| Title | Instant Neural Graphics Primitives with a Multiresolution Hash Encoding |
|---|---|
| Author | Thomas Müller Alex Evans Christoph Schied Alexander Keller |
| Conf/Jour | ACM Transactions on Graphics (SIGGRAPH 2022) |
| Year | 2022 |
| Project | Instant Neural Graphics Primitives with a Multiresolution Hash Encoding (nvlabs.github.io) |
| Paper | Instant Neural Graphics Primitives with a Multiresolution Hash Encoding (readpaper.com) |
哈希函数在cuda(cuda c++)中进行编程,不需深挖具体代码,初学只需理解多分辨率哈希编码思想。i.e.目前只需要学会使用tiny-cuda-nn即可:NVlabs/tiny-cuda-nn: Lightning fast C++/CUDA neural network framework (github.com)
哈希编码思想:
哈希编码后的输出值的数量与L(分辨率数量)、F(特征向量维度)有关,eg: L=16,F=2,则输入一个坐标xyz,根据多分辨率体素网格,插值出来L个特征值,每个特征值维度为2,因此输出值的维度为32
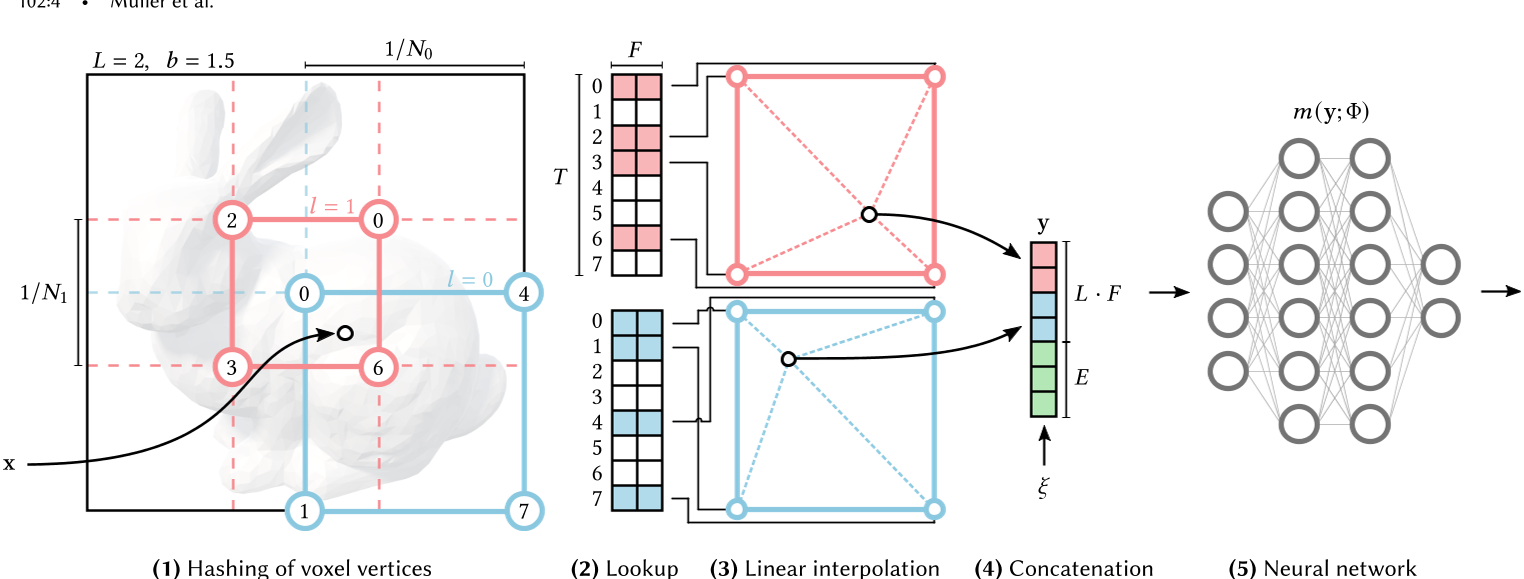
L为分辨率数量,l为分辨率序号。示例中L=2,$N_{0}= N_{min} =2$ , $N_{1}= N_{max}= 3$ , $b = \frac{3}{2}$
- L:多分辨率
- T:每个分辨率下有T个特征向量
- F:特征向量的维度
- 最小和最大分辨率:$N_{min} , N_{max}$
- b:每个level的缩放per_level_scale $b= e^{\frac{ln(\frac{N_{max}}{N_{min}})}{L-1}}$

改进之处
InstantNGP通过多分辨率哈希编码加速了对特征值的查找,减少了对空白空间的访问
| 对比 | NeRF | InstantNGP |
|---|---|---|
| 编码 | 频率编码 | 多分辨率哈希编码 |
| 资源 | 全连接神经网络,MLP,训练和评估花费大 | 采用多功能的新输入编码和在不牺牲质量的前提下更小的网络,减少了资源花费 |
| 速度 | 很慢 | 实现了几个数量级的提速 |
编码可视化(nerfstudio):Field Encoders - nerfstudio
- 我们通过一种通用的新输入编码来降低这种成本,这种编码允许在不牺牲质量的情况下使用更小的网络,从而显著减少浮点数和内存访问操作的数量:一个小的神经网络通过一个多分辨率的可训练特征向量哈希表来增强,这些特征向量的值通过随机梯度下降进行优化。多分辨率结构允许网络消除哈希冲突的歧义,使得一个简单的架构在现代gpu上并行化是微不足道的,使用完全融合的CUDA内核实现整个系统来利用这种并行性,最大限度地减少浪费的带宽和计算操作
