| Title | Color-NeuS: Reconstructing Neural Implicit Surfaces with Color |
|---|---|
| Author | Licheng Zhong1 , Lixin Yang1,2 , Kailin Li1, Haoyu Zhen1, Mei Han3, Cewu Lu1,2 |
| Conf/Jour | arXiv |
| Year | 2023 |
| Project | Color-NeuS (colmar-zlicheng.github.io) |
| Paper | Color-NeuS: Reconstructing Neural Implicit Surfaces with Color (readpaper.com) |
集成了与视图无关的全局颜色变量和与视图相关的relight效果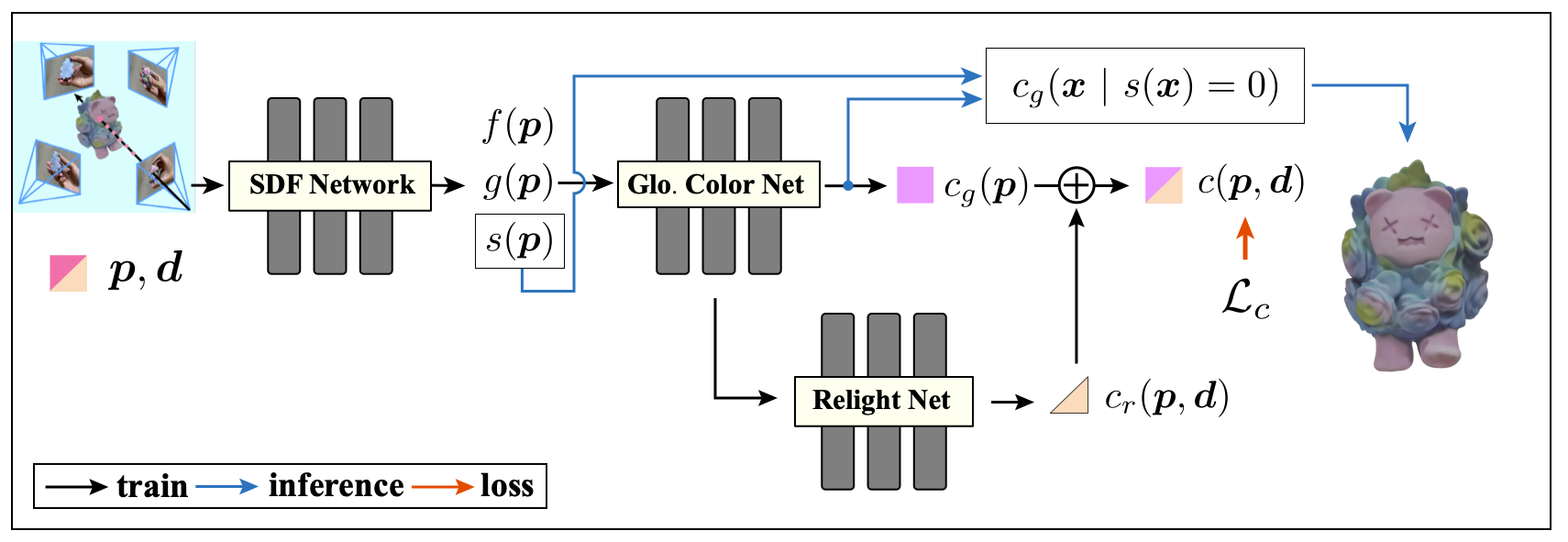
Conclusion
本文介绍了一种新的三维隐式纹理表面重建方法Color-NeuS,该方法与任何类似Neus的模型兼容。通过从神经辐射场中分离出依赖于视图的元素,并采用重光照网络来维持体绘制,Color-NeuS能够有效地检索表面颜色,同时准确地重建表面细节。我们使用我们个人收集的序列以及几个公共数据集,将Color-NeuS测试放在要求苛刻的手持对象扫描任务上。结果表明,Color-NeuS具有重建具有准确颜色表示的神经隐式表面的能力。
AIR
从多视图图像或单目视频中重建物体表面是计算机视觉中的一个基本问题。然而,最近的许多研究集中在通过隐式或显式方法重建几何。在本文中,我们将重点转向与颜色相结合的网格重建。我们从神经体绘制中去除与视图相关的颜色,同时通过重光照网络保持体绘制性能。从表面的符号距离函数(SDF)网络中提取网格,并从全局颜色网络中绘制每个表面顶点的颜色。为了评估我们的方法,我们设想了一个手持物体扫描任务,该任务具有许多遮挡和光照条件的急剧变化。我们为这项任务收集了几个视频,结果超过了任何现有的能够重建网格和颜色的方法。此外,使用公共数据集(包括DTU、BlendedMVS和OmniObject3D)评估了我们的方法的性能。结果表明,我们的方法在所有这些数据集上都表现良
Introduction
从二维图像重建三维物体是计算机视觉和图形学领域的一个关键和持续的挑战。此前,SFM方法[20,21]被广泛用于从2D图像重建3D物体。然而,此外,它经常很难处理缺乏纹理或重复模式的场景,导致模糊的对应关系和不正确的深度估计。SFM的另一个限制是它不能有效地处理闭塞。当场景中的物体被部分遮挡时,往往会导致重建错误。SFM的另一个局限性在于它对点云表示的依赖,无法实现完全密集的重建。最近,这一领域的前景一直在发展,人们对通过体渲染来研究隐式神经表面的兴趣日益浓厚Neus[23],它可以表示像素级的精细表面。这是基于神经辐射场的工作[18]NeRF。
