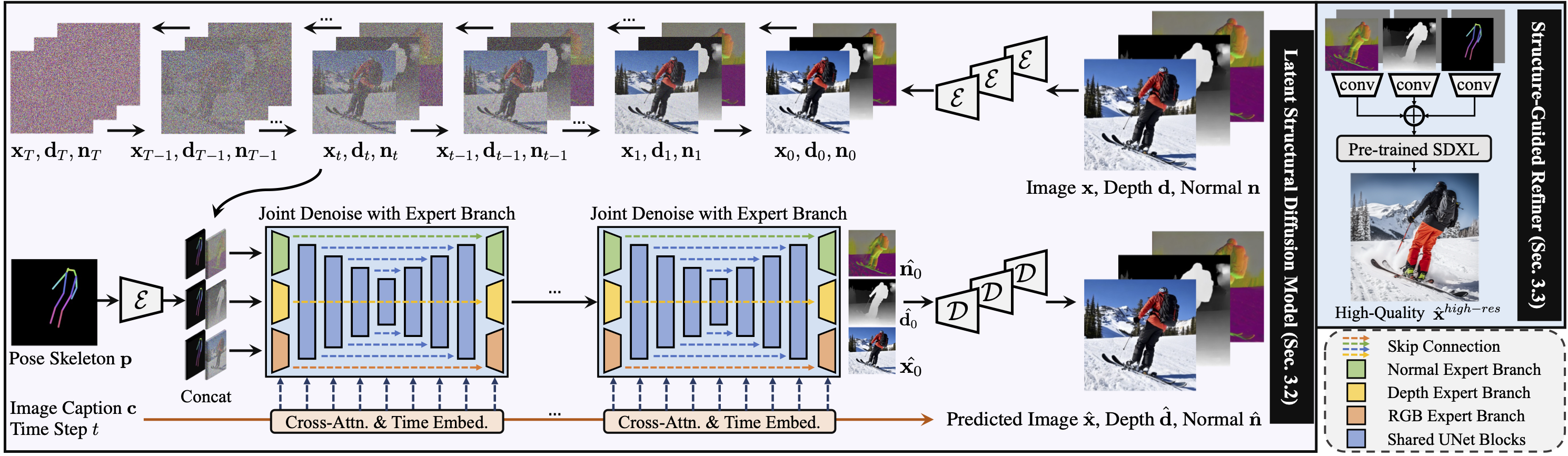
HyperHuman
SyncDreamer
SyncDreamer: Generating Multiview-consistent Images from a Single-view Image (liuyuan-pal.github.io)
多视图一致的图片生成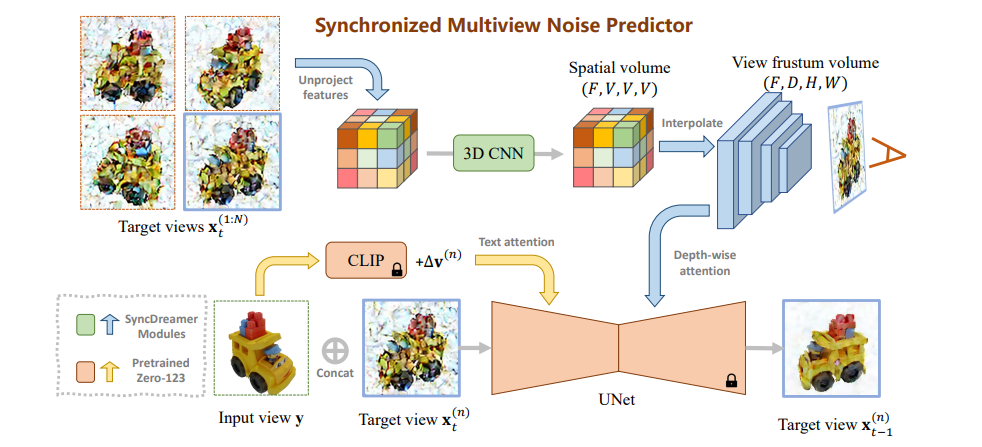
One-2-3-45
MVS+NeRF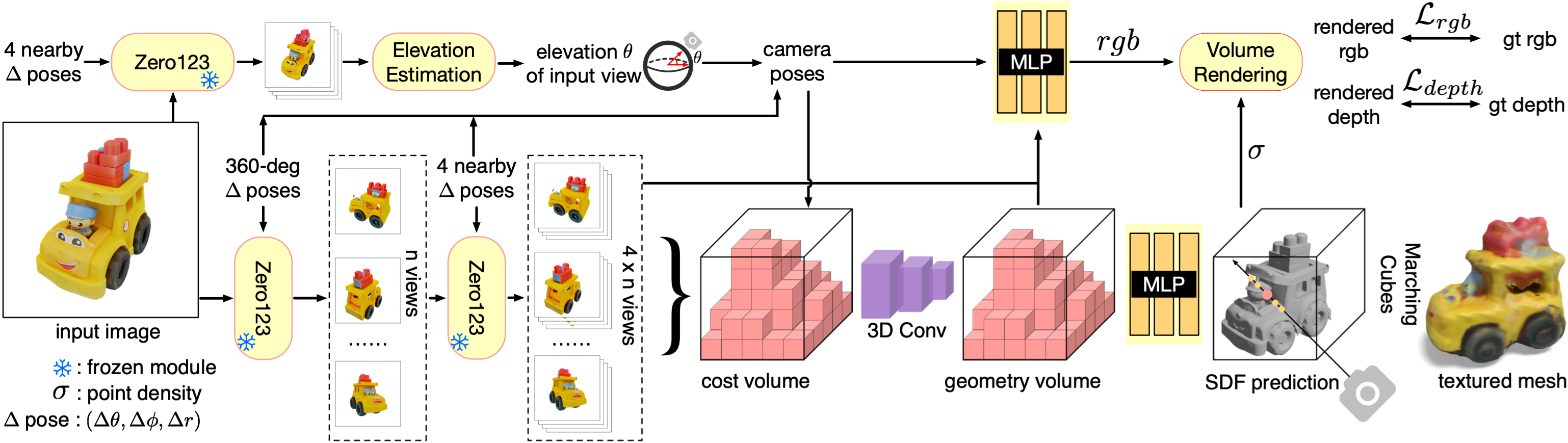
