| Title | Human Performance Modeling and Rendering via Neural Animated Mesh |
|---|---|
| Author | Fuqiang Zhao, Yuheng Jiang, Kaixin Yao, Jiakai Zhang, Liao Wang, Haizhao Dai, Yuhui Zhong, Yingliang Zhang Minye Wu, Lan Xu, Jingyi Yu |
| Conf/Jour | SIGGRAPH Asia 2022 |
| Year | 2022 |
| Project | Human Performance Modeling and Rendering via Neural Animated Mesh (zhaofuq.github.io) |
| Paper | Human Performance Modeling and Rendering via Neural Animated Mesh (readpaper.com) |
可以理解为对Neus使用多分辨率哈希编码进行加速
- 使用TSDF代替SDF
- 有限差分函数计算SDF的梯度,在tiny-CUDAnn并未集成,公开了自己的CUDAC++代码
不足:
- 数据集需要手动mask
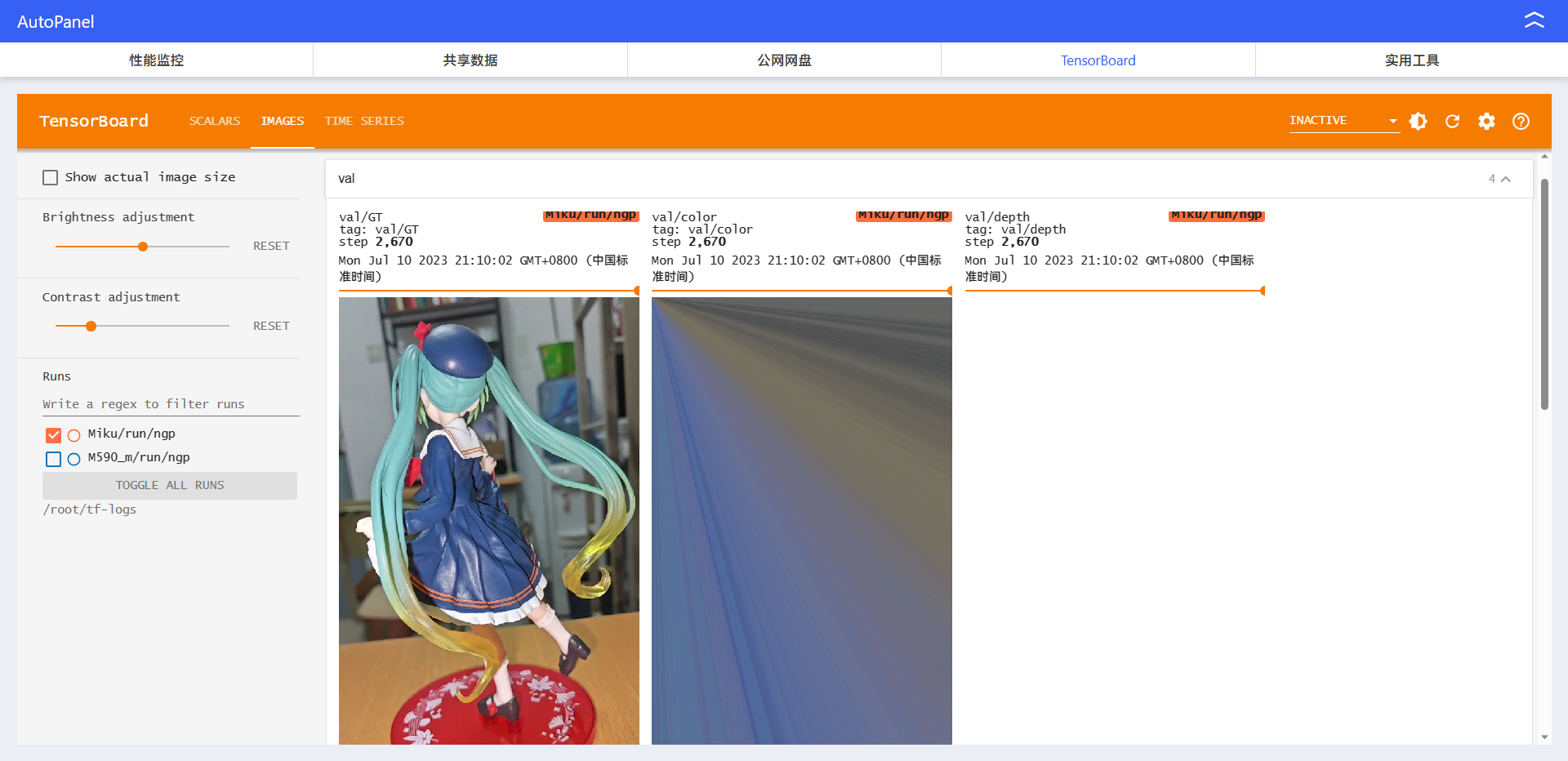
数据集图片:
论文
Abstract
将truncated(截断) signed distance field(TSDF)与multi-resolution hash encoding结合在一起
进一步提出了hybrid neural tracker混合神经追踪器生成动画的meshs
- 它将显式非刚性跟踪与隐式动态变形结合在一个自监督框架中
- 前者提供coarse扭曲回规范空间
- 后者则使用与我们的重构器中的4D哈希编码相同的隐式方式进一步预测位移
我们讨论了使用获得的动画网格的渲染方案,从动态纹理到在各种带宽设置下的透视渲染。为了在质量和带宽之间取得复杂的平衡,我们提出了一种分层解决方案:
- 首先渲染覆盖表演者的6个虚拟视图,然后进行遮挡感知的神经纹理混合。我们在各种基于网格的应用程序和各种平台上展示了我们方法的有效性,例如通过移动AR将虚拟人表演插入真实环境,或者通过VR头显身临其境地观看才艺展示。
ACM分类:Computing methodologies → Computational photography; Image-based rendering.
Keywords:virtual human, neural rendering, human modeling, human performance capture
Introduction
目标:在VR or AR场景中,可以身临其境地观看人类表演。具体而言,用户可以像与表演者面对面一样进行互动,简单到改变视角,复杂到通过触手可及的方式进行内容编辑。
目前显式重建方法的不足:迄今为止,生成体积人类表演的最广泛应用工作流程仍然是通过重建和跟踪动态网格,并为每一帧贴上纹理贴图。实际上,无论是基于摄影测量的重建还是基于3D扫描的重建仍然耗时,并容易受到遮挡和缺乏纹理的影响,从而导致产生洞和噪声。为了满足最低程度的沉浸式观看要求,最终重建的序列需要经验丰富的艺术家进行大量修复工作。
NeRF: 静态场景和动态场景
- 静态场景通过多个观察视图,绕过显式重建,专注合成逼真的新视图
- [Lombardi等,2019; Tewari等,2020; Wu等,2020]
- [Mildenhall等,2020] NeRF用MLP取代了传统的几何和外观概念
- 最初的NeRF及其加速方案[Müller等,2022; Yu等,2021a]主要关注静态场景
- 动态场景中的实时渲染需要在空间和质量之间达到复杂的平衡
- [Peng等,2021b; Tretschk等,2020; Zhang等,2021; Zhao等,2022]旨在将这种神经表示扩展到具有时间作为潜在变量的动态场景中
- 空间[Müller等,2022; Sara Fridovich-Keil和Alex Yu等,2022; Yu等,2021a]
- 质量[Suo等,2021; Wang等,2022]
- 在可动人类角色的背景下,也可以通过将参数化人体模型作为先验条件[Bagautdinov等,2021; Habermann等,2021; Liu等,2021; Xiang等,2021]来生成神经角色。然而,它们的最终质量在很大程度上依赖于预扫描或参数化模板和繁琐耗时的每个角色训练。
目前的神经方法提取出来的mesh不适应现有的基于网格的动画流水线:
- 神经方法的另一个主要挑战是它们的结果,即经过训练的神经网络,不能直接支持现有的基于网格的动画流水线,无论是流媒体还是渲染。尽管可能可以从网络中提取网格,例如通过对NeRF的密度场进行阈值处理,然后进行三角剖分,但所产生的几何形状往往过于嘈杂,无法适应先前的基于网格的流水线[Collet等人,2015年]。
将NeRF的密度场换成SDF,可以得到高质量mesh,但是仍然很费时:(例如Neus)
- 开创性的神经隐式表面[Munkberg等人,2021年;Wang等人,2021a]在体积渲染公式中将密度场替换为有符号距离场(SDF),可以恢复出非常高质量的几何形状。然而,这些方法仍然需要很长的训练时间,无法扩展以生成动态网格序列。事实上,即使可以重构网格序列,很少有工作强调应用基于神经网络的网格压缩来支持流媒体或高质量播放的神经渲染。
本文方法