我们实现了几个数量级的综合加速,能够在几秒钟内训练高质量的神经图形原语neural graphics primitives,并在几十毫秒内以1920×1080的分辨率进行渲染。
关键词:大规模并行算法;矢量/流算法;神经网络。(Massively parallel algorithms; Vector / streaming algorithms; Neural networks.)
- 其他关键词和短语:图像合成,神经网络,编码,哈希,gpu,并行计算,函数逼近。(Image Synthesis, Neural Networks, Encodings, Hashing, GPUs, Parallel Computation, Function Approximation.)
INTRODUCTION
计算机图形原语基本上是由参数化外观的数学函数表示的。数学表示的质量和性能特征对于视觉保真度至关重要:我们希望表示在捕获高频局部细节的同时保持快速和紧凑。由多层感知器(mlp)表示的函数,用作神经图形原语,已被证明符合这些标准(在不同程度上)
这些方法的重要共同点是编码将神经网络输入映射到高维空间,这是从紧凑模型中提取高近似质量的关键。这些编码中最成功的是可训练的、特定于任务的数据结构:Neural Sparse Voxel Fields,Neural Geometric Level of Detail: Real-time Rendering with Implicit 3D Shapes承担了很大一部分学习任务。这使得使用更小、更高效的mlp成为可能。然而,这种数据结构依赖于启发式方法和结构修改(如剪枝、分割或合并),这可能会使训练过程复杂化,将方法限制在特定的任务上,或者限制gpu上的性能,因为控制流和指针追踪是昂贵的。
我们通过多分辨率哈希编码来解决这些问题,该编码具有自适应性和高效性,并且与任务无关。它仅通过两个值进行配置——参数数量𝑇和所需的最高分辨率𝑁max,在经过几秒钟的训练后,在各种任务中能够达到最先进的质量:
- Gigapixel image: MLP学习从2D坐标到高分辨率图像的RGB颜色的映射。
- SDF: MLP学习从三维坐标到表面距离的映射。
- NRC: MLP从蒙特卡罗路径跟踪器中学习给定场景的5D光场。
- NeRF: MLP从图像观测和相应的透视变换中学习给定场景的3D密度和5D光场

同时实现任务无关的适应性和效率的关键是多分辨率哈希表层次结构:
- 适应性:我们将一系列的网格映射到对应的固定大小的特征向量数组。在粗分辨率下,网格点与数组条目之间存在一对一的映射关系。在细分辨率下,数组被视为哈希表,并使用空间哈希函数进行索引,多个网格点会与同一数组条目重叠。这种哈希碰撞导致碰撞的训练梯度取平均值,意味着最大的梯度——与损失函数最相关的梯度将占主导地位。因此,哈希表会自动优先考虑具有最重要细节的稀疏区域。与以前的方法不同,训练过程中不需要对数据结构进行任何结构更新。
- 效率:我们的哈希表查找是O(1),不需要控制流。这很好地映射到现代gpu,避免了执行分歧和树遍历中固有的串行指针追逐。所有分辨率的哈希表都可以并行查询。
