NeRF代码(基于Pytorch)。流程图:train流程图 and 渲染流程图 (基于Drawio)
train流程
if use_batching
config_parser()
1 | def config_parser(): |
load_???_data()
load_llff_data()
输入:
- args.datadir :’./data/llff/fern’
- args.factor,
- recenter=True,
- bd_factor=.75,
- spherify=args.spherify
- path_zflat=False
输出:
load_blender_data(basedir, half_res=False, testskip=1)
输入:
- basedir,数据集路径’E:\\3\\Work\dataset\\nerf_synthetic\\chair’
[!info]- chair 文件夹
- chair:
- test
- 200张png 800x800x4
- train
- 100张png
- val
- 100张png
- .DS_Store
- transforms_test.json
- transforms_train.json
- transforms_val.json
- test
- chair:
- half_res,是否将图像缩小一倍 (下采样)
- testskip,测试集跳着读取图像
输出: - imgs:train、val、test,三个集的图像数据 imgs.shape : (400, 800, 800, 4)
- poses:相机外参矩阵,相机位姿 poses.shape : (400, 4, 4) 400张图片的4x4相机外参矩阵
- render_poses:渲染位姿,生成视频的相机位姿(torch.Size([40, 4, 4]):40帧)
- [H, W, focal] 图片数据,高、宽、焦距
- i_split,三个array数组
- 0,1,2,…,99 (100张train图像)
- 100,101,…,199 (100张val图像)
- 200,201,…399 (200张test图像)
create_nerf(args)
输入:
- args,由命令行和默认设置的arguments共同组成的字典
1
2parser = config_parser()
args = parser.parse_args()
输出:
- render_kwargs_train
- render_kwargs_test
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22render_kwargs_train = {
'network_query_fn' : network_query_fn,
'perturb' : args.perturb, # 默认为1 --perturb:在训练时对输入进行扰动
'N_importance' : args.N_importance, # --N_importance:每条射线的附加精细采样数
'network_fine' : model_fine,
'N_samples' : args.N_samples, # --N_samples:每条射线的粗略采样数
'network_fn' : model,
'use_viewdirs' : args.use_viewdirs, # --use_viewdirs:使用全5D的输入代替3D的输入
'white_bkgd' : args.white_bkgd,
'raw_noise_std' : args.raw_noise_std, # 默认0 --raw_noise_std:添加到输入的噪声标准差
}
# NDC only good for LLFF-style forward facing data
# NDC 全称是 Normalized Device Coordinates,即归一化设备坐标
if args.dataset_type != 'llff' or args.no_ndc:
print('Not ndc!')
render_kwargs_train['ndc'] = False
render_kwargs_train['lindisp'] = args.lindisp
render_kwargs_test = {k : render_kwargs_train[k] for k in render_kwargs_train}
render_kwargs_test['perturb'] = False
render_kwargs_test['raw_noise_std'] = 0. - start :global step
- grad_vars:model的参数列表,包括权重和偏置
grad_vars = list(model.parameters())- if args.N_importance > 0:
grad_vars += list(model_fine.parameters())
- optimizer
1
2
3optimizer = torch.optim.Adam(params=grad_vars, lr=args.lrate, betas=(0.9, 0.999))
if 加载了ckpt : optimizer.load_state_dict(ckpt['optimizer_state_dict'])
get_embedder(args.multires, args.i_embed)
输入:
- args.multires, 输入的L
- args.i_embed,默认为0,使用位置编码,-1为无位置编码
输出:
- embed, 位置编码函数,
