Instant Neus的代码理解
参考了:
- ngp_pl: Great Instant-NGP implementation in PyTorch-Lightning! Background model and GUI supported.
- Instant-NSR: NeuS implementation using multiresolution hash encoding.
使用了PyTorch Lightning库
文件结构:
1 | ├───configs # 配置文件 |
fit流程伪代码
train.fit()结构的伪代码
1 | def fit(self): |
datasets
init
1 | datasets = {} |
dtu
数据集加载操作,返回一个DataLoader
- load_K_Rt_from_P,从P矩阵中恢复K、R和T
1 | def load_K_Rt_from_P(P=None): |
- create_spheric_poses,创建一个球形的相机位姿,用于测试时的位姿和输出视频
ref: torch.cross: 叉积 - 维基百科,自由的百科全书 (wikipedia.org)
理解特征值和特征向量是什么?torch.linalg.eig
1 | # 生成球形相机姿态, 测试使用 |
- DTUDatasetBase,
setup(self,config,split)- load cameras_file and
imread(/root_dir/image/*.png)cv2.imread : shape[0] is H , shape[1] is Wis different frome PIL image
- img_downscale or img_wh to downscale
- n_images(数据集图片数量)
max([int(k.split('_')[-1]) for k in cams.keys()]) + 1 - for i in range(n_images):
P = (world_mat @ scale_mat)[:3,:4]K, c2w = load_K_Rt_from_P(P)fx, fy, cx, cy = K[0,0] * self.factor, K[1,1] * self.factor, K[0,2] * self.factor, K[1,2] * self.factorself.factor = w / W
directions = get_ray_directions(w, h, fx, fy, cx, cy)得到的光线方向i.e. rays_d为类似NeRF的计算方式,y与j反向,z远离物体的方向- self.directions append directions
- c2w to tensor float and for c2w, flip the sign of input camera coordinate yz
- c2w_ = c2w.clone
c2w_[:3,1:3] *= -1.because Neus DTU data is different from blender or blender- all_c2w append c2w_
- if train or val
- open i:06d.png image (PIL image) (size : w,h)
- resize to w,h by Image.BICUBIC
- TF(torchvision.transforms.functional).to_tensor() : CHW
CHW.permute(1, 2, 0)[...,:3]: HWC
- open mask and covert(‘L’) , resize , to_tensor
- all_fg_mask append mask
- all_images append img
- all_c2w : stack all_c2w
- if test
- all_c2w = 创建一个球形相机位姿create_spheric_poses
- all_images = zeros(n_test_traj_steps,h,w,3) dtype = torch.float32
- all_fg_masks = zeros(n_test_traj_steps,h,w) dtype = torch.float32
directions = directions[0]
- else
- all_images = stack all_images
- all_fg_masks = stack al_images
- directions = stack self.directions
- .float().to(self.rank)
- self.rank = get_rank() = 0 ,1 ,2 … gpu序号
- load cameras_file and
- DTUDataset 继承Dataset和DTUDatasetBase
__init__ , __len__ , __getitem__
- DTUIterableDataset 继承IterableDataset 和 DTUDatasetBase
__init__ , __iter__
- DTUDataModule 继承pl.LightningDataModule
- @datasets.register(‘dtu’)
__init__(self,config)- setup(self,stage)
stage in [None , 'fit']: train_dataset = DTUIterableDataset(self.config,’train’)stage in [None , 'fit' , 'validate']: val_dataset = DTUDataset(self.config, self.config.get(‘val_split’,’train’))stage in [None , 'test']: test_dataset = DTUDataset(self.config , self.config.get(‘test_split’,’test’))stage in [None , 'predict']: predict_dataset = DTUDataset(self.config, ‘train’)
- prepare_data
- general_loader(self,dataset,batch_size)
- return DataLoader(dataset,num_workers=os.cpu_count(),batch_size,pin_memory=True,sampler=None)
- train_dataloader(self)
- return self.general_loader(self.train_dataset,batch_size=1)
- val_dataloader(self)
- return self.general_loader(self.val_dataset,batch_size=1)
- test_dataloader(self)
- return self.general_loader(self.test_dataset,batch_size=1)
- predict_dataloader(self)
- return self.general_loader(self.predict_dataset,batch_size=1)
models
init
@models.register('neus') 修饰器的作用:
- 主要是为了实例化NeuSModel()的同时,在models字典中同时存入一个NeuSModel()值,对应的key为’neus’
当运行 neus_model = NeuSModel() 时,即例如运行self.texture = models.make(self.config.texture.name, self.config.texture)时 ,会运行neus_model = register('neus')(NeusModel)
返回给neus_model的值为decorator(cls) 函数的返回值,即NeusModel
1 | models = {} |
base
BaseModel , 继承nn.Module
__init__(self,config)- self.confg = config , self.rank = get(rank)
- self.setup()
- 如果有config.weights,则load_state_dict(torch.load(config.weights))
- setup()
- update_step(self,epoch,global_step)
- train(self,mode=True)
- return super().train(mode=mode)
- eval(self)
- return super().eval()
- regularizations(self,out)
- return {}
- @torch.no_gard() export(self,export_config)
- return {}
其他model需要继承于BaseModel
neus
Neus中的两个网络
VarianceNetwork 继承nn.Module
sigmoid函数的s参数在训练中变化
__init__(self,config)- self.config, self.init_val
- self.register_parameter来自nn.Module注册一个参数
- if self.modulate
- True: mod_start_steps, reach_max_steps, max_inv_s
- False: none
- @property 将该函数变为类的属性: inv_s()
- $val = e^{variance * 10.0}$
- if self.modulate and do_mod
- val = val.clamp_max(mod_val)
- return val
- forward(self,x)
return torch.ones([len(x), 1], device=self.variance.device) * self.inv_s- 输入长度x1大小的inv_s
- update_step(self,epoch,global_step)
- if self.modulate
- …
- if self.modulate
NeuSModel 继承BaseModel
@models.register(‘neus’)
得到经过网络渲染后的一系列参数:
position: n_samples x 3
1 | forward_: |
- out:
- rgb, normal : n_rays x 3
- opacity=权重累加, depth , rays_valid: opacity>0 : n_rays x 1
num_samples: torch.as_tensor([len(t_starts)],dtype = torch.int32,device=rays.device)- if self.training:
- update:
- sdf, : n_samples x 1
- sdf_grad, : n_samples x 3
- (weights, midpoints, dists, ray_indices).view(-1) : n_samples x 1
- update:
and
- if learned_background:
- out_bg:
- rgb, opacity, depth, rays_valid, num_samples
- if self.training:
- update: (weights, midpoints, intervals, ray_indices).view(-1)
- out_bg:
- else: rgb = None, num_samples = 0, rays_valid = 0
and
- out_full
- rgb:
out_rgb + out_bg_rgb * (1.0 - out_opacity), n_rays x 1 - num_samples: out_num + out_bg_num , n_samples + n_samples_bg