先前的编码方式(BACKGROUND AND RELATED WORK)
编码的好处:高频的输入可以重建出图片的高频信息
将机器学习模型的输入编码到高维空间的早期示例包括独热编码one-hot encoding(Harris和Harris 2013)和核技巧kernel trick(Theodoridis 2008),通过这些方法可以使数据的复杂排列线性可分。
频率编码:对于神经网络而言,在循环结构的注意力组件(Gehring等人,2017)和随后的变换器(Vaswani等人,2017)中,输入编码被证明在帮助神经网络识别当前正在处理的位置方面非常有用。 Vaswani等人(2017)将标量位置𝑥 ∈ R编码为𝐿 ∈ N正弦和余弦函数的多分辨率序列。
这已经被应用于计算机图形学中,用于在NeRF算法中对空间方向变化的光场和体密度进行编码(Mildenhall等人,2020)。这个光场的五个维度使用上述公式独立地进行编码;后来将其扩展到了随机定向的平行波前(Tancik等人,2020)和细节级别过滤(Barron等人,2021a)。我们将这个编码家族称为频率编码。值得注意的是,频率编码后跟线性变换已经在其他计算机图形学任务中使用,比如逼近可见性函数(Annen等人,2007;Jansen和Bavoil,2010)。Müller等人(2019;2020)提出了一种基于光栅化核心的连续变体的单热编码,即单斑点编码,它在有界域中可以实现比频率编码更准确的结果,但代价是单尺度的。
参数化编码: 最近,参数化编码取得了最先进的结果,它们模糊了经典数据结构和神经方法之间的界限。其思想是在辅助数据结构中排列额外的可训练参数(除了权重和偏置),例如一个网格(Chabra等人,2020年;Jiang等人,2020年;Liu等人,2020年;Mehta等人,2021年;Peng等人,2020a年;Sun等人,2021年;Tang等人,2018年;Yu等人,2021a年)或一棵树(Takikawa等人,2021年),并根据输入向量x ∈ R𝑑查找并(可选地)插值这些参数。这种安排以更大的内存占用为代价来换取较小的计算成本:在通过网络向后传播的每个梯度中,全连接MLP网络中的每个权重都必须更新,而对于可训练的输入编码参数(”特征向量”),只有很少数量受到影响。例如,对于一个三线性插值的三维网格特征向量,每个样本反向传播到编码时只需要更新8个这样的网格点。通过这种方式,尽管参数化编码的总参数数量比固定输入编码要高得多,但在训练期间更新所需的FLOP数和内存访问并没有显著增加。通过减小MLP的大小,这样的参数化模型通常可以更快地收敛训练,而不会牺牲逼近质量。
- 另一种参数化方法使用了对域R𝑑的树细分,其中一个名为大型辅助坐标编码器神经网络(ACORN)(Martel等人,2021)被训练用于在围绕x的叶节点处输出密集的特征网格。这些密集的特征网格大约有10,000个条目,然后进行线性插值,类似于Liu等人2020的方法。与先前的参数化编码相比,这种方法往往能够产生更高程度的适应性,但计算成本更高,只有当足够多的输入x落入每个叶节点时,才能摊销这些成本。