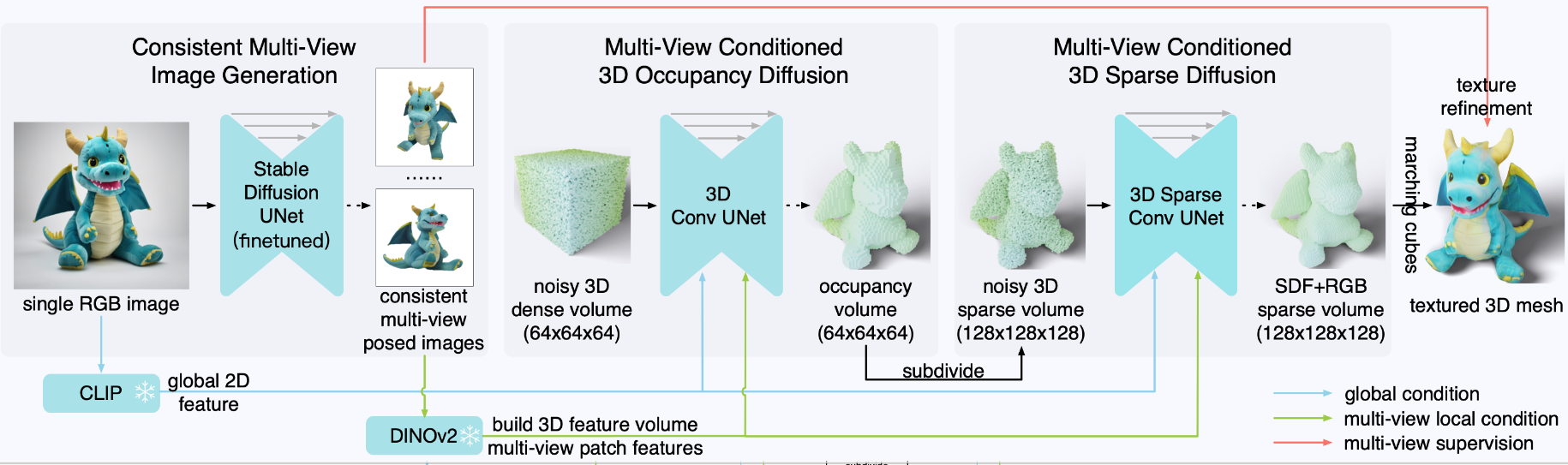
One-2-3-45++
One-2-3-45++ (sudo-ai-3d.github.io)
==提供了一个可以图片生成3D 资产的 demo== sudoAI
一致性图像生成 + CLIP + 3D Diffusion Model
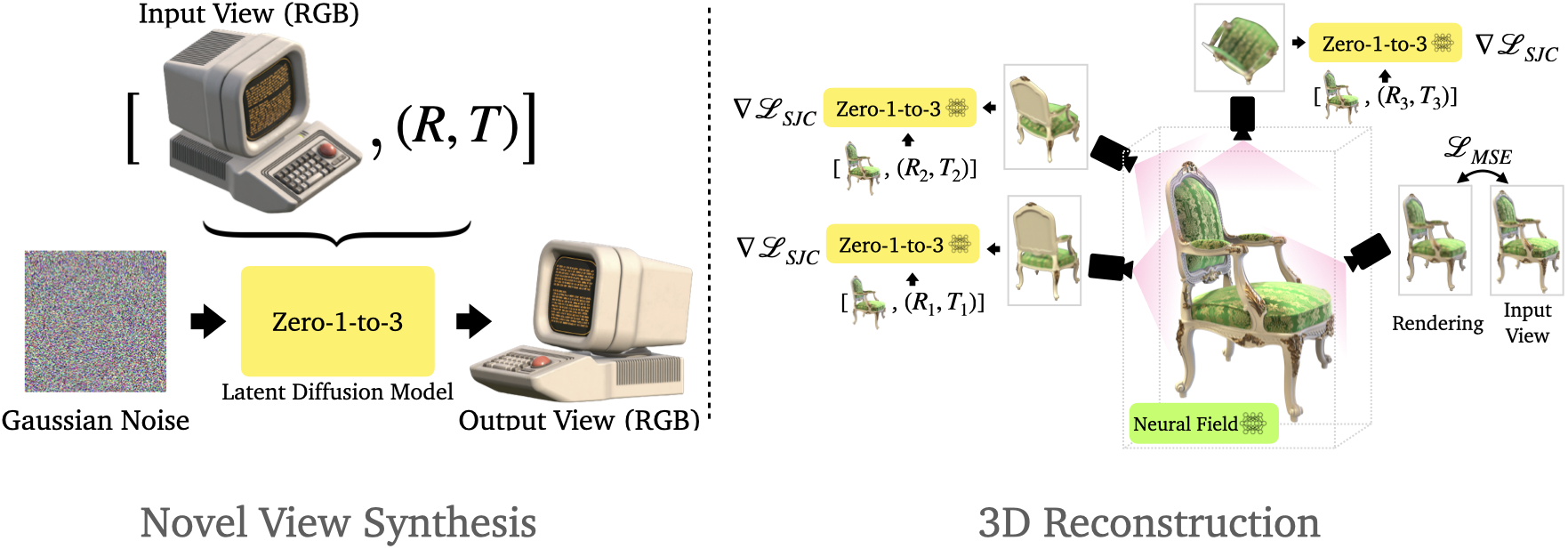
Zero-1-to-3