- rays_valid: out_valid + out_bg_valid , n_rays x 1
- rgb:
- setup
- self.geometry
- self.texture
- self.geometry.contraction_type
- if self.config.learned_background
- self.geometry_bg
- self.texture_bg
- self.geometry_bg.contraction_type
- self.near_plane_bg, self.far_plane_bg
- self.cone_angle_bg = $10^{\frac{log_{10}(far.plane.bg)}{num.samples.per.ray.bg}}-1 = 10^{\frac{log_{10}(10^{3})}{64}}-1$
- self.variace = VarianceNetwork(self.config.variance)
- self.register_buffer(‘scene_aabb’)
- 即将 self.scene_aabb放在模型缓冲区,可以与参数一起保存,对这个变量进行优化
- if self.config.grid_prune 使用nerfacc中整合的InstantNGP中的占据网格,跳过空间中空白的部分
- self.occupancy_grid = OccupancyGrid(roi_aabb, resolution=128 , contraction_type=AABB)
- if self.learned_background:
- self.occupancy_grid_bg = OccupancyGrid(roi_aabb, resolution=256 , contraction_type=UN_BOUNDED_SPHERE)
- self.randomized = true
- self.background_color = None
- self.render_step_size = $1.732 \times 2 \times \frac{radius}{num.samples.per.ray}$
- update_step(self,epoch,global_step)
- update_module_step(m,epoch,global_step)
- m: self.geometry, self.texture,self.variance
- if learned_background self.geometry_bg, self_texture_bg
- m: self.geometry, self.texture,self.variance
- cos_anneal_end = config.cos_anneal_end = 20000
- if cos_anneal_end == 0: self.cos_anneal_end = 1.0
- else :min(1.0, global_step / cos_anneal_end)
- occ_eval_fn(x)
x: Nx3- sdf = self.geometry(x,…)
inv_s = self.variance(torch.zeros([1,3]))[:,:1].clip(1e-6,1e6)inv_s = inv_s.expand(sdf.shape[0],1)estimated_next_sdf = sdf[...,None] - self.render_step_size * 0.5- $next = sdf - 1.732 \times 2 \times \frac{radius}{n.samples.perray} \cdot 0.5 = sdf - cos \cdot dist \cdot 0.5$
- $cos = 2 \cdot \sqrt{3}$
- $next = sdf - 1.732 \times 2 \times \frac{radius}{n.samples.perray} \cdot 0.5 = sdf - cos \cdot dist \cdot 0.5$
estimated_prev_sdf = sdf[...,None] + self.render_step_size * 0.5prev_cdf = torch.sigmoid(estimated_prev_sdf * inv_s)next_cdf = torch.sigmoid(estimated_prev_sdf * inv_s)p = prev_cdf - next_cdf , c = prev_cdfalpha = ((p + 1e-5) / (c + 1e-5)).view(-1, 1).clip(0.0, 1.0)Nx1- return alpha
- occ_eval_fn_bg(x)
density, _ = self.geometry_bg(x)return density[...,None] * self.render_step_size_bg
- if self.training(在nn.Module中可以这样判断是否为训练模式) and self.grid_prune
- self.occupancy_grid.every_n_step :nerfacc的占据网格每n步更新一次
- if learned_background: self.occupancy_grid_bg.every_n_step
- update_module_step(m,epoch,global_step)
- isosurface:判断是否等值面
- mesh = self.geometry.isosurface()
- return mesh
- get_alpha:获取$\alpha$值
inv_s = self.variance(torch.zeros([1,3]))[:,:1].clip(1e-6,1e6)inv_s = inv_s.expand(sdf.shape[0],1)true_cos = (dirs * normal).sum(-1, keepdim=True)iter_cos = -(F.relu(-true_cos * 0.5 + 0.5) * (1.0 - self.cos_anneal_ratio)+F.relu(-true_cos) * self.cos_anneal_ratio)estimated_next_sdf = sdf[...,None] + iter_cos * dists.reshape(-1, 1) * 0.5estimated_prev_sdf = sdf[...,None] - iter_cos * dists.reshape(-1, 1) * 0.5prev_cdf = torch.sigmoid(estimated_prev_sdf * inv_s)next_cdf = torch.sigmoid(estimated_next_sdf * inv_s)p = prev_cdf - next_cdfc = prev_cdfalpha = ((p + 1e-5) / (c + 1e-5)).view(-1).clip(0.0, 1.0)N,
- forward_bg_:背景的输出
n_rays = rays.shape[0],rays_o, rays_d = rays[:, 0:3], rays[:, 3:6]- sigma_fn(t_starts, t_ends, ray_indices)
- ref: Volumetric Rendering — nerfacc 0.3.5 documentation
density, _ = self.geometry_bg(positions)- return
density[...,None]
_, t_max = ray_aabb_intersect(rays_o, rays_d, self.scene_aabb)near_plane = torch.where(t_max > 1e9, self.near_plane_bg, t_max)- if t_max > 1e9, near_plane = self.near_plane_bg, else near_plane = t_max
- with torch.no_grad():
- ray_indices, t_starts, t_ends = ray_marching()
- ref:Volumetric Rendering — nerfacc 0.3.5 documentation
- ray_indices = ray_indices.long() 为
N_rays - t_origins = rays_o[ray_indices]
N_rays x 3 - t_dirs = rays_d[ray_indices]
N_rays x 3 - midpoints = (t_starts + t_ends) / 2.
n_samples x 1 - positions = t_origins + t_dirs * midpoints
n_samples x 3 - intervals = t_ends - t_starts 为
n_samples x 1- n_samples = N_rays1 n_samples_ray1 + N_rays2 n_samples_ray2 + …
- density, feature = self.geometry_bg(positions)
- density : n_samples x 1
- feature : n_samples x feature_dim
- rgb = self.texture_bg(feature, t_dirs)
- rgb: n_samples x 3
- weights = render_weight_from_density(t_starts, t_ends, density[…,None], ray_indices=ray_indices, n_rays=n_rays)
- 从密度中得到权重: $w_i = T_i(1 - exp(-\sigma_i\delta_i)), \quad\textrm{where}\quad T_i = exp(-\sum_{j=1}^{i-1}\sigma_j\delta_j)$
- ref: nerfacc.render_weight_from_density — nerfacc 0.3.5 documentation
- n_samples x 1
- opacity = accumulate_along_rays(weights, ray_indices, values=None, n_rays=n_rays)
- ref: nerfacc.accumulate_along_rays — nerfacc 0.3.5 documentation
- n_rays, 1
- depth = accumulate_along_rays(weights, ray_indices, values=midpoints, n_rays=n_rays)
- n_rays, 1
- comp_rgb = accumulate_along_rays(weights, ray_indices, values=rgb, n_rays=n_rays)
- n_rays , 3
- comp_rgb = comp_rgb + self.background_color * (1.0 - opacity)
- n_rays , 3
- return out
1 | out = { |
- forward_:前景输出
n_rays = rays.shape[0],rays_o, rays_d = rays[:, 0:3], rays[:, 3:6]- with torch.no_grad():
- ray_indices, t_starts, t_ends = ray_marching(…)
- ref:Volumetric Rendering — nerfacc 0.3.5 documentation
- ray_indices = ray_indices.long()
- t_origins = rays_o[ray_indices]
- t_dirs = rays_d[ray_indices]
- midpoints = (t_starts + t_ends) / 2.