稀疏参数编码。尽管现有的参数编码比非参数编码的前身具有更高的准确性,但它们也具有效率和多功能性的缺点。密集的可训练特征网格所占用的内存比神经网络权重要多。为了说明权衡并激励我们的方法,图2展示了几种不同编码方式对神经辐射场重建质量的影响。没有任何输入编码(a)时,网络只能学习到一个相当平滑的位置函数,导致对光场的逼近较差。频率编码(b)允许相同中等大小的网络(8个隐藏层,每个层宽度为256)更准确地表示场景。中间图像(c)将一个较小的网络与1283个三线性插值、16维特征向量的密集网格配对,总共有3360万个可训练参数。由于每个样本仅影响8个网格点,大量的可训练参数可以有效地更新。
- 然而,密集的网格在两个方面是浪费的。
- 首先,它将同样多的特征分配给空白区域和靠近表面的区域。参数数量呈O(𝑁^3)增长,而感兴趣的可见表面的面积仅呈O(𝑁^2)增长。在这个例子中,网格的分辨率为1283,但只有53,807个(2.57%)单元与可见表面接触。
- 其次,自然场景呈现出平滑性,促使人们使用多分辨率分解的方法(Chibane等,2020年; Hadadan等,2021年)。图2(d)显示了使用编码的结果,其中插值特征存储在分辨率从163到1733的八个共位网格中,每个网格包含2维特征向量。这些向量被连接在一起形成一个16维(与(c)相同)的输入网络。尽管参数数量不到(c)的一半,但重构质量相似。
- 如果已经知道感兴趣的表面,可以使用诸如八叉树(Takikawa等,2021年)或稀疏网格(Chabra等,2020年; Chibane等,2020年; Hadadan等,2021年; Jiang等,2020年; Liu等,2020年; Peng等,2020a年)这样的数据结构来剔除稠密网格中未使用的特征。然而,在NeRF设置中,表面只在训练期间出现。NSVF (Liu等,2020年)和其他一些同时进行的工作(Sun等,2021年; Yu等,2021a年)采用了多阶段的粗到细的策略,逐渐对特征网格的区域进行细化和剔除。虽然这种方法有效,但会导致更复杂的训练过程,其中稀疏数据结构必须定期更新。
- 然而,密集的网格在两个方面是浪费的。
多分辨率哈希编码: 我们的方法——图2(e,f)——结合了这两个想法来减少浪费。我们将可训练的特征向量存储在一个紧凑的空间哈希表中,其大小是一个超参数𝑇,可以通过调整来在参数数量和重建质量之间进行权衡。它既不依赖于训练过程中的渐进修剪,也不依赖于场景几何的先验知识。类似于(d)中的多分辨率网格,我们使用多个独立的哈希表在不同分辨率上进行索引,将它们的插值输出连接在一起,然后通过MLP传递。尽管参数数量减少了20倍,但重建质量与密集网格编码相当。与以前在3D重建中使用空间哈希(Teschner等,2003)(Nießner等,2013)的工作不同,我们不通过典型的探测、存储或链式处理等手段来明确处理哈希函数的冲突。相反,我们依靠神经网络学习自行消除哈希冲突,避免了控制流分歧,减少了实现复杂性,提高了性能。另一个性能优势是哈希表的可预测内存布局,它独立于所表示的数据。尽管在树状数据结构中很难实现良好的缓存行为,但我们的哈希表可以针对低级架构细节(如缓存大小)进行微调。
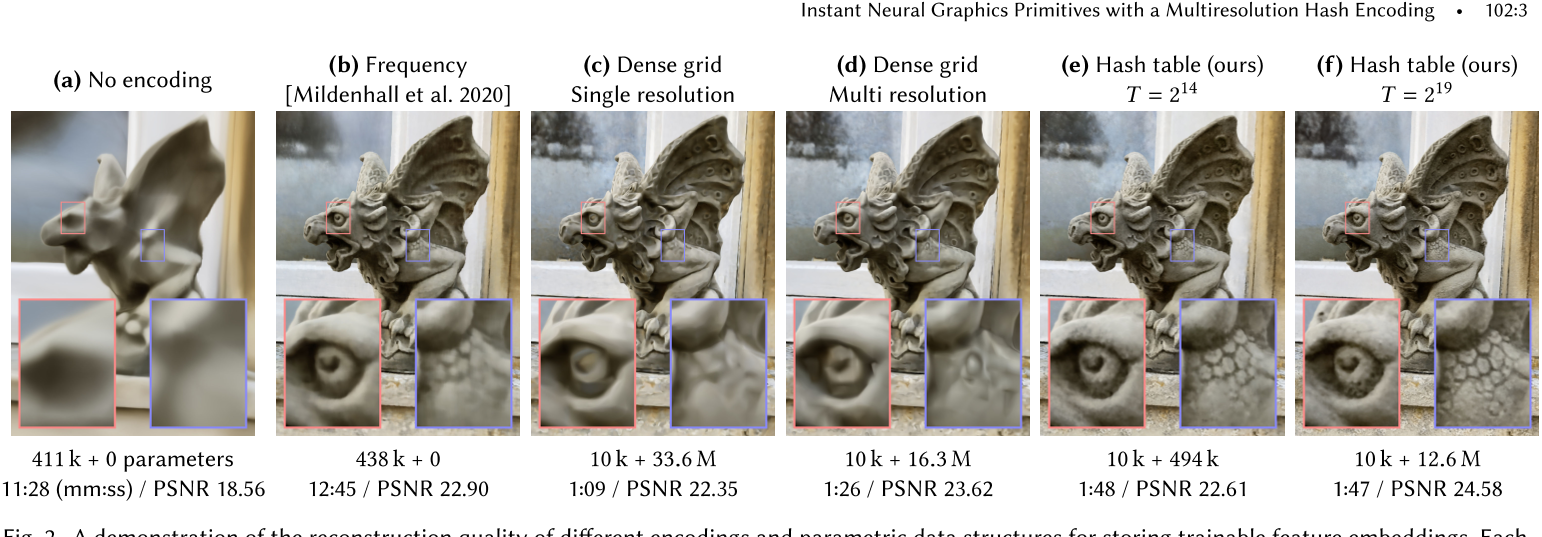