Zero-1-to-3: Zero-shot One Image to 3D Object (columbia.edu)
多视图一致 Diffusion Model + NeRF
Pix2pix3D
pix2pix3D: 3D-aware Conditional Image Synthesis (cmu.edu)
一致性图像生成+NeRF
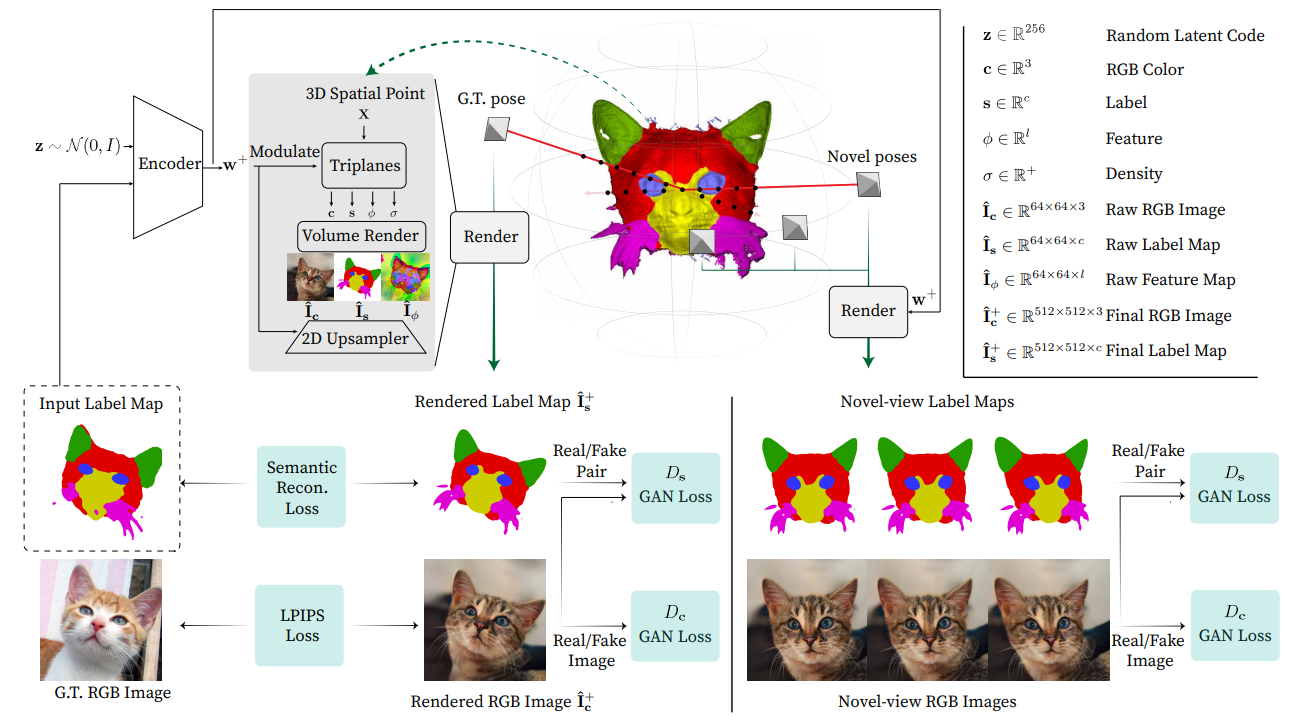
Consistent4D
Consistent4D (consistent4d.github.io)
