| Title | PAniC-3D: Stylized Single-view 3D Reconstruction from Portraits of Anime Characters |
|---|---|
| Author | Chen, Shuhong and Zhang, Kevin and Shi, Yichun and Wang, Heng and Zhu, Yiheng and Song, Guoxian and An, Sizhe and Kristjansson, Janus and Yang, Xiao and Matthias Zwicker |
| Conf/Jour | CVPR |
| Year | 2023 |
| Project | ShuhongChen/panic3d-anime-reconstruction: CVPR 2023: PAniC-3D Stylized Single-view 3D Reconstruction from Portraits of Anime Characters (github.com) |
| Paper | PAniC-3D: Stylized Single-view 3D Reconstruction from Portraits of Anime Characters (readpaper.com) |
基于EG3D无条件生成模型
PAniC-3D对比PixelNeRF、EG3D(+Img2stylegan or +PTI)、Pifu
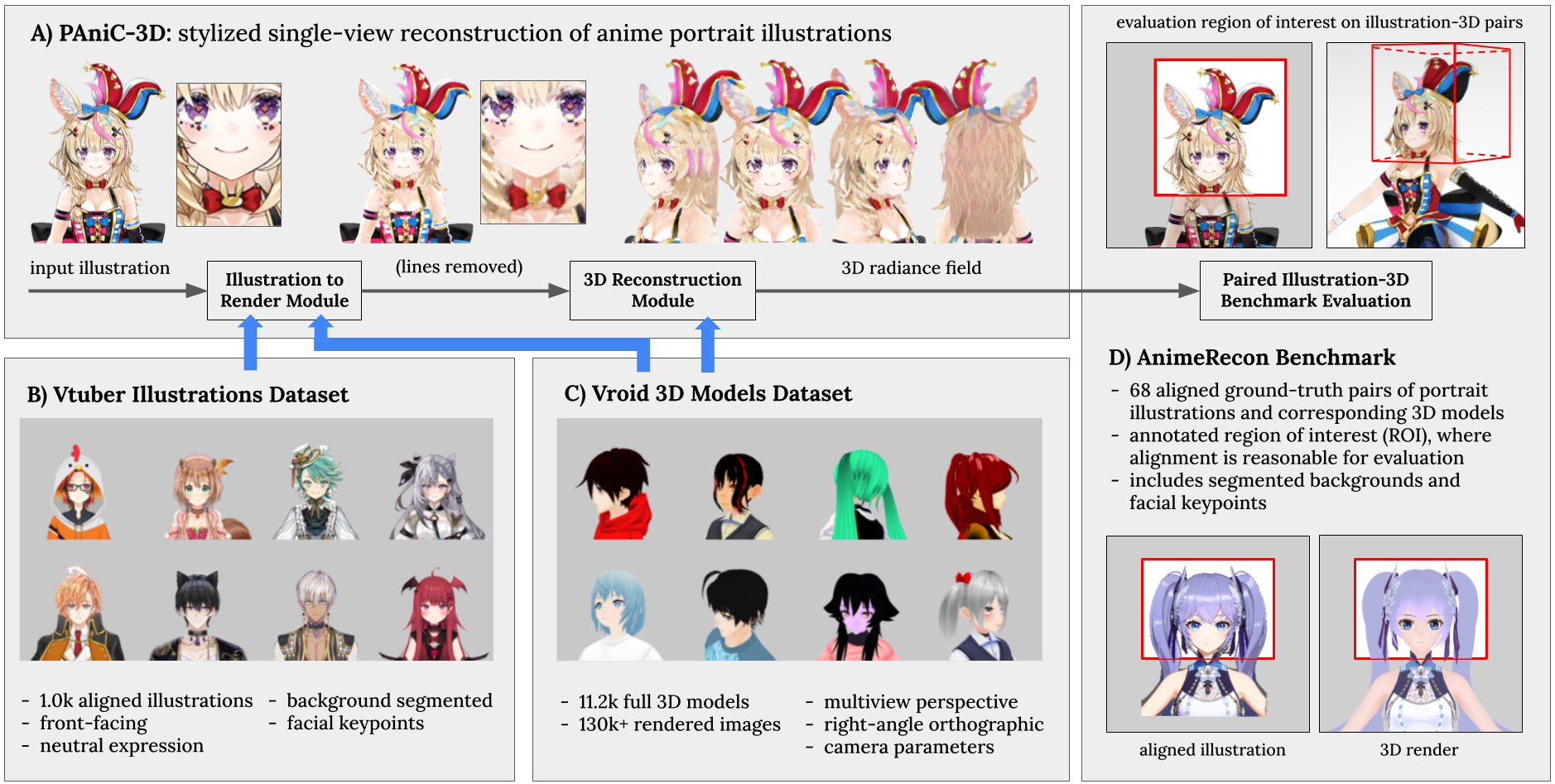
AIR
我们提出了PAniC-3D,这是一个能够直接从插画风格的(p)动漫(ani)角色(c)肖像中重建立体化的系统。与自然人头部的真实图像相比,动漫角色肖像插画具有更复杂和多样的发型、配饰几何,且呈现非照片般的轮廓线阴影,从而为单视角重建带来独特的挑战。此外,缺乏适用于训练和评估这一模糊化风格重建任务的3D模型和肖像插画数据。面对这些挑战,我们提出的PAniC-3D架构通过线条填充模型跨越了插画到3D领域的差距,并利用体积辐射场来表示复杂的几何形态。我们使用两个大型新数据集(11.2k个Vroid 3D模型,1k个Vtuber肖像插画)来训练我们的系统,并在新颖的AnimeRecon插画到3D对比基准上进行评估。PAniC-3D在很大程度上优于基线方法,并为确立从肖像插画中进行风格化重建的任务提供了数据支持。
随着AR/VR应用的兴起,除了对高保真度human avatars的需求在增加,对虚拟形象如动漫3D角色的需求也在增加。大多数角色设计师通常首先创建概念插图,允许他们表达复杂和高度多样化的特征,如头发,配饰,眼睛,皮肤,头饰等。不幸的是,将插图概念艺术开发成AR/VR就绪的3D资产的过程是昂贵的,需要专业的3D艺术家训练使用专家建模软件。虽然基于模板的创作者在一定程度上民主化了3D化身,但它们通常仅限于与特定身体模型兼容的3D资产。