可训练参数的数量(MLP权重+编码参数)、训练时间和重建精度(PSNR)显示在每个图像下方。
由于参数更新的稀疏性和较小的MLP,我们的编码(e)具有与频率编码配置(b)相似的可训练参数总数,训练速度超过8倍。增加参数(f)的数量进一步提高了重建精度,而不显著增加训练时间。
- C: 单分辨率,将单位正方体划分为多个小正方体,每个小正方体8个顶点,每个顶点有一个特征值,当输入一个三维坐标xyz时,从8个顶点特征值三线性插值出输入三维坐标的特征值
- D: 多分辨率,将多个分辨率插值出的特征值concatenate起来
- E: 计算出每个网格的每个顶点的哈希值,并将其存入哈希表中,用哈希值做索引,特征值为内容,输入的每个坐标,通过每个顶点所在网格的位置,通过特征值三线性插值出输入坐标的特征值,然后作为MLP的输入
多分辨率哈希编码
MULTIRESOLUTION HASH ENCODING
给定一个全连接神经网络𝑚(y; Φ),我们对其输入𝑦 = enc(x; 𝜃)的编码感兴趣,该编码在各种应用中提高了近似质量和训练速度,同时没有明显的性能开销。我们的神经网络不仅具有可训练的权重参数Φ,还具有可训练的编码参数𝜃。这些参数被分成𝐿个层级,每个层级包含多达𝑇个特征向量,每个特征向量的维度为𝐹。表1显示了这些超参数的典型值。图3说明了我们多分辨率哈希编码中执行的步骤。每个层级(图中以红色和蓝色显示的两个层级)是独立的,并在概念上将特征向量存储在一个网格的顶点上,该网格的分辨率选择为最粗和最细分辨率之间的几何级数$[𝑁_{min}, 𝑁_{max}]$。
- L:多分辨率
- T:每个分辨率下有T个特征向量
- F:特征向量的维度
- 最小和最大分辨率:$N_{min} , N_{max}$
2D中多分辨率哈希编码的示意图。(1) 对于给定的输入坐标 x,我们在 𝐿 个分辨率级别上找到周围的体素,并通过哈希其整数坐标为它们的角点分配索引。(2) 对于所有得到的角点索引,我们从哈希表 𝜃𝑙 中查找相应的 𝐹 维特征向量。(3) 根据 x 在相应的第 𝑙 个体素中的相对位置进行线性插值。(4) 我们将每个级别的结果以及辅助输入 𝜉 ∈ R𝐸 进行串联,生成编码的 MLP 输入 𝑦 ∈ R𝐿𝐹 +𝐸,这是最后进行评估的。(5) 为了训练编码,损失梯度通过 MLP (5)、串联 (4)、线性插值 (3) 并累积在查找到的特征向量中进行反向传播。
L为分辨率数量,l为分辨率序号。示例中L=2,$N_{0}= N_{min} =2$ , $N_{1}= N_{max}= 3$ , $b = \frac{3}{2}$
⌊x𝑙 ⌋ 和 ⌈x𝑙 ⌉ 在 $Z_{𝑑}$ (整数)中跨越一个具有 2𝑑 个整数顶点的体素。我们将每个角落映射到级别的相应特征向量数组中的一个条目,该数组的固定大小最多为𝑇 。对于需要少于 𝑇 个参数的密集网格的粗略级别,即$(𝑁_{𝑙} + 1)𝑑 ≤ 𝑇$ ,此映射是一对一的。在更细的级别上,我们使用一个哈希函数 ℎ :$Z^{𝑑} → Z_{𝑇}$ 来索引数组,实际上将其视为哈希表,尽管没有显式的冲突处理。相反,我们依赖基于梯度的优化来在数组中存储适当的稀疏细节,并使用后续的神经网络 𝑚(y; Φ) 进行冲突解决。可训练的编码参数 𝜃 的数量因此为 O (𝑇 ),并且受到 𝑇 · 𝐿 · 𝐹 的限制,我们的情况始终为 𝑇 · 16 · 2 (表 1)。