单目视频生成 4D 动态物体,Diffusion Model 生成多视图(时空)一致性的图像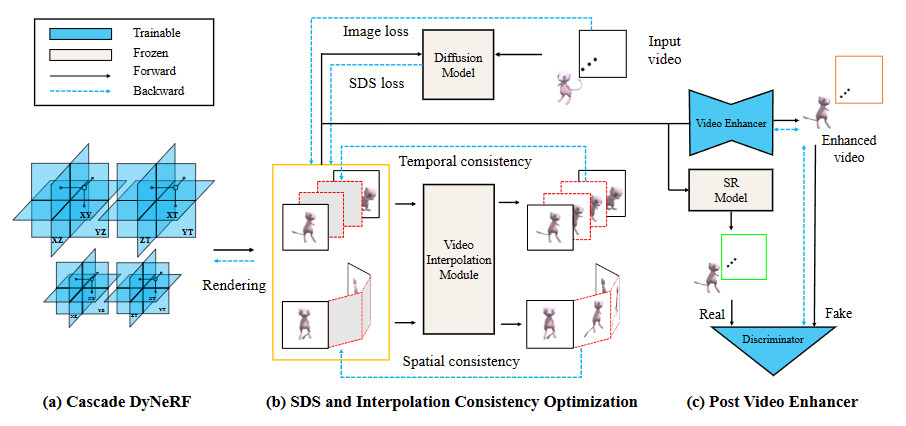
ConRad
ConRad: Image Constrained Radiance Fields for 3D Generation from a Single Image
ConRad: Image Constrained Radiance Fields for 3D Generation from a Single Image (readpaper.com)
