| Title | DMV3D: Denoising Multi-View Diffusion using 3D Large Reconstruction Model |
|---|---|
| Author | Xu, Yinghao and Tan, Hao and Luan, Fujun and Bi, Sai and Wang Peng and Li, Jihao and Shi, Zifan and Sunkavalli, Kaylan and Wetzstein Gordon and Xu, Zexiang and Zhang Kai} |
| Conf/Jour | arxiv |
| Year | 2023 |
| Project | DMV3D: Denoising Multi-View Diffusion Using 3D Large Reconstruction Mode (justimyhxu.github.io) |
| Paper | DMV3D: DENOISING MULTI-VIEW DIFFUSION USING 3D LARGE RECONSTRUCTION MODEL (readpaper.com) |
需要相机位姿 + 多视图 + Diffusion Model + NeRF Triplane2MLP
不足:
- 对未见视图的重建质量不高
- 只支持低分辨率图像和三平面
- 只支持输入没有背景的物体图像
- 没用到任何先验知识
Abstract
我们提出了一种新的三维生成方法 DMV3D,它使用基于 transformer 的三维大重建模型来去噪多视图扩散。我们的重建模型采用三平面 NeRF 表示,可以通过 NeRF 重建和渲染去噪多视图图像,在单个 A100 GPU 上实现 30 秒内的单阶段 3D 生成。我们只使用图像重建损失,而不访问 3D 资产,在高度多样化对象的大规模多视图图像数据集上训练 DMV3D。我们展示了最先进的单图像重建问题的结果,其中需要对未见物体部分进行概率建模,以生成具有尖锐纹理的多种重建。我们还展示了高质量的文本到 3D 生成结果,优于以前的 3D 扩散模型。
Method
我们现在展示我们的单阶段 3D 扩散模型。特别是,我们引入了一种新的扩散框架,该框架使用基于重建的去噪器来去噪 3D 生成的多视图图像(第 3.1 节)。在此基础上,我们提出了一种新的基于 lrm 的(Hong et al., 2023)基于扩散时间步长的多视点去噪器,通过 3D NeRF 重建和渲染逐步去噪多视点图像(第 3.2 节)。我们进一步扩展我们的模型以支持文本和图像调节,从而实现可控生成(第 3.3 节)。
MULTI-VIEW DIFFUSION AND DENOISING
Diffusion. Denoising Diffusion Probabilistic Models (DDPM)在正向扩散过程中使用高斯噪声调度对数据分布 $x_{0} \sim q(x)$ 进行变换。生成过程是图像逐渐去噪的反向过程。
Multi-view diffusion.
Reconstruction-based denoising.
$\mathbf{I}_{r,t}=\mathrm{R}(\mathrm{S}_t,\boldsymbol{c}),\quad\mathrm{S}_t=\mathrm{E}(\mathcal{I}_t,t,\mathcal{C})$
- 使用重建模块 E(·) 从有噪声的多视图图像中重建三维表示 S
- 基于 lrm 的重构器 E(·)