我们提出了PAniC-3D,这是一个系统,可以直接从动漫角色的肖像插图自动重建风格化的3D角色头部。我们将问题分为两部分:
1)隐式单视图头部重建, implicit single-view head reconstruction
2)跨插图- 3d域间隙,from across an illustration-3D domain gap.
主要贡献:
- PAniC-3D: a system to reconstruct the 3D radiance field of a stylized character head from a single linebased portrait illustration.单线基础的肖像插图
- The Vroid 3D dataset of 11.2k character models and renders, the first such dataset in the anime-style domain to provide 3D assets with multiview renders.
- The Vtuber dataset of 1.0k reconstruction-friendly portraits (aligned, front-facing, neutral-expression) that bridges the illustration-render domain gap through the novel task of line removal from drawings.
- The AnimeRecon benchmark with 68 pairs of aligned 3D models and corresponding illustrations, enabling quantitative evaluation of both image and geometry metrics for stylized reconstruction.
Implicit 3D Reconstruction
虽然已经有很多基于网格的图像重建工作[23],但这些系统的表现力不足以捕捉3D字符拓扑的极端复杂性和多样性。
受到最近在生成高质量3D辐射场方面取得成功的启发[4,5,25,39],我们转而使用隐式表示。然而,为了获得高质量的结果,最近的隐式重建工作,如PixelNerf[40],由于缺乏公开可用的高质量3D数据,往往只从2D图像进行操作。
一些使用复杂3D资产的隐式重建系统,如Pifu[31],在使用基于点的监督方面取得了一定的成功,但需要仔细的点采样技术和损失平衡。
还有一组工作是基于草图的建模,其中3D表示是从轮廓图像中恢复的。例如,Rui等人[24]使用多视图解码器来预测草图到深度和法线,然后将其用于表面重建。Song等人[44]还尝试通过学习重新调整输入来补偿多视图绘制差异。虽然与我们的单视图肖像重建问题有关,但这些方法需要多视图草图,这对于角色艺术家来说很难一致地绘制,并且无法处理颜色输入