多视图一致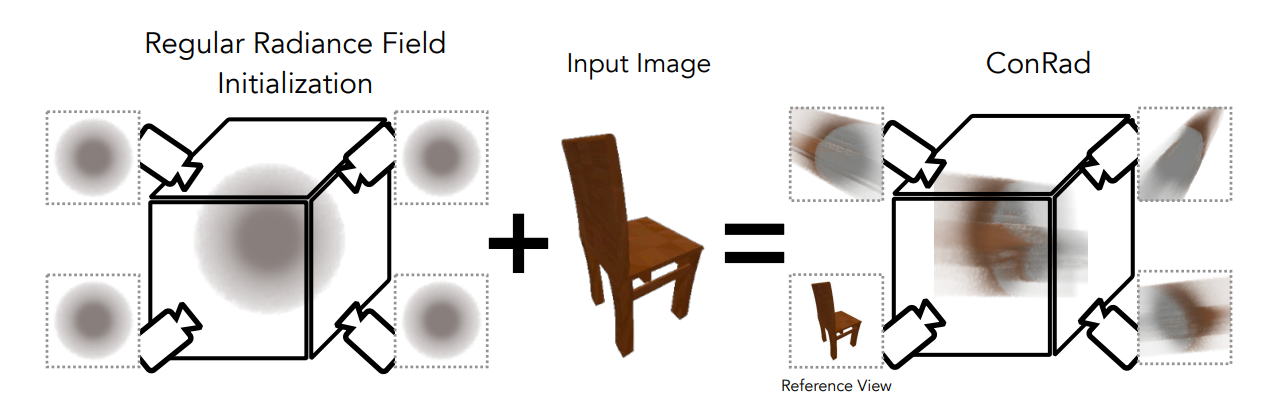
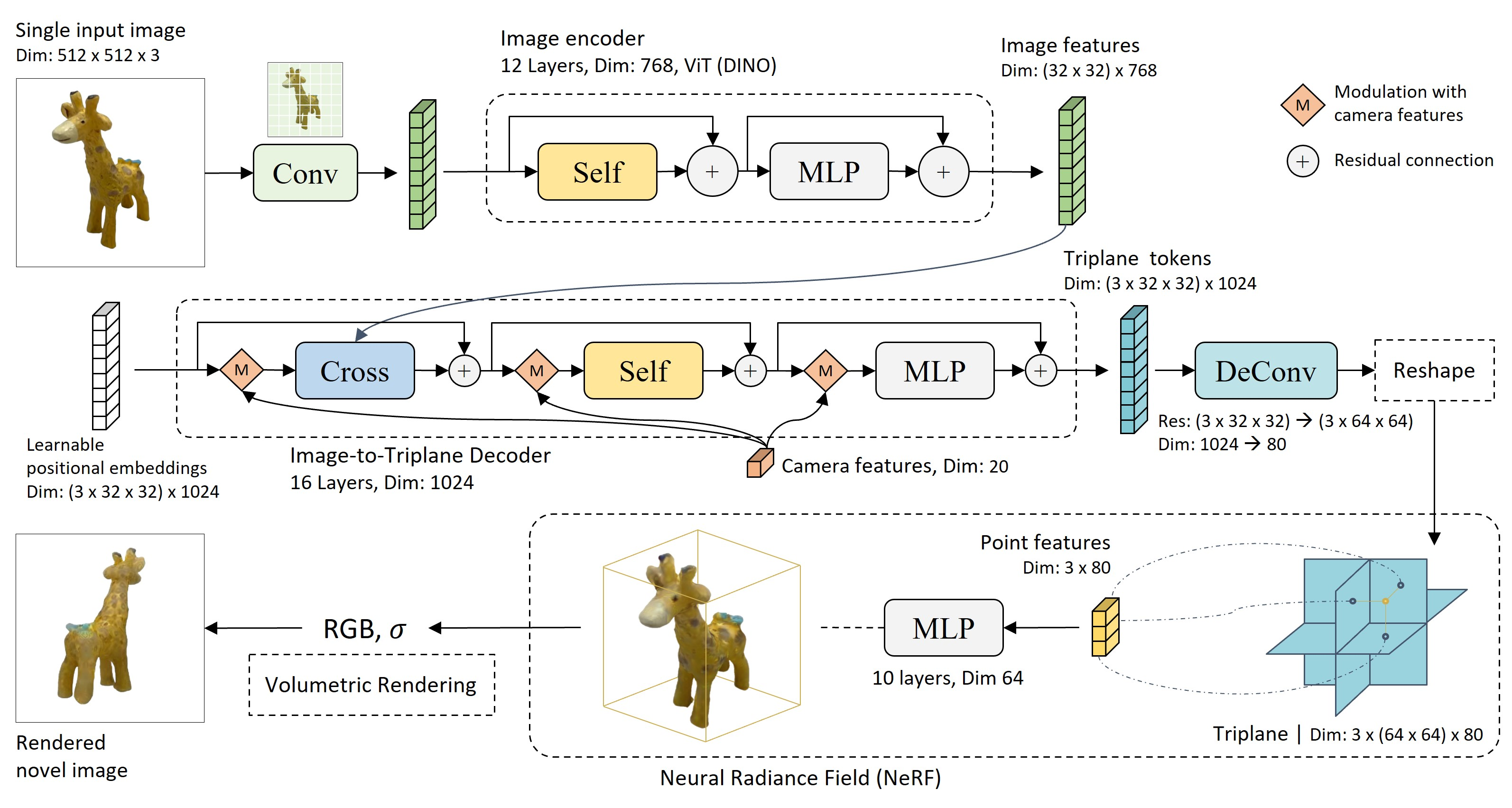
LRM
LRM: Large Reconstruction Model for Single Image to 3D (scalei3d.github.io)
大模型 Transformer(5 亿个可学习参数) + 5s 单视图生成 3D
Instant3D
Instant3D: Instant Text-to-3D Generation (ming1993li.github.io)