将(1024 * 32 * 64) * 3处理为 (1024 * 32 * 64) * 63- input_ch = 3 , L = 10 并且包括输入维度
- embedder_obj.out_dim : 输出的维度
Embedder()
1 | class Embedder: |
NeRF(nn.Module)
继承nn.Module构建的类
def init(self, D=8, W=256, input_ch=3, input_ch_views=3, output_ch=4, skips=[4], use_viewdirs=False)
1 | model = NeRF(...) 实例化 |
- D=args.netdepth, W=args.netwidth
- input_ch=input_ch, output_ch=output_ch
- skips=skips,
- input_ch_views=input_ch_views
- use_viewdirs=args.use_viewdirs
network_query_fn
1 | network_query_fn = lambda inputs, viewdirs, network_fn : run_network(inputs, viewdirs, network_fn, |
if render_only:
render_path()
输入:
- render_poses, 测试集的渲染相机位姿 200 4 4
- hwf,
- K, 相机内参矩阵
- chunk,
args.chunk=1024*32 - render_kwargs = render_kwargs_test
- gt_imgs=None,
- savedir=None,
- render_factor=0
输出:
- rgbs, 200 x W x H x 3
- disps,200xWxH
1 | render_path(render_poses, hwf, K, args.chunk, render_kwargs_test, gt_imgs=images, savedir=testsavedir, render_factor=args.render_factor) |
render()
1 | rgb, disp, acc, _ = render(H, W, K, chunk=chunk, c2w=c2w[:3,:4], **render_kwargs) |
get_rays_np(H, W, K, c2w) numpy版本(narray)
通过输入的图片大小和相机参数,得到从相机原点到图片每个像素的光线(方向向量d和相机原点o)
输入:
- H:图片的高
- W:图片的宽
- K:相机内参矩阵
1
2
3
4
5K = np.array([
[focal, 0, 0.5*W],
[0, focal, 0.5*H],
[0, 0, 1]
]) - c2w:相机外参矩阵
1
2
3
4
5c2w = np.array([
[ -0.9980267286300659, 0.04609514772891998, -0.042636688798666, -0.17187398672103882],
[ -0.06279052048921585, -0.7326614260673523, 0.6776907444000244, 2.731858730316162],
[-3.7252898543727042e-09, 0.6790306568145752,0.7341099381446838, 2.959291696548462],
[ 0.0,0.0,0.0,1.0 ]])
输出:从相机原点到800x800图片中每个像素生成的光线 $r(t)=\textbf{o}+t\textbf{d}$
- rays_o:光线原点(世界坐标系下)(800, 800, 3)
- rays_d:光线的方向向量(世界坐标系下)(800, 800, 3)
需要对render输入的光线做batch: rays = batch_rays
render()
1 | (H, W, K, chunk=1024*32, rays=None, c2w=None, ndc=True,near=0., far=1.,use_viewdirs=False, c2w_staticcam=None, **kwargs) |
输入
- H
- W
- K
- chunk=args.chunk 同时处理光线的最大数量
- rays=batch_rays
[2, batch_size, 3] - verbose=i < 10
- retraw=True
- render_kwargs_train
1 | render_kwargs_train = { |
输出:ret_list + [ret_dict]
- rgb:
all_ret['rgb_map'] - disp:
all_ret['disp_map'] - acc:
all_ret['acc_map'] - extras:
[{'raw': raw , '...': ...}]
eg:all_ret['raw'] : W * H * N_samples +N_importance * 4
eg:all_ret['rgb_map'] : W * H * 3
渲染流程图
get_rays(H, W, K, c2w) torch版本(tensor)
通过输入的图片大小和相机参数,得到从相机原点到图片每个像素的光线(方向向量d和相机原点o)
输入:
- H:图片的高
- W:图片的宽
- K:相机内参矩阵
1
2
3
4
5K = np.array([
[focal, 0, 0.5*W],
[0, focal, 0.5*H],
[0, 0, 1]
]) - c2w:相机外参矩阵
1
2
3
4
5c2w = np.array([