像NeRF[18]及其后继者[1,4,16,30,36]这样的开创性作品令人信服地证明了神经网络在表示连续3D场景方面的强大功能。这是通过学习从3D坐标到体密度和视图相关颜色的映射来实现的,从而实现高效的新视图合成。随后,Neus[23]扩展了这一概念,利用有符号距离函数(SDF)重建神经隐式曲面。然而,NeuS的范围仍然局限于无顶点颜色的网格重建。这个限制出现在Neus的神经体渲染中,每个点的颜色都是由它的位置和观察光线方向决定的。因此,在没有视图方向的网格重建环境中,NeuS无法为每个点分配特定的颜色值。为了解决这一问题,本文提出了一种基于视觉无关颜色的神经隐式曲面重建方法。
我们提出了Color-NeuS,这是一种与NeuS兼容的方法,可以独立于视点,促进3D表面和全局顶点颜色的重建。同时,它支持NeuS在渲染2D图像和执行3D表面重建方面的强大功能。为此,我们用与视图无关的全局颜色变量和与视图相关的重光照效果的集成取代了神经体渲染中与视图相关的单一颜色分量,如图1所示。这不仅使我们的模型能够进行标准体渲染的训练,而且为全局顶点颜色的学习铺平了道路。重要的是,Color-NeuS自然地处理物体表面的大量反射,并且可以处理物体之间动态交互过程中的间歇性遮挡(见图7)。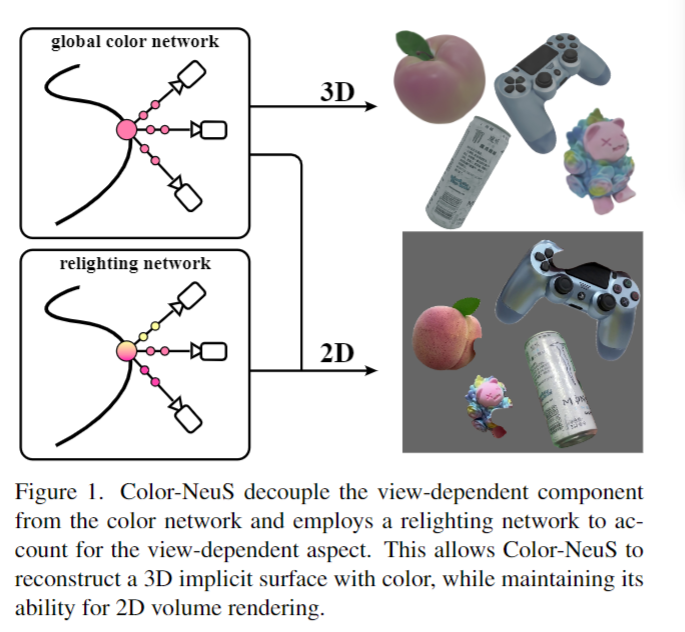

我们的Color-NeuS的有效性已经在各种数据集上得到了广泛的验证,包括DTU[13]、BlendedMVS[32]和OmniObject3D[29]数据集。为了证明我们的方法的优越性,我们与激光扫描和成熟的方法如COLMAP[20,21]和HHOR[12]进行了比较评估。结果表明,Color-NeuS在提取合理纹理的同时,成功地重建了物体表面。为了强调其实际应用,我们将Color-NeuS应用于现实世界中具有挑战性的任务:手持物体扫描[10,12]。作为这个过程的一部分,我们收集一个数据集进行验证,其中包括物体的3D扫描,手持移动物体的视频,以及以物体为中心的相机转换。
贡献:
- 我们提出了一种新的方法来重建一个具有颜色的神经隐式表面,可以应用于任何类Neus模型。
- 我们解耦了神经体渲染中依赖于视图的过程,在获得全局顶点颜色的同时能够处理遮挡和反射。
- 我们设计了一个具有挑战性的手持物体扫描任务,用于重建带颜色的网格,并为此任务编译了一个真实世界的数据集。
Related Work
Neural Radiance Field.
继NeRF的开创性工作[18]之后,神经隐式场出现了各种各样的研究。
- 其中值得注意的是,NeRF−−[26]、NoPe-NeRF[2]、BARF[15]和GNeRF[17]一直在研究在训练隐式场时估计相机姿势的方法。
- 与此同时,Pixel-NeRF[36]、MVSNeRF[4]和IBRNet[24]等研究的重点是神经辐射场的泛化。
- 与此同时,KiloNeuS[7]、NeX[28]、NeRV[22]、NeRD[3]等研究项目也在关注神经领域的照明和再照明。
- 该方法兼容神经体绘制,保留了新视图合成的能力。
Surface Reconstruction.
- 隐式可微分渲染器(IDR)[33]通过利用隐式几何正则化(IGR)[8],将几何表示为有符号距离函数(SDF)的零水平集。
- Neus[23]结合了SDF场和体绘制来重建曲面。
- VolSDF[34]和UNISURF[19]都将隐式表面表示与体绘制结合起来:
- VolSDF[34]将外观与几何分离,
- 而UNISURF[19]以内聚的方式制定隐式表面模型和亮度场。