- positions = t_origins + t_dirs * midpoints
- dists = t_ends - t_starts
- sdf, sdf_grad, feature = self.geometry(positions, with_grad=True, with_feature=True)
- sdf : n_samples x 1
- sdf_grad: n_samples x 3
- feature: n_samples x feature_dim
- normal = F.normalize(sdf_grad, p=2, dim=-1) 法向量:将sdf的梯度归一化
- normal: n_samples x 3
- alpha = self.get_alpha(sdf, normal, t_dirs, dists)[…,None]
- n_samples x 1
- rgb = self.texture(feature, t_dirs, normal)
- n_samples x 3
- weights = render_weight_from_alpha(alpha, ray_indices=ray_indices, n_rays=n_rays)
- 从$\alpha$中得到权重:$w_i = T_i\alpha_i, \quad\textrm{where}\quad T_i = \prod_{j=1}^{i-1}(1-\alpha_j)$
- ref: nerfacc.render_weight_from_alpha — nerfacc 0.3.5 documentation
- n_samples x 1
- opacity = accumulate_along_rays(weights, ray_indices, values=None, n_rays=n_rays)
- n_rays, 1
- depth = accumulate_along_rays(weights, ray_indices, values=midpoints, n_rays=n_rays)
- n_rays, 1
- comp_rgb = accumulate_along_rays(weights, ray_indices, values=rgb, n_rays=n_rays)
- n_rays, 3
- comp_normal = accumulate_along_rays(weights, ray_indices, values=normal, n_rays=n_rays)
- n_rays, 3
- comp_normal = F.normalize(comp_normal, p=2, dim=-1)
- n_rays, 3
- return
{**out, **{k + '_bg': v for k, v in out_bg.items()}, **{k + '_full': v for k, v in ut_full.items()}}
1 | out = { |
forward(rays)
- if self.training
- out = self.forward_(rays)
- else
- out = chunk_batch(self.forward_, self.config.ray_chunk, True, rays)
- return
{**out, 'inv_s': self.variance.inv_s}
- if self.training
train(self, mode=True)
- self.randomized =
mode and self.config.randomized - return super().train(mode=mode)
- self.randomized =
eval
- self.randomized = False
- return super().eval()
regularizations
- losses = {}
- losses.update(self.geometry.regularizations(out))
- losses.update(self.texture.regularizations(out))
- return losses
@torch.no_grad()
- export:导出带有texture的mesh
1 |
|
network_utils
各种编码方式和MLP网络
- VanillaFrequency, ProgressiveBandHashGrid, tcnn.Encoding
- VanillaMLP, tcnn.Network
可以使用的方法: - get_encoding, get_mlp, get_encoding_with_network
- VanillaFrequency 继承nn.Module
__init__(self, in_channels, config)- self.N_freqs 即L
- self.in_channels, self.n_input_dims = in_channels, in_channels
self.funcs = [torch.sin, torch.cos]self.freq_bands = 2**torch.linspace(0, self.N_freqs-1, self.N_freqs)- self.n_output_dims = self.in_channels (len(self.funcs) self.N_freqs) = 3x2xL
- self.n_masking_step = config.get(‘n_masking_step’, 0)
- self.update_step 每步开始前都需要更新出mask
- forward(self,x)
- out = []
- for freq , mask in zip(self.freq_bands, self.mask):
- for func in self.funcs:
out += [func(freq*x) * mask]
- for func in self.funcs:
- return torch.cat(out, -1)
- update_step(self,epoch,global_step)
- if self.n_masking_step <= 0 or global_step is None:
- self.mask = torch.ones(self.N_freqs, dtype=torch.float32) 与L相同形状的全1张量
- else:
- self.mask = (1. - torch.cos(math.pi (global_step / self.n_masking_step self.N_freqs - torch.arange(0, self.N_freqs)).clamp(0, 1))) / 2.
- mask = $\left(1-cos\left(\pi \cdot \left(\frac{global.step \cdot L}{n.masking.step}-arrange\right).clamp\right)\right) \cdot 0.5$
- rank_zero_debug(f’Update mask: {global_step}/{self.n_masking_step} {self.mask}’)
- self.mask = (1. - torch.cos(math.pi (global_step / self.n_masking_step self.N_freqs - torch.arange(0, self.N_freqs)).clamp(0, 1))) / 2.
- if self.n_masking_step <= 0 or global_step is None:
Vanilla:最初始的
即NeRF中的频率编码方式
$\gamma(p)=\left(\sin \left(2^{0} \pi p\right), \cos \left(2^{0} \pi p\right), \cdots, \sin \left(2^{L-1} \pi p\right), \cos \left(2^{L-1} \pi p\right)\right)$
ProgressiveBandHashGrid,继承nn.Module
__init__(self, in_channels,config)- self.n_input_dims = in_channels
- encoding_config = config.copy()
- encoding_config[‘otype’] = ‘HashGrid’
- with torch.cuda.device(get_rank()):
- self.encoding = tcnn.Encoding(in_channels, encoding_config) 使用哈希编码
- self.n_output_dims = self.encoding.n_output_dims
- self.n_level = config[‘n_levels’],分辨率个数
- self.n_features_per_level = config[‘n_features_per_level’],特征向量维数
- self.start_level, self.start_step, self.update_steps = config[‘start_level’], config[‘start_step’], config[‘update_steps’]
- self.current_level = self.start_level
- self.mask = torch.zeros(self.n_level * self.n_features_per_level, dtype=torch.float32, device=get_rank())
- forward(self,x)
- enc = self.encoding(x)
- enc = enc * self.mask ,第一个step,mask为0,之后每过update_steps,更新一次mask
- return enc
- update_step(self,epoch,global_step)
- current_level = min(self.start_level + max(global_step - self.start_step, 0) // self.update_steps, self.n_level)
- min(1+max(global_step-0,0)//update_steps, 16)
- if current_level > self.current_level:
- rank_zero_debug(f’Update current level to {current_level}’)
- self.current_level = current_level
self.mask[:self.current_level * self.n_features_per_level] = 1.- mask从0到(当前分辨率x特征向量维数) 置为1
- current_level = min(self.start_level + max(global_step - self.start_step, 0) // self.update_steps, self.n_level)
CompositeEncoding,继承nn.Module
__init__(self, encoding , include_xyz = True, xyz_scale=1 , xyz_offset=0)- self.encoding = encoding
- self.include_xyz, self.xyz_scale, self.xyz_offset = include_xyz, xyz_scale, xyz_offset
- self.n_output_dims = int(self.include_xyz) * self.encoding.n_input_dims + self.encoding.n_output_dims
- $o.dim = int(TorF) \cdot n.idim +n.odim$
forward(self,x,*args)- return
self.encoding(x, *args) if not self.include_xyz else torch.cat([x * self.xyz_scale + self.xyz_offset, self.encoding(x, *args)], dim=-1)- if include_xyz:
torch.cat([x * self.xyz_scale + self.xyz_offset, self.encoding(x, *args)], dim=-1)将输入x变为2x-1,并与编码后的输入cat起来 - else :
self.encoding(x, *args)
- if include_xyz:
- return
- update(self, epoch, global_step)
- update_module_step(self.encoding, epoch, global_step)
config_to_primitive在utils/misc.py中,return OmegaConf.to_container(config, resolve=resolve)