- 使用可微渲染模块 R(·)渲染去噪图像
仅在输入视点监督 $\mathcal{I}_0$ 预测并不能保证高质量的3D 生成, 也监督来自3D 模型 $S_{t}$ 的新颖视图渲染
$\mathrm{L}_{recon}(t)=\mathbb{E}_{\mathbf{I},\boldsymbol{c}\sim\mathcal{I}_{full},\mathcal{C}_{full}}\ell\big(\mathbf{I},\mathrm{R}(\mathrm{E}(\mathcal{I}_t,t,\mathcal{C}),\boldsymbol{c})\big)$ , $\mathcal{I}_{full}\mathrm{~and~}\mathcal{C}_{full}$ 表示图像和姿态的完整集合(来自随机选择的输入和新视图)
RECONSTRUCTOR-BASED MULTI-VIEW DENOISER
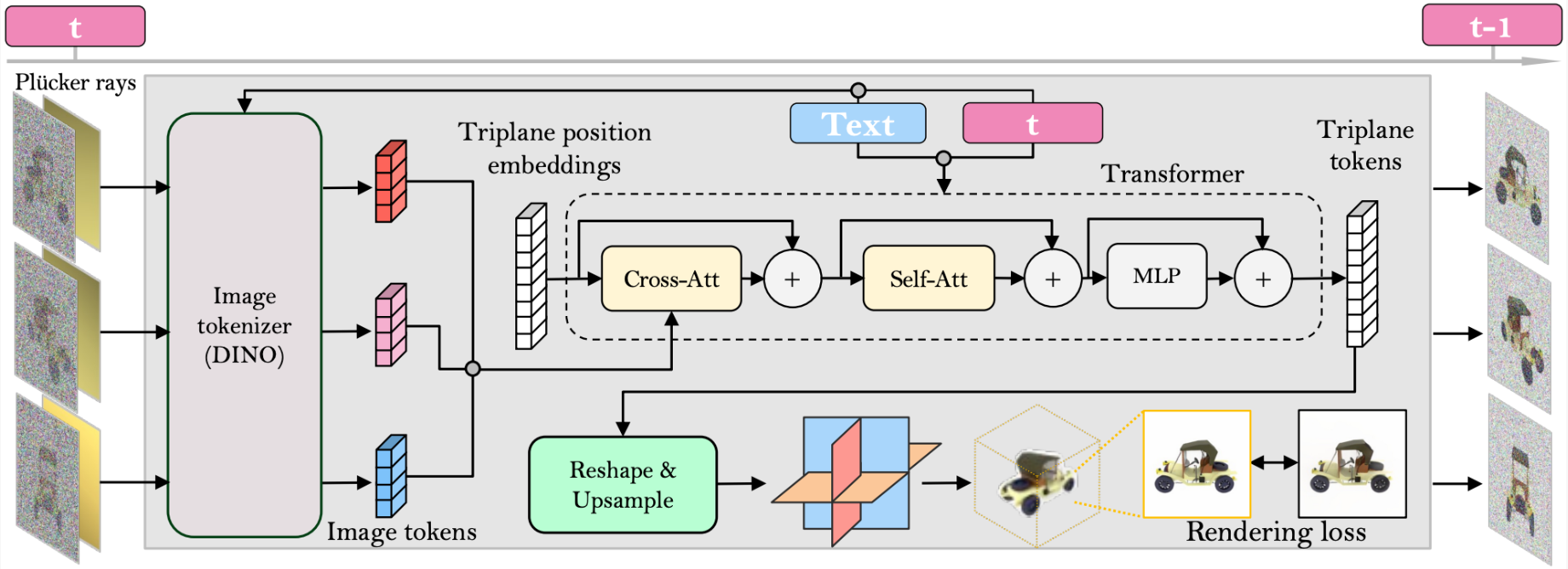
我们在 LRM (Hong et al., 2023)上构建了我们的多视图去噪器,并使用大型 transformer 模型从嘈杂的稀疏视图图像中重建干净的三平面 NeRF (Chan et al., 2022)。然后将重建的三平面 NeRF 的渲染图用作去噪输出。
Reconstruction and Rendering.
与 LRM 工作一样,transformer 变压器模型由一系列三平面到图像的交叉注意层和三平面到三平面的自注意层组成
Time Conditioning.
与基于 cnn 的 DDPM 相比,我们基于变压器的模型需要不同的时间调节设计(Ho et al., 2020)。受 DiT (Peebles & Xie, 2022)的启发,我们通过将 adaLN-Zero 块(Ho et al., 2020)注入模型的自注意层和交叉注意层来对时间进行调节,以有效处理不同噪声水平的输入。
Camera Conditioning.
在具有高度多样化的相机特性和外部特性的数据集上训练我们的模型,例如 MVImgNet (Yu et al., 2023),需要有效地设计输入相机调节,以促进模型对用于 3D 推理的相机的理解 。
一种基本策略是,在时间调节的情况下,对相机参数使用 adaLN-Zero 块(Peebles & Xie, 2022)(如 Hong 等人(2023)所做的那样);Li et al.(2023)。然而,我们发现,同时使用相同的策略对相机和时间进行调节往往会削弱这两个条件的效果,并且往往导致训练过程不稳定和收敛缓慢。
相反,我们提出了一种新的方法——用像素对齐的射线集参数化相机。特别是继 Sitzmann et al. (2021);Chen et al. (2023a),我们使用 Plucker 坐标 r = (o × d, d)参数化射线,其中 o 和 d 是由相机参数计算的像素射线的原点和方向,x 表示叉积。我们将 Plucker 坐标与图像像素连接,并将其发送到 ViT 转换器进行二维图像标记化,实现有效的相机调理
CONDITIONING ON SINGLE IMAGE OR TEXT
迄今为止所描述的方法使我们的模型能够作为无条件生成模型运行。我们现在介绍如何用条件去噪器 $\operatorname{E}(\mathcal{I}_t,t,\mathcal{C},y),$ 对条件概率分布建模,其中 y 是文本或图像,从而实现可控的 3D 生成。
Image Conditioning.