- PET-NeuS[25]是NeuS[23]的扩展,引入了新的组件,如独特的位置编码类型、三平面表示和可学习的卷积操作。然而,这些方法没有考虑到全局视图无关的表面颜色。
- 我们的方法侧重于从全局颜色网络中提取表面颜色,同时保持从重光照网络中学习几何和图像渲染的能力。
In-hand Object Scanning.
- ObMan[11]提出了一种端到端可学习的模型,该模型采用独特的接触损失,鼓励物理上合理的手-物配置。
- 对于手持物体扫描任务,IHOI[35]利用估计的手部姿态,从单个RGB图像进行重建。
- 另一方面,BundleSDF[27]使用RGBD输入序列图像估计目标姿态,同时重建由有符号距离函数(Signed Distance Function, SDF)表示的隐式表面。
- HHOR[12]也利用SDF来表示物体表面,但它是与手一起重建物体的,而手是牢牢握住物体的。
- 最近的一项工作[9]从RGB序列重建物体,并通过使用占用场来表示表面来同时估计相机姿势。但是,它假设光源距离较远,并且光的方向保持不变。
- 相反,我们的方法可以处理任意光照条件来模拟物体的外观。
Preliminary
我们首先引入神经隐式曲面(Neural Implicit Surface, NeuS)[23],这是我们方法的基础。给定一个具有已知内在参数的相机,我们可以将相机坐标系中的光线表示为 : $p(z)=\mathbf{o}+z\mathbf{d},$ Eq.1
其中o和d分别是原点和射线的方向,z是原点到射线上一点的距离。然后,使用MLP网络$\mathcal{G}$将p编码为其带符号距离函数(SDF) s(p)和特征向量f (p),分别为:$[s(p),f(p)]=\mathcal{G}(p).$ Eq.2
以位置p、方向d、特征向量f (p)、梯度g(p)为输入,另一个MLP $\mathcal{M}$输出查询点的颜色为:$c(p,d)=\mathcal{M}(p,d,f(p),g(p)),$ Eq.3
其中$g(p) =∇s(p)$为SDF在p点处的梯度。最后,对查询像素C沿射线的颜色进行积分,得到查询像素C的颜色,
$C=\int_{z_n}^{z_f}w(z)c(\mathbf{p},\mathbf{d})dz,$ Eq.4
$w(z)=\exp\big(-\int_{z_n}^z\sigma(t)dt\big)*\sigma(z),$ Eq.5
$\sigma(\mathbf{p})=\frac{\alpha e^{-\alpha s(\mathbf{p})}}{(1+e^{-\alpha s(\mathbf{p})})^2},$ Eq.6
其中σ(p)表示以$\alpha\in\mathbb{R}^1$作为可学习参数的p的密度。$w(z)$表示在z点处赋予颜色的权重。另外,$z_{n}$和$z_{f}$分别表示相机的近、远平面。
基于Eq.(4)中的输入d,输出的每个顶点颜色与视图相关。因此,原始的Neus避免了incorporating color,,只专注于表面形状的重建。
Method
我们的目标是提取物体的颜色和几何形状,
$c_g(\mathbf{x}),x\in\mathcal{S},$ Eq.7
