| Title | A Critical Analysis of NeRF-Based 3D Reconstruction |
|---|---|
| Author | Fabio Remondino , Ali Karami , Ziyang Yan, Gabriele Mazzacca , Simone Rigon and Rongjun Qin |
| Conf/Jour | MDPI remote sensing |
| Year | 2023 |
| Project | A Critical Analysis of NeRF-Based 3D Reconstruction |
| Paper | A Critical Analysis of NeRF-Based 3D Reconstruction (readpaper.com) |
对比photogrammetry与NeRF在3D Reconstruction中的表现,提供数据集Github_NeRFBK
- photogrammetry(Colmap)
- 对无纹理物体重建效果很差(non-collaborative surfaces的3D测量),例如镜面反射物体
- 非协作表面: 反射、无纹理等
- 对无纹理物体重建效果很差(non-collaborative surfaces的3D测量),例如镜面反射物体
- NeRF(InstantNGP | NerfStudio | SDFstudio)
结论:
- 在传统摄影测量方法失败或产生嘈杂结果的情况下,例如无纹理、金属、高反射和透明物体,NeRF优于摄影测量
- 对于纹理良好和部分纹理的物体,摄影测量仍然表现更好
该研究为NeRF在不同现实场景中的适用性提供了有价值的见解,特别是在遗产和工业场景中,这些场景的表面可能特别具有挑战性,未来的研究可以探索NeRF和摄影测量的结合,以提高具有挑战性场景下三维重建的质量和效率
Conclusions
本文对神经辐射场(NeRF)方法在基于图像的三维重建中的应用进行了全面分析。与传统摄影测量进行比较,报告定量和视觉结果,以了解在处理多种类型的表面和场景时的优缺点。
该研究客观地评估了nerf生成的3D数据的优缺点,并深入了解了它们在不同现实场景和应用中的适用性。
该研究采用了一系列纹理良好的、无纹理的、金属的、半透明的和透明的物体,使用不同的比例和图像集进行成像。使用各种评估方法和指标对生成的基于nerf的3D数据的质量进行评估,包括噪声水平、表面偏差、几何精度和完整性。
报告的结果表明,在传统摄影测量方法失败或产生嘈杂结果的情况下,例如无纹理、金属、高反射和透明物体,NeRF优于摄影测量。相比之下,对于纹理良好和部分纹理的物体,摄影测量仍然表现更好。这是因为基于NeRF的方法能够生成与反射率和透明度相关的几何形状,这是由于NeRF模型依赖于视图的特性。
该研究为NeRF在不同现实场景中的适用性提供了有价值的见解,特别是在遗产和工业场景中,这些场景的表面可能特别具有挑战性。更多的数据集正在准备中,并将很快在Github_NeRFBK上共享[103]。研究结果突出了NeRF和摄影测量的潜力和局限性,为该领域的后续研究奠定了基础。未来的研究可以探索NeRF和摄影测量的结合,以提高具有挑战性场景下三维重建的质量和效率。
AIR
摘要:本文对基于图像的三维重建进行了批判性分析,并将其与传统摄影测量法photogrammetry进行了定量比较。因此,目的是客观地评估NeRF的优势和劣势,并深入了解其在不同现实场景中的适用性,从小型物体到遗产和工业场景。在全面概述摄影测量和NeRF方法,突出各自的优点和缺点后,使用不同尺寸和表面特征的不同物体,包括无纹理,金属,半透明和透明表面,对各种NeRF方法进行比较。
我们使用多种标准评估生成的3D重建的质量,例如噪声水平、几何精度和所需图像的数量(即图像基线)。
结果表明,在具有无纹理、反射和折射表面的非协作对象方面,NeRF表现出优于摄影测量的性能。
相反,在物体表面具有协同纹理的情况下,摄影测量优于NeRF。这种互补性应在今后的工作中进一步加以利用。
Introduction