[ -0.9980267286300659, 0.04609514772891998, -0.042636688798666, -0.17187398672103882],
[ -0.06279052048921585, -0.7326614260673523, 0.6776907444000244, 2.731858730316162],
[-3.7252898543727042e-09, 0.6790306568145752,0.7341099381446838, 2.959291696548462],
[ 0.0,0.0,0.0,1.0 ]])
输出:从相机原点到800x800图片中每个像素生成的光线 $r(t)=\textbf{o}+t\textbf{d}$
- rays_o:光线原点(世界坐标系下)(800, 800, 3)
- rays_d:光线的方向向量(世界坐标系下)(800, 800, 3)
ndc_rays(H, W, focal, near, rays_o, rays_d)
仅需要对LLFF做Projection 变换到NDC坐标系下
输入:
- H
- W
- focal
- near
- rays_o
- rays_d
输出:NDC坐标系下
- rays_o
- rays_d
batchify_rays(rays_flat, chunk=1024*32, **kwargs)
输入:
- rays_flat: (WxH)x8 or (WxH)x11
- chunk=1024*32
- **kwargs
输出:
- all_ret: 将ret = {‘rgb_map’ : rgb_map, ‘disp_map’ : disp_map, ‘acc_map’ : acc_map} 拼接起来
ret:chunk(1024 * 32) —> all_ret:800x800
render_rays()
输入:
- ray_batch
- 继承来自render()输入的参数:
- network_fn,
- network_query_fn,
- N_samples,
- retraw=False,
- lindisp=False,
- perturb=0.,
- N_importance=0, 每条光线增加的采样数
- network_fine=None,
- white_bkgd=False,
- raw_noise_std=0.,
- verbose=False,
- pytest=False
输出:
ret = {‘rgb_map’ : rgb_map, ‘disp_map’ : disp_map, ‘acc_map’ : acc_map}1
2
3
4
5
6
7
8if retraw:
ret['raw'] = raw
if N_importance > 0:
ret['rgb0'] = rgb_map_0
ret['disp0'] = disp_map_0
ret['acc0'] = acc_map_0
ret['z_std'] = torch.std(z_samples, dim=-1, unbiased=False) # [N_rays]
run_network(inputs, viewdirs, fn, embed_fn, embeddirs_fn, netchunk=1024*64)
输入:
- inputs
- viewdirs
- fn:network_fn = model ,经过一次MLP训练
- embed_fn
- embeddirs_fn
- netchunk=1024*64
输出:
- outputs: chunk N_samples 4 (每条光线,每个采样点的RGBσ)
在这里调用了run_network函数1
2
3
4 network_query_fn = lambda inputs, viewdirs, network_fn : run_network(inputs, viewdirs, network_fn,
embed_fn=embed_fn,
embeddirs_fn=embeddirs_fn,
netchunk=args.netchunk)
batchify(fn, chunk)
输入:
- fn : model
- chunk : 1024* 32
如果chunk没有数据,则返回fn,否则:1
2
3def ret(inputs):
return torch.cat([fn(inputs[i:i+chunk]) for i in range(0, inputs.shape[0], chunk)], 0)
# 每个chunk的大小为1024*32,即每次fn处理1024*32个点,最后返回结果
raw2outputs(raw, z_vals, rays_d, raw_noise_std=0, white_bkgd=False, pytest=False)
体渲染在其中
chunk = N_rays,射线数
输入:
- raw: chunk N_samples 4
- z_vals: chunk * N_samples
- rays_d: chunk * 3
- raw_noise_std=0,
- white_bkgd=False,
- pytest=False)
输出:
- rgb_map,
[chunk, 3] - disp_map:
[chunk] - acc_map:
[chunk] - weights:
[chunk, N_samples] - depth_map:
[chunk]
sample_pdf(bins, weights, N_samples, det=False, pytest=False)
输入:
- bins, chunk * 63
- weights, chunk * 62
- N_samples = N_importance
- det=False = (perturb\==0.)