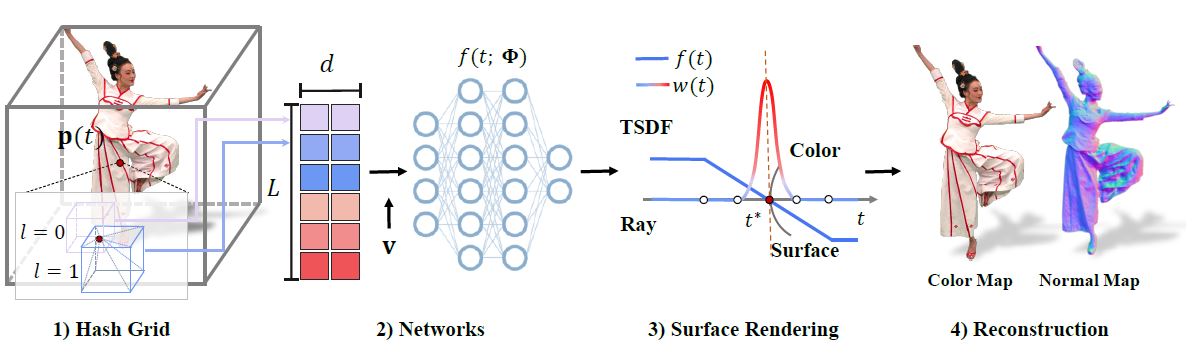
我们提出了一个全面的神经建模和渲染流程,用于支持多视角摄像机球顶捕捉的人类表演的高质量重建、压缩和渲染。我们遵循传统的动画网格工作流程,但采用一种新的高效神经技术类别,如图1所示。
- InstantNGP+Neus:具体而言,在网格重建方面,我们提出了一种高度加速的神经表面重建器Instant-NSR,类似于InstantNGP [Müller等,2022],但基于NeuS [Wang等,2021a]的SDF体积公式进行表面重建。
- TSDF:我们发现直接采用多分辨率哈希编码可能会导致梯度爆炸问题,因此无法在基于特征哈希的网络优化的早期迭代中稳定收敛。相反,我们提出了截断SDF(TSDF)公式,该公式在先前的3D融合框架[Newcombe等,2015,2011]中得到应用,并通过Sigmoid映射实现。我们的开源PyTorch实现将训练时间从NeuS的8小时缩短到10分钟,并且具有相当的质量。
- 我们还提出了一种基于有限差分的CUDA实现,用于近似估计法线,这可以进一步缩短训练时间,但质量略有降低。
动画的meshs:
我们应用Instant-NSR生成高质量的网格序列,然后开始对几何进行压缩,并使用动画网格编码时间对应的信息。具体来说,我们引入了一个混合神经跟踪器,将显式的非刚性跟踪和隐式的动态变形结合在一个自监督框架中。
- 在显式阶段,我们采用了基于嵌入变形的快速非刚性跟踪方案[Newcombe等人,2015年;Xu等人,2019b]。它从各个帧生成粗糙的初始变形,以维持高效率。
- 在隐式阶段,我们学习规范空间中4D坐标(3D变形位置+1D时间戳)的每个顶点位移,以保留精细的几何细节。我们再次采用CUDA核心的4D哈希编码方案和Instant-NSR中的体积渲染公式,以进行快速和自监督训练,以获得动画网格。
渲染方面:
粗暴的方法是采用动态纹理[Collet等人,2015; UVAtlas 2011]来支持流式沉浸式体验。
相反,我们讨论了在不同带宽设置下的策略,从在整个序列中使用单个纹理映射到从所有圆顶摄像头流式传输视频以进行高质量的图像重建[Buehler等人,2001]。我们展示了一种妥协方案,首先渲染涵盖不同观察者视角的6个虚拟视图,然后进行神经纹理混合,考虑遮挡和视角依赖性,以在质量和带宽之间实现复杂的平衡。最后,我们展示了各种虚拟和增强现实应用的内容播放,包括在移动AR平台上将虚拟人类表演插入真实环境,以及使用VR头显沉浸式地观看超高质量的才艺表演节目。
总结
总结起来,我们的主要贡献包括:
- 我们引入了一种新颖的流程,以在神经时代era始终更新动态人物表演的建模、跟踪和渲染,在效果和效率两方面都与现有系统相比具有优势。
- 我们提出了一种快速的神经表面重建方案,通过将TSDF体积渲染与哈希编码相结合,在几分钟内生成高质量的隐式表面。
- 我们提出了一种混合神经跟踪方法,以自我监督的方式将显式和隐式的运动表示相结合,生成与传统制作工具兼容的动画网格。
- 我们提出了一种分层神经渲染方法,用于逼真的人物表演合成,并展示了我们的流程在各种基于网格的应用和沉浸式自由视角虚拟现实/增强现实体验中的能力。
RelatedWork
神经人类建模
Neural Human Modeling
- 神经隐式表示最近作为传统场景表示(如网格、点云和体素网格)的有希望替代方法出现。由于其连续性特点,神经隐式表示在理论上可以以无限分辨率渲染图像。最近,NeRF(Mildenhall等,2020)及其后续工作(Chen等,2021a,b; Park等,2021; Peng等,2021b; Pumarola等,2021; Tiwari等,2021; Wang等,2021c,b,d; Zhang等,2021; Zhao等,2022)利用体积表示,通过对5D坐标表示进行光线行进计算辐射。基于经典的体积渲染技术,它们在新视角合成方面取得了令人印象深刻的结果。然而,由于体积渲染的模糊性(Zhang等,2020),这些方法仍然受到几何质量较低的影响。
- 一些基于表面渲染的方法(Niemeyer等,2019, 2020; Saito等,2021; Yariv等,2020)尝试通过隐式微分获得梯度,直接优化底层表面。
- UNISURF(Oechsle等,2021)是一种混合方法,通过体积渲染学习隐式表面,并鼓励体积表示收敛到一个表面。
- 与UNISURF不同,NeuS(Wang等,2021a)提供了从符号距离函数(SDF)到体积渲染密度的无偏转换。UNISURF通过占用值表示表面,并逐渐减少一些预定义步骤中的采样区域,使占用值收敛到表面,而NeuS通过SDF表示场景,因此表面可以作为SDF的零水平集自然提取,从而比UNISURF具有更好的重建精度。
- 所有这些方法的共同点是它们依赖于NeRF训练过程,在渲染过程中在网络上进行光线行进推理,这在训练和推理过程中计算量很大。因此,它们只适用于静态场景重建,无法处理需要无法接受的训练时间的动态场景。
- 最近,一些NeRF扩展(Müller等,2022; Sara Fridovich-Keil和Alex Yu等,2022; Wang等,2022; Yu等,2021a; Zhang等,2022)被提出以加速NeRF的训练和渲染,但未加速隐式表面重建。最近的一项研究(Munkberg et al.,2021)通过利用高效可微分光栅化来优化显式网格表示,但仍需要几个小时的训练时间。我们的目标是提出一种快速的隐式表面重建方法,只需要几分钟的训练时间,并利用多视角图像进行重建。
人类行为捕捉
Human Performance Capture.