在计算机视觉和摄影测量领域中,高质量的三维重建是一个重要的课题,在质量检测、逆向工程、结构监测、数字保存等方面有着广泛的应用。然而,提供高几何精度和高分辨率细节的低成本,便携式和灵活的3D测量技术多年来一直需求量很大。
现有的三维重建方法大致可分为接触式和非接触式两大类[1]。
- 为了确定物体的精确3D形状,基于接触的技术通常使用物理工具,如卡尺或坐标测量机。虽然精确的几何3D测量是可行的,并且非常适合于许多应用,但它们确实有一些缺点,例如获取数据和执行稀疏3D重建所需的时间长度,测量系统的局限性,和/或需要昂贵的仪器,这限制了它们在具有独特计量规范的专业实验室和项目中的使用。
- 另一方面,非接触式技术允许精确的3D重建,而没有相关的缺点。大多数研究人员都专注于被动图像方法,因为它们的低成本,便携性和灵活性在广泛的应用领域,包括工业检测和质量控制[2-5]以及遗产heritage 3D文档[6-9]。
在基于图像的三维重建方法中,摄影测量photogrammetry是一种被广泛认可的方法,它可以从不同角度拍摄的一组图像中创建真实场景的密集和几何精确的三维点云。摄影测量可以处理从室内到室外环境的各种场景,并且在多个项目中具有许多商业和开源工具[10,11]。然而,摄影测量有其局限性,特别是当涉及到非协作表面的3D测量时,由于其对物体纹理属性的敏感性,并且它可能难以生成非常详细的3D重建。例如,图像中镜面反射的存在会导致高反射和弱纹理物体的噪声结果,而透明物体由于折射和镜面反射引起的纹理变化会带来重大挑战[12-15]。
最近,一种基于神经辐射场(Neural Radiance Fields, NERF)的图像数据集三维重建的新方法引起了研究界的极大关注[16 - 22]。该方法通过优化一组定向图像的连续场景函数,能够生成复杂场景的新视图。NeRF的工作原理是训练一个完全连接的网络,称为神经辐射场,通过使用渲染损失来复制场景的输入视图(图1)。
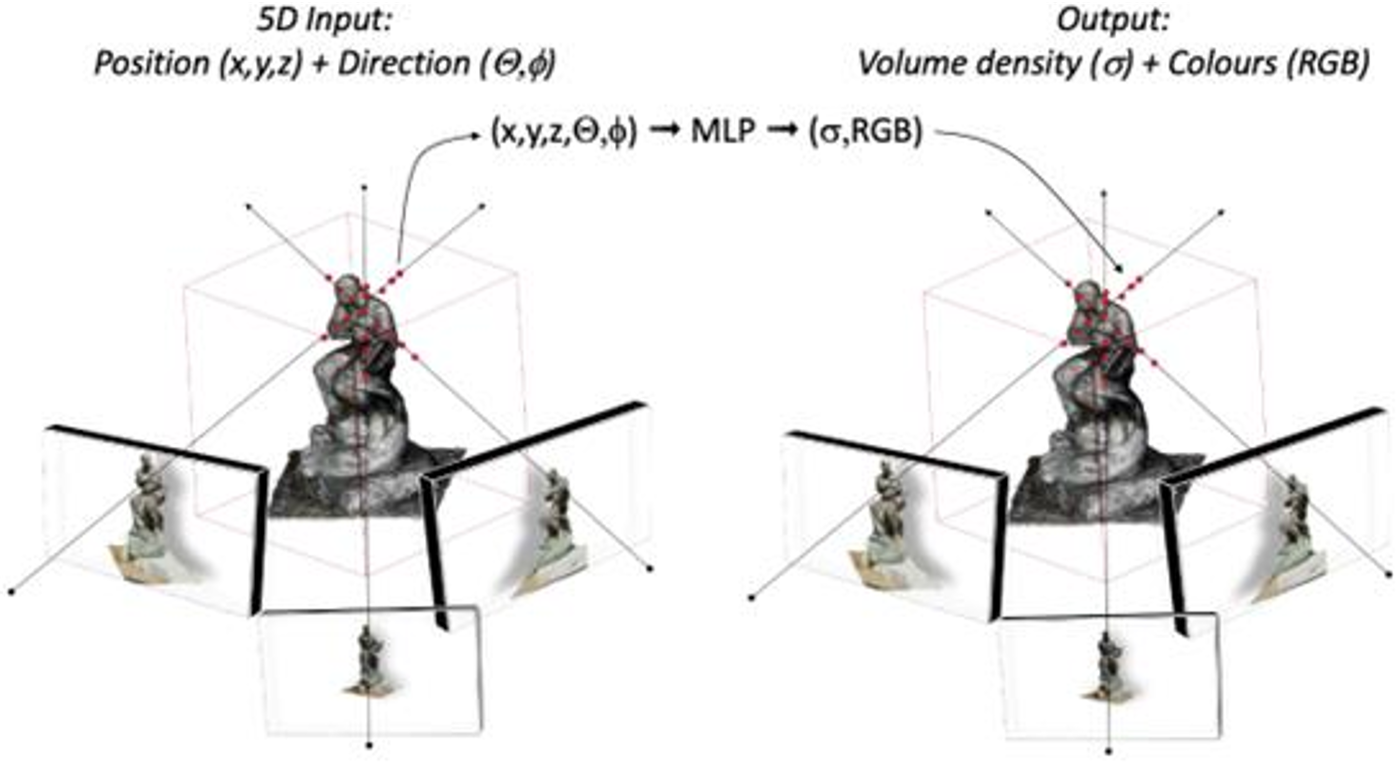
如图1所示,神经网络以一组由空间位置(x, y, z)和观看方向(θ, φ)组成的连续5D坐标作为输入,输出每个点在每个方向上的体积密度(σ)和与视图相关的发射亮度(RGB)。然后从某个角度渲染NeRF,并且可以导出3D几何形状,例如,通过行进相机光线以网格的形式[23]Marching cubes。
尽管它们最近很受欢迎,但是,与更传统的摄影测量相比,仍然需要对基于NeRF的方法进行批判性分析,以便客观地量化所产生的3D模型的质量,并充分了解它们的优势和局限性。
NeRF方法最近在基于图像的3D重建领域成为摄影测量和计算机视觉的一种有前途的替代方法。因此,本研究旨在深入分析NeRF方法用于3D重建目的。我们评估了使用基于NeRF的技术和通过摄影测量在尺寸和表面特征(纹理良好,无纹理,金属,半透明和透明)的各种物体上生成的3D重建的准确性。我们根据表面偏差(噪声水平)和几何精度检查了每种技术产生的数据。最终目的是评估NeRF方法在现实场景中的适用性,并提供关于基于NeRF的3D重建方法的优势和局限性的客观评估指标
本文组织如下:第2节介绍了以前使用基于摄影测量和基于NeRF的方法进行3D重建的研究活动的概述。第3节介绍了建议的质量评估管道和使用的数据集,而第4节报告了评估和比较结果。最后,在第5节给出结论和未来的研究计划。
The State of the Art(SOTA)
在本节中,全面概述了之前的3D重建研究,结合了摄影测量和基于NeRF的方法,并考虑了它们在非协作表面(反射、无纹理等)上的应用。
Photogrammetric-Based Methods
摄影测量是一种被广泛接受的对纹理良好的物体进行三维建模的方法,它能够通过多视图立体(MVS)方法准确可靠地恢复物体的三维形状。基于摄影测量的方法[19,24 - 30]要么依靠特征匹配进行深度估计[27,28],要么使用体素来表示形状[24,29,31,32]。也可以使用基于学习的MVS方法,但它们通常会取代经典MVS管道的某些部分,例如特征匹配[33 - 36],深度融合[37,38]或多视图图像深度推断[39 - 41]。然而,具有无纹理、反射或折射表面的物体重建具有挑战性,因为所有摄影测量方法都需要在多个图像之间匹配对应关系[14]。