由于OmegaConf config objects很占用内存,因此使用to_container转化为原始的容器,如dict。如果resolve值设置为 True,则将在转换期间解析内插${foo}。
- get_encoding(n_input_dims, config)
if config.otype == 'VanillaFrequency':- encoding = VanillaFrequency(n_input_dims, config_to_primitive(config))
elif config.otype == 'ProgressiveBandHashGrid':- encoding = ProgressiveBandHashGrid(n_input_dims, config_to_primitive(config))
- else:
- with torch.cuda.device(get_rank()):
- encoding = tcnn.Encoding(n_input_dims, config_to_primitive(config))
- with torch.cuda.device(get_rank()):
encoding = CompositeEncoding(encoding, include_xyz=config.get('include_xyz', False), xyz_scale=2., xyz_offset=-1.)- return encoding
- VanillaMLP , 继承nn.Module
- NeRF中的MLP
__init__(self,dim_in,dim_out,config)- 一共n_hidden_layers个隐藏层,每个隐藏层有n_neurons个节点
Sequential(*self.layers)将每层都加入ModuleList中,并在内部实现forward,可以不写forward- get_activation:utils中的激活函数方法,根据不同的output_activation选择不同的激活函数
1 | self.n_neurons, self.n_hidden_layers = config['n_neurons'], config['n_hidden_layers'] |
- VanillaMLP 接上
- forward(self,x),Sequential可以直接使用,而不需构建一个循环从ModuleList中依次执行
- x = self.layers(x.float())
- x = self.output_activation(x)
- return x
- make_linear(self,dim_in,dim_out,is_first,is_last)
- layer = nn.Linear(dim_in, dim_out, bias=True) # network without bias will degrade quality
- if self.sphere_init: 初始化每层的权重和偏置(常数或者正态分布)
- if is_last:
- torch.nn.init.constant_(layer.bias, -self.sphere_init_radius)
- torch.nn.init.normal_(layer.weight, mean=math.sqrt(math.pi) / math.sqrt(dim_in), std=0.0001)
- elif is_first:
- torch.nn.init.constant_(layer.bias, 0.0)
- torch.nn.init.constant_(layer.weight[:, 3:], 0.0)
- torch.nn.init.normal_(layer.weight[:, :3], 0.0, math.sqrt(2) / math.sqrt(dim_out))
- else:
- torch.nn.init.constant_(layer.bias, 0.0)
- torch.nn.init.normal_(layer.weight, 0.0, math.sqrt(2) / math.sqrt(dim_out))
- if is_last:
- else:
- torch.nn.init.constant_(layer.bias, 0.0)
- torch.nn.init.kaiming_uniform_(layer.weight, nonlinearity=’relu’)
- if self.weight_norm:
- layer = nn.utils.weight_normal(layer)
- return layer
- make_activation
- if self.sphere_init:
- return nn.Softplus(beta=100)
- else:
- return nn.ReLU(inplace=True)
- if self.sphere_init:
- forward(self,x),Sequential可以直接使用,而不需构建一个循环从ModuleList中依次执行
- sphere_init_tcnn_network(n_input_dims, n_output_dims, config, network)
- rank_zero_debug(‘Initialize tcnn MLP to approximately represent a sphere.’)
- padto = 16 if config.otype == ‘FullyFusedMLP’ else 8
- n_input_dims = n_input_dims + (padto - n_input_dims % padto) % padto
- $ni = ni + (padto - ni \% padto) \% padto$ 取余数
- n_output_dims = n_output_dims + (padto - n_output_dims % padto) % padto
data = list(network.parameters())[0].dataassert data.shape[0] == (n_input_dims + n_output_dims) * config.n_neurons + (config.n_hidden_layers - 1) * config.n_neurons**2new_data = []
1 | # first layer |
get_mlp(n_input_dims, n_output_dims, config)
if config.otype == 'VanillaMLP':- network = VanillaMLP(n_input_dims, n_output_dims, config_to_primitive(config))
else:- with torch.cuda.device(get_rank()):
- network = tcnn.Network(n_input_dims, n_output_dims, config_to_primitive(config))
- if config.get(‘sphere_init’, False):
- sphere_init_tcnn_network(n_input_dims, n_output_dims, config, network)
- with torch.cuda.device(get_rank()):
- return network 返回一个model
EncodingWithNetwork,继承nn.Module
__init__(self,encoding,network)- self.encoding, self.network = encoding, network
- forward(self,x)
- return self.network(self.encoding(x))
- update_step(self, epoch, global_step)
- update_module_step(self.encoding, epoch, global_step)
- update_module_step(self.network, epoch, global_step)
get_encoding_with_network(n_input_dims, n_output_dims, encoding_config, network_config)
if encoding_config.otype in ['VanillaFrequency', 'ProgressiveBandHashGrid'] or network_config.otype in ['VanillaMLP']:- encoding = get_encoding(n_input_dims, encoding_config)
- network = get_mlp(encoding.n_output_dims, n_output_dims, network_config)
- encoding_with_network = EncodingWithNetwork(encoding, network)
- else:
- with torch.cuda.device(get_rank()):
- encoding_with_network = tcnn.NetworkWithInputEncoding(n_input_dims,n_output_dims,encoding_config,network_config)
- with torch.cuda.device(get_rank()):
- return encoding_with_network
geometry
输入点的位置position经过MLP网络得到背景density, feature或者前景物体sdf, sdf_grad, feature
- contract_to_unisphere,根据contraction_type,将位置x缩放到合适大小
1
2
3
4
5
6
7
8
9
10
11
12
13def contract_to_unisphere(x, radius, contraction_type):
if contraction_type == ContractionType.AABB:
x = scale_anything(x, (-radius, radius), (0, 1))
elif contraction_type == ContractionType.UN_BOUNDED_SPHERE:
x = scale_anything(x, (-radius, radius), (0, 1))
x = x * 2 - 1 # aabb is at [-1, 1]
mag = x.norm(dim=-1, keepdim=True)
mask = mag.squeeze(-1) > 1
x[mask] = (2 - 1 / mag[mask]) * (x[mask] / mag[mask])
x = x / 4 + 0.5 # [-inf, inf] is at [0, 1]
else:
raise NotImplementedError
return x
将等值面三角网格化
- MarchingCubeHelper 继承nn.Module
__init__(resolution, use_torch=True)- self.resolution = resolution
- self.use_torch = use_torch
- self.points_range = (0, 1)
- if self.use_torch:
- import torchmcubes
- self.mc_func = torchmcubes.marching_cubes
- else:
- import mcubes
- self.mc_func = mcubes.marching_cubes
- self.verts = None
- grid_vertices()
- if self.verts is None:
x, y, z = torch.linspace(*self.points_range, self.resolution), torch.linspace(*self.points_range, self.resolution), torch.linspace(*self.points_range, self.resolution)x: torch.Size([resolution])
- x, y, z = torch.meshgrid(x, y, z, indexing=’ij’)
x: torch.Size([resolution, resolution, resolution])
verts = torch.cat([x.reshape(-1, 1), y.reshape(-1, 1), z.reshape(-1, 1)], dim=-1).reshape(-1, 3)verts: torch.Size([resolution ** 3, 3])
- self.verts = verts
- return self.verts
- if self.verts is None:
- forward(self,level,threshold=0.)