- pytest=False
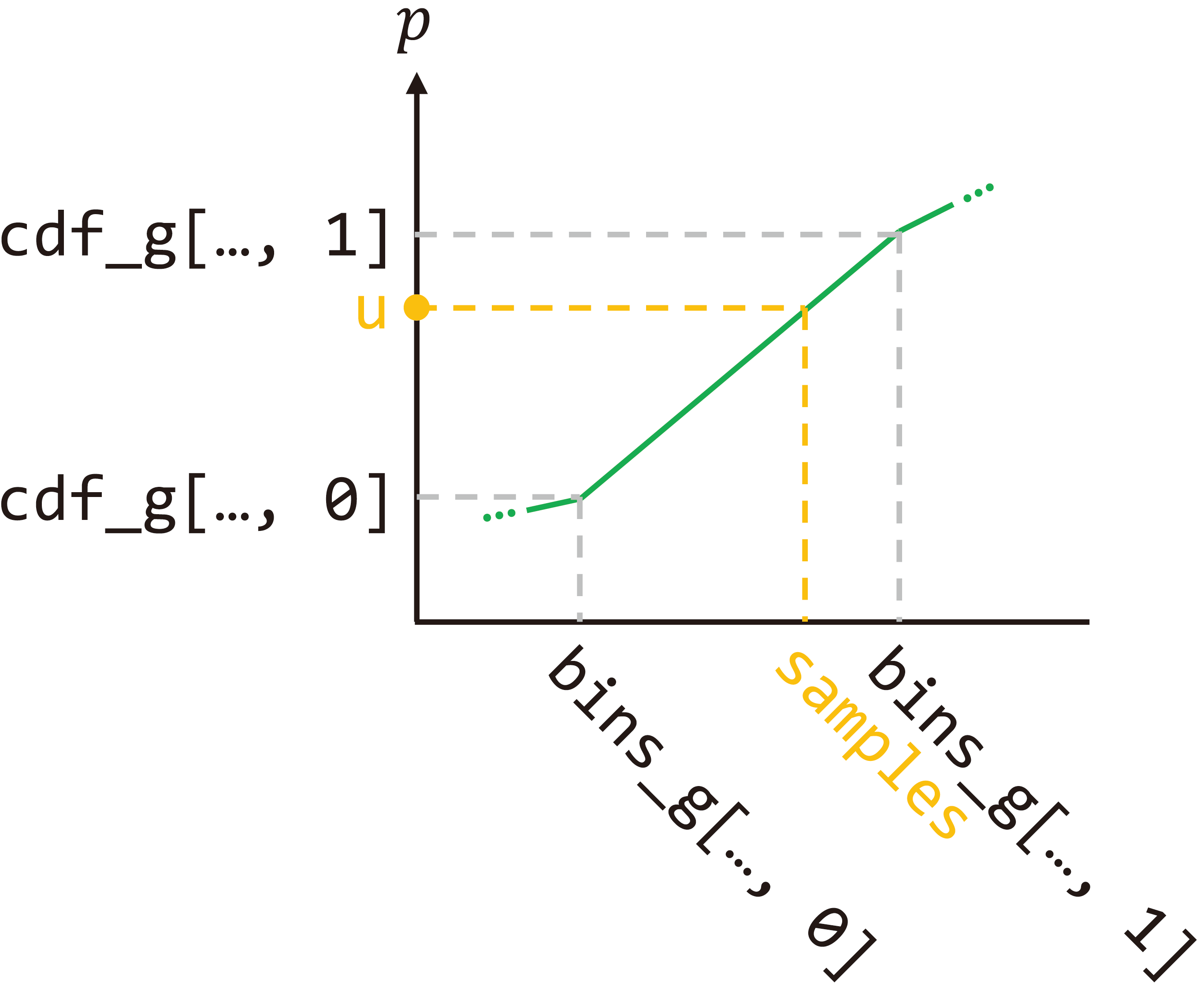
输出:
- samples: chunk * N_importance
img2mse() and mse2psnr()
1 | img2mse = lambda x, y : torch.mean((x - y) ** 2) |
数学公式:
$\text{MSE}(x, y) = \frac{1}{N}\sum_{i=1}^{N}(x_i - y_i)^2$
$\text{PSNR}(x) = -10 \cdot \frac{\ln(x)}{\ln(10)}$