| Title | Differentiable Volumetric Rendering: Learning Implicit 3D Representations without 3D Supervision |
|---|---|
| Author | Michael Niemeyer1,2 Lars Mescheder1,2,3† Michael Oechsle1,2,4 Andreas Geiger1,2 |
| Conf/Jour | CVPR |
| Year | 2020 |
| Project | autonomousvision/differentiable_volumetric_rendering: This repository contains the code for the CVPR 2020 paper “Differentiable Volumetric Rendering: Learning Implicit 3D Representations without 3D Supervision” (github.com) |
| Paper | Differentiable Volumetric Rendering: Learning Implicit 3D Representations without 3D Supervision (readpaper.com) |
Abstract
基于学习的三维重建方法已经显示出令人印象深刻的结果。然而,大多数方法需要3D监督,这通常很难获得真实世界的数据集。最近,一些研究提出了可微分渲染技术来训练RGB图像的重建模型。不幸的是,这些方法目前仅限于基于体素和网格的表示,受到离散化或低分辨率的影响。在这项工作中,我们提出了一种用于隐式形状和纹理表示的可微分渲染公式。隐式表征最近越来越受欢迎,因为它们连续地表示形状和纹理。我们的关键观点是深度梯度可以使用隐式微分的概念解析地推导出来。这允许我们直接从RGB图像中学习隐含的形状和纹理表示。我们的实验表明,我们的单视图重建可以与那些完全3D监督的学习相媲美。此外,我们发现我们的方法可以用于多视图三维重建,直接产生水密网格。
Introduction
近年来,基于学习的三维重建方法取得了令人瞩目的成果[12,13,17,24,41,48,49,56,64,80]。通过使用在训练过程中获得的丰富的先验知识,他们能够从单个图像中推断出3D模型。然而,大多数基于学习的方法都局限于合成数据,主要是因为它们需要精确的三维地面真值模型作为训练的监督。
为了克服这一障碍,最近的研究工作已经研究了只需要以深度图或多视图图像形式进行2D监督的方法。大多数现有方法通过修改渲染过程使其可微来实现这一点[4,11,15,21,33,36,43,44,47,50,58,59,62,75,76,79,88]。虽然产生令人信服的结果,但它们仅限于特定的3D表示(例如体素或网格),这些表示受到离散化伪影的影响,并且计算成本将它们限制在小分辨率或变形固定模板网格。同时,已经提出了形状和纹理的隐式表示[12,48,56][54,66],它们在训练过程中不需要离散化,并且具有恒定的内存占用。然而,使用隐式表示的现有方法需要3D ground truth进行训练,并且如何仅从图像数据中学习隐式表示仍然不清楚
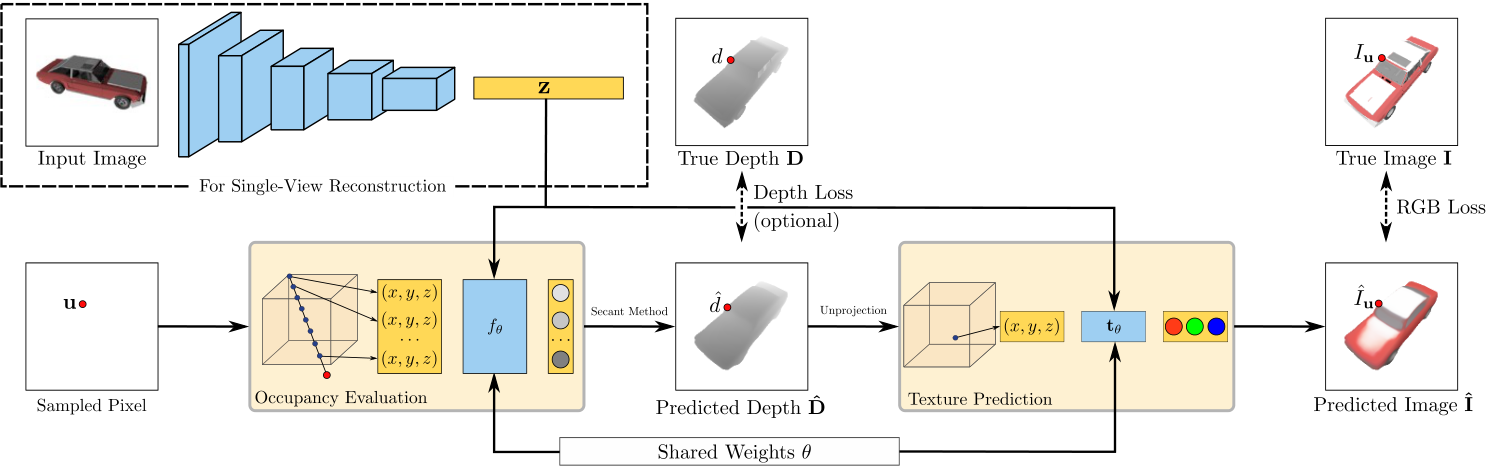
贡献:在这项工作中,我们引入了可微分体积渲染(DVR)。我们的关键见解是,我们可以根据隐式形状和纹理表示的网络参数推导出预测深度图的分析梯度(见图1)。这一见解使我们能够为隐式形状和纹理表示设计一个可微分的渲染器,并允许我们仅从多视图图像和对象蒙版中学习这些表示。由于我们的方法不需要在前向传递中存储体积数据,因此其内存占用与深度预测步骤的采样精度无关。我们表明,我们的公式可以用于各种任务,如单视图和多视图重建,并适用于合成和真实数据。与[54]相反,我们不需要将纹理表示限制在几何上,而是学习一个具有表示几何和纹理的共享参数的单一模型。我们的代码和数据提供在https://github.com/autonomousvision/可微分体绘制。
Related Work
3D Representations