- level = level.float().view(self.resolution, self.resolution, self.resolution)
- if self.use_torch:
verts, faces = self.mc_func(level.to(get_rank()), threshold)verts, faces = verts.cpu(), faces.cpu().long()
- else:
verts, faces = self.mc_func(-level.numpy(), threshold)# transform to numpyverts, faces = torch.from_numpy(verts.astype(np.float32)), torch.from_numpy(faces.astype(np.int64))
- verts = verts / (self.resolution - 1.)
- return {‘v_pos’: verts, ‘t_pos_idx’: faces}
获得等值面的mesh网格,包括vertices和faces
- BaseImplicitGeometry,继承BaseModel
__init__(self,config)if self.config.isosurface is not None:assert self.config.isosurface.method in ['mc', 'mc-torch']if self.config.isosurface.method == 'mc-torch':raise NotImplementedError("Please do not use mc-torch. It currently has some scaling issues I haven't fixed yet.")
self.helper = MarchingCubeHelper(self.config.isosurface.resolution, use_torch=self.config.isosurface.method=='mc-torch')
- self.contraction_type = None
- self.radius = self.config.radius
- forward_level(self,points)
- raise NotImplementedError
- isosurface_(self,vmin,vmax): 返回mesh
1 | def batch_func(x): |
- BaseImplicitGeometry 接上
- @torch.no_grad()
- isosurface(self)
- if self.config.isosurface is None:
- raise NotImplementedError
- mesh_coarse = self.isosurface_((-self.radius, -self.radius, -self.radius), (self.radius, self.radius, self.radius))
- vmin, vmax = mesh_coarse[‘v_pos’].amin(dim=0), mesh_coarse[‘v_pos’].amax(dim=0)
- vmin_ = (vmin - (vmax - vmin) * 0.1).clamp(-self.radius, self.radius)
- vmax_ = (vmax + (vmax - vmin) * 0.1).clamp(-self.radius, self.radius)
- mesh_fine = self.isosurface_(vmin_, vmax_)
- return mesh_fine 返回vertices和faces
- if self.config.isosurface is None:
背景几何:density和feature
@models.register(‘volume-density’)
- VolumeDensity 继承BaseImplicitGeometry
- setup()
- self.n_input_dims = self.config.get(‘n_input_dims’, 3)
- self.n_output_dims = self.config.feature_dim
- self.encoding_with_network = get_encoding_with_network(self.n_input_dims, self.n_output_dims, self.config.xyz_encoding_config, self.config.mlp_network_config)
- forward(self,points) 根据编码方式和网络,得到density和feature
- points = contract_to_unisphere(points, self.radius, self.contraction_type)
out = self.encoding_with_network(points.view(-1, self.n_input_dims)).view(*points.shape[:-1], self.n_output_dims).float()- density, feature = out[…,0], out
- if ‘density_activation’ in self.config:
- density = get_activation(self.config.density_activation)(density + float(self.config.density_bias))
- if ‘feature_activation’ in self.config:
- feature = get_activation(self.config.feature_activation)(feature)
- return density, feature
- forward_level(self,points) 根据编码方式和网络,得到-density,方便进行判断等值面isosurface
- points = contract_to_unisphere(points, self.radius, self.contraction_type)
density = self.encoding_with_network(points.reshape(-1, self.n_input_dims)).reshape(*points.shape[:-1], self.n_output_dims)[...,0]- if ‘density_activation’ in self.config:
- density = get_activation(self.config.density_activation)(density + float(self.config.density_bias))
- return -density
- update_step(self,epoch, global_step)
- update_module_step(self.encoding_with_network, epoch, global_step)
- setup()
前景物体几何:sdf, sdf_grad, feature
@models.register(‘volume-sdf’)
- VolumeSDF
- setup()
- self.n_output_dims = self.config.feature_dim
- encoding = get_encoding(3, self.config.xyz_encoding_config)
- network = get_mlp(encoding.n_output_dims, self.n_output_dims, self.config.mlp_network_config)
- self.encoding, self.network = encoding, network
- self.grad_type = self.config.grad_type
- forward(self, points, with_grad=True, with_feature=True)
with torch.inference_mode(torch.is_inference_mode_enabled() and not (with_grad and self.grad_type == 'analytic')): 是否启用推理模式,当前为推理,并且没有grad,grad_type不是analyticwith torch.set_grad_enabled(self.training or (with_grad and self.grad_type == 'analytic')):- if with_grad and self.grad_type == ‘analytic’:
- if not self.training:
- points = points.clone() # points may be in inference mode, get a copy to enable grad
- points.requires_grad_(True)
- points_ = points 初始位置
- points = contract_to_unisphere(points, self.radius, self.contraction_type) points normalized to (0, 1)
out = self.network(self.encoding(points.view(-1, 3))).view(*points.shape[:-1], self.n_output_dims).float()sdf, feature = out[...,0], out- if ‘sdf_activation’ in self.config: sdf激活
- sdf = get_activation(self.config.sdf_activation)(sdf + float(self.config.sdf_bias))
- if ‘feature_activation’ in self.config:
- feature = get_activation(self.config.feature_activation)(feature)
- if with_grad: 求梯度的两种方法:自动微分or有限差分法
if self.grad_type == 'analytic':- grad = torch.autograd.grad(sdf, points_, grad_outputs=torch.ones_like(sdf),create_graph=True, retain_graph=True, only_inputs=True)[0]