为了解决这个问题,已经开发了各种摄影测量方法来重建这些非协作对象。对于无纹理的对象,已经提出了随机模式投影[13,42,43]或合成模式[14,44]等解决方案。然而,这些方法难以处理具有强镜面反射或互反射的高反射表面[43]。其他方法,如交叉极化[7,45]和图像预处理[46,47]已用于反射或非协同表面,但一些技术可能会平滑表面粗糙度并影响视图间的纹理一致性[48,49]。
摄影测量也用于混合方法[50 -53],其中MVS方法用于生成稀疏的3D形状,可以作为使用光度立体(PS)进行高分辨率测量的基础。传统的[52,54,55]和基于学习的[56 - 58]PS方法也用于理解图像辐照度方程和检索成像物体的几何形状,但镜面仍然是所有基于图像的方法的挑战。
NeRF-Based Methods
合成逼真的图像和视频是计算机图形学的核心,也是几十年来研究的焦点[59]。神经渲染是一种基于学习的图像和视频生成方法,用于控制场景属性(例如,照明,相机参数,姿势,几何形状,外观等)。神经渲染将深度学习方法与计算机图形学的物理知识相结合,以实现可控和逼真的场景(3D)模型。其中,由Mildenhall等人于2020年首次提出的NeRF是一种使用隐式表示呈现新视图并重建3D场景的方法(图1)。在NeRF方法中,使用神经网络从2D图像中学习物体的3D形状。如式(1)所定义的亮度场,从每个可能的观看方向捕获场景中每个点的颜色和体积密度:
$F(X,d)====>(c,\sigma)$ Eq.1
NeRF模型使用神经网络表示,其中X表示图像的三维坐标,d表示方位角和极视角,c表示颜色,σ表示场景的体积密度。为了保证多视角的一致性,σ的预测被设计成与观察方向无关,而颜色c可以根据观察方向和位置而变化。为了实现这一点,多层感知器(MLP)分两步使用。在第一步中,MLP以X作为输入,同时输出σ和高维特征向量。然后将特征向量与观察方向d结合,并通过另一个MLP,产生颜色表示c。
最初的NeRF实现以及随后的方法使用了不确定性分层抽样方法,如式(2)-(4)所示。这种方法包括将射线分成N个等间隔的箱子,并从每个箱子均匀地抽取一个样本:
$C(r)=\sum_{i=1}^N\alpha_iT_ic_i$ Eq.2
$T_i=e^{-\sum_{j=1}^{i-1}\sigma_j\delta_j}$ Eq.3
$\alpha_i=1-e^{\sigma_i\delta_i}$ Eq.4
其中$δ_i$表示连续样本(i和i + 1)之间的距离,$σ_i$和$c_i$表示沿样本点(i)的估计密度和颜色值。透明度或不透明度$α_i$在样本点(i)也使用式(4)计算。
连续的方法[60 - 62]也纳入了估计的深度,如式(5)所示,对密度施加限制,使它们类似于场景表面的类delta函数,或者在深度上强制平滑:
$D(r)=\sum_{i=1}^{N}\alpha_{i}t_{i}T_{i}$ Eq.5
为了优化MLP参数,对每个像素使用平方误差光度损失: $M=\sum_{r\in R}|C-C_{gt}|_{2}^{2}$
其中,变量$C_{gt}(R)$表示训练图像中与射线R对应的像素的地面真色,R表示与待合成图像相关联的射线批次。需要注意的是,NeRF的隐式3D表示被指定用于视图渲染。为了获得明确的三维几何图形,需要通过对每条光线取深度分布的最大似然来提取不同视图的深度图。然后可以将这些深度图融合以导出点云或输入Marching Cube[23]算法以导出3D网格。
尽管NeRF为3D重建提供了一种替代传统摄影测量方法的解决方案,并且可以在摄影测量可能无法提供准确结果的情况下产生有希望的结果,但正如不同作者所报道的那样,它仍然面临一些局限性[63 -68]。从3D计量的角度来看,需要考虑的一些主要问题包括:
- 生成的神经渲染图(随后转换为3D网格)的分辨率可能受到输入数据的质量和分辨率的限制。一般来说,更高分辨率的输入数据将产生更高分辨率的3D网格,但代价是增加了计算需求。