- 最近,通过传统的非刚性融合流程提出了具有实时性能的自由形态动态重建。从开创性的作品DynamicFusion [Newcombe等,2015年]开始,它通过GPU求解器和先进的多摄像头系统获益,Fusion4D [Dou等,2016年]和motion2fusion [Dou等,2017年]将非刚性跟踪流程扩展到具有挑战性动作的动态场景捕捉。
- KillingFusion [Slavcheva等,2017年]和SobolevFusion [Slavcheva等,2018年]对运动场提出了更多约束,以支持拓扑变化和快速帧间运动。
- DoubleFusion [Yu等,2019年]通过添加身体模板SMPL [Loper等,2015年]作为先验知识,将内部身体和外部表面组合在一起,更稳健地捕捉人体活动。
- 得益于人体运动表示,UnstructuredFusion [Xu等,2019b年]实现了非结构化多视角设置。
- Function4d [Yu等,2021b年]将时间体积融合与隐式函数相结合,生成完整的几何形状,并能处理拓扑变化。
- 然而,这些方法都利用了深度传感器精度有限的深度图。与此同时,这些方法及其后续工作[Jiang等,2022b年; Xu等,2019b年; Yu等,2021b年]对RGB和深度传感器的校准非常敏感。
- 基于数字人体建模,一些先前的工作通过网格压缩探索支持自由视点视频。实现几何一致性压缩的关键是可靠地建立存储为3D网格序列的所有帧之间的对应关系。在行为捕捉的背景下,由于大规模非刚性变形随时间容易失去跟踪,这个任务仍然具有挑战性。拓扑变化和退化重构(例如,无纹理区域)导致额外的问题。现有的仅考虑形状的描述符[Litman和Bronstein 2013;Windheuser等,2014]对噪声敏感,而密集形状对应要求拓扑一致性,主要应用于零亏格表面。早期的匹配方案采用了强假设,包括等距或共形几何、测地线或扩散约束、局部几何一致性等,在马尔可夫随机场(MRF)或随机决策森林(RDF)框架下进行。最近的神经方法尝试从多视深度图或全景深度图中训练特征描述符,以分类不同的身体区域,以提高鲁棒性。
- 一旦构建完成,动画网格可以被有效压缩以进一步节省存储空间。基于主成分分析(PCA)的方法[Alexa和Müller 2000;Luo等人2013;Vasa和Skala 2007]旨在识别人体的不同几何集群(手臂、手、腿、躯干、头等),而[Gupta等人2002;Mamou等人2009]在网格上进行预分割以确保连接的一致性。时空模型可以进一步预测顶点轨迹以形成顶点组[Mamou等人2009;Ibarria和Rossignac 2003;Luo等人2013]。然而,一个被大部分忽视的问题是序列的渲染:在传统的计算机图形中,一个具有足够分辨率的单一预渲染纹理就足够渲染序列中的所有网格。然而,在真实捕捉到的序列中,由于遮挡、相机的校准误差以及颜色或光照不一致,几乎不可能产生具有可比质量的单一纹理。此外,使用单一纹理映射会失去视角依赖性。相反,我们的方法通过多视角RGB图像恢复人体几何形状,并通过传统的管线和神经形变网络进行非刚性跟踪,从而能够自然地处理人体活动。
单一视角恢复物体的纹理,质量很低
- 在传统的计算机图形中,一个具有足够分辨率的单一预渲染纹理就足够渲染序列中的所有网格
- 然而,在真实捕捉到的序列中,由于遮挡、相机的校准误差以及颜色或光照不一致,几乎不可能产生具有可比质量的单一纹理
- 此外,使用单一纹理映射会失去视角依赖性
- 相反,我们的方法通过多视角RGB图像恢复人体几何形状,并通过传统的管线和神经形变网络进行非刚性跟踪,从而能够自然地处理人体活动
神经人类渲染
Neural Human Rendering
- 在逼真的新颖视图合成和3D场景建模领域,基于不同数据代理的可微神经渲染取得了令人印象深刻的结果,并变得越来越受欢迎。采用各种数据表示以获得更好的性能和特性,如点云[Aliev等,2020; Suo等,2020; Wu等,2020],体素[Lombardi等,2019],纹理网格[Liu等,2019; Shysheya等,2019; Thies等,2019]或隐式函数[Kellnhofer等,2021; Mildenhall等,2020; Park等,2019]和混合神经融合[Jiang等,2022a; Sun等,2021; Suo等,2021]。
- 最近,[Li等,2020; Park等,2020; Pumarola等,2021; Wang等,2022]将神经辐射场[Mildenhall等,2020]扩展到动态环境中。
- [Hu等,2021; Peng等,2021a,b; Zhao等,2022]利用人类先验SMPL[Loper等,2015]模型作为锚点,并使用线性混合蒙皮算法来扭曲辐射场。
- 此外,[Jiang等,2022a; Sun等,2021]将动态神经渲染和融合扩展到人类物体交互场景中。
- 然而,对于上述绝大多数方法来说,仍然需要密集的空间视图以实现高保真度的新视图渲染。基于图像的融合方法学习相邻视图的融合权重,并以轻量级方式合成逼真的新视图。
- [Wang等,2021b]学习融合权重以获得泛化能力。
- [Suo等,2021]使用遮挡地图作为融合权重估计的指导。
- [Jiang等,2022a]将基于图像的融合与每顶点纹理结合起来解决遮挡问题。
- 相比之下,我们的神经融合方案结合了通过规范空间渲染获得的时空信息,同时将内存压缩到极限,也能确保融合结果的保真度。
InstantNSR
INSTANT NEURAL SURFACE RECONSTRUCTION
体渲染函数形式
NeRF:通过输入(𝑥, 𝑦, 𝑧, 𝜃, 𝜙)来获得$\sigma$和RGB值
Neus:用SDF代替了$\sigma$场,从而实现了更确定和准确的几何形状提取
本文采用NeRF类似体渲染方式,通过沿着光线累加n个采样点的几何和外观属性来获得像素的颜色值Color,然而SDF的表示中没有定义$\sigma$ 。本文遵循Neus将密度替换为不透明度密度$\rho(t)$,基于采样点位置$\mathbf{p}(t)$和累计密度分布CDF:$\Phi_s(x) = \frac{1}{1+e^{-bx}}$,其中b为inv_s是可以训练的超参数,随着网络训练的收敛,逐渐增加到较大数量。
体渲染函数与Neus类似:
$\rho(t)=\max\left(\frac{-\frac{\mathrm{d}\Phi_s}{\mathrm{d}t}(f(\mathbf{p}(t)))}{\Phi_s(f(\mathbf{p}(t)))},0\right)$
$\alpha_i=\max\left(\frac{\Phi_s(f(\mathbf{p}(t_i))))-\Phi_s(f(\mathbf{p}(t_{i+1})))}{\Phi_s(f(\mathbf{p}(t_i)))},0\right) =\max\left(1 - \frac{\Phi_s(f(\mathbf{p}(t_{i+1})))}{\Phi_s(f(\mathbf{p}(t_i)))},0\right)$
$\hat{C}=\sum_{i=1}^n T_i\alpha_i c_i$,离散累计透射率:$T_i=\prod_{j=1}^{i-1}(1-\alpha_j)$
Truncated SDF Hash Grids
在这里,我们引入了一种类似于Instant-NGP的神经表面重构器InstantNSR,它可以从密集的多视图图像中高效地生成高质量的表面。哈希编码提供了高效的表示学习和查询方案,TSDF表示可以大大提高网络训练的稳定性。
具体而言,给定光线上的样本点 p(t),我们首先通过插值从 L 级哈希网格的八个顶点处获取特征向量。我们将获取的特征向量连接成 $Fhash ∈ R^{𝐿×𝑑}$,然后将其输入到我们的 SDF 网络$m_{s}$中,该网络由一个浅层的 MLP 组成。$m_{s}$输出样本点的 SDF 值 𝑥
$m_{s}$训练SDF的网络表示为:$(x,F_{geo})=m_{s}(p,F_{hash}).$
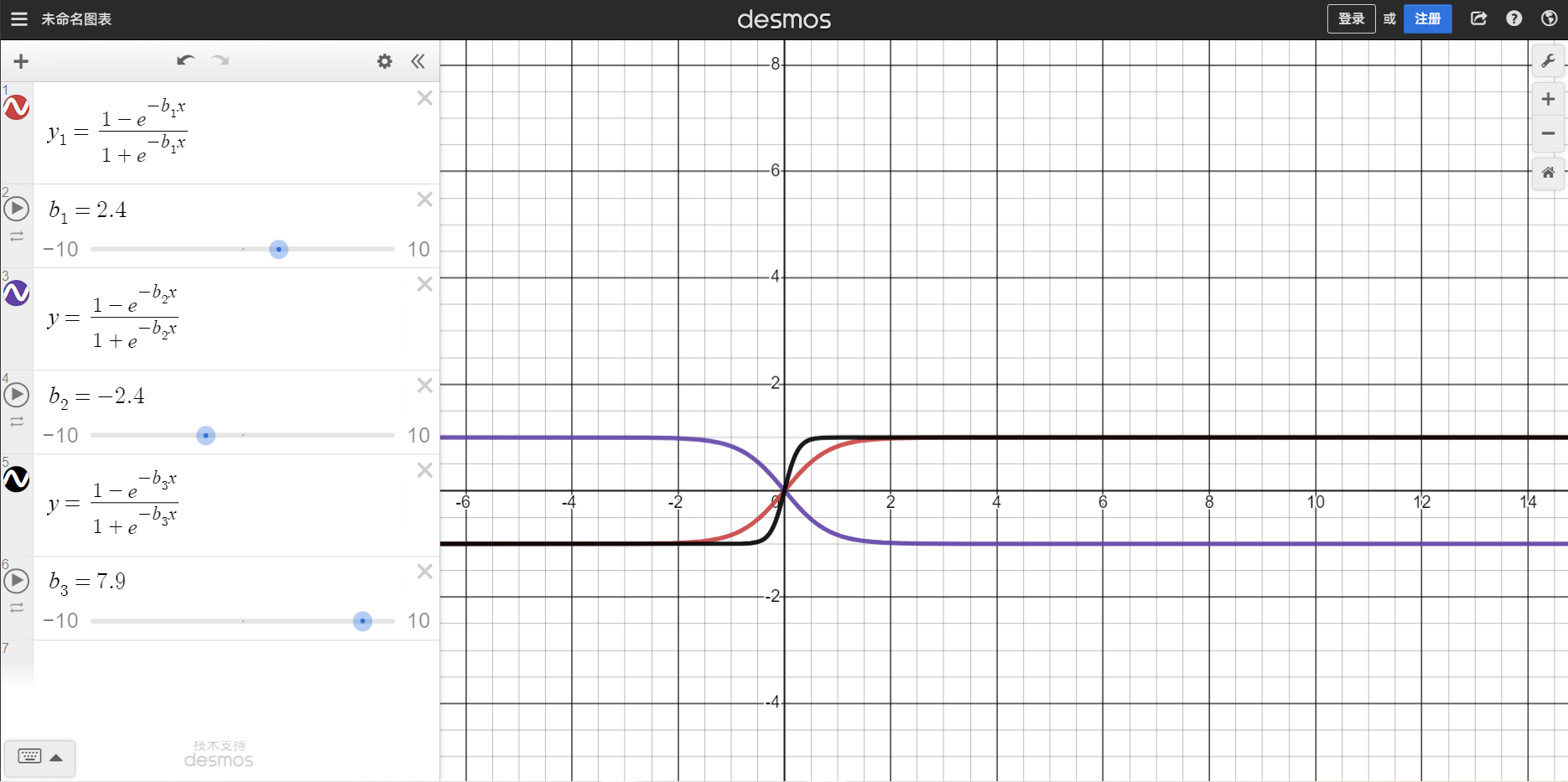
单纯地将SDF表示应用于哈希编码框架将在优化过程中引入几个收敛问题。原始的基于SDF的方法利用累积密度分布$\Phi_s(x) = \frac{1}{1+e^{-bx}}$来计算alpha值,这会产生数值问题。当𝑏增加时,术语−𝑏𝑥将成为一个较大的正数,并使得$𝑒^{−𝑏𝑥}$接近无穷大。这种数值不稳定性使得损失函数在训练过程中很容易发散。
为了避免$\Phi_s(x)$中的值溢出,我们引入截断有符号距离函数(TSDF),表示为$\hat x$。由于TSDF的值范围为-1到1,这种修改确保了数值稳定性。我们将SDF输出应用于Sigmoid函数𝜋(·),而不是直接截断SDF,以实现更好的收敛性并避免梯度消失问题。
$\pi(x)=\frac{1-e^{-bx}}{1+e^{-bx}}.$, 此时$\Phi_s(x) = \frac{1}{1+e^{-b \cdot \pi(x)}}$
类似于Instant-NGP [Müller et al. 2022],我们将样本点的几何编码$𝐹_{𝑔𝑒𝑜}$、位置p和视线方向v输入到一个颜色网络$𝑚_{𝑐}$中,以预测其颜色$\hat C$。此外,我们还将点的法线n作为输入的一部分。法线即为SDF的梯度。引入n的原因是为了隐式地对输出的SDF进行规范化,基于这样一个观察:如果邻近采样点的法线也相近,颜色网络倾向于输出相似的颜色。由于我们将法线定义为SDF的一阶导数,法线的梯度可以反向传播到SDF中。将法线添加到输入中可以使重建的表面更加平滑,尤其是对于无纹理区域。
$m_{c}$训练颜色的网络表示为:$\hat{C}=m_{c}(\mathrm{p},\mathrm{n},\mathrm{v},F_{geo}).$
损失函数loss
对于类似于Instant-NGP的基于CUDA的加速,我们采用有限差分函数来近似计算方程6和8中的梯度,以实现高效的法线计算。这种策略避免了繁琐的二阶梯度反向传播,而这在现有的库如tiny-CUDAnn [Müller 2021]中仍然没有得到完全支持。为了促进更加忠实的CUDA实现的未来工作,我们将公开发布我们的版本。
神经动画网格
NEURAL ANIMATION MESH
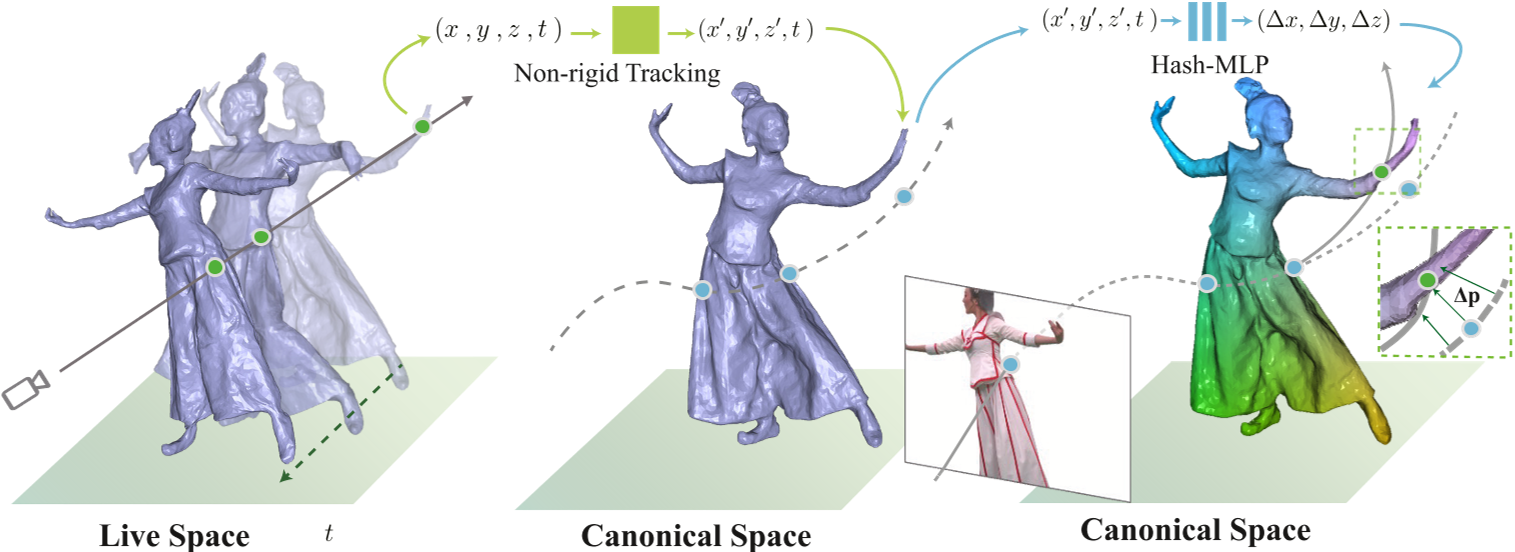
尽管我们的快速神经表面重建(第3节)为渲染提供了高精度的几何图形,但由于内存占用大,单独保存每帧的几何图形效率低下,限制了应用范围。为此,我们着手从高精度几何结构中构建拓扑一致的网格,以进一步压缩数据,并启用时间编辑效果。动画网格的生成是基于查找帧之间的几何对应关系。如图5所示,我们提出了一种神经跟踪管道,将非刚性跟踪和神经变形网络以粗到细的方式结合在一起。它包括如下所述的两个阶段
粗追踪阶段
Coarse Tracking Stage
在粗跟踪阶段,我们采用传统的非刚性跟踪方法[Guo等,2015年;Jiang等,2022年a;Newcombe等,2015年;Xu等,2019年a,b;Yu等,2019年]基于嵌入变形的方法来建立粗略对应关系。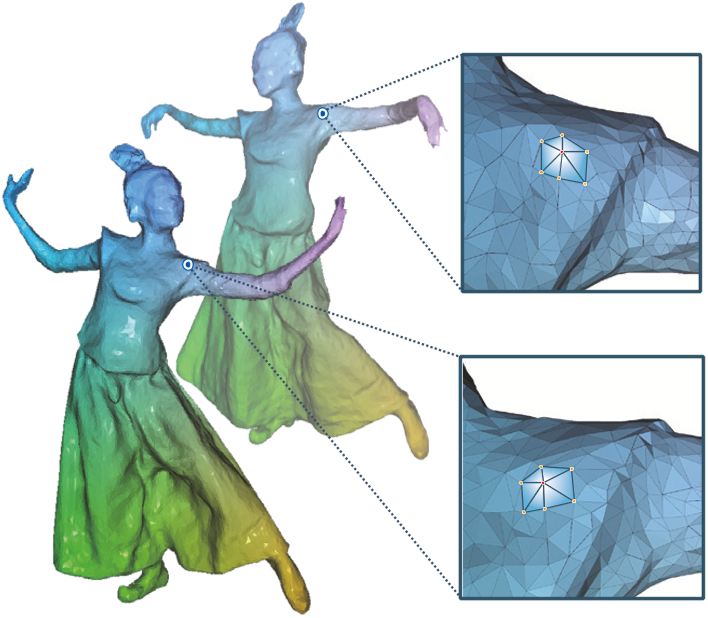
如图4所示,我们在第一帧建立一个规范空间,并将第一帧的重建结果作为跟踪参考的规范网格。基于基于图形的表示方法[Newcombe等,2015年],我们通过计算规范网格上的测地线距离均匀采样嵌入变形(ED)节点[Sumner等,2007年],并使用这些节点驱动其进入目标帧。同时,我们用ED节点对人体运动$𝐻 = \{ 𝑇_{𝑖} , 𝑥_{𝑖} \}$进行参数化,其中$𝑥_{𝑖}$是采样的ED节点坐标,$𝑇_{𝑖}$是刚性变换。一旦获得优化的运动𝐻,我们可以使用线性混合蒙皮(LBS)[Loper等,2015年]将规范网格的顶点转换到实时空间:
$\mathrm{v’}_j=\sum_{i\in\mathcal{N}(\mathrm{v}_j)}\omega(\mathrm{x}_i,\mathrm{v}_j)T_i\mathrm{v}_j.$
在规范网格上,$v_{𝑗}$ 是一个顶点,$N(v_{𝑗})$ 表示顶点的相邻 ED 节点
$\omega(\mathrm{x}_{i},\mathrm{v}_{j})=\left(1-\left|\mathrm{v}_{j}-\mathrm{x}_{i}\right|_{2}^{2}/r^{2}\right)^{3}$ 是第𝑖个节点 $𝑥_{𝑖}$对$𝑣_{𝑗}$ 的影响权重。𝑟 是影响半径,在我们的实验中设置为 0.075。
变形场估计
Warping Field Estimation