文本生成 3D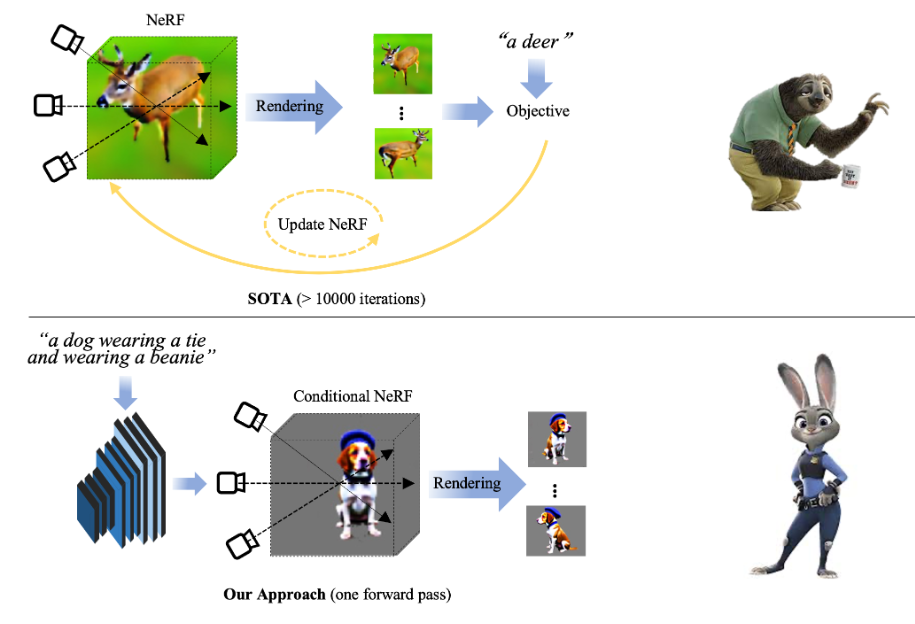
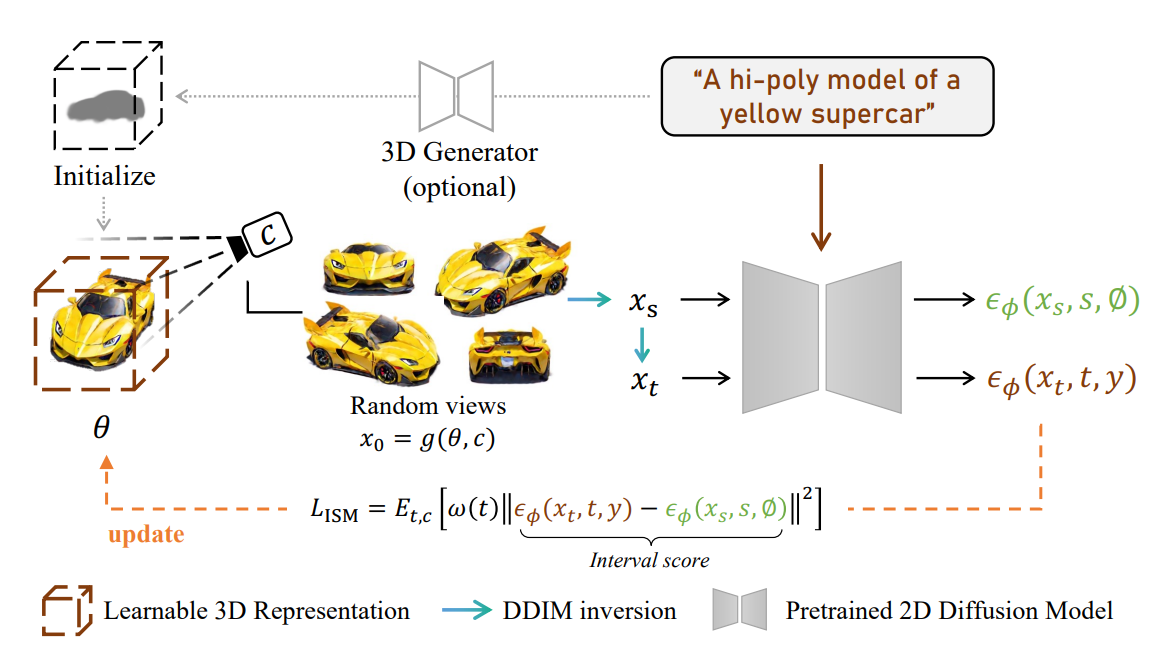
LucidDreamer
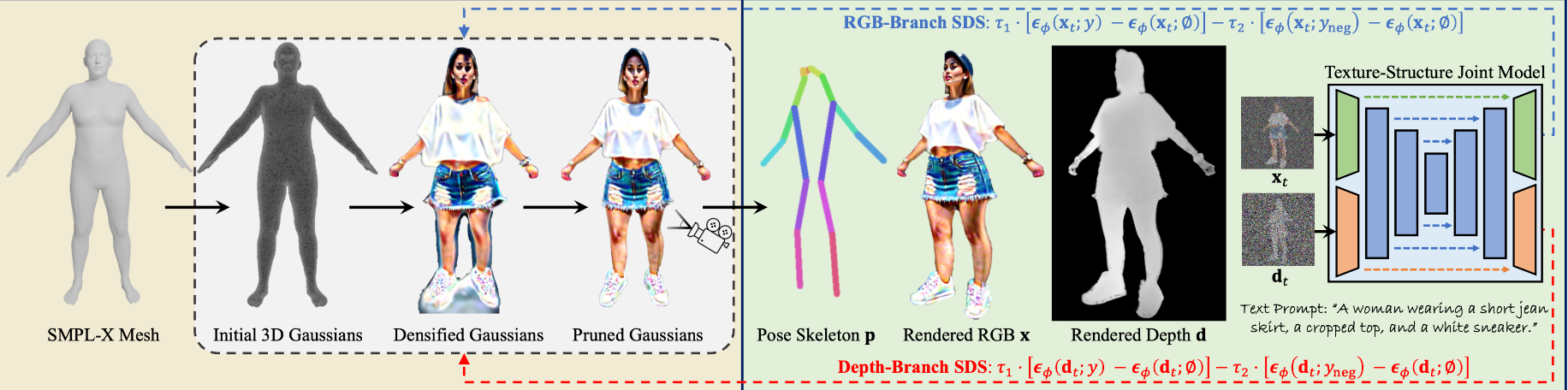
HumanGaussian
HumanGaussian: Text-Driven 3D Human Generation with Gaussian Splatting (alvinliu0.github.io)