对于复杂的高质量3D资产,我们证明了可微体绘制在重建中的优越性。我们建立在最近的无条件生成工作(EG3D[4])的基础上,将重建问题定义为条件生成,提出了一些架构改进,并应用由我们的3D数据集提供的直接2.5D监督信号。
Anime-style 3D Avatars and Illustrations
对于3D角色艺术家来说,从肖像插图中制作3D模型是一项相当常见的任务;然而,从计算机图形学的角度来看,这种程式化的重建设置给已经不适定的问题增加了额外的模糊性。此外,虽然在流行的动漫/漫画领域有使用3D角色资产的工作(姿势估计[18],重新定位[17,20]和休息[22]等),但缺乏公开可用的多视图渲染3D角色资产,允许可扩展的训练(表1)。鉴于这些问题,我们提出AnimeRecon(图1d)通过配对的插图到3D基准来形式化风格化任务。并提供3D资产的Vroid数据集(图1c),以实现大规模训练。
在程式化重建问题中,我们解决了从插图中去除轮廓的问题。在线条提取[21,38]、草图简化[33,34]、线条重建[11,24]、艺术图像的线条利用[6,41]和划线去除[8,27,29,32,35]方面有很多工作;然而,从基于线条的插图中删除线条却很少受到关注。我们在更有利于3D重建的渲染图像中调整图纸的背景下研究了这种轮廓删除任务;我们发现朴素的图像到图像翻译[19,45]不适合这项任务,并提出了一种简单而有效的带有面部特征感知的对抗性训练设置。最后,我们提供了一个Vtuber肖像数据集(图1b)来训练和评估用于3D重建的轮廓去除。
Methodology
PAniC-3D由两个主要组件组成(图1a):一个直接监督的3D重建器,用于预测给定前端渲染的辐射场,以及一个将图像转换为重建器训练分布的插图-渲染模块。这两个部分是独立训练的,但在推理时是顺序使用的。
3D Reconstruction Module
3D重建模块图3在直接监督下进行训练,将正面渲染转换为体积辐射场。我们以最近的无条件生成工作(EG3D[4])为基础,将重建问题表述为条件生成问题,提出了几种架构改进,并应用我们的3D数据集提供的直接2.5D监督信号。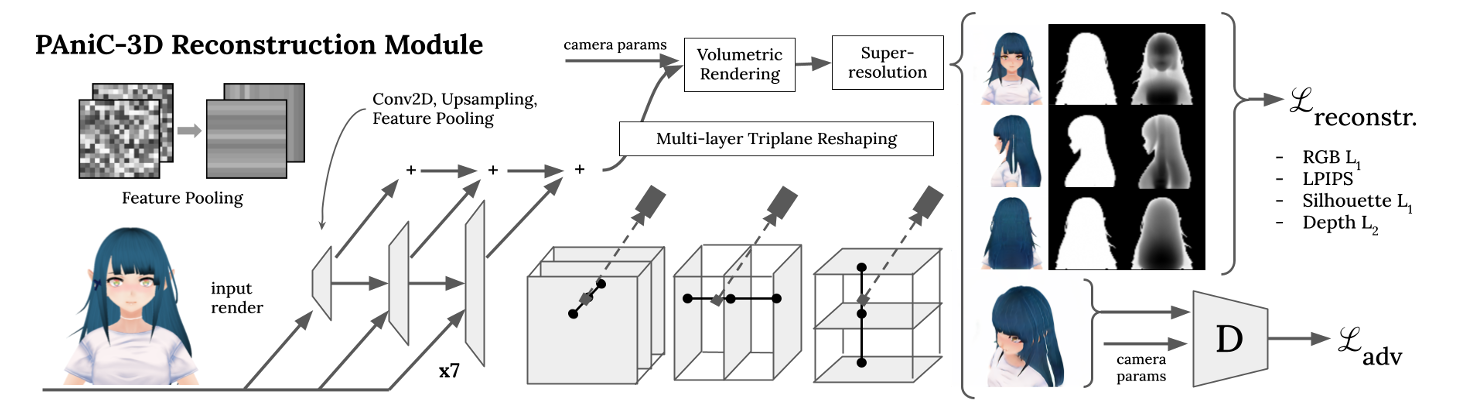
- Conditional inputinput条件输入:将给定的要重建的正面正交视图调整大小并附加到EG3D中使用的Stylegan2主干的中间特征图中[4]。此外,在最早的特征映射中,我们通过连接预训练的Resnet-50动画标注器的倒数第二个特征,为模型提供有关输入的高级领域特定语义信息。所述标注器提供适合调节所述生成器的高级语义特征;之前的工作[7]对1062个相关类别进行了预训练,如蓝头发、猫耳朵、双辫子等