- 使用NeRF生成神经渲染(然后是3D网格)可能是计算密集型的,需要大量的计算能力和内存。
- 一般无法准确地模拟非刚性物体的三维形状。
- 原始NeRF模型是基于每像素RGB重建损失进行优化的,当仅使用RGB图像作为输入时,存在无限数量的与照片一致的解释,这可能导致噪声重建。
- NeRF通常需要大量具有小基线的输入图像来生成精确的3D网格,特别是对于具有复杂几何或遮挡的场景。在难以获取图像或计算资源有限的情况下,这可能是一个挑战。
针对上述问题,研究人员对原始NeRF方法进行了一些修改和扩展,以提高性能和3D结果。
- Tancik等人[69]和Sitzmann等人[70]在NeRF高频表示能力不足的情况下,为了提高神经渲染结果的分辨率,采用了与nerf不同频率的位置编码操作。
- 在此之后,其他方法侧重于以不同的方式提高神经渲染结果的效率和分辨率,包括模型加速[20,71]、压缩[72 -74]、重光照[75 -77]和视图依赖归一化[78],或高分辨率2D特征平面[68]。
- Müller等人[20]InstantNGP 引入了具有多分辨率哈希编码的即时神经图形原语的概念,该概念允许快速高效地生成3D模型。
- Barron等人[64,79]提出Mip-NeRF是原始NeRF的修改版本,允许在连续值尺度上表示场景, Mip-NeRF通过有效地渲染抗锯齿圆锥形截体而不是射线,大大增加了NeRF强调细节的能力。然而,该方法的局限性可能包括训练困难和计算效率问题。
- Chen等人[72]提出了一种名为TensoRF的新方法,用于将场景的亮度场建模和重建为4D张量。这种方法表示具有每体素多通道特征的3D体素网格。除了提供卓越的渲染质量之外,与以前和现代的方法相比,这种方法实现了更低的内存使用。
- Yang等人[80]提出了一种基于融合的方法,称为PS-NeRF,将NeRF的优势与光度立体方法相结合。该方法旨在通过利用NeRF重建场景的能力来解决传统光度立体技术的局限性,最终提高所得网格的分辨率。
- Reiser等人[68]引入了Memory-Efficient Radiance Field (MERF)表示,通过利用稀疏特征网格和高分辨率2D特征平面,可以快速渲染大规模场景。
- Li等人[21]介绍了Neuralangelo,这是一种利用多分辨率3D散列网格和神经表面渲染的创新方法,在从多视图图像中恢复密集的3D表面结构方面取得了优异的效果,可以从RGB视频捕获中实现非常详细的大规模场景重建。
- 已经提出了一些方法[67,81 - 85],将NeRF扩展到动态领域。这些方法使得重建和渲染物体的图像成为可能,而它们正在经历刚性和非刚性运动,从一个在场景中移动的相机。
- 例如,Yan等人[84]引入了表面感知的动态NeRF (NeRF- DS)和掩模引导的变形场。通过将表面位置和方向作为神经辐射场函数的调节因素,NeRF-DS改善了高光表面复杂反射特性的表征。此外,使用掩模引导的变形场使NeRF-DS能够有效地处理物体运动过程中发生的大变形和遮挡
- 为了提高存在噪声的三维重建的精度,特别是对于光滑和无纹理的表面,一些研究将各种先验纳入优化过程。
- 这些先验包括语义相似度[86]、深度平滑度[60]、表面平滑度[87,88]、曼哈顿世界假设[89]和单目几何先验[90]。
- 相比之下,Bian等人[91]提出的NoPe-NeRF方法使用单深度映射来约束帧之间的相对姿态并规范NeRF的几何形状。该方法具有较好的姿态估计效果,提高了新视图合成和几何重建的质量。
- Rakotosaona等人[92]为3D表面重建引入了一种新颖且通用的架构,该架构有效地将nerf驱动方法中的体积表示提取到签名表面近似网络中。这种方法可以提取精确的3D网格和外观,同时保持跨各种设备的实时渲染能力。
- Elsner等人[93]提出了自适应Voronoi nerf,这是一种通过使用Voronoi图将场景划分为单元来提高处理效率的技术。这些细胞随后被细分,以有效地捕获和表示复杂的细节,从而提高性能和准确性。