其中$\mathcal{S}=\left.\{x\in\mathbb{R}^3|s(\mathbf{x})=0\right\}$表示物体表面(网格顶点的集合),其特征为一组具有零级带符号距离值的点。
Property1:
([23, Sec.3.1]) NeuS具有一个有利的性质,其中密度σ(p)的标准差由可训练参数1/α决定,随着网络训练达到收敛,该参数逐渐接近零。
根据性质1,神经辐射场的密度σ(p)基本上集中在表面s上,这为我们在网络训练达到收敛时提取物体的表面(每个顶点)颜色提供了一个焦点。
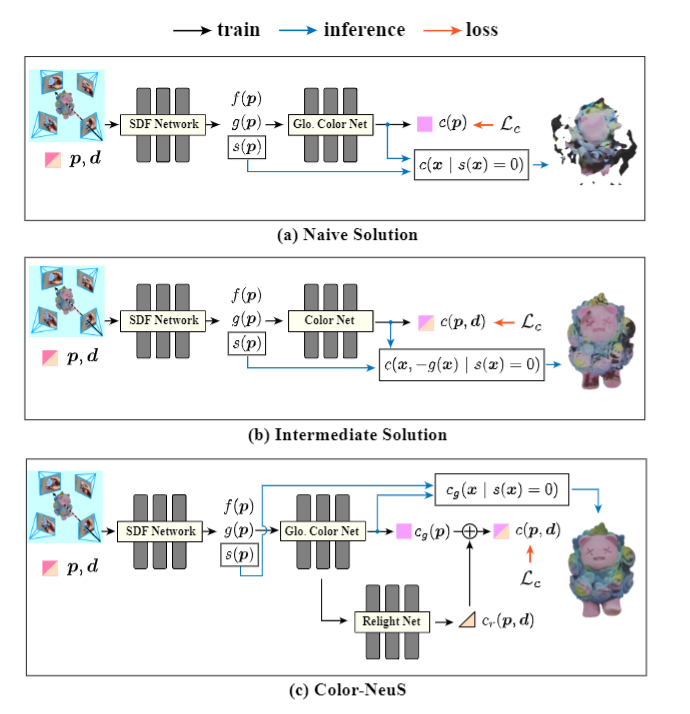
Naive Solution
一种看似直观的解决方案是简单地删除式(3)中的视图相关项,如:
$c(p)=\mathcal{M}(p,f(p),g(p)).$ Eq.8
遗憾的是,进行这个过程可能会潜在地损害所学到的几何形状和神经辐射场内的外观。这是由于当视点相关项缺失时,神经辐射场无法准确表达不同方向点的光变化。此外,这种方法也可能最终导致SDF场的破裂,随后引发地表的破碎。朴素解的定性结果如图3所示。

Intermediate Solution
中间的解决方案是利用一个恒定的方向作为颜色网络的输入,以便从表面提取颜色信息。例如,在HHOR[12]中,顶点颜色是根据表面的法线方向来定义的。对于任意x∈S,法线方向由- g(x)给出。因此,可以使用
$c(x)=\mathcal{M}(x,-g(x),f(x),g(x)).$Eq.9
然而,考虑到物体表面颜色在不断变化的光照条件下会发生相当大的变化,用单一的“方向色”来表示物体的真实颜色可能是不够的。与光表面相互作用相关的固有复杂性要求更细致入微的方法来提取颜色。
Color-NeuS
在我们的方法Color-NeuS中,我们提出了一个工作流来将全局颜色从视图相关的公式中分离出来,同时保留适当的几何形状并为每个顶点获得合理的视图无关的颜色。具体来说,我们用一个独立于视图的全局颜色变量(第4.3.1节)和一个依赖于视图的重光照效果(第4.3.2节)的学习取代了单个依赖于视图的颜色组件的学习(如Eq.(3)所示)。
Removing View-Dependence
我们提出的解决方案首先从Eq.(3)中删除视图依赖项,将模型转换为全局颜色网络,如下:
$c_{g}(\mathbf{p})=\mathcal{M}_{g}(\mathbf{p},f(\mathbf{p}),g(\mathbf{p})).$ Eq.10
该公式与Eq.(8)中提出的朴素解相匹配,后者是提取依赖于视图的顶点颜色的理想起点。然而,仅仅使用这个方程(忽略视图依赖性)来训练网络收敛将违反性质1。因此,这种矛盾可以阻止密度σ(p)凝聚到物体表面,无意中影响学到的几何。
因此,我们提出的解决方案(Color-NeuS)是将推理过程与训练分开。
- 在训练过程中,我们将全局颜色与与视图方向不一致的残差项重新整合。该集成的结果满足体绘制公式Eq.(4)中提出的视图要求,并且在训练阶段保持属性1。
- 在推理过程中,一旦密度σ(p)浓缩到物体表面,就可以保证物体的形状(s(p) = 0)。另外,$c_{g}(p)$获得了表示顶点颜色的能力。