elif self.grad_type == 'finite_difference':- 有限差分得到$𝑓 ′ (𝑥) = (𝑓 (𝑥 + Δ𝑥) − (𝑓 𝑥 − Δ𝑥))/2Δ𝑥$,sdf对位置的梯度grad
rv = [sdf]- if with_grad:
- rv.append(grad)
- if with_feature:
- rv.append(feature)
rv = [v if self.training else v.detach() for v in rv]return rv[0] if len(rv) == 1 else rv
- setup()
1 | 有限差分法 |
- VolumeSDF 接上
- forward_level(self, points)
- points = contract_to_unisphere(points, self.radius, self.contraction_type) # points normalized to (0, 1)
sdf = self.network(self.encoding(points.view(-1, 3))).view(*points.shape[:-1], self.n_output_dims)[...,0]- if ‘sdf_activation’ in self.config:
- sdf = get_activation(self.config.sdf_activation)(sdf + float(self.config.sdf_bias))
- return sdf
- update_step(self, epoch , global_step)
- update_module_step(self.encoding, epoch, global_step)
- update_module_step(self.network, epoch, global_step)
- forward_level(self, points)
texture
根据feature、dirs得到背景颜色
根据feature、dirs,以及normal得到前景颜色
前背景颜色值
@models.register(‘volume-radiance’)
- VolumeRadiance,继承nn.Module
__init__- self.config = config
- self.n_dir_dims = self.config.get(‘n_dir_dims’, 3)
- self.n_output_dims = 3
- encoding = get_encoding(self.n_dir_dims, self.config.dir_encoding_config)
- self.n_input_dims = self.config.input_feature_dim + encoding.n_output_dims
- network = get_mlp(self.n_input_dims, self.n_output_dims, self.config.mlp_network_config)
- self.encoding = encoding
- self.network = network
forward(self, features, dirs, *args)- dirs = (dirs + 1.) / 2. # (-1, 1) => (0, 1)
- dirs_embd = self.encoding(dirs.view(-1, self.n_dir_dims))
network_inp = torch.cat([features.view(-1, features.shape[-1]), dirs_embd] + [arg.view(-1, arg.shape[-1]) for arg in args], dim=-1)color = self.network(network_inp).view(*features.shape[:-1], self.n_output_dims).float()- if ‘color_activation’ in self.config:
- color = get_activation(self.config.color_activation)(color)
- return color
- update_step(self, epoch, global_step)
- update_module_step(self.encoding, epoch, global_step)
- regularizations(self, out)
- return {}
@models.register(‘volume-color’)
- VolumeColor,不使用编码方法
__init__- self.config = config
- self.n_output_dims = 3
- self.n_input_dims = self.config.input_feature_dim
- network = get_mlp(self.n_input_dims, self.n_output_dims, self.config.mlp_network_config)
- self.network = network
forward(self, features, *args)network_inp = features.view(-1, features.shape[-1])color = self.network(network_inp).view(*features.shape[:-1], self.n_output_dims).float()- if ‘color_activation’ in self.config:
- color = get_activation(self.config.color_activation)(color)
- return color
- regularizations(self, out)
- return {}
ray_utils
- cast_rays
获取光线的方向(相机坐标下)
- get_ray_directions(W, H, fx, fy, cx, cy, use_pixel_centers=True)
1 | def get_ray_directions(W, H, fx, fy, cx, cy, use_pixel_centers=True): |
获取光线
- get_rays(directions, c2w, keepdim=False):
1 | def get_rays(directions, c2w, keepdim=False): |
utils
分批使用func处理数据,并决定是否移动到cpu
chunk_batch(func, chunk_size, move_to_cpu, *args, **kwargs)- B = None
- for arg in args
- if isinstance(arg, torch.Tensor):
B = arg.shape[0]- break
- if isinstance(arg, torch.Tensor):
- out = defaultdict(list) 将字典中同个key的多个value构成一个列表
- out_type = None
- for i in range(0, B, chunk_size):
out_chunk = func(*[arg[i:i+chunk_size] if isinstance(arg, torch.Tensor) else arg for arg in args], **kwargs)- 使用func函数得到一批输出
- if out_chunk is None:
- continue
- out_type = type(out_chunk)
- if isinstance(out_chunk, torch.Tensor): 将out_chunk 变为字典
- out_chunk = {0: out_chunk}
- elif isinstance(out_chunk, tuple) or isinstance(out_chunk, list):
- chunk_length = len(out_chunk)
- out_chunk = {i: chunk for i, chunk in enumerate(out_chunk)}
- elif isinstance(out_chunk, dict):
- pass
- else:
print(f'Return value of func must be in type [torch.Tensor, list, tuple, dict], get {type(out_chunk)}.')- exit(1)
- for k, v in out_chunk.items():
- v = v if torch.is_grad_enabled() else v.detach()
- v = v.cpu() if move_to_cpu else v
out[k].append(v)
- if out_type is None:
- return
- out = {k: torch.cat(v, dim=0) for k, v in out.items()}
- if out_type is torch.Tensor:
- return out[0]
elif out_type in [tuple, list]:return out_type([out[i] for i in range(chunk_length)])
- elif out_type is dict:
- return out
将dat从inp缩放到tgt
- scale_anything(dat, inp_scale, tgt_scale):
- if inp_scale is None:
inp_scale = [dat.min(), dat.max()]
dat = (dat - inp_scale[0]) / (inp_scale[1] - inp_scale[0])dat = dat * (tgt_scale[1] - tgt_scale[0]) + tgt_scale[0]- return dat
- if inp_scale is None:
激活函数
- get_activation(name)
- if name is None:
- return lambda x: x
- name = name.lower() # lower: 将所有大写字符转换为小写
- if name == ‘none’: return lambda x: x
- if name.startswith(‘scale’):
- scale_factor = float(name[5:])
- return lambda x: x.clamp(0., scale_factor) / scale_factor