然而,由于规范帧和当前帧之间存在较大的运动差异,直接计算两者之间的运动𝐻是不现实的,这将导致非刚性跟踪失败。相反,我们跟踪相邻帧,然后将优化后的局部变形场𝑊传播到规范空间,以获得每帧的运动𝐻。遵循传统的非刚性跟踪流程[Li et al. 2009; Newcombe et al. 2015],我们使用非刚性迭代最近点(ICP)算法在帧𝑡 − 1和帧𝑡之间搜索点对点和点对平面的对应关系。由于我们已经有每帧的几何信息,我们可以直接使用几何信息进行跟踪,而不是使用深度输入。
利用几何信息作为输入的优势有两个方面:
- 首先,它可以防止融合算法受到深度传感器引起的输入噪声的干扰;
- 其次,我们能够在欧拉空间中建立初始的局部对应关系,以进行跟踪优化,而不仅仅在单个射线上找到对应关系[Newcombe et al. 2011]。
用于优化变形场𝑊𝑡的能量函数被定义为:
$E(W_t,V_{t-1},M_t,G)=\lambda_\text{data}E_\text{data}(W_t,V_{t-1},M_t)+\lambda_\text{reg}E_\text{reg}(W_t,G),$在这里 $𝑉_{𝑡 −1}$ 是使用扭曲场$𝑊_{𝑡 −1}$ 从规范空间变形的动画网格;$𝑀_{𝑡}$ 是从(第3节)获得的当前帧的重构几何体。数据项用于最小化拟合误差,公式为:
$E_{\mathrm{clata}}=\sum_{\mathrm{v}_{j}\in C}\lambda_{\mathrm{point}}\left|\mathrm{v’}_{j}-\mathrm{c}_{j}\right|_{2}^{2}+\lambda_{\mathrm{plane}}\left|\mathrm{n}_{\mathrm{c}_{j}}^{\mathrm{T}}\left(\mathrm{v’}_{j}-\mathrm{c}_{j}\right)\right|^{2},$其中$v’_𝑗$是从规范空间变换得到的变形顶点 $v_𝑗$,$c_𝑗$ 是当前帧网格上的对应顶点。C 表示从非刚性 ICP 中获取的初始对应顶点对集合。权重 𝜆 用于平衡不同项的相对重要性。在我们的实验中,我们设置:
$𝜆_{data} = 1,𝜆_{reg} = 20,𝜆_{point} = 0.2 和 𝜆_{reg} = 0.8$为了约束ED节点运动的平滑性,我们采用了局部尽可能刚性的正则化方法:
$E_{\mathrm{reg}}=\sum_{\mathrm{x}_{i}}\sum_{\mathrm{x}_{j}\in\mathcal{N}(\mathrm{x}_{i})}\omega\left(\mathrm{x}_{i},\mathrm{x}_{j}\right)\psi_{\mathrm{reg}}\left\Vert\mathrm{T}_{i}\mathrm{x}_{i}-\mathrm{T}_{j}\mathrm{x}_{i}\right\Vert_{2}^{2},$
其中$x_𝑖,x_𝑗$是共享ED图𝐺上边的ED节点。$𝜔 (x_𝑖,x_𝑗)$定义了边的权重。$T_𝑖,T_𝑗$是ED节点的变换。$𝜓_𝑟𝑒𝑔$是保持不连续性的Huber惩罚项。然后我们通过GPU上的Gauss-Newton求解器来解决非线性最小二乘问题。更多细节请参考[Newcombe et al. 2015; Yu et al. 2019]。
追踪细化阶段
Tracking Refinement Stage
我们的显式粗糙非刚性跟踪阶段在复杂运动方面具有表现力强的表示能力,但仍然受到自由度的限制。因此,在细化阶段,我们采用了一种称为变形网络的神经方案,为几何跟踪提供更多的自由度,纠正不对齐问题并保留细粒度的几何细节,这是对现有工作的重大进展[Newcombe等人,2015年;Slavcheva等人,2017年;Xu等人,2019年b;Yu等人,2018年]。
我们采取两个步骤来实现这个目标:
- 首先,我们利用原始的Instant-NGP [Müller等人,2022年]以快速方式在规范空间中获得辐射场$𝜙^{𝑜}:(c, 𝜎) = 𝜙^𝑜(p, d)$,其中c表示颜色场,𝜎表示密度场,p是规范空间中的点,d是射线方向。在获得这个辐射场之后,我们冻结模型参数。
- 其次,我们训练一个变形网络$𝜙^𝑑$来预测每帧的变形位移,并进一步微调帧的运动𝐻。第二步的核心是建立粗糙运动估计和光度损失方案之间的联系,以便我们可以使用输入图像在端到端监督中优化变形位移。我们引入了可微分的体渲染管线,与跟踪的ED节点合作实现监督。
由于存在粗糙的运动𝐻,我们将规范帧中的ED节点转换为当前帧,并沿着目标视图的像素射线采样点。对于每个样本点p,我们找到其𝑘个最近的ED节点,并插值它们的反变形以回到规范空间。规范空间中的变形点表示为p’。我们将p’和当前帧的时间戳𝑡作为变形网络$𝜙^𝑑$的输入。网络$𝜙^𝑑$将预测位移Δp’。我们采用哈希编码方案[Müller等人,2022年]对$𝜙^𝑑$进行编码,以使其训练和推理高效。样本点p的密度和颜色的计算如下:
$\mathrm{(c,\sigma)=\phi^{o}(p’+\phi^{d}(p’,t),d).}$
动画网格生成
Animation Mesh Generation
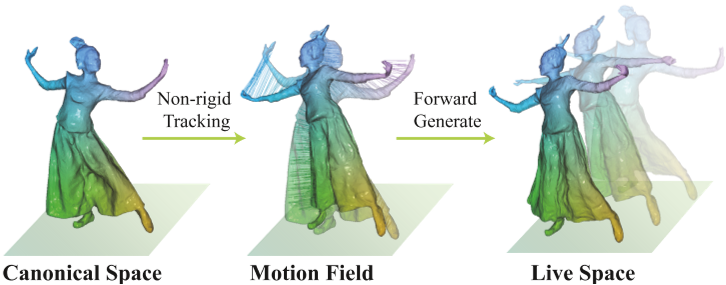
使用变形网络可以为我们提供从当前帧到规范帧的更好对应关系。我们可以利用细粒度的对应关系作为非刚性跟踪算法中更好的先验信息,重新优化运动为𝐻 ′。为了生成当前帧的动画网格,我们只需要将𝐻 ′ 应用于规范网格的顶点,并保持拓扑关系不变。
如图6所示,我们利用精细的变形场参数来跟踪和获取实时帧的动画网格。与保存原始网格序列和网络参数不同,我们只需要保存规范网格和运动场,以支持回放、实时渲染和编辑。
渲染
RENDERING
神经动画网格重建提供准确的几何信息,能够为各种渲染方法(如纹理网格渲染和基于图像的渲染)提供高质量的渲染效果。这些方法可以基于我们的神经动画网格在新视角下产生逼真的图像质量,但是要么缺乏视角相关的效果,要么需要大量的参考视角存储空间。
在本节中,我们提出了一种结合了显式二维纹理映射和隐式神经纹理混合的方法,该方法能够流式传输并保持高渲染质量。为此,我们的方法通过降低4D视频序列的比特率来实现流式应用,并旨在具有更低的存储需求。
外观蒸馏
Appearance Distillation