- 类似地,Kulhanek和Sattler[94]引入了一种名为tera-NeRF的新的亮度场表示,它成功地适应了作为稀疏点云给出的3D几何先验,以获取更多细节。然而,值得注意的是,渲染场景的质量可能会根据不同区域点云的密度而有所不同。
- 一些工作旨在减少输入图像的数量[60,70,78,86,90,95]。
- Yu等人[95]提出了一种架构PixelNeRF,该架构使用全卷积方法对图像输入条件NeRF,使网络能够在对多个场景进行训练之前学习一个场景。这允许它从少量视点执行前馈视图合成,甚至少到只有一个视点。
- 类似地,Niemeyer等人[60]引入了一种方法RegNeRF,对未见视图进行采样,并对这些视图生成的斑块的外观和几何形状进行正则化。
- Jain等人[86]提出了DietNeRF,通过辅助的语义一致性损失来增强少数镜头的质量,从而提高新位置的逼真渲染。DietNeRF从单个场景中学习,以准确地呈现来自相同位置的输入图像,并在不同的随机姿势中匹配高级语义特征。
- 在文化遗产领域,只有有限数量的出版物明确调查并认识到nerf在3D重建、数字保存和保护目的方面的潜力[96,97]。
Analysis and Evaluation Methodology
主要目标是通过客观测量产生的3D数据的质量,对基于nerf的传统摄影测量方法进行批判性评估。
为了实现这一点,我们考虑了各种不同大小和表面特征的物体和场景,包括纹理良好的、无纹理的、金属的、半透明的和透明的(第3.3节)。
拟议的评估策略和指标(第3.1和3.2节)应有助于研究人员了解每种方法的优势和局限性,并可用于对新提出的方法进行定量评估。
所有实验均基于SDFStudio[98]和Nerfstudio[22]框架。值得提醒的是,NeRF输出是一个神经渲染;因此,使用marching cube方法[23]从每个视图的不同深度图创建网格模型。然后从网格顶点提取点云,使用Open3D库[78]进行定量评估。
Proposed Methodology
首先,将专用框架[22,98]中可用的各种NeRF方法应用于两个数据集,以了解其性能并选择性能最佳的方法(第4.1节)。然后,将该方法应用于其他数据集,对常规摄影测量和可用的地面真值(GT)数据进行评估和比较(第4.2-4.7节)。
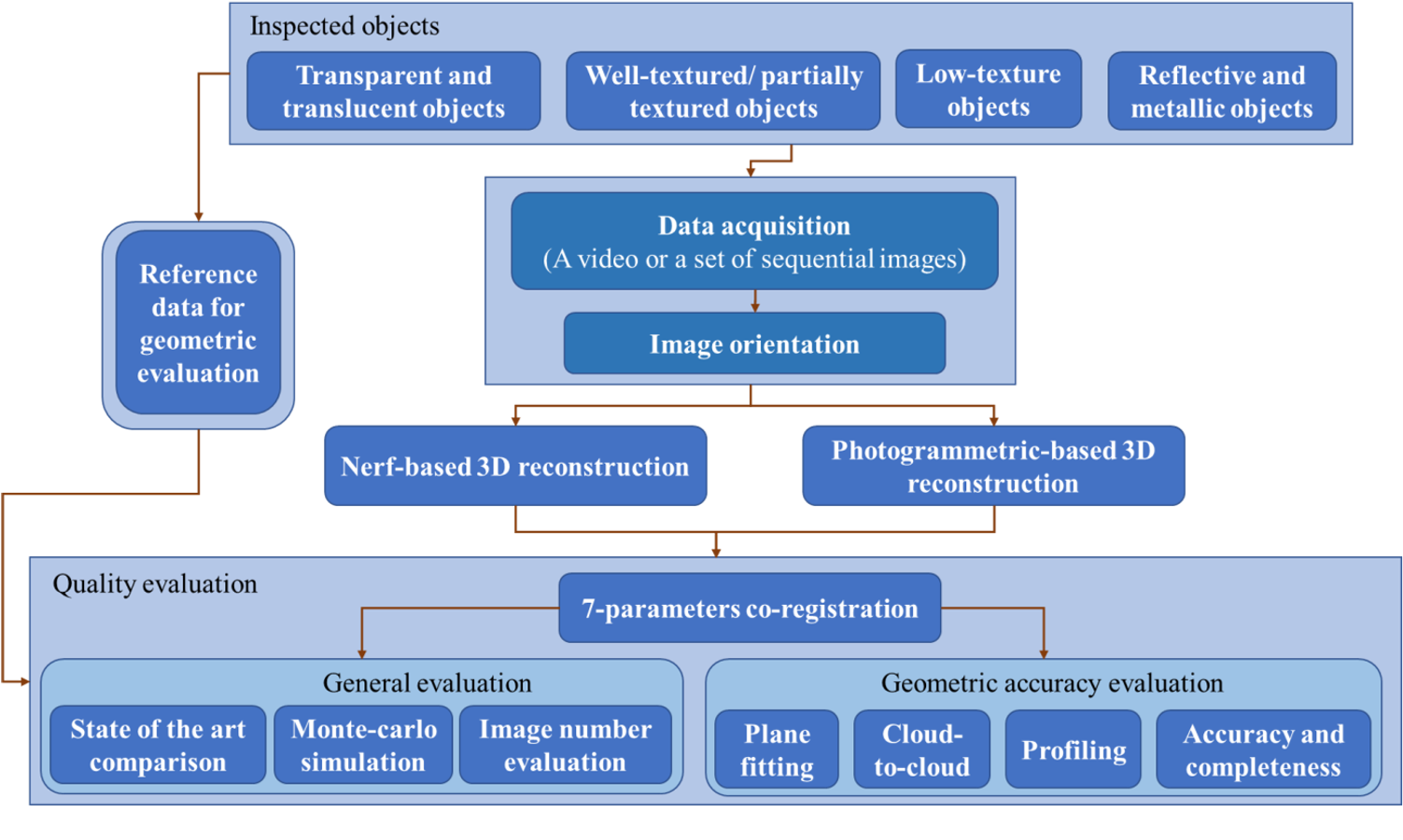
图2显示了proposed procedure的总体概述,用于定量评估基于nerf的3D重建的性能。
所有收集的图像或视频都需要相机姿势才能生成3D重建,无论是使用传统的摄影测量还是基于nerf的方法。
- 从可用图像开始,使用Colmap检索相机姿势。
- 然后,应用多视角立体(MVS)或NeRF来生成3D数据。
- 最后,我们提供了一个独特而强大的环境和条件,以提供客观的几何比较。为了实现这一目标,使用摄影测量和NeRF生成的3D数据在Cloud Compare(使用迭代最近点(ICP)算法[99])中相对于可用的地面真值(GT)数据进行共同注册和重新缩放,并进行质量评估。
为了提供对几何精度的无偏评估,应用了不同的知名标准[13,43,100 - 102],包括最佳平面拟合plane fitting、云对云比较、剖面分析profiling、精度和完整性completeness。
对于前两个标准,使用了标准偏差(STD)、平均误差(Mean_E)、均方根误差(RMSE)和平均绝对误差(MAE)等指标(第3.2节)。
- 最佳平面拟合是通过使用最小二乘拟合(LSF)算法来完成的,该算法在物体的一个区域上定义一个最佳拟合平面,假设该区域是平面的。该标准允许我们评估由摄影测量或NeRF m生成的3D数据中的噪声水平
- 通过从三维数据中提取截面来突出重建表面的复杂几何细节,从而进行剖面分析。对轮廓的检查使我们能够评估一种方法在保留几何细节(如边缘和角落)和避免平滑效果方面的性能。
- C2C (Cloud-to-cloud)比较是指测量两个点云中对应点之间的最近邻距离
Metrics
尽管NeRF在3D重建中越来越受欢迎和广泛应用,但仍然缺乏基于特定标准或标准(例如VDI/VDE 2643 BLATT 3)的质量评估信息。根据之前提到的共同注册过程和标准,使用以下指标(特别是云对云和plane fitting过程):