Gaussian Splatting 文本生成 3DHuman
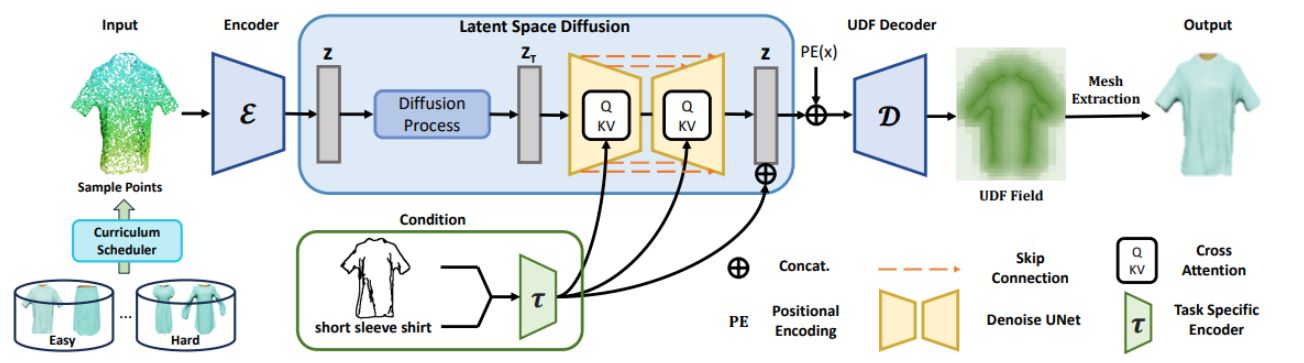
Surf-D
高质量拓扑 3D 衣服生成
HumanRef
单视图 Diffusion 人体生成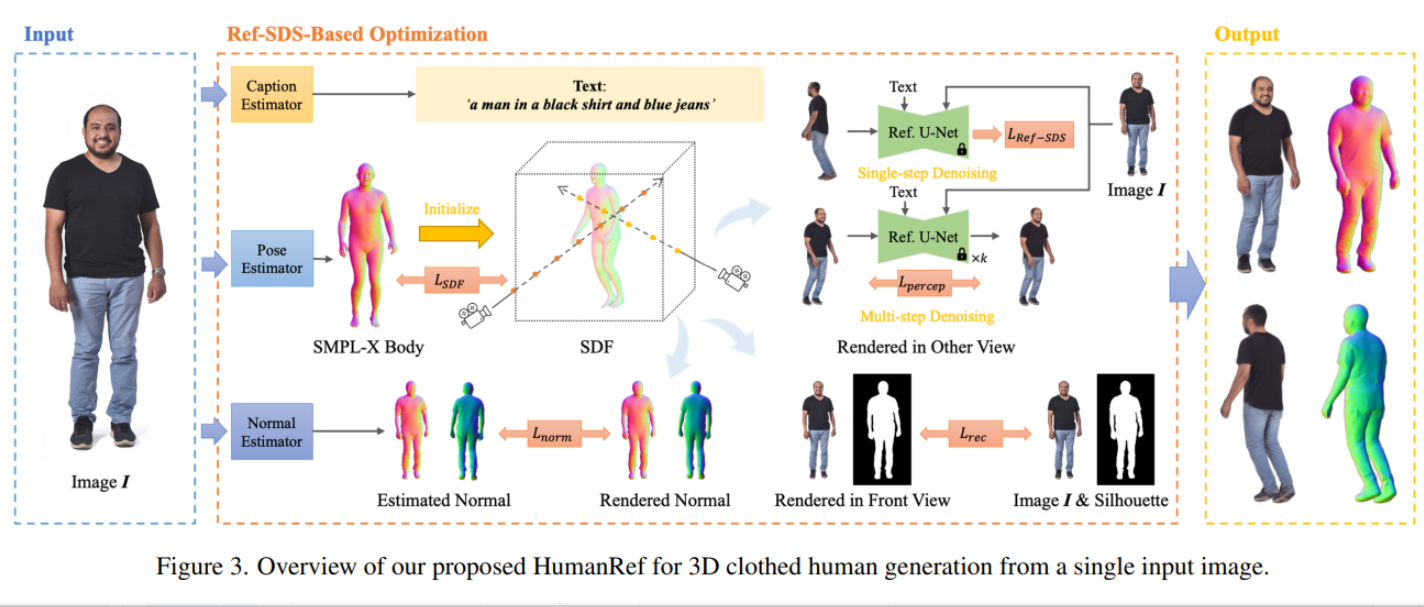
RichDreamer
文本生成 3D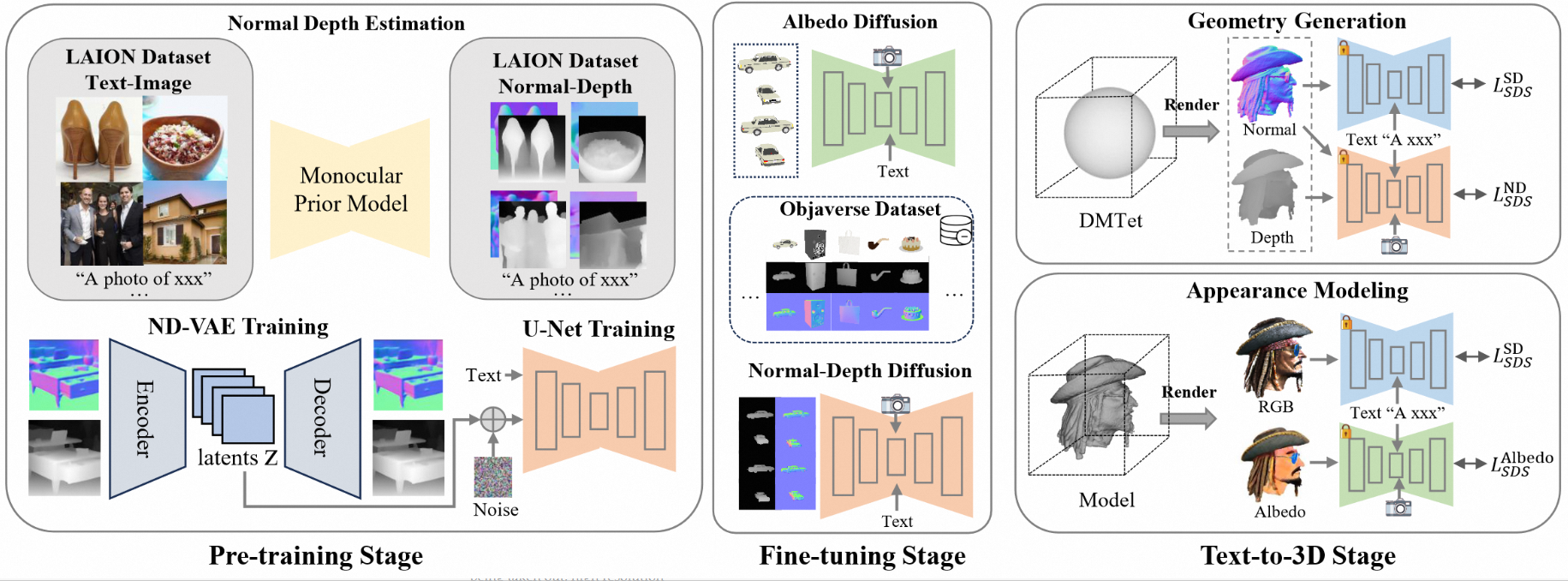
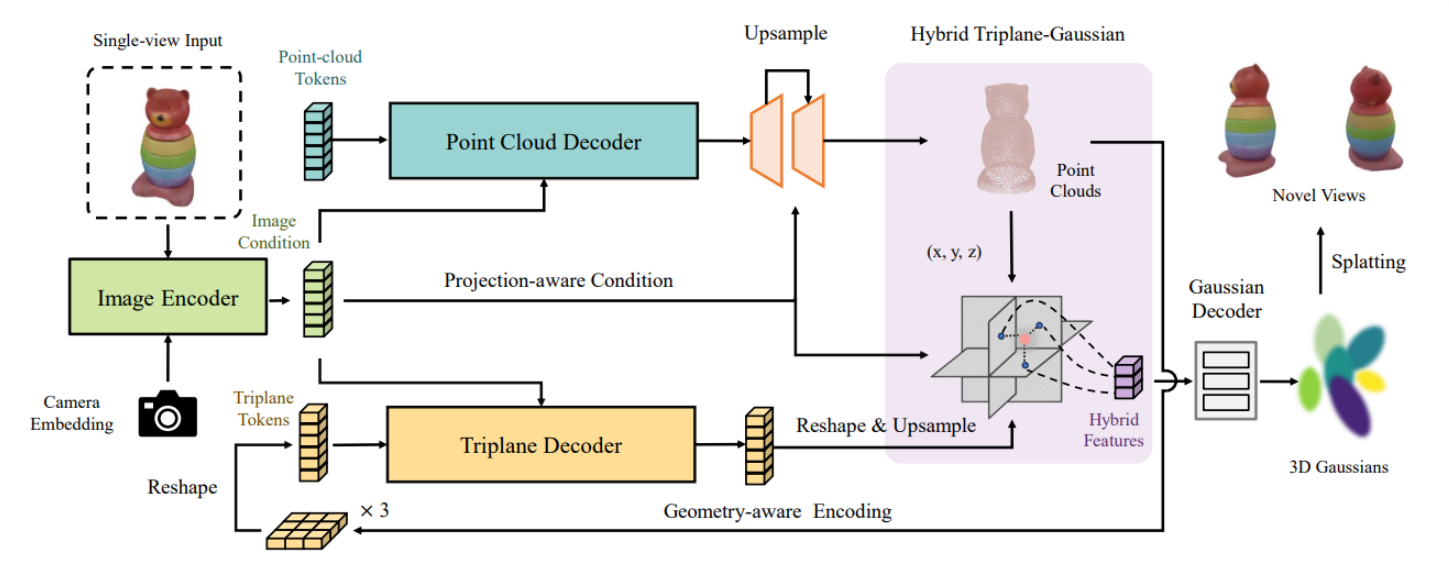