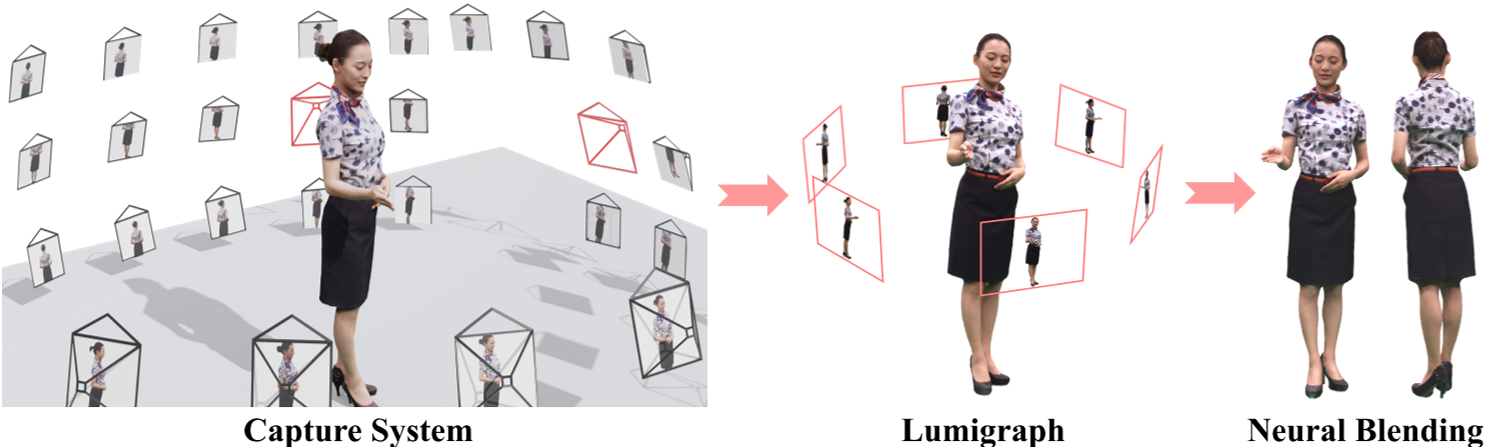
请注意,我们的神经动画网格可以减少几何存储空间,但我们仍然有数十个参考视图,其视频需要存储空间。关键的想法是将所有参考视图的外观信息浓缩到更少的图像中。我们通过基于图像的渲染来实现这个目标。具体而言,我们预先定义了六个虚拟视点,均匀地围绕并朝向中心的表演者。这些视图具有足够的视场角,以便在图中显示的视图中可以看到整个表演者,如图8所示。我们使用无结构光图法[Gortler et al. 1996]来合成这些视图图像,该方法根据给定的几何计算相邻参考视图的像素混合。合成的视图通过从不同的身体部位和其他视图混合像素来编码原始参考视图的外观信息。以这种方式需要存储的视图数量减少到六个。然而,这种减少会导致信息丢失,从而降低蒸馏过程中结果的质量。因此,我们使用神经网络部署了一种神经混合方法来补偿信息损失。
神经混合
Neural Blending
我们引入了一种神经混合方案,可以将相邻虚拟视图中的细粒度纹理细节混合到新视图中。与[Suo等人,2021]类似,神经混合的输入不仅包括目标相机的两个相邻视图,还包括它们的深度图以实现遮挡感知。然而,由于视图稀疏性,一些自遮挡部分可能无法通过任何相邻的虚拟视图观察到。为了填补新视图中的这种区域,我们还采用了纹理动画网格渲染结果作为混合组件的一部分。图9展示了我们混合模块的流程。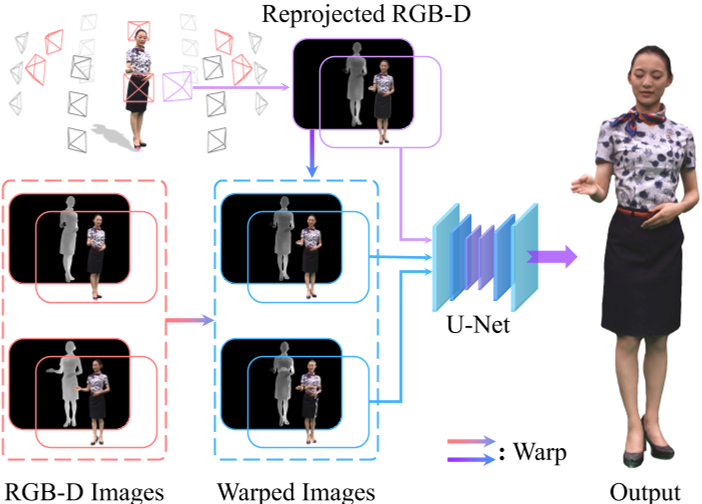
遮挡感知:目标视图中的大部分外观信息可以通过其两个相邻的虚拟视图观察到,由于自遮挡而导致的缺失部分可以在我们的稀疏视图重新渲染设置中使用2D纹理图进行恢复。基于这个假设,我们提出了一种混合方法,通过使用选定的视图通过混合网络重新渲染动画网格。给定围绕表演者的𝑘个输入图像,我们首先生成目标视图的深度图($𝐷𝑟_𝑡$ )、两个输入视图的深度图($𝐷𝑟_{1}$和$𝐷𝑟_{2}$),以及目标视图中的粗糙渲染图像$𝐼_{𝑟}$,其中使用了第4节中描述的纹理网格。然后,我们使用$𝐷𝑟_{𝑡}$将输入图像$𝐼_1$和$𝐼_2$变形到目标视图,表示为$𝐼_{1,𝑡}和𝐼_{2,𝑡}$。我们还将源视图的深度图变形到目标视图,并获得$𝐷𝑟_{1,𝑡}$和$𝐷𝑟_{2,𝑡}$,以获得遮挡图$𝑂_{𝑖} = 𝐷𝑟_{𝑡} − 𝐷𝑟_{𝑖,𝑡} (𝑖 = 1, 2)$,它表示了遮挡信息。
混合网络:由于自遮挡和几何代理不准确,$𝐼_{1,𝑡}$和$𝐼_{2,𝑡}$可能不正确。仅使用二维纹理进行混合会产生明显的伪影。因此,我们引入了一个混合网络 $𝑈_{𝑏}$,该网络利用了多视图环境中的固有全局信息,并利用像素级的混合地图 𝑊 融合了相邻输入视图的局部精细几何和纹理信息,其可表示为:$W=U_{\boldsymbol{b}}(I_{1,\boldsymbol{t}},O_1,I_{2,\boldsymbol{t}},O_2).$
- $𝑈_{𝑏}$的网络结构类似于U-Net,网络输出两个通道的特征图𝑊 = (𝑊1, 𝑊2),分别表示扭曲图像的混合权重。
为了实时性能,深度图在低分辨率(512 × 512)上生成。为了实现逼真的渲染,我们需要将深度图和混合图都上采样到2K分辨率。
然而,简单的上采样会导致边界附近的严重锯齿效应,这是由于深度推断模糊性造成的。因此,我们提出了一种边界感知方案,以改进深度图上的人体边界区域。具体而言,我们使用双线性插值来上采样$𝐷r_{𝑡}$。然后,应用腐蚀操作来提取边界区域。边界区域内的深度值通过使用第4节中描述的流程重新计算,并形成2K分辨率的$\hat 𝐷𝑟_{𝑡}$。然后,我们使用$\hat 𝐷𝑟_{𝑡}$将原始高分辨率输入图像变形为目标视图,得到$\hat 𝐼_{𝑖,𝑡}$。因此,我们最终的纹理融合结果可以表示为:
$I=\hat{W}_1\cdot\hat{I}_{1,t}+\hat{W}_2\cdot\hat{I}_{2,t}+(1-\hat{W}_2-\hat{W}_2)\cdot I_r,$
其中 $\hat 𝑊$ 是通过双线性插值直接上采样的高分辨率混合图;$𝐼_{r}$是对应纹理动画网格的图像。我们使用 Twindom [twindom [n. d.]] 数据集生成训练样本。合成训练数据包含 1,500 个带纹理的人体模型,并在每个模型周围渲染 360 个新视角和深度图。在训练过程中,我们随机选择六个视角,其相对姿态满足预定义的关系作为参考视角,而其他视角则是目标视角的真实值。我们通过均方误差损失函数将混合图像 𝐼 和对应的真实图像 𝐼 ′ 进行比对,以监督网络训练。
Results
Implementation Details and Running-time analysis
整个系统运行在单个RTX3090上
各阶段花费时间
| Stage | Action | Avg Time |
|---|---|---|
| Preprocessing | background matting | ∼ 1 min |
| Neural Surface | fast surface reconstruction | ∼ 10 mins |
| Neural Tracking | coarse tracking | ∼ 57 ms |
| neural deformation | ∼ 2 mins | |
| Neural Rendering | 2D texture generation | ∼ 30s |
| sparse view generation | ∼ 2s | |
| neural texture blending | ∼ 25ms |
数据集
对于每次表演,我们提供了80个预先校准和同步的RGB摄像机以2048 × 1536分辨率和25-30帧/秒捕获的视频序列,摄像机在表演者周围以4个不同纬度的圆圈均匀布置。我们还使用现成的背景抠图方法提供动态性能的前景分割
对比
- 渲染效果比较
- 商业软件Agisoft PhotoScan
- NeuralHumanFVV
- 基于神经图像的渲染方法IBRNet
- 动态神经辐射场ST-NeRF

- 定量比较,我们采用峰值信噪比(PSNR)、结构相似指数(SSIM)、平均绝对误差(MAE)和学习感知图像斑块相似度(LPIPS)
- 几何比较
消融研究
沉浸体验
Limitations and Discussion
作为升级基于网格的工作流程的试验,我们的方法能够生成与现有后期制作工具兼容的动态人体资产,并为可流式沉浸式体验提供照片级真实人体建模和渲染。