因此,我们可以在推理过程中提取曲面(其中$x\in\mathcal{S}$,即$s(\mathbf{x})=0$)上的顶点颜色
$c_g(\mathbf{x})=\mathcal{M}_g(\mathbf{x},f(\mathbf{x}),g(\mathbf{x})).$ Eq.11
Coupling Relighting Effect
为了在$c_{g}(x)$中去除视图依赖项后保持模型的性能,我们引入了一个重光照网络来补偿丢弃的视图依赖项。重照明网络根据位置、方向和与视图无关的颜色发挥作用,为每个点生成一个小的与视图相关的颜色调整。这可以表示为:
$c_{r}(\mathbf{p},\mathbf{d})=\mathcal{R}_{g}(c_{g}(\mathbf{p}),\mathbf{p},\mathbf{d},g(\mathbf{p})).$Eq.12
然后,将重光照效果与全局颜色进行积分,计算出每个点的最终颜色,如下:
$c(\mathbf{p},\mathbf{d})=\Psi(\Psi^{-1}(c_g(\mathbf{p}))+c_r(\mathbf{p},\mathbf{d})),$Eq.13
其中$Ψ$和$Ψ^{−1}$分别表示sigmoid函数和逆sigmoid函数。目前,颜色是全局颜色(与视图无关)和重光照效果(与视图相关)的融合。然后将$c(\mathbf{p},\mathbf{d})$纳入方程(4)中计算体积积分c。
Optimization
沿着采样光线的渲染颜色C可以使用公式计算。(4) ~(6)。设$\widehat{C}$为地面真色,可将颜色损失定义为:
$\mathcal{L}_{c}=\frac{1}{N_{r}}\sum_{i=1}^{N_{r}}|\widehat{C}_{i}-C_{i}|_{2}^{2},$ Eq.14
式中,$N_{r}$为采样射线的个数。
为了使优化后的神经表示满足有效的SDF,我们对SDF预测进行了eikonal正则化[8],如下:
$\mathcal{L}_{e}=\frac{1}{N_{r}N_{p}}\sum_{i,j}^{N_{r},N_{p}}(|\nabla s(p_{i,j})|_{2}-1)^{2},$ Eq.15
其中$N_{p}$为每条射线上的采样点数。
为了使全局颜色更接近实际颜色,我们对relight颜色$c_{r}$的平均值施加约束为零,如下所示:
$\mathcal{L}_{r}=\frac{1}{N_{r}N_{p}}\sum_{i,j=1}^{N_{r},N_{p}}c_{ri,j}(p,d).$Eq.16
这种策略促使全局颜色网络在平均光照条件下学习颜色。换句话说,这样可以最小化重光照网络对全局颜色的影响。这个损失项是必要的,因为我们不能直接监督全局颜色,原因在幼稚方案4.1中提到。
在物体重建的背景下,一种直观的方法是使用物体(前景)分割来消除背景元素。在前景分割可用且没有物体-场景遮挡的情况下,我们建议合并掩码损失$L_{m}$
$\mathcal{L}_{m}=\frac{1}{N_{r}}\sum_{N_{r}}BCE(M,\hat{O}),$ Eq.17
其中,$\hat{O}=\sum_{j}w_{j}$是沿相机光线的累积权值,M是表示光线是否在目标分割边界内的二进制掩码。