$STD=\sqrt{\frac{1}{N-1}\sum_{j=1}^{N}(X_{j}-\underline{X})^{2}}$ Eq.7
$Mean_E=\frac{(X_1+X_2+\cdots X_j)}{N}$ Eq.8
$RMSE=\sqrt{\frac{\sum_{j=1}^{N}(X_{j})^{2}}{N}}$ Eq.9
$\text{MAE} =\sqrt{\frac{\sum_{j=1}^N|X_j|}N}$ Eq.10
式中,N为观测点云的个数,$X_j$为每个点与相应参考点或参考面最近的距离,$X$为平均观测距离。
准确度(Accuracy)和完备性(completeness),也称为精确度(precision)和召回率(recall)[101,102],涉及测量两个模型之间的距离。
在评估精度时,计算从计算数据到地面真值(GT)的距离。相反,为了评估完整性,计算从GT到计算数据的距离。根据具体的评估方法,这些距离可以是有符号的,也可以是无符号的。准确性反映了重建点与地面真实值对齐的紧密程度,而完整性表示所有GT点被覆盖的程度。通常,使用阈值距离来确定落在可接受阈值内的点的分数或百分比。阈值是根据数据密度和噪声水平等因素确定的。
Testing Objects
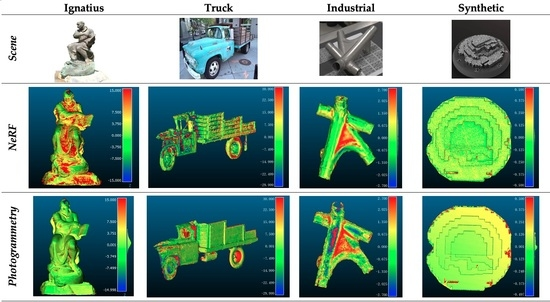
为了实现工作目标,使用了不同的数据集(图3):它们具有不同尺寸和表面类型的物体,并且在不同的照明条件、材料、相机网络、尺度和分辨率下捕获。

Ignatius和Truck数据集来源于Tanks和Temples基准[101],其中GT数据(通过激光扫描获得)也是可用的
其他数据集(Stair, Synthetic, Industrial, Bottle_1和Bottle_2)在FBK中创建。
- Stair数据集提供了一个具有锐利边缘的平坦、反射和纹理良好的表面。GT由台阶表面的理想平面提供。
- 使用Blender v3.2.2(用于几何模型,UV纹理和材料)和Quixel Mixer v2022(用于PBR纹理)创建的Synthetic 3D对象具有具有复杂几何形状的纹理良好的表面,包括边缘和角。具有特定参数的虚拟摄像机(焦距:50mm;传感器尺寸:36mm;图像大小:1920 × 1080像素)用于创建一系列图像,这些图像遵循对象周围的螺旋曲线路径。使用Blender中生成的3D模型作为GT进行精度评估。
- Industrial object具有无纹理和高反射的金属表面,这给所有被动3D方法带来了问题。其GT数据由Hexagon/AICON Primescan有源扫描仪获取,标称精度为63 μm。还包括两个瓶子,具有透明和折射表面:它们的GT数据是在表面粉末/喷涂后使用摄影测量法生成的。
作者正在准备NeRF方法的具体基准,并将在[103]上提供,其中包含更多具有地面真实数据的数据集
# NERFBK: A HOLISTIC DATASET FOR BENCHMARKING NERF-BASED 3D RECONSTRUCTION
Comparisons and Analyses
本节介绍了评估和比较基于nerf的技术与标准摄影测量(Colmap)性能的实验。在比较了多种最先进的方法(第4.1节)后,选择Instant-NGP作为基于nerf的方法进行全面评估,因为相对于其他方法,它提供了更好的结果。NeRF训练使用Nvidia A40 GPU执行,而3D结果的几何比较在标准PC上执行。
State-of-the-Art Comparison
主要目标是对多种基于nerf的方法进行综合分析。为了实现这一目标,我们使用了Yu等人[98]开发的SDFStudio统一框架,该框架将多种神经隐式表面重建方法整合到一个框架中。SDFStudio是建立在Nerfstudio框架上的[22]。在实现的方法中,选择了10种方法来比较它们的性能:
- 来自Nerfstudio的Nerfacto and Tensorf