- elif name.startswith(‘clamp’):
- clamp_max = float(name[5:])
- return lambda x: x.clamp(0., clamp_max)
- elif name.startswith(‘mul’):
- mul_factor = float(name[3:])
- return lambda x: x * mul_factor
- elif name == ‘lin2srgb’:
return lambda x: torch.where(x > 0.0031308, torch.pow(torch.clamp(x, min=0.0031308), 1.0/2.4)*1.055 - 0.055, 12.92*x).clamp(0., 1.) - elif name == ‘trunc_exp’: return trunc_exp
- elif name.startswith(‘+’) or name.startswith(‘-‘): return lambda x: x + float(name)
- elif name == ‘sigmoid’:return lambda x: torch.sigmoid(x)
- elif name == ‘tanh’: return lambda x: torch.tanh(x)
- else: return getattr(F, name)
- if name is None:
systems
init
1 | systems = {} |
base
- BaseSystem,继承pl.LightningModule和SaverMixin
__init__- self.config = config
- self.rank = get_rank()
- self.prepare()
- self.model = models.make(self.config.model.name, self.config.model)
- prepare
- pass
- forward(self, batch)
- raise NotImplementedError
- C(self, value)
1 | C(): |
- BaseSystem接上
- preprocess_data(self, batch, stage)
- pass
- on_train_batch_start(self, batch, batch_idx, unused=0)等pl.LightningModule规定的方法
- preprocess_data(self, batch, stage)
1 | """ |
1 | in systems/utils.py |
neus
有两种在console上输出信息的方式:
- self.print: correctly handle progress bar
- rank_zero_info: use the logging module
@systems.register(‘neus-system’)
- NeuSSystem,继承BaseSystem
- prepare
- self.criterions = { ‘psnr’: PSNR()}
self.train_num_samples = self.config.model.train_num_rays * (self.config.model.num_samples_per_ray + self.config.model.get('num_samples_per_ray_bg', 0))- 训练采样数= 训练光线数x(每条光线上采样数+背景中每条光线采样数)
- self.train_num_rays = self.config.model.train_num_rays
- 训练光线数 = config中训练光线数
- forward(self, batch)
return self.model(batch['rays'])
- preprocess_data(self, batch, stage)
- stage: train
- if batch_image_sampling 随机抽train_num_rays张图片, 索引为index(随机多张图片中,每张图片随机选取一个像素生成光线)
- directions :(n_images, H, W, 3) —> (train_num_rays, 3)
- c2w:(n_images, 3, 4) —> (train_num_rays, 3, 4)
- rays_o, rays_d : (train_num_rays, 3)
- rgb: (n_images, H, W, 3) —> (train_num_rays, 3)
- fg_mask: (n_images, H, W) —> (train_num_rays,)
- else 随机抽取一张图片,索引index长度为1(一张图片,随机选取多个像素生成光线)
- directions :(n_images, H, W, 3) —> (train_num_rays, 3)
- c2w:(n_images, 3, 4) —> (1, 3, 4)
- rays_o, rays_d : (train_num_rays, 3)
- rgb: (n_images, H, W, 3) —> (train_num_rays, 3)
- fg_mask: (n_images, H, W) —> (train_num_rays,)
- if batch_image_sampling 随机抽train_num_rays张图片, 索引为index(随机多张图片中,每张图片随机选取一个像素生成光线)
- stage: val
index = batch['index']- c2w: (n_images, 3, 4) —> (3, 4)
- directions: (n_images, H, W, 3) —> ( H, W, 3)
- rays_o, rays_d : (H, W, 3)
- rgb: (n_images, H, W, 3) —> (len(index)xHxW,3)
- fg_mask: (n_images, H, W, 3) —> (len(index)xHxW)
- stage: test
index = batch['index']- c2w: (n_test_traj_steps ,3,4) —> (3,4)
- directions: (H,W,3) —> (H,W,3)
- rays_o, rays_d : (H,W,3)
- rgb: (n_test_traj_steps, H, W, 3) —> (HxW , 3)
- fg_mask : (n_test_traj_steps, H, W) —> (HxW)
- rays将rays_o和归一化后的rays_d,cat起来
- stage: train
- if bg_color: white
- model.bg_color = torch.ones((3,))
- if bg_color: random
- model.bg_color = torch.rand((3,))
- else: raise NotImplementedError
- if bg_color: white
- stage: val, test
- model.bg_color = torch.ones((3,))
- if apply_mask:
rgb = rgb * fg_mask[...,None] + model.bg_color * (1 - fg_mask[...,None])
- batch.update({‘rays’: rays, ‘rgb’: rgb, ‘fg_mask’: fg_mask})
- stage: train
- prepare
1 | def preprocess_data(self, batch, stage): |
- NeuSSystem接上
- training_step(self, batch, batch_idx)
out = self(batch) = self.model(batch['rays'])(self()相当于执行forward)- loss = 0
- if dynamic_ray_sampling 动态更新训练光线数
train_num_rays = int(train_num_rays*(train_num_samples/out['num_samples_full'].sum().item()))- 如果采样得到的总点数多了,则减少光线数,如果总点数少了,则增加光线数
self.train_num_rays = min(int(self.train_num_rays * 0.9 + train_num_rays * 0.1), self.config.model.max_train_num_rays)- 最后训练光线数为,两者取最小:
原来num*0.9 + 更新后num * 0.1与config.model.max_train_num_rays
- 最后训练光线数为,两者取最小:
- loss_rgb_mse = F.mse_loss,log(loss_rgb_mse),
loss+= loss_rgb_mse *lambda_rgb_mse- render_color:
out['comp_rgb_full'][out['rays_valid_full'][...,0]] - gt_color:
batch['rgb'][out['rays_valid_full'][...,0]]
- render_color:
- loss_rgb_l1 = F.l1_loss,log(loss_rgb_l1),
loss+= loss_rgb_l1 *lambda_rgb_l1out['comp_rgb_full'][out['rays_valid_full'][...,0]]batch['rgb'][out['rays_valid_full'][...,0]]
- loss_eikonal,log(loss_eikonal),
loss+= loss_eikonal *lambda_eikonal((torch.linalg.norm(out['sdf_grad_samples'], ord=2, dim=-1) - 1.)**2).mean()
- loss_mask,log(loss_mask),
loss+= loss_mask *lambda_mask- opacity.clamp(1.e-3, 1.-1.e-3)
binary_cross_entropy(opacity, batch['fg_mask'].float())
- loss_opaque,log(loss_opaque),
loss+= loss_opaque *lambda_opaque- binary_cross_entropy(opacity, opacity)
- loss_sparsity,log(loss_sparsity),