TriplaneGaussian
单视图生成3D
Mosaic-SDF
Mosaic-SDF (lioryariv.github.io)
一种新的三维模型的表示方法:M-SDF,基于Flow的生成式方法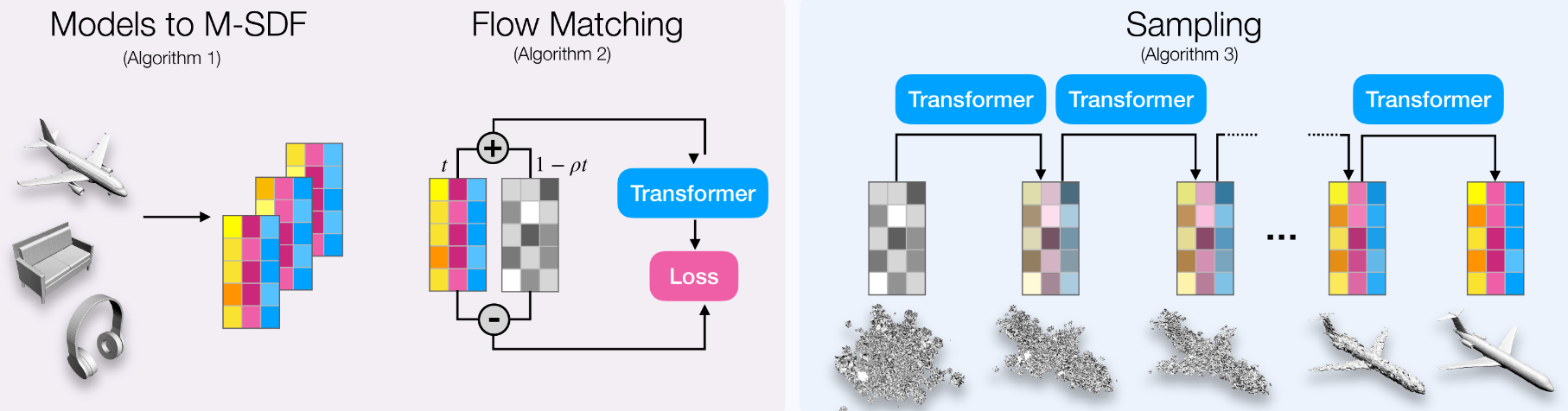
PI3D
[2312.09069] PI3D: Efficient Text-to-3D Generation with Pseudo-Image Diffusion (arxiv.org)