哈希运算(杂凑函数):把任意长度的输入通过散列算法变换成固定长度的输出
Hash table样式为——hash value : grid index
我们使用的空间哈希函数(Teschner et al . 2003)的形式为:$h(\mathbf{x})=\left(\bigoplus\limits_{i=1}^dx_i\pi_i\right)\mod T,$⊕ 表示按位异或运算,异或的运算法则为:0⊕0=0,1⊕0=1,0⊕1=1,1⊕1=0(同为0,异为1),𝜋𝑖 是唯一的、很大的素数。实际上,这个公式对每个维度的线性同余(伪随机)排列结果进行了异或操作 (Lehmer 1951),从而减弱了维度对散列值的影响。值得注意的是,为了实现(伪)独立性,只需要对 𝑑 - 1 个维度进行排列,因此我们选择 𝜋1 := 1,以获得更好的缓存一致性,𝜋2 = 2 654 435 761,𝜋3 = 805 459 861。
最后,每个角落的特征向量根据 x 在其超立方体内的相对位置进行𝑑线性插值,即插值权重为 w𝑙 := x𝑙 − ⌊x𝑙 ⌋。请记住,这个过程对每个级别都是独立进行的𝐿 levels. 每个级别的插值特征向量以及辅助输入 𝜉 ∈ R𝐸(如编码的视角和神经辐射缓存中的纹理)被连接起来产生 y ∈ R𝐿𝐹 +𝐸,它是输入编码 enc(x; 𝜃) 到 MLP 𝑚(y; Φ) 的。
性能与质量: 特征向量的个数T越多,质量越好,但同时性能会更低。内存占用与 𝑇 成线性关系,而质量和性能往往以次线性的方式进行缩放。我们在图 4 中分析了 𝑇 的影响,报告了三种神经图形原语在各种 𝑇 值下的测试误差与训练时间的关系。我们建议从业者使用 𝑇 来调整编码以获得所需的性能特征。超参数 𝐿(层级数量)和 𝐹(特征维度数量)也在质量和性能之间进行权衡,我们在图 5 中对可训练编码参数 𝜃 的数量近似恒定条件下进行了分析。在这个分析中,我们发现 (𝐹 = 2, 𝐿 = 16) 是我们所有应用中有利的 Pareto 最优解,因此我们在所有其他结果中使用这些值,并将其推荐为默认值。
隐式哈希冲突解决(多个相同的grid可能具有相同的哈希值)。这种编码能够在哈希冲突存在的情况下忠实地重建场景,这可能看起来违反直觉。其成功的关键在于不同的分辨率级别具有互补的不同优势。低分辨率只有少量网格,哈希冲突较少,高分辨率网格很多,可能发生哈希冲突,但是由于当多个网格的哈希值冲突时,可能只有其中的几个网格是有价值的,其他是空气等与所建物体无关的网格。(粗略的级别,以及整个编码,是一对一映射的——也就是说,它们根本不会发生冲突。然而,它们只能表示场景的低分辨率版本,因为它们提供的特征是从一个间隔较大的点网格进行线性插值的。相反,细节级别可以捕捉到小的特征,因为它们具有细密的网格分辨率,但会遇到许多冲突——也就是说,不同的点会哈希到相同的表项。)附近具有相同整数坐标⌊x𝑙⌋的输入不被视为碰撞;只有当不同的整数坐标散列到相同的索引时才会发生碰撞。幸运的是,这种碰撞在空间中是伪随机分布的,并且统计上不太可能在给定一对点的每个级别同时发生。