- 来自SDFStudio的Mono-Neus, Neus-Facto, MonoSDF, VolSDF, NeuS, MonoUnisurf and UniSurf
- 以及来自Müller等人最初实现的InstantNGP[20]。
使用了两个数据集:
(i) 合成数据集,由200张图像(1920 × 1080像素)组成;
(ii) Ignatius dataset [101],包含263张图像(从1920 × 1080像素分辨率的视频中提取)
与GT数据的对比结果如图4所示。在RMSE、MAE和STD方面的结果表明,Instant-NGP和Nerfacto方法取得了最好的结果,优于所有其他方法。在处理时间方面,instantngp需要不到一分钟的时间来训练两个数据集的模型,Nerfacto大约需要15分钟。
应该注意的是,对于Ignatius序列(图4b),尽管MonoSDF、VolSDF和Neus-Facto的神经渲染在视觉上令人满意,但导出网格模型的行进立方体失败了;因此,不可能进行评估。
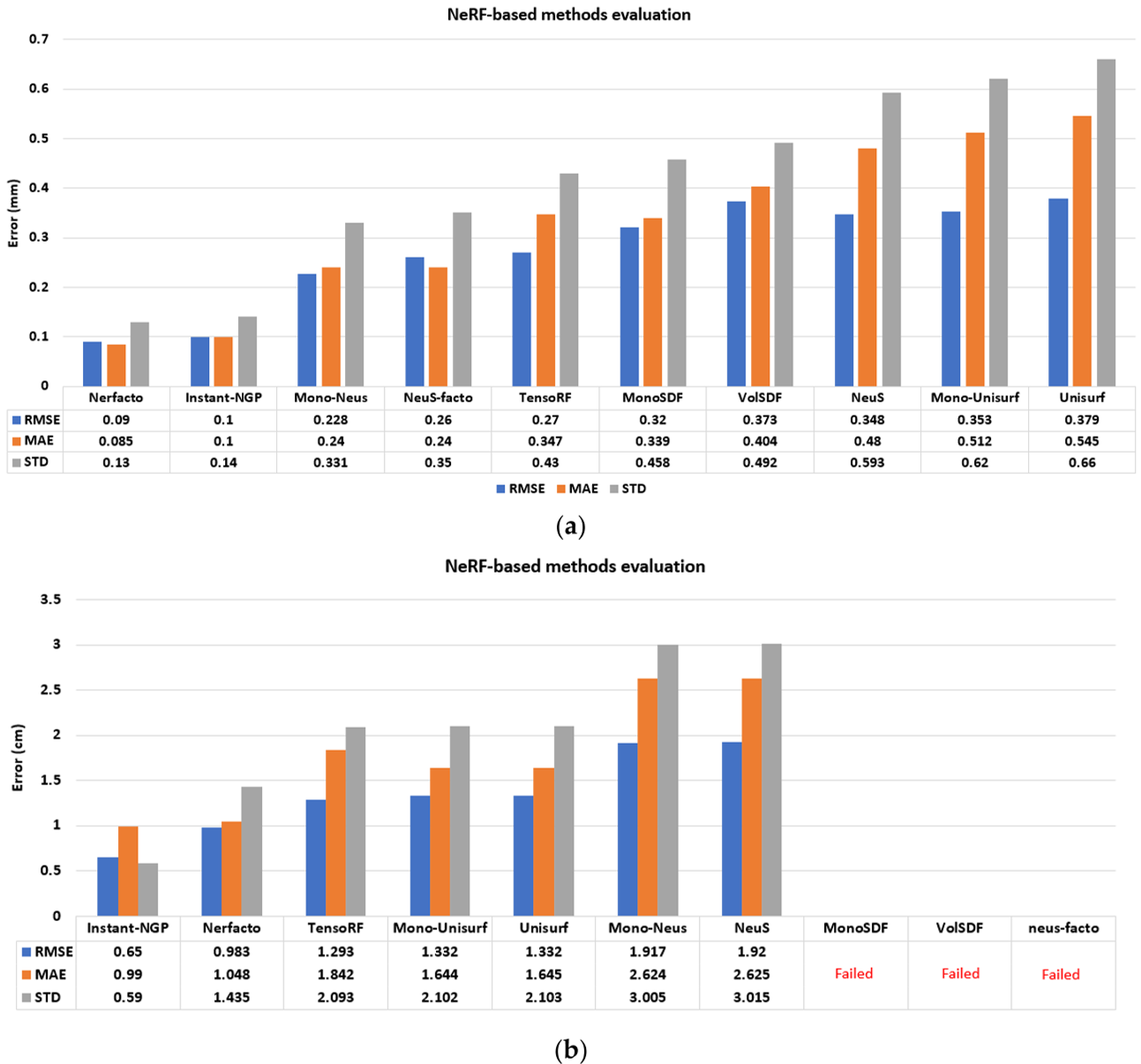
因此,根据所获得的精度和处理时间,本文选择了Instant-NGP进行后续实验。
Image Baseline’s Evaluation
本节报告了当输入图像数量减少(即基线增加)时基于nerf的方法的评估。
本文对被认为优于其他方法(第4.1节)的Instant-NGP和一种成熟的用于稀疏图像场景的方法Mono-Neus进行了比较评估[66,90]。
实验利用由四个输入图像子集组成的合成数据集,从200到20张图像不等(图5),逐步减少输入图像的数量(即大约加倍图像基线)。对于每一组输入图像,两种nerf方法都用于生成3D结果,保持相似的epoch数。对于每个子集,通过与GT数据点对点比较得出的RMSE估计如图5所示。

研究结果表明,当大量输入图像可用时,Instant-NGP表现出优于Mono-Neus的性能。然而,在图像数量较少的情况下,Mono-Neus优于Instant-NGP。然而,重要的是要注意,无论是Instant-NGP还是Mono-Neus都无法仅使用10个输入图像成功生成3D重建。
Monte Carlo Simulation
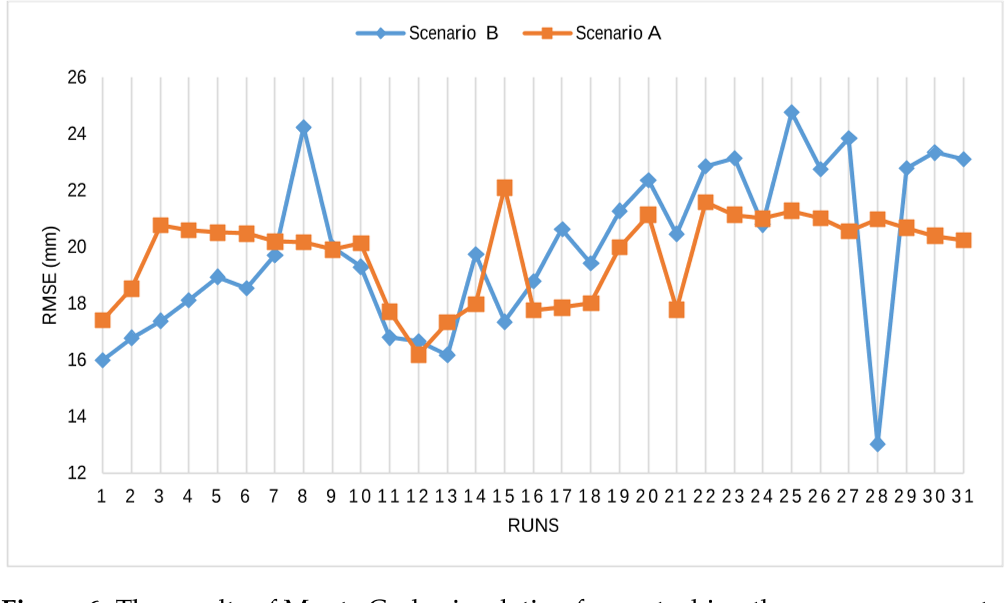
目的是在相机姿势改变/扰动时评估基于nerf的3D结果的质量。因此,采用蒙特卡罗模拟[104],在有限范围内随机扰动摄像机参数的旋转和平移。扰动后,使用Instant-NGP生成三维重建,并与参考数据进行比较。
在两种情况下共进行30次迭代(运行):
(A)在平移±20 mm和旋转±2度范围内随机扰动旋转和平移,
(B)在±40 mm和±4度范围内随机扰动旋转和平移。
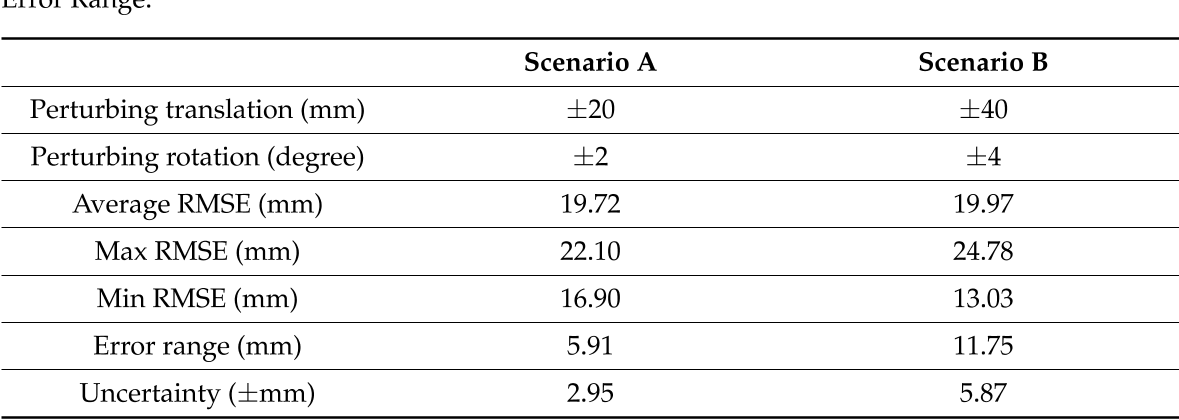
使用Ignatius数据集运行此模拟,结果如图6和表1所示。这些发现清楚地表明了拥有准确的相机参数的重要性。在情景A中,平均估计RMSE为19.72 mm,不确定性为2.95 mm。在情景B中,平均估计RMSE几乎保持不变(19.97 mm),而由于较大的扰动范围,不确定性增加了一倍(5.87 mm)。
Plane Fitting
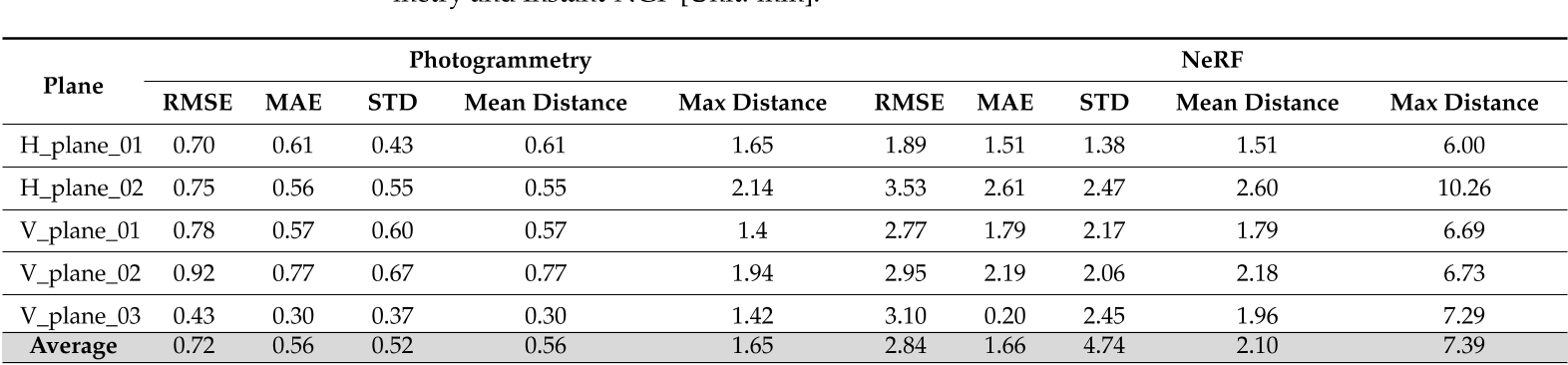
平面拟合方法可用于评估/测量重建平面上的噪声水平。在Stair数据集的第一个实验中(图7a),采用相同数量的图像和相机姿势,导出了摄影测量点云和基于nerf的重建。根据最佳拟合过程识别和分析两个水平面和三个垂直平面(图7b)。派生的度量如表2所示。

以类似的方式,使用了合成数据集,其中200张图像用于Instant-NGP, 24张图像用于摄影测量处理。选择5个垂直平面和5个水平面,如图8所示,通过拟合理想平面来进行重构对象表面的曲面偏差分析。派生的度量报告在表3中。
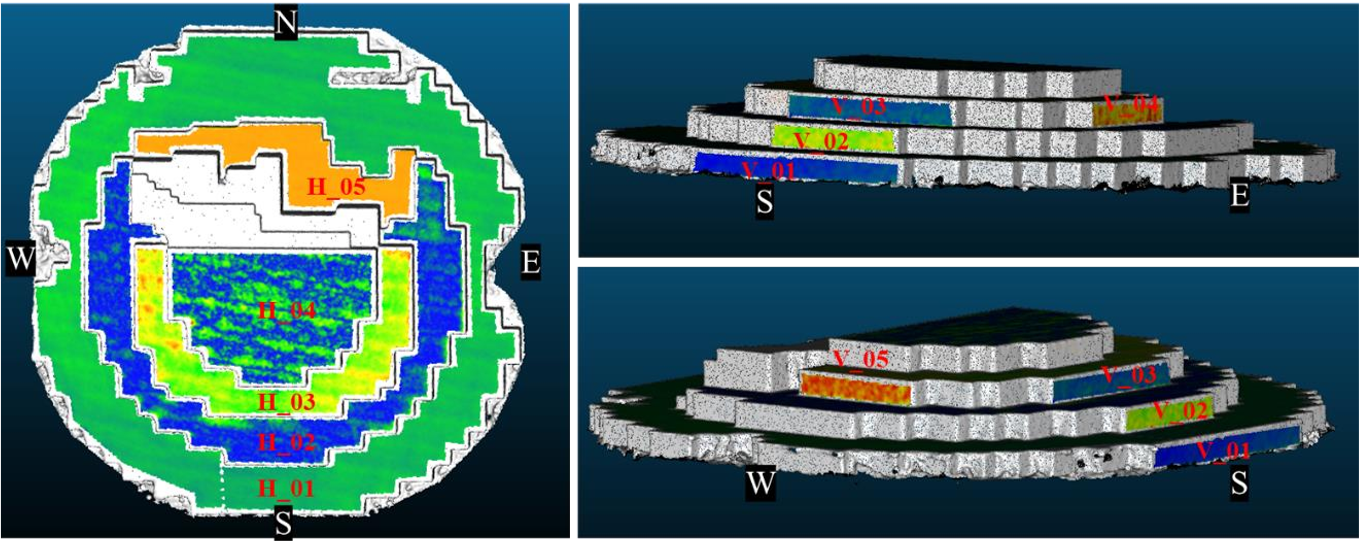
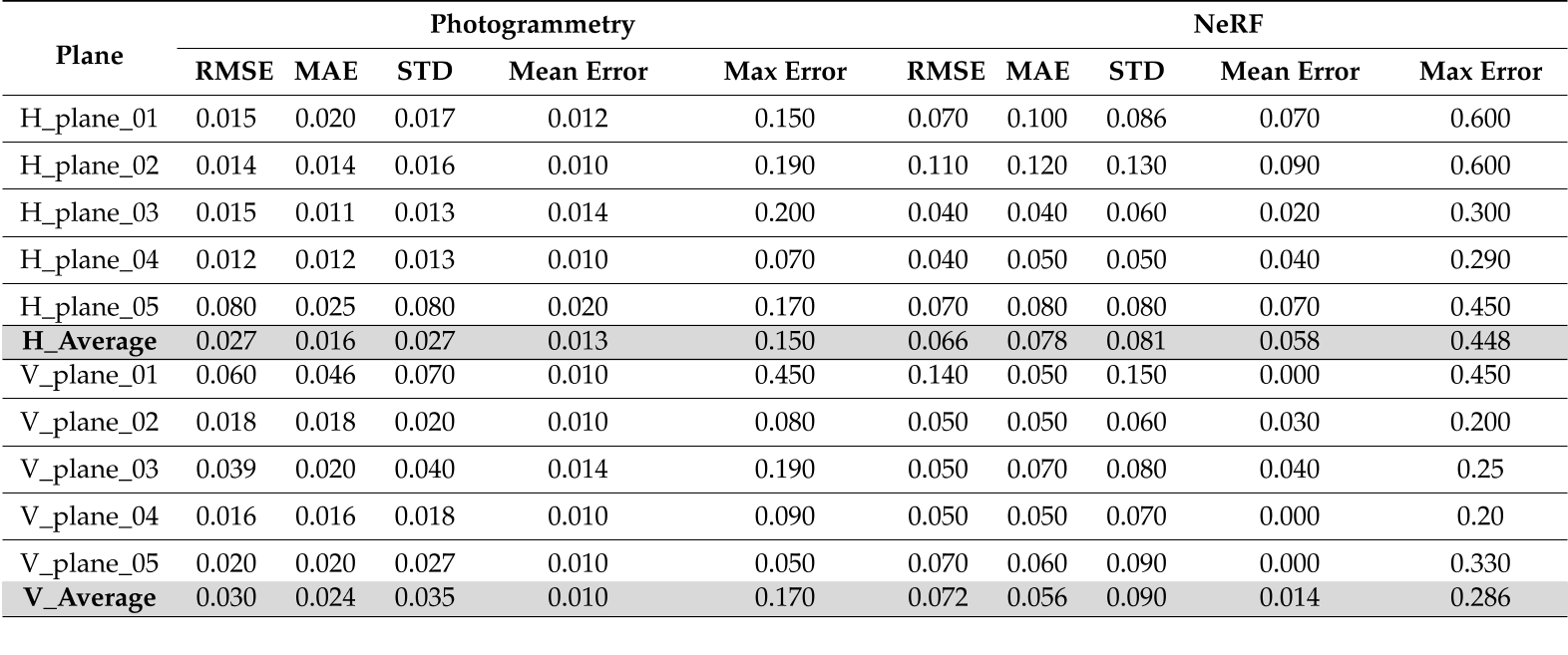