尽管具备这些引人注目的功能,我们的流程仍然存在一些限制。在这里,我们提供详细分析并讨论潜在的未来扩展。
- 首先,我们的方法依赖于基于图像的绿屏分割来分离前景表演,但无法提供视图一致的抠像结果。因此,我们的方法容易出现分割错误,仍然无法提供具有透明度细节的高质量头发渲染。受到最近的工作[Barron等人,2022年;Luo等人,2022年]的启发,我们计划将背景和透明度头发的显式建模引入我们的神经框架中。
- 此外,我们的渲染流程依赖于动画网格,因此受到跟踪质量的限制。即使使用虚拟视图的神经融合,我们的方法在处理极快速运动、严重的拓扑变化(如脱衣服)或复杂的人物-物体交互时仍然容易出现渲染伪影。这仍然是一个活跃研究领域中尚未解决的问题。如表1所示的运行时分析结果,我们的流程仅支持实时播放,仍无法实现实时即时建模和渲染以用于实时直播流媒体。瓶颈在于Instant-NSR的变形,尤其是隐式表面学习。为了加速,我们指出采用有限差分进行基于CUDA的法线估计,但这种近似的法线会降低表面细节。一个更忠实的CUDA实现需要数月的工程工作,以弄清楚MLP和哈希特征的二阶梯度的反向传播,而这在现有的CUDA库或代码库[Müller,2021年;Müller等人,2022年]中并没有得到充分支持。为了推动未来朝着这个方向的研究工作,我们将公开我们的PyTorch实现。
对于管道设计,我们的方法分别促进了各种神经技术用于人体表演的重建、追踪和渲染,与最近的隐式NeRF类框架相比[Tretschk等人,2020;Zhang等人,2021]。进一步设计和传输紧凑的神经表示,并将其解码为几何、动作或外观,以支持各种下游应用,这是很有前景的。我们认为我们的方法是朝着这个最终目标迈出的坚实一步,通过中间利用基于动画网格的工作流程并将其推进到神经时代。此外,由于我们的方法能够高效地生成动态人体素材,我们计划扩大我们的穹顶级数据集,并探索生成可动画的数字人类[Xiang等人,2021]。将光线和材料明确分解到我们的方法中以实现可重新照明的人体建模也是很有趣的。
Conclusion
我们提出了一种综合的神经建模和渲染方法,用于从密集的多视角RGB输入中重建、压缩和渲染高质量的人体表演。我们的核心思想是将传统的动画网格工作流提升到神经时代,采用一类高效的全新神经技术。我们的神经表面重建器Instant-NSR通过将基于TSDF的体积渲染与哈希编码相结合,能够在几分钟内高效生成高质量的表面。我们的混合追踪器以自监督的方式压缩几何信息并编码时间信息,生成动画网格,支持使用动态纹理或光照图进行各种常规基于网格的渲染。我们进一步提出了一种分层神经渲染方案,在质量和带宽之间取得了精细的平衡。我们展示了我们的方法在各种基于网格的应用和虚拟增强现实中以4D人体表演回放的形式的照片级沉浸式体验方面的能力。我们相信,我们的方法是从成熟的基于网格的工作流向神经人体建模和渲染的强有力过渡,它为忠实记录人类表演迈出了坚实的一步,具有众多在娱乐、游戏和虚拟现实/增强现实以及元宇宙中沉浸体验方面的潜在应用。
细节
神经网络:
Instant-NSR由两个串联的MLP组成:
- 一个具有2个隐藏层的SDF MLP $𝑚_{𝑠}$,用Softplus替换了原始的ReLU激活函数,并且对所有隐藏层的激活函数设置了𝛽=100,SDF MLP使用哈希编码函数[Müller等人,2022]将3D位置映射为32个输出值。
- 一个具有3个隐藏层的颜色MLP $𝑚_{𝑐}$
- 每个隐藏层宽度为64个神经元
$m_{s}$训练SDF的网络表示为:$(x,F_{geo})=m_{s}(p,F_{hash}).$
- input
- 每个三维采样点的3个输入空间位置值
- 来自哈希编码位置的32个输出值
- output
- sdf值,然后我们将截断的函数应用于输出SDF值,该值使用sigmoid激活将其映射到
[−1,1]。 - 15维的$F_{geo}$值
- 共16个输出值
- sdf值,然后我们将截断的函数应用于输出SDF值,该值使用sigmoid激活将其映射到
$m_{c}$训练颜色的网络表示为:$\hat{C}=m_{c}(\mathrm{p},\mathrm{n},\mathrm{v},F_{geo}).$
- input
- 每个三维采样点的3个输入空间位置值
- 用有限差分函数估计SDF梯度的3个正态值
- 视角方向在球谐函数基础上分解为4阶及以下的前16个系数
- SDF MLP的15维的输出值$F_{geo}$
- output
- RGB: 3
用sigmoid激活将输出的RGB颜色值映射到[0,1]范围
训练细节
我们在论文中证明了我们约10分钟的训练结果与原始NeuS的约8小时优化结果是可比较的[Wang et al. 2021a]。在优化阶段,我们假设感兴趣的区域最初位于单位球内。我们在PyTorch实现中采用了[Mildenhall et al. 2021]的分层采样策略,其中粗采样和细采样的数量分别为64和64。我们每批次采样4,096条光线,并使用单个NVIDIA RTX 3090 GPU进行为期6,000次迭代的模型训练,训练时间为12分钟。为了近似梯度以进行高效的法线计算,我们采用有限差分函数$𝑓 ′ (𝑥) = (𝑓 (𝑥 + Δ𝑥) − (𝑓 𝑥 − Δ𝑥))/2Δ𝑥$,如第3.2节所述。在我们的PyTorch实现中,我们将近似步长设置为Δ𝑥 = 0.005,并在训练结束时将其减小到Δ𝑥 = 0.0005。我们通过最小化Huber损失L𝑐𝑜𝑙𝑜𝑟和Eikonal损失L𝑒𝑖𝑘来优化我们的模型。这两个损失使用经验系数𝜆进行平衡,在我们的实验中将其设置为0.1。此外,我们选择Adam [Diederik P Kingma et al.2014]优化器,初始学习率为1𝑒 − 2,并在训练过程中将其降低到1.6𝑒 − 3。
Neural Tracking Implementation Details
在第4节中,我们提出了一种神经跟踪流程,它将传统的非刚性跟踪和神经变形网络以一种由粗到精的方式结合在一起。我们通过高斯-牛顿方法解决非刚性跟踪问题,并在接下来的内容中介绍了详细信息。