- 当训练样本以这种方式发生碰撞时,它们的梯度会取平均值。需要考虑到这些样本对最终重构的重要性很少相等。例如,辐射场中可见表面上的一个点会对重构图像产生很强的贡献(具有高能见度和高密度,两者都对梯度的幅值产生乘法效应),从而导致其表项发生很大变化,而指向同一表项的空间中的一个点将具有更小的权重。因此,更重要样本的梯度主导了碰撞平均值,并且通过优化,使别名的表项自然地反映了更高权重点的需求。哈希编码的多分辨率方面涵盖了从粗分辨率𝑁min(可以保证无碰撞)到任务所需的最细分辨率𝑁max的全范围。因此,它保证了无论稀疏性如何,都包括了可能发生有意义学习的所有尺度。几何缩放允许只使用O(log(𝑁max/𝑁min))个级别来覆盖这些尺度,这允许选择一个保守地较大的𝑁max值。
在线适应性。请注意,如果输入x的分布在训练过程中随时间变化,例如如果它们变得集中在一个小区域内,那么更精细的网格级别将会遇到较少的冲突,从而可以学习到更准确的函数。换句话说,多分辨率哈希编码会自动适应训练数据的分布,继承了树状编码的好处(Takikawa等人,2021),而不需要进行特定任务的数据结构维护,这可能导致训练过程中出现离散跳跃。我们的一个应用程序,第5.3节中的神经辐射缓存,不断适应动画视点和3D内容,极大地受益于这一特性。
𝑑-线性插值。对查询的哈希表条目进行插值,确保编码 enc(x; 𝜃) 及其与神经网络 𝑚(enc(x; 𝜃); Φ) 的组合是连续的。如果没有插值,网络输出中将存在与网格对齐的不连续性,这会导致不理想的块状外观。当近似偏微分方程时,可能希望更高阶的平滑性。计算机图形学中的一个具体示例是有符号距离函数,此时梯度 𝜕𝑚(enc(x; 𝜃); Φ)/𝜕x,即表面法线,理想情况下也应连续。如果必须保证更高阶的平滑性,我们在附录 A 中描述了一种低成本的方法,但在我们的任何结果中都没有使用,因为会导致重建质量略微降低。
IMPLEMENTATION
为了展示多分辨率哈希编码的速度,我们在CUDA中实现了它,并将其与tiny-cuda-nn框架(Müller 2021)中的快速全融合MLP集成在一起。我们将多分辨率哈希编码的源代码作为Müller 2021的更新版本发布,并发布了与神经图形原语相关的源代码,网址为https://github.com/nvlabs/instant-ngp
- 性能考虑。为了优化推理和反向传播的性能,我们以半精度(每个条目2字节)存储哈希表条目。此外,我们还以完全精度维护参数的主副本,以进行稳定的混合精度参数更新,参考Micikevicius等人2018的方法。
- 为了最佳地利用GPU的缓存,我们逐层评估哈希表:在处理一批输入位置时,我们安排计算来查找所有输入的多分辨率哈希编码的第一级,然后是所有输入的第二级,依此类推。因此,在任何给定时间,只有少量连续的哈希表需要驻留在缓存中,这取决于GPU上可用的并行性。重要的是,这种计算结构自动地充分利用了可用的缓存和并行性,适用于各种哈希表大小𝑇。
- 在我们的硬件上,只要哈希表大小保持在$T ≤ 2^{19}$以下,编码的性能基本保持不变。超过这个阈值后,性能开始显著下降;请参见图4。这是由于我们的NVIDIA RTX 3090 GPU的6 MB L2缓存对于单个级别而言变得太小,当2 · T · F > 6 · 220时,其中2是半精度条目的大小。