从两个结果(表2和表3)可以清楚地看出,对于这两个对象,摄影测量优于NeRF,并且可以获得更少的噪声结果。一般来说,NeRF的均方根误差至少比摄影测量高2-3倍。
Profiling
截面轮廓的提取有助于证明三维重建方法检索几何细节或对三维几何应用平滑效果的能力。使用Cloud Compare处理第4.4节中提供的合成数据集的结果:在预定义的距离上提取几个横截面(图9),并使用不同的指标与参考数据进行几何比较,如表4所示
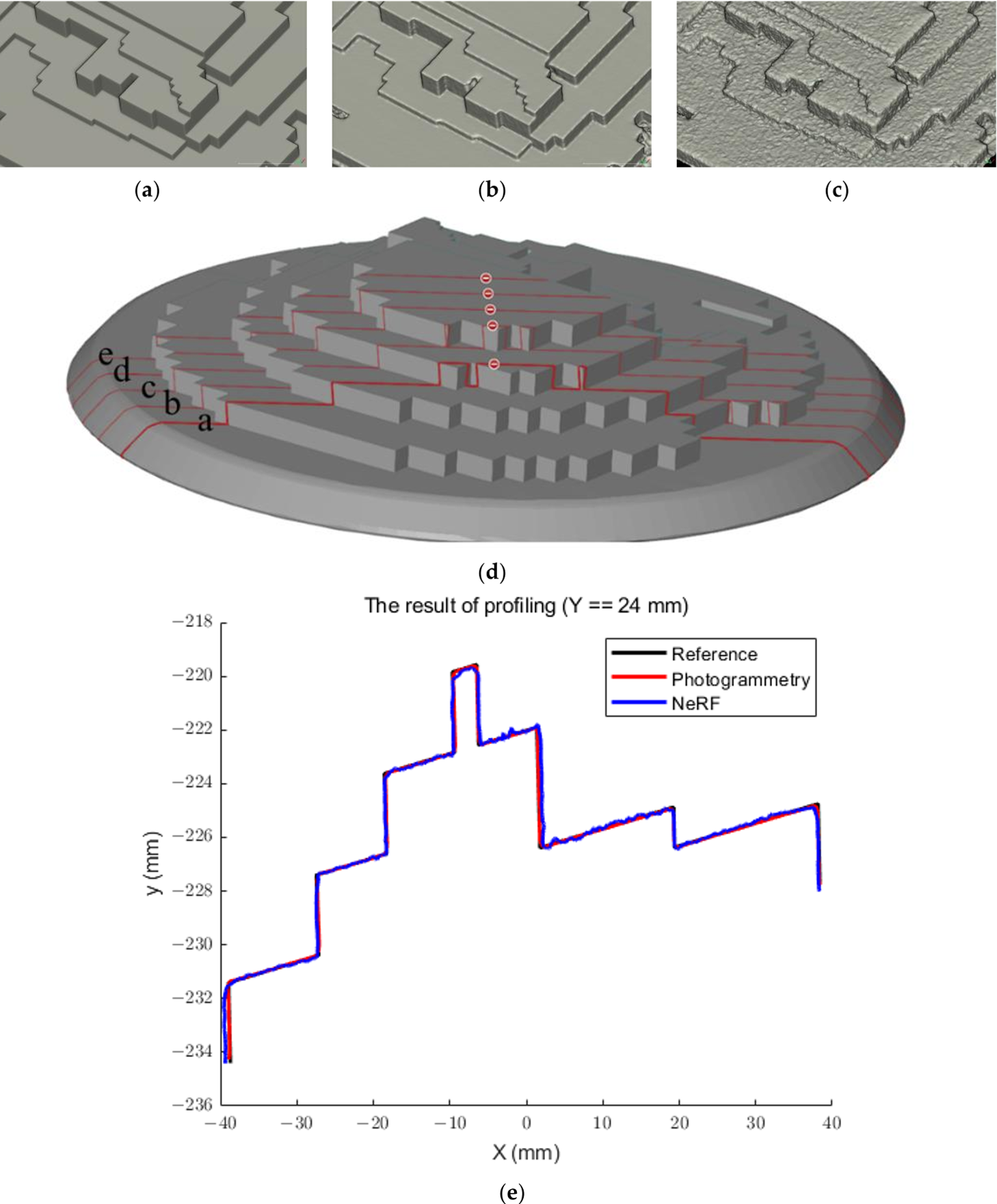
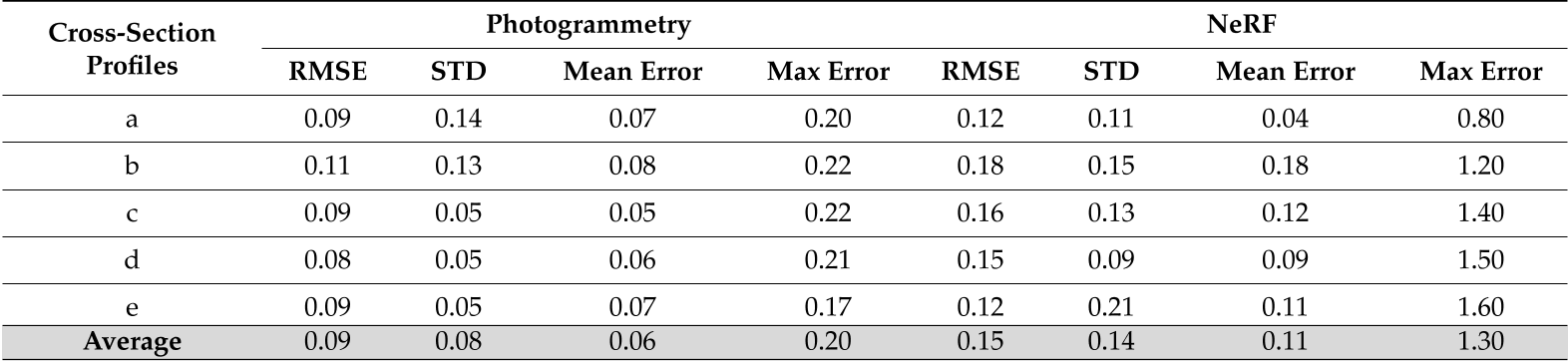
对单个横截面剖面以及所有剖面的平均值所获得的结果表明,摄影测量优于NeRF,后者通常会产生更多的噪声结果(图9a-c)。例如,摄影测量的估计RMSE和STD的平均值约为0.09 mm和0.08 mm,而NeRF的这个值大于0.13 mm
Cloud-to-Cloud Comparison
云对云比较是指评估数据集中相应3D样本相对于参考数据之间的相对欧几里得距离。
考虑具有不同特征的不同对象(图3):Ignatius、Truck、Industrial和Synthetic。它们是小型和大型的物体,具有无纹理,闪亮和金属表面。
对于每个数据集,使用摄影测量(Colmap)和Instant-NGP生成3D数据,然后共同注册到可用的GT(图10)。最后,度量的推导如表5所示。值得注意的是,在执行的测试中使用的图像数量并不总是相同的:
事实上,对于Synthetic、Ignatius和Truck数据集,
- 摄影测量已经用较少的图像数量提供了准确的结果,因此增加更多的图像不会导致进一步的改进。
- 另一方面,对于NeRF,所有可用的图像都被使用,因为较少的图像(或扩大基线)不会导致良好的结果(参见4.2节)。
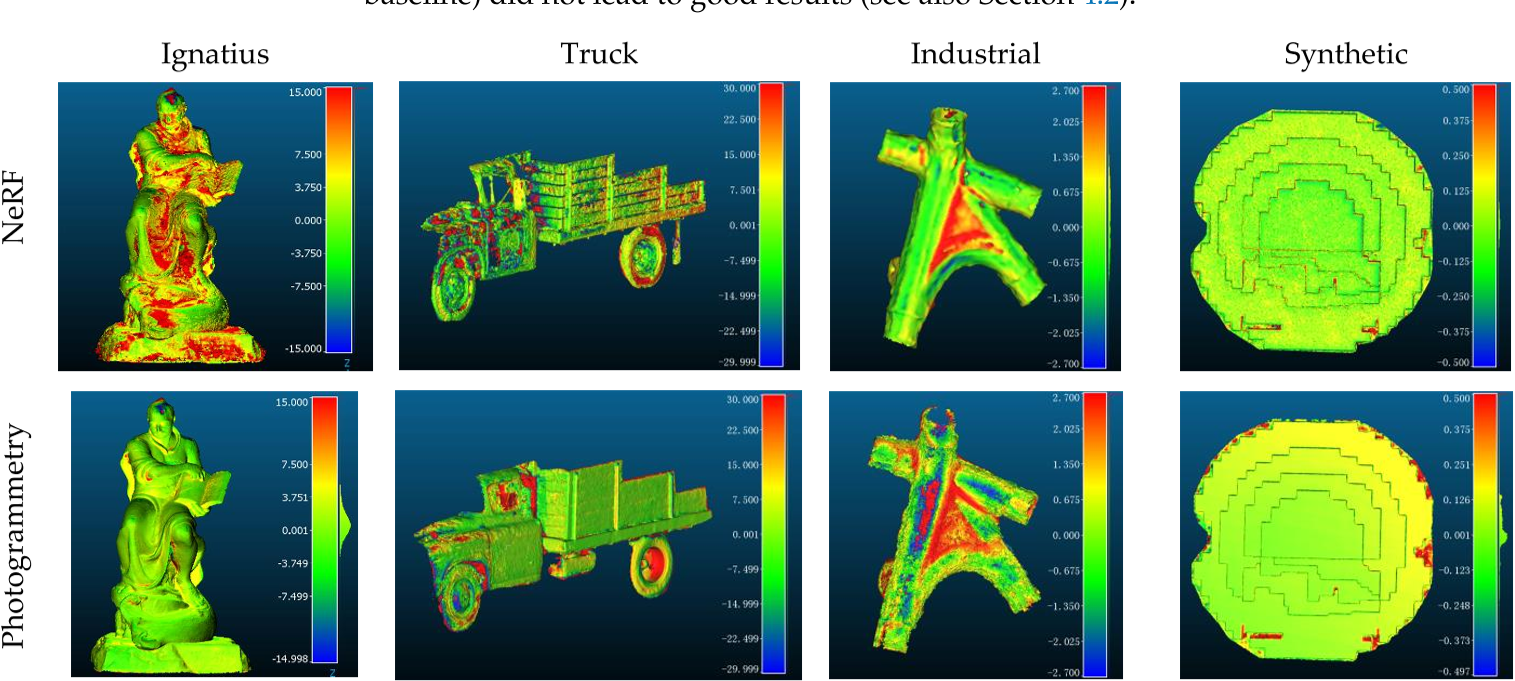
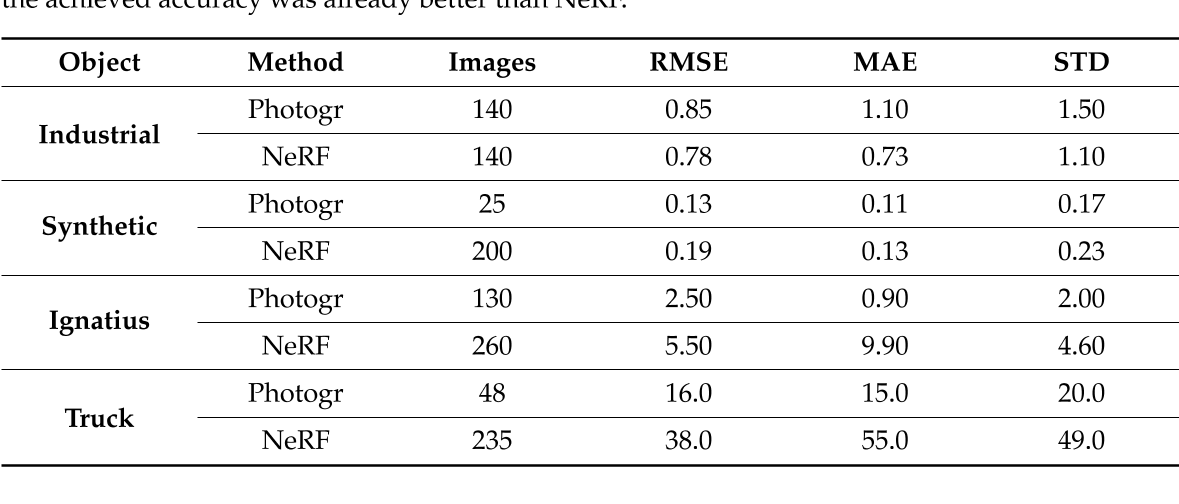
从提供的结果可以看出,对于金属和高反射物体(工业数据集),NeRF的表现优于摄影测量,而对于其他场景,摄影测量产生的结果更准确
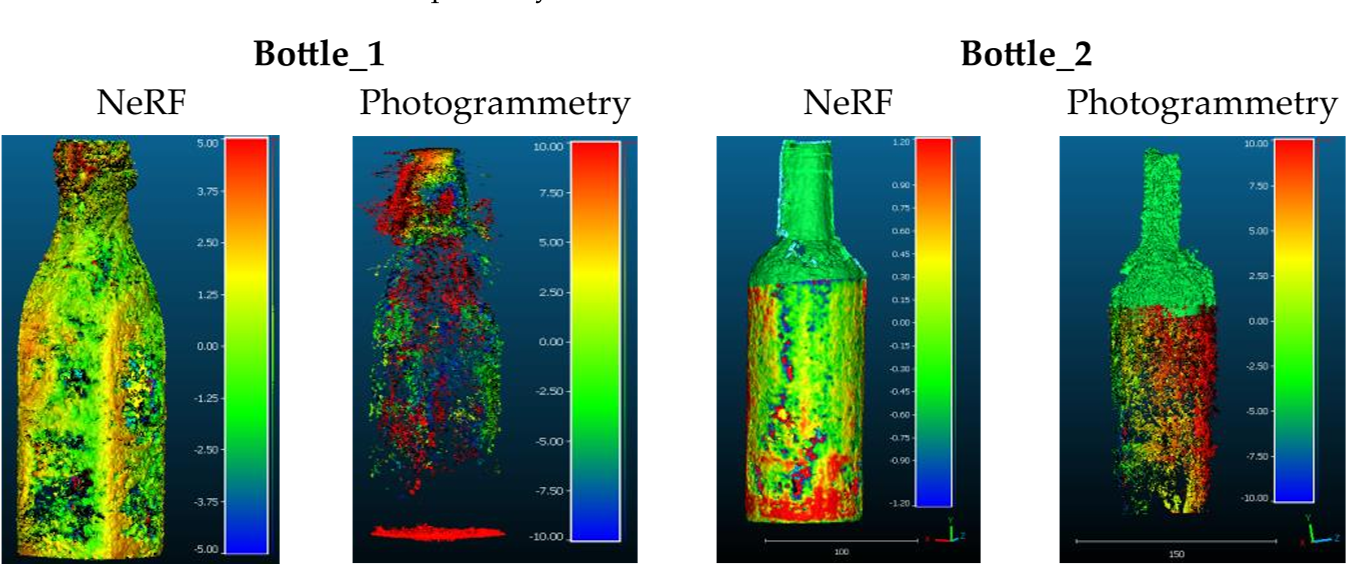
另外两种半透明和透明物体被考虑:Bottle_1和Bottle_2(图3)。玻璃物体不会漫反射入射光,也没有自己的纹理用于摄影测量3D重建任务。它们的外观取决于物体的形状、周围的背景和光照条件。
因此,在这种情况下,摄影测量很容易失败或产生非常嘈杂的结果。另一方面,正如Mildenhall等人所宣称的那样[16],由于NeRF模型的视图依赖性质,NeRF可以学习正确地生成与透明度相关的几何形状。
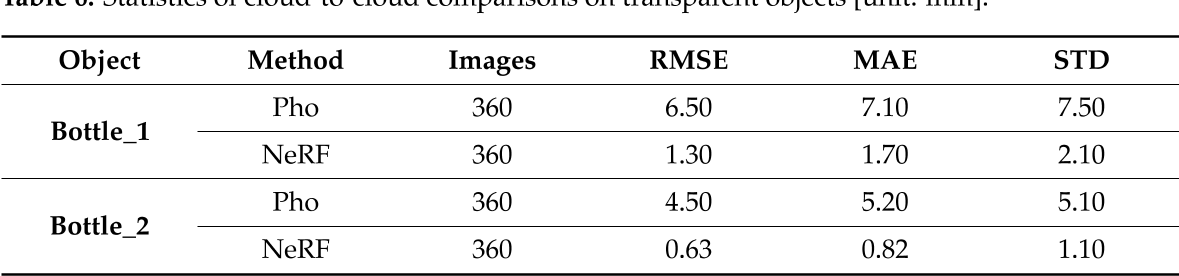
对于这两个目标,基于摄影测量和NeRF的3D结果被共同注册到GT数据中,并计算度量(图11和表6)。
研究结果证明,对于透明目标,NeRF的表现优于摄影测量。例如,Bottle_1上摄影测量的估计RMSE, STD和MAE分别为6.5 mm, 7.1 mm和7.5 mm。相比之下,NeRF值分别显著降低到1.3 mm、1.7 mm和2.1 mm。
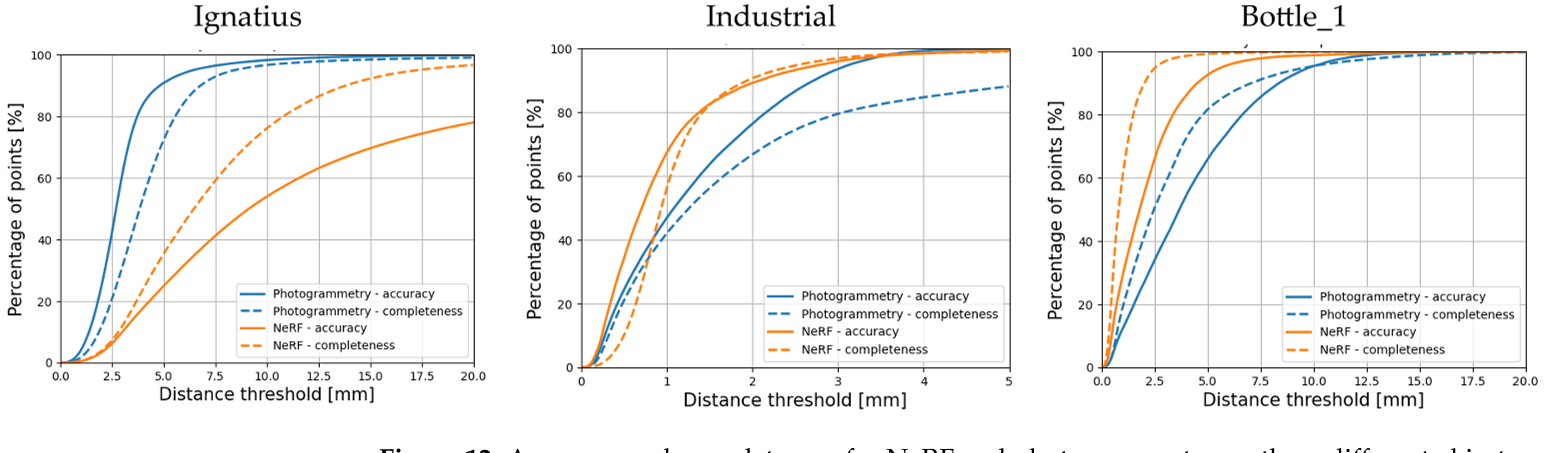
Accuracy and Completeness
三个不同的数据集用于比较摄影测量和NeRF的准确性和完整性: Ignatius, Industrial和Bottle_1。
对于NeRF (Instant-NGP)和摄影测量,这两个度量都是根据可用的地面真值数据计算的。结果如图12所示,揭示了以下见解:
(i)对于Ignatius数据集,与NeRF相比,摄影测量显示出更高的准确性和完整性;
(ii)对于工业和Bottle_1数据集,NeRF显示了稍好的结果。
这些发现在数量上证实了第4.6节,并且基于nerf的方法在处理具有非协作表面的物体时表现出色,特别是那些透明或有光泽的物体。相比之下,摄影测量学在捕捉这些表面的复杂细节方面面临挑战,使NeRF成为更合适或互补的选择