不改变模型结构,我们保持第一个视图 I1(在去噪器输入中)无噪声作为条件图像,同时对其他视图应用扩散和去噪。在这种情况下,去噪器本质上是学习使用从第一个输入视图中提取的线索来填充嘈杂的未见视图中缺失的像素,类似于 2D dm 可寻址的图像绘制任务(Rombach et al., 2022a)。此外,为了提高我们的图像条件模型的可泛化性,我们在与条件视图对齐的坐标框架中生成三平面,并使用相对于条件视图的姿态渲染其他图像。我们在训练过程中以与 LRM (Hong et al., 2023)相同的方式规范化输入视图的姿态,并在推理过程中以相同的方式指定输入视图的姿态
Text Conditioning.
CLIP 文本编码器
TRAINING AND INFERENCE
Training:
$\mathrm{L}=\mathbb{E}_{t\sim U[1,T],(\mathbf{I},\boldsymbol{c})\sim(\mathcal{I}_{full},\mathcal{C}_{fuu)}}\ell\big(\mathbf{I},\mathrm{R}(\mathrm{E}(\mathcal{I}_t,t,\mathcal{D},y),c)\big)$
Inference:
为了进行推断,我们选择了四个视点,它们均匀地围绕在一个圆圈中,以确保生成的 3D 资产的良好覆盖。我们将相机的视角设置为 50 度,用于四个视图。由于我们预测三平面 NeRF 与条件反射图像的相机帧对齐,因此我们也将条件反射图像的相机外饰件固定为具有相同的方向和(0,−2,0)位置,遵循 LRM 的实践(Hong et al., 2023)。我们从最后的去噪步骤输出三平面 NeRF 作为生成的 3D 模型。我们利用 DDIM (Song et al., 2020a)算法来提高推理速度。
Conclusion
我们提出了一种新的单阶段扩散模型,该模型通过去噪多视图图像扩散来生成 3D 资产。我们的多视图去噪器基于大型 transformer模型(Hong et al., 2023),该模型采用带噪的多视图图像来重建干净的三平面 NeRF,并通过体渲染输出去噪图像。我们的框架支持文本和图像调节输入,通过直接扩散推理实现快速3D 生成,而无需进行资产优化。我们的方法在文本到3D 生成方面优于以前的3D 扩散模型,并在各种测试数据集上实现了最先进的单视图重建质量。
Limitations
尽管我们在这项工作中展示了高质量的图像或文本条件下的3D生成结果,但未来的工作仍有一些限制可以探索:
1)首先,我们为物体未见部分生成的纹理似乎缺乏高频细节,颜色略有褪色。这将是有趣的进一步提高纹理保真度;
2)我们的输入图像和三平面目前是低分辨率的。将我们的方法扩展到从高分辨率输入图像生成高分辨率NeRF也是非常可取的;
3)我们的方法只支持输入没有背景的物体图像;直接生成具有3D背景的对象NeRF (Zhang et al., 2020;Barron et al., 2022)在许多应用中也非常有价值;
4)我们的图像和文本条件模型都是从头开始训练的,而不需要利用2D基础模型(如Stable diffusion)中的强图像先验(Rombach et al., 2022b)。考虑如何在我们的框架中利用这些强大的2D图像先验可能会有所帮助
道德声明。我们的生成模型是在Objaverse数据和MVImgNet数据上训练的。该数据集(1M左右)小于训练2D扩散模型的数据集(100M ~ 1000M左右)。数据的缺乏会引起两方面的考虑。首先,它可能会偏向训练数据的分布。其次,它可能不够强大,无法涵盖测试图像和测试文本的所有巨大多样性。我们的模型具有一定的泛化能力,但可能不能像二维扩散模型那样覆盖那么多的模式。鉴于我们的模型不具备识别超出其知识范围的内容的能力,它可能会引入不令人满意的用户体验。此外,如果文本提示或图像输入与某些数据样本高度一致,我们的模型可能会泄漏训练数据。这种潜在的泄漏引起了法律和安全方面的考虑,并在所有生成模型(如LLM和2D扩散模型)中共享。