综上所述,我们的训练损失按照Eq.(18)计算,其中$λ_{c}, λ_{e}, λ_{r}, λ_{m}$为超参数。
$\mathcal{L}=\lambda_{c}\mathcal{L}_{c}+\lambda_{e}\mathcal{L}_{e}+\lambda_{r}\mathcal{L}_{r}+\lambda_{m}\mathcal{L}_{m}.$
除了优化上面提到的网络参数外,对于我们的野生数据集,我们还根据NeRF−−[26]优化了相机姿势。与GNeRF[17]一样,我们使用连续的6D向量$r\in\mathbb{R}^6$来表示三维旋转,这被证明更适合于学习[37]。联合优化公式可表示为:
$\Theta^{},\Pi^{}=\operatorname*{arg}_{\Theta,\Pi}\mathcal{L}(\Theta,\Pi),$
其中$Θ$为网络参数,$Π$为摄像机姿态。
Experiment
- 8张图片,每批1024条射线
- 当个A10 GPU 10 iter
- 在前5k次迭代中,学习率首先从0线性升温到$5×10^{−4}$,然后通过余弦衰减调度控制到最小学习率$2.5×10^{−5}$
- 对于所有数据集,我们设置λc为1.0,λe为0.1,λr为1.0。对于没有对象分割的数据集(OmniObject3D)或发生对象-场景遮挡的数据集(IHO-Video),我们将λm设置为0.0。相反,对于其他数据集,我们设置λm为0.1
- 如果分割蒙版可用,我们应用采样策略,以便在训练期间落在蒙版内的光量从50%逐渐增加到80%。
Empirical Evaluation - Hand-held Object Scan
“手持物体扫描” HOS
手持对象视频’ (IHO-Video)。
- IHO-Video Dataset
- HOS Task Evaluation
Evaluation on Public Datasets
- OmniObject3D
- OmniObject3D是一个全面的3D对象数据集,其特点是具有广泛的词汇表和大量高质量,实时扫描的3D对象。
- DTU
- BlendedMVS
- HOD Hand-held Object Dataset (HOD)
Quantitative Results
Ablation Study

实验
环境配置
1 | git clone https://github.com/Colmar-zlicheng/Color-NeuS.git |
运行
1 | # train |
Miku
python train.py -g 0 --cfg ./config/Color_NeuS_dtu.yml -obj Miku
大概需要8h左右
恢复训练,添加关机指令: && /usr/bin/shutdownpython train.py -g 0 --cfg ./config/Color_NeuS_dtu.yml -obj Miku --resume /root/autodl-tmp/Color-NeuS/exp/default_2023_0917_2027_15 && /usr/bin/shutdown
对自定义数据集的重建效果很差,无法实现很好的渲染,而且所需时间很长