- 特征维度𝐹的最佳数量取决于GPU架构。一方面,较小的数量有利于先前提到的流式处理方法中的缓存本地性,但另一方面,较大的𝐹通过允许𝐹宽度的向量加载指令来促进内存一致性。𝐹 = 2给出了我们在所有实验中使用的最佳成本质量权衡(参见图5)。
- 体系结构/神经网络:在除了稍后我们将描述的NeRF之外的所有任务中,我们使用具有两个隐藏层的多层感知器(MLP),每个隐藏层具有64个神经元,隐藏层上使用修正线性单元(ReLU)激活函数,以及一个线性输出层。对于NeRF和有符号距离函数,最大分辨率𝑁max设置为2048×场景尺寸,对于half of the gigapixel image 设置为width的一半,以及辐射缓存中的$2^{19}$(为了支持大场景中的近距离物体而设置的较大值)。
- 初始化。我们按照Glorot和Bengio 2010的方法初始化神经网络权重,以便在神经网络的各个层中提供合理的激活和梯度缩放。我们使用均匀分布U(−10−4,10−4)初始化哈希表条目,以提供一定的随机性,同时鼓励初始预测接近零。我们还尝试了各种不同的分布,包括零初始化,但结果都导致初始收敛速度稍微变慢。哈希表似乎对初始化方案具有鲁棒性。
- 训练。我们通过应用Adam (Kingma和Ba 2014)来共同训练神经网络权重和哈希表条目,其中我们设定 $𝛽1 = 0.9,𝛽2 = 0.99,𝜖 = 10^{−15}$。𝛽1和𝛽2的选择只会产生很小的差异,但𝜖 = 10−15的小值在哈希表条目的梯度稀疏和弱时能够显著加快收敛速度。为了防止长时间训练后的发散,我们对神经网络权重应用了弱的L2正则化(因子为10−6),但不适用于哈希表条目。
- 当拟合gigapixel图像或NeRFs时,我们使用L2损失。对于有符号距离函数,我们使用平均绝对百分比误差(MAPE),定义为|预测值-目标值|/|目标值|+0.01,并且对于神经辐射缓存,我们使用亮度相对L2损失(Müller et al. 2021)。我们观察到对于有符号距离函数,学习率为$10^-4$时收敛最快,对于其他情况,学习率为$10^-2$。对于神经辐射缓存,我们使用批量大小为$2^{14}$,对于其他情况,使用批量大小为$2^{18}$。最后,我们在哈希表条目的梯度完全为0时跳过Adam步骤。这在梯度稀疏的情况下可以节省约10%的性能,这在𝑇 ≫ BatchSize的情况下是常见的。尽管这种启发式方法违反了Adam背后的一些假设,但我们观察到收敛没有降级。
- 非空间输入维度 $𝜉 ∈ R^𝐸$。多分辨率哈希编码以相对低维度目标处理空间坐标。我们所有的实验都是在2D或3D中进行的。然而,在学习光场时,将辅助维度$𝜉 ∈ R^𝐸$ 输入神经网络往往是非常有用的,例如视角和材料参数。在这种情况下,可以使用已建立的技术对辅助维度进行编码,其成本不会随着维度的增加而超线性地增长;我们在神经辐射缓存中使用单blob编码(Müller等,2019),在NeRF中使用球谐基函数,与同时进行的工作相似(Verbin等,2021;Yu等,2021a)。
EXPERIMENTS
突出编码的多功能性和高质量,我们将其与以前的编码进行比较,在四个不同的计算机图形基元中,这些基元受益于编码空间坐标。