跟踪细节: 在进行非刚性跟踪之前,我们通过计算规范网格上的测地距离来对ED节点进行采样。我们计算平均边长,并将其乘以一个半径比例,用于控制压缩程度,以获得影响半径𝑟。通过所有的实验,我们发现简单地调整为0.075也可以得到很好的结果。给定𝑟,我们按Y轴对顶点进行排序,并在距离𝑟之外时从现有ED节点集合中选择ED节点。此外,当ED节点影响相同的顶点时,我们可以将它们连接起来,然后提前构建ED图以进行后续优化。
$\mathrm{(c,\sigma)=\phi^{o}(p’+\phi^{d}(p’,t),d).}$
网络结构: 我们改进阶段的关键包括规范辐射场$𝜙^𝑜$和变形网络$𝜙^𝑑$。
$𝜙^𝑜$具有与Instant-NGP相同的网络结构,包括三维哈希编码和两个串联的MLP: 密度和颜色。
- 三维坐标通过哈希编码映射为64维特征,作为密度MLP的输入。然后,密度MLP具有2个隐藏层(每个隐藏层有64个隐藏维度),并输出1维密度和15维几何特征。
- 几何特征与方向编码连接在一起,并输入到具有3个隐藏层的颜色MLP中。最后,我们可以获得每个坐标点的密度值和RGB值。
$𝜙^{𝑑}$包括四维哈希编码和单个MLP。
- 四维哈希编码具有32个哈希表,将输入(p′,𝑡)映射到64维特征。通过我们的2个隐藏层变形MLP(每个隐藏层具有128个隐藏维度),最终可以得到Δp′。
训练细节
训练细节。我们分别训练$𝜙^𝑜$和 $𝜙^{𝑑}$ 。我们首先利用多视图图像来训练规范表示 $𝜙^𝑜$。当 PSNR 值稳定下来(通常在100个epoch之后),我们冻结 $𝜙^𝑜$ 的参数。然后,我们训练变形网络 $𝜙^{𝑑}$ 来预测每帧的变形位移。我们构建了一个PyTorch CUDA扩展库来实现快速训练。我们首先将规范帧中的ED节点转换到当前帧,然后构建一个KNN体素。具体而言,我们的体素分辨率是2563到5123,并且对于KNN体素中的每个体素,我们通过堆查询4到12个最近邻的ED节点。基于KNN体素,我们可以快速查询体素中的任何3D点,并获取邻居和对应的蒙皮权重,以通过非刚性跟踪计算坐标。
Neural Blending Implementation Details
U-Net: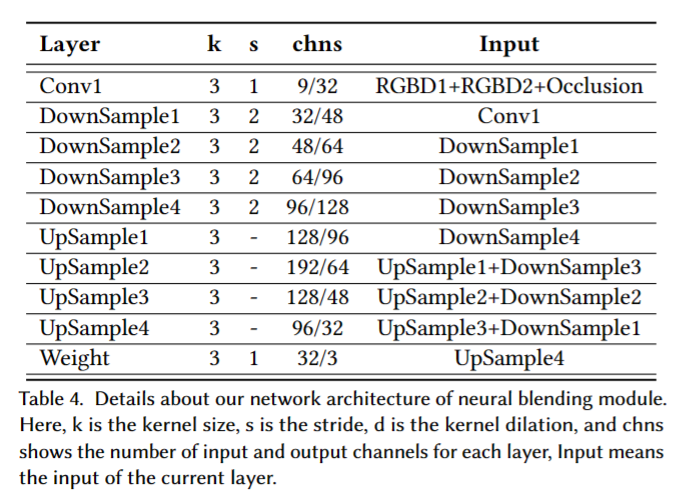
训练细节
在训练过程中,我们引入了一个称为遮挡映射的新维度,它是两个变形深度图之间的差异计算得出的。然后,我们将遮挡映射(1维)和两个变形的RGBD通道(4维)作为网络输入,进一步帮助U-net网络优化混合权重。在传统的逐像素神经纹理混合过程中,混合结果仅从两个变形图像生成。然而,如果目标视图在相邻虚拟视图中都被遮挡,将导致严重的伪影问题。因此,我们使用纹理渲染结果作为额外输入,以恢复由于遮挡而丢失的部分。为了有效地渲染,我们首先将输入图像降采样为512×512作为网络输入,然后通过双线性插值上采样权重映射以生成最终的2K图像。为了避免混合网络过度拟合额外的纹理渲染输入,我们在训练过程中应用高斯模糊操作来模拟低分辨率的纹理渲染图像。这个操作有助于网络专注于选定的相邻视图的细节,同时从额外的纹理渲染输入中恢复缺失的部分。此外,我们选择Adam [Diederik P Kingma et al.2014]优化器,初始学习率为1e-4,权重衰减率为5e-5。我们在一台单独的NVIDIA RTX 3090 GPU上使用Twindom [web.twindom.com]数据集对神经纹理混合模型进行了两天的预训练。
数据集
训练数据集。为了训练一个更具适应性的神经纹理融合网络,我们构建了一个大规模的合成多视角数据集。我们利用Twindom [web.twindom.com] 数据集中的预扫描模型生成多视角图像。具体而言,我们重新渲染预扫描模型以生成用于融合的六个固定视角,并在球体上采样180个虚拟目标视角来训练网络。为了增强我们网络的生成能力,我们通过给3D模型添加更具挑战性的姿势来扩大训练数据集。
实验
环境配置
如instant-nsr-pl中环境配置tiny-cuda-nn
创建conda环境:
conda create -n nsr python=3.8conda activate nsrpip install -r requirements.txtpip install git+https://github.com/NVlabs/tiny-cuda-nn/#subdirectory=bindings/torch
数据集:a test dataset dance
训练
CUDA_VISIBLE_DEVICES=x python xxx.py
- 类似于py文件中
os.environ['CUDA_VISIBLE_DEVICES']='x',只不过它用起来更加方便。只能指定一张卡而且不能再程序运行中途换卡,适用于一次run,全程只需要占单卡的.py文件
1 | # Instant-NSR Training |
提取网格
1 | # Instant-NSR Mesh extraction |
resolution: 1024

生成特定的目标相机图片
1 | # Instant-NSR Rendering |

render_img

depth_img

normal_img
NeRF-Mine: 基于InstantNSR在没有mask的情况下生成结果很差,放弃该项目
方便在本地和服务器之间拷贝
基于instant-NSR = Neus+ InstantNGP
环境配置
选择RTX3090单卡,镜像配置:
- PyTorch 1.10.0
- Python 3.8(ubuntu20.04)
- Cuda 11.3
1 | source /etc/network_turbo |
conda create -n nsr python=3.8conda activate nsrpip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple- 可选
pip install git+https://github.com/NVlabs/tiny-cuda-nn/#subdirectory=bindings/torch
error
1 | 1 |
error2:(21条消息) torch.utils.cpp_extension.load卡住无响应_zParquet的博客-CSDN博客
在示例数据集上训练
下载InstantNSR提供的示例数据集:a test dataset dance,放入inputs目录下
1 | # 开始训练 |
训练结果不理想:猜想是由于没有去除后面的背景,可以说nsr是一个依赖mask的方法