- Feature pooling特征池化:由于空间特征映射将像EG3D[4]一样被重新塑造成三维三平面,我们发现沿着图像轴将每个特征映射的一部分通道池化是有益的(见图3左)。这种简单的技术有助于沿着公共三平面轴分发信息,从而提高几何度量的性能。
- Multi-layer triplane多层三平面:根据并行工作[1]中提出的,我们通过在每个平面上堆叠更多通道来改进EG3D三平面(见图3中心)。该方法可以解释为三平面和体素网格之间的混合(如果层数等于空间大小,它们是等效的)。当双线性采样时,每个平面设置三层可以更好地消除空间歧义,特别是有助于我们的模型生成更可信的头部背面(EG3D没有面临的挑战)。
- Loss损失:我们充分利用了我们可用的3D资产提供给我们的真实2.5D表示。我们的重建损失包括:RGB L1、LPIPS[42]、轮廓L1和深度L2;这些应用于前、后、右和左正射影视图,如图3所示。除了保持生成方向外,还采用了判别损失来提高细节质量。我们还保留了EG3D训练中的R1和密度正则化损失。我们的2.5D表示和对抗性设置使我们能够超越类似的单视图重构器,如PixelNerf[40],它只适用于颜色损失
- Post-processing后处理:我们利用我们的假设,即正面视图作为输入,通过在推理时将给定的输入拼接到生成的亮度场。每个像素的交点在体内的坐标被用来采样作为一个uv纹理图的输入;我们从每个交叉点投射一些额外的光线来测试正面的可见性,并相应地应用纹理。这种简单而有效的方法以可忽略不计的成本提高了输入的细节保存。
Illustration-to-Render Module
为了去除输入插图中存在的不真实的等高线,但在漫射光照场中不存在,我们设计了一个插图-渲染模块(图4)。假设可以访问未配对的插图和渲染(分别是我们的Vtuber和Vroid数据集),浅网络在绘制的线条附近重新生成像素颜色,以便对抗性地匹配渲染图像分布。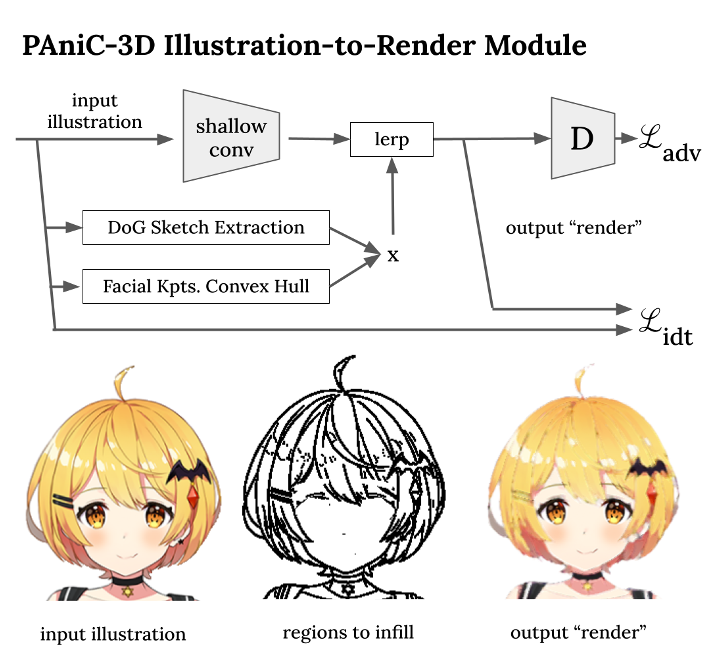
与CycleGAN和UGATIT[19,45]等未配对的图像对图像模型类似,我们也施加了小的身份损失;虽然这对于我们的填充情况似乎适得其反,因为在非生成区域中保留了身份,但我们发现这可以稳定GAN训练。请注意,我们的设置也不同于其他填充模型,因为我们的着色是为了匹配与输入不同的分布。根据之前的工作,从基于线的动画中提取草图[6],我们使用简单高斯差分(DoG)算子,以防止在每个笔画周围提取双线。
虽然图纸中出现的大多数线条应该被删除,但关键面部特征周围的某些线条必须保留,因为它们确实出现在效果图中(眼睛,嘴巴,鼻子等)。我们使用了一个现成的动漫面部地标检测器[16],在关键结构周围创建凸壳,其中不允许填充。
我们展示了这个线移除模块确实实现了一个更像渲染的外观;当在我们的AnimeRecon对上进行评估时,它比基线方法更准确地执行图像平移(表4),并从最终的亮度场渲染中去除线伪影(图6)。