基于学习的三维重建方法可以分为三类。它们使用的表示方式有基于体素的[8,13,19,61,64,73,82,83],基于点的[2,17,31,40,77,85],基于网格的[24,32,41,45,55,80],或者隐式表示[3,12,22,30,48,49,56,66,81]。体素可以通过标准深度学习架构轻松处理,但即使在稀疏数据结构上操作[23,64,74],它们也仅限于相对较小的分辨率。虽然基于点的方法[2,17,40,77,85]的内存效率更高,但由于缺少连接信息,它们需要密集的后处理。大多数基于网格的方法不进行后处理,但它们通常需要一个可变形的模板网格[80]或将几何形状表示为3D补丁的集合[24],这会导致自相交和非水密网格。
为了缓解这些问题,隐式表示越来越受欢迎[3,12,22,30,48,49,53,54,56,66,81]。通过隐式描述三维几何和纹理,例如,作为二值分类器的决策边界[12,48],它们不会离散空间,并且具有固定的内存占用。
在这项工作中,我们证明了隐式表示的体积渲染步骤是固有可微的。与之前的作品相比,这使我们能够使用2D监督学习隐含的3D形状和纹理表示。
3D Reconstruction
恢复在图像捕获过程中丢失的3D信息是计算机视觉的长期目标之一[25]。经典的多视图立体(MVS)方法[5 - 7,20,37,60,68 - 70]通常在相邻视图之间匹配特征[5,20,68]或在体素网格中重建三维形状[6,7,37,60,70]。虽然前一种方法产生深度图作为输出,但必须在有损的后处理步骤中进行融合,例如使用体积融合[14],后一种方法受到3D体素网格过度内存要求的限制。与这些高度工程化的方法相比,我们的通用方法直接在3D空间中输出一致的表示,可以很容易地转换为水密网格,同时具有恒定的内存占用。
最近,基于学习的方法[16,29,39,58,63,86,87]被提出,要么学习匹配图像特征[39],精炼或融合深度图[16,63],优化经典MVS管道的部分[57],要么用端到端训练的神经网络替换整个MVS管道[29,86,87]。与这些基于学习的方法相比,我们的方法可以仅从2D图像进行监督,并输出一致的3D表示。
Differentiable Rendering
我们专注于通过可微渲染学习3D几何的方法,而不是最近的神经渲染方法[42,51,52,71],后者合成高质量的新视图,但不推断3D物体。它们也可以根据它们所使用的3D几何图形的底层表示进行分类。
Loper等人[47]提出了OpenDR,它近似于传统的基于网格的图形管道的向后传递,并启发了后续的一些工作[11,21,27,28,33,44,88]。Liu等人[44]用软版本替换栅格化步骤,使其可微。虽然在重建任务中产生令人信服的结果,但这些方法需要一个可变形的模板网格进行训练,限制了输出的拓扑结构。
另一条工作线在体素网格上运行[46,50,57,79]。Paschalidou等人[57]和Tulsiani等人[79]提出了一种概率射线势公式。虽然提供了一个坚实的数学框架,但所有中间评估都需要保存以进行反向传播,这将这些方法限制在相对小分辨率的体素网格中。
Liu等人[45]提出通过在具有稀疏数量支持区域的光线交叉点上执行max-pooling来推断多视图轮廓的隐式表示。相比之下,我们使用纹理信息使我们能够改善视觉船体和重建凹形状。Sitzmann等人[72]通过基于lstm的可微分渲染器从RGB图像中推断出隐含的场景表示。在生成高质量的渲染图时,不能直接提取几何图形,需要存储中间结果以便计算梯度。相反,我们证明了体绘制对于隐式表示是固有可微的。因此,不需要为向后传递保存中间结果。
Method
在本节中,我们描述了我们的可微分体积渲染(DVR)方法。我们首先定义用于表示三维形状和纹理的隐式神经表示。接下来,我们提供了DVR的正式描述和所有相关的实现细节。图2概述了我们的方法
Conclusion
在这项工作中,我们提出了可微分体积渲染(DVR)。观察到体绘制对于隐式表示是固有可微的,这使我们能够为相对于网络参数的深度梯度制定一个解析表达式。我们的实验表明,DVR使我们能够在没有3D监督的情况下从多视图图像中学习隐式3D形状表示,与完全3D监督学习的模型相媲美。此外,我们发现我们的模型也可以用于多视图三维重建。我们认为DVR是一种有用的技术,它拓宽了隐式形状和纹理表示的应用范围。在未来,我们计划研究如何规避对物体蒙版和相机信息的需求,例如,通过预测软蒙版,以及如何不仅估计纹理,还估计更复杂的材料属性。