loss+= loss_sparsity *lambda_sparsitytorch.exp(-self.config.system.loss.sparsity_scale * out['sdf_samples'].abs()).mean()- $\frac{1}{n.samples} \sum e^{-sparsity.scle \cdot |sdf|}$
- if lambda_distortion>0
- loss_distortion,log(loss_distortion),
loss+= loss_distortion *lambda_distortionflatten_eff_distloss(out['weights'], out['points'], out['intervals'], out['ray_indices'])
- loss_distortion,log(loss_distortion),
- if learned_background and lambda_distortion_bg>0
- loss_distortion_bg,log(loss_distortion_bg),
loss+= loss_distortion_bg *lambda_distortion_bgflatten_eff_distloss(out['weights_bg'], out['points_bg'], out['intervals_bg'], out['ray_indices_bg'])
- loss_distortion_bg,log(loss_distortion_bg),
- losses_model_reg = self.model.regularizations(out)
- for name, value in losses_model_reg.items():
- self.log(f’train/loss_{name}’, value)
- loss_ = value * self.C(self.config.system.loss[f”lambda_{name}”])
- loss += loss_
- self.log(‘train/inv_s’, out[‘inv_s’], prog_bar=True)
- for name, value in self.config.system.loss.items():
- if name.startswith(‘lambda’):
- self.log(f’train_params/{name}’, self.C(value))
- self.log(‘train/num_rays’, float(self.train_num_rays), prog_bar=True)
- return {‘loss’ : loss}
- training_step(self, batch, batch_idx)
loggers:
Epoch 0: : 29159it [30:20, 16.02it/s, loss=0.0265, train/inv_s=145.0, train/num_rays=1739.0, val/psnr=23.30]
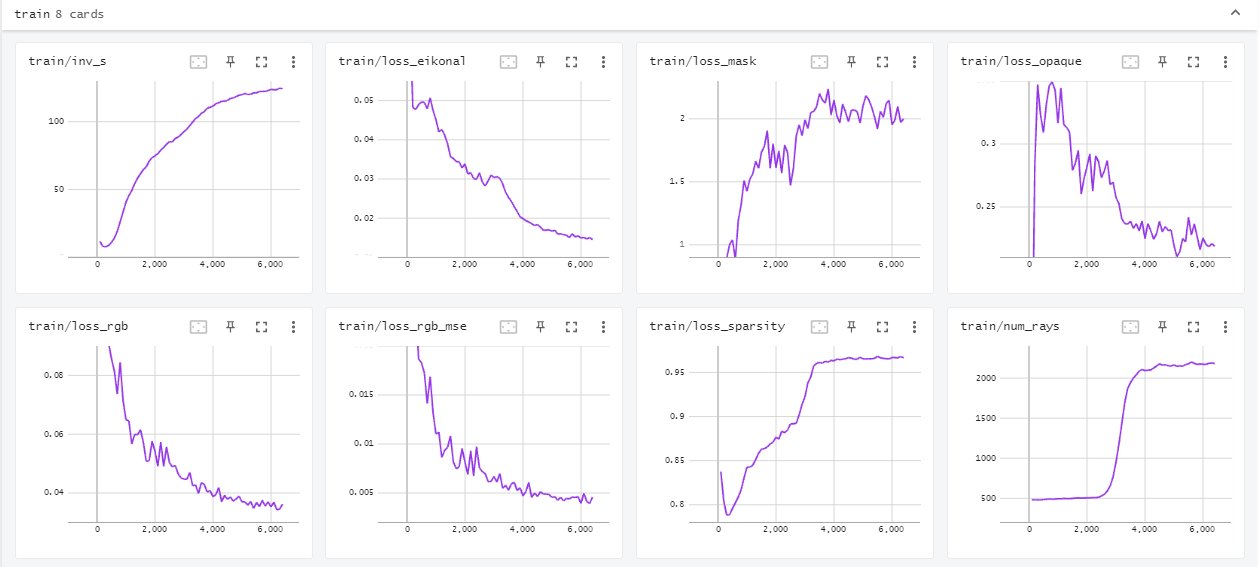
- NeuSSystem接上
- validation_step(self, batch, batch_idx)
- out = self(batch)
psnr = self.criterions['psnr'](out['comp_rgb_full'].to(batch['rgb']), batch['rgb'])- W, H = self.dataset.img_wh
- self.save_image_grid
- return {‘psnr’: psnr,’index’: batch[‘index’]}
- validation_step(self, batch, batch_idx)

- NeuSSystem接上
- validation_epoch_end(self,out)
- out = self.all_gather(out) 将所有数据类型的输出拼接起来
Union[Tensor, Dict, List, Tuple] - if self.trainer.is_global_zero:
- out_set = {}
- for step_out in out:
- DP:
if step_out['index'].ndim == 1: out_set[step_out['index'].item()] = {'psnr': step_out['psnr']}- ref: 单机vs多机pytorch中的分布式训练之DP VS DDP - 知乎 (zhihu.com)
- DDP:
for oi, index in enumerate(step_out['index']):out_set[index[0].item()] = {'psnr': step_out['psnr'][oi]}
- DP:
- psnr = $\frac{1}{len(index)}\sum psnr_{i}$
- self.log(psnr)
- out = self.all_gather(out) 将所有数据类型的输出拼接起来
- test_step(self, batch, batch_idx)
- out = self(batch)
psnr = self.criterions['psnr'](out['comp_rgb_full'].to(batch['rgb']), batch['rgb'])- W, H = self.dataset.img_wh
- self.save_image_grid
- 由于测试时,采用的相机位姿是未知的新视点,因此在image生成时,
batch['rgb']即gt图为zero(黑色)
- 由于测试时,采用的相机位姿是未知的新视点,因此在image生成时,
- return {‘psnr’: psnr,’index’: batch[‘index’]}
- validation_epoch_end(self,out)
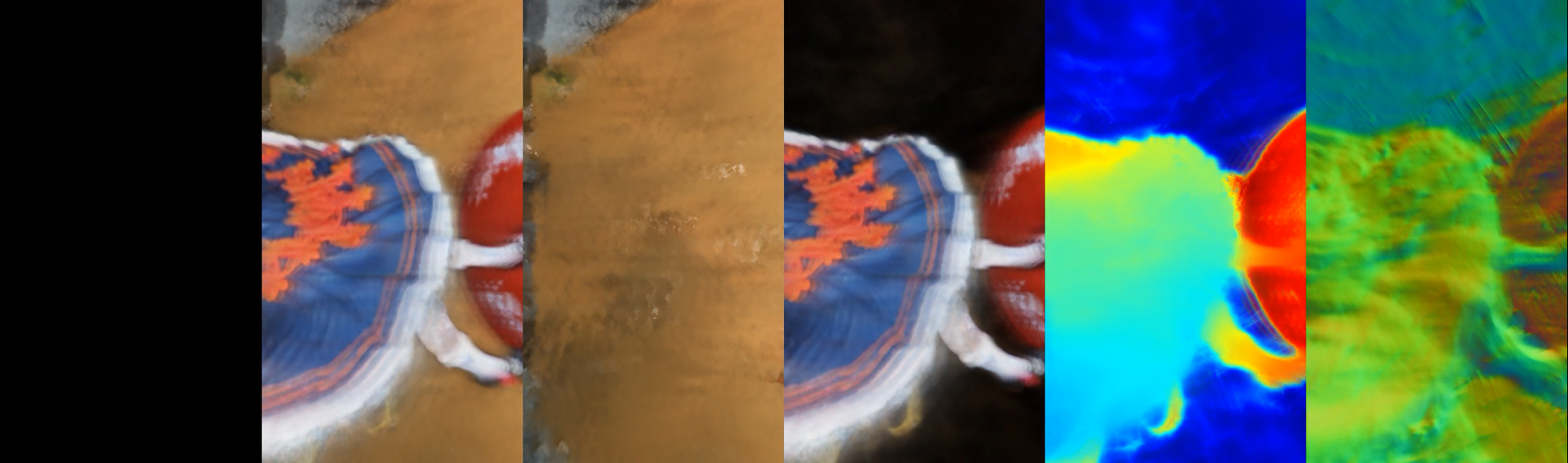
- NeuSSystem接上
- test_epoch_end(self,out)
- 同validation
- psnr = $\frac{1}{len(index)}\sum psnr_{i}$
- self.log(psnr)
- self.save_img_sequence()
- self.export
- 同validation
- export
- mesh = self.model.export(self.config.export)
- self.save_mesh()
- test_epoch_end(self,out)
criterions
- PSNR,继承nn.Module
- forward(self, inputs , targets, valid_mask= None, reduction= ‘mean’)
- assert reduction in [‘mean’, ‘none’]
value = (inputs - targets)**2,即$v = (inputs - targets)^{2}$- if valid_mask is not None:
- value = value[valid_mask]
- if reduction == ‘mean’:
- return -10 * torch.log10(torch.mean(value))
- $psnr = 10 \cdot log_{10}(\frac{1}{N} \sum v)$
- elif reduction == ‘none’:
- return -10 * torch.log10(torch.mean(value, dim=tuple(range(value.ndim)[1:])))
- forward(self, inputs , targets, valid_mask= None, reduction= ‘mean’)
utils
- ChainedScheduler
- SequentialLR
- ConstantLR
- LinearLR
- get_scheduler
- getattr_recursive
- get_parameters
- parse_optimizer
- parse_scheduler
- update_module_step(m,epoch,global_step)
- if hasattr(m,’update_step’) 如果m中有update_step这个属性or方法
- m.update_step(epoch,global_step) 则执行m.update_step(epoch,global_step)
- 如果m中没有update_step,则不执行操作
- if hasattr(m,’update_step’) 如果m中有update_step这个属性or方法
utils
mixins
class SaverMixin(): 被systems中的BaseSystem继承
- get_save_path(self,filename)
1 | def get_save_path(self, filename): |
- save_image_grid(self, filename, imgs)
- img = self.get_image_grid_(imgs)
- cv2.imwrite(self.get_save_path(filename),img)
1 | in val step: |
- get_image_grid_(self, imgs)
1 | def get_image_grid_(self, imgs): |
- get_rgb_image_(self, img, data_format, data_range))
1 | def get_rgb_image_(self, img, data_format, data_range): |
- get_grayscale_image_(self, img, data_range , cmap)
1 | def get_grayscale_image_(self, img, data_range, cmap): |
- convert_data(self, data),将输入的数据转化成ndarry类型
1 | def convert_data(self, data): # isinstance 判断一个对象是否是一个已知的类型 |
- save_img_sequence(self, filename, img_dir, matcher, save_format=’gif’, fps=30)
1 | in test step |
- save_mesh()
1 | in export: |
obj文件:
可以看出最后生成的模型在一个半径为1的单位圆中
1 | # 每个点的位置值和颜色值 |