| Title | A Review of Deep Learning-Powered Mesh Reconstruction Methods |
|---|---|
| Author | Zhiqin Chen |
| Conf/Jour | |
| Year | 2023 |
| Project | |
| Paper | [A Review of Deep Learning-Powered Mesh Recon arxiv.org/pdf/2303.02879#page=40.17 |
介绍了几种3D模型表示方法+回顾了将DL应用到Mesh重建中的方法
Conclusion and Future work
在这项调查中,我们回顾了不同的形状表示,以及各种深度学习3D重建方法,这些方法可以从体素、点云、单图像和多视图图像中重建表面。
虽然这项调查旨在涵盖可以产生显式网格的方法,但被引用的作品中有一半使用隐式表示,除了与形状解析相关的任务外,最先进的总是那些采用隐式表示的作品。因此,研究学习显式表征的基本问题,以及/或弥合隐式表征和显式表征之间的差距是值得的。
大型图像和语言模型表明,只要有更多的训练数据,就可以实现泛化。但在三维领域,训练数据确实非常有限。例如,大多数3d监督方法使用ShapeNet [17], ShapeNet中总共有6778把椅子。怎么能指望一个仅仅在6778把椅子上训练过的方法推广到由数百万种不同结构、风格和纹理组成的现实生活中的椅子呢? 因此,ahead 有多个新的方向,例如,有效的数据增强,使用真实的2D图像来促进3D学习,合成数据集的预训练,合成到真实的域适应,半自动3D数据收集和标记,当然,需要有人来做创建大规模3D数据集的脏活。
AIR
随着最近硬件和渲染技术的进步,3D模型在我们的生活中无处不在。然而,创建3D形状是艰巨的,需要大量的专业知识。同时,深度学习可以从各种来源实现高质量的3D形状重建,使其成为一种以最小effort获取3D形状的可行方法。重要的是,为了在常见的3D应用中使用,重建的形状需要表示为多边形网格,由于网格镶嵌的不规则性,这对神经网络来说是一个挑战。在本调查中,我们提供了由机器学习驱动的网格重建方法的全面审查。我们首先描述了深度学习环境中3D形状的各种表示。然后回顾了体素、点云、单图像和多视图图像的三维网格重建方法的发展。最后,我们确定了该领域的几个挑战,并提出了潜在的未来方向。
KW:3D shape, mesh, and representation; reconstruction from voxels, point clouds, and images; machine learning
Introduction
随着近年来硬件和渲染技术的进步,3D模型在我们的生活中无处不在:电影、视频游戏、AR/VR、自动驾驶,甚至在网站上[1]。与人们可以用相机或智能手机轻松创建的图像和视频相比,建模3D内容需要专业知识。就像编程一样,只有经过繁琐的培训和实践的人才能够在3D建模软件中创建3D模型和场景。

尽管如此,以更简单的方式创建3D模型是可能的。理想情况下,用户可以提供一些易于获取的数据作为输入,并依靠复杂的三维重建算法获得三维模型
因此,拥有强大的工具来执行从这些输入的三维形状重建是非常重要的。它们在人们的日常生活中非常有用,并使娱乐业受益。在相关领域已经投入了大量的研究和努力。许多经典的重建方法,如用于等面重建的Marching Cubes[96],用于点云重建的screening Poisson[74],以及用于多视图重建的COLMAP[129,130],都是非常鲁棒的算法,直到今天仍在使用。然而,正是深度学习革命为人们带来了工具,使他们能够完成许多以前无法完成的任务。基于深度学习的方法不仅放松了输入约束,允许我们从稀疏或有噪声的数据中重建形状,而且将重建质量提高到一个全新的水平。
尽管如此,许多挑战仍然存在,大多数方法还远远不能应用于实际产品。一个很大的挑战是,几乎所有的软件和硬件都只能支持三角形网格,这应该是这些重建方法的理想输出。然而,三角形镶嵌的非均匀性和不规则性自然不支持传统的卷积操作,因此新的网络架构和新的表示已经被设计出来,以与神经网络兼容的方式表示3D形状。
这项调查提供了一个全面的审查这些网格重建方法由机器学习。在第2节中,我们描述了深度学习环境中3D形状的各种表示。然后在第3、4、5和6节中,我们分别回顾了从体素、点云、单图像和多视图图像重建表面的3D重建方法。最后,在第7节中,我们确定了该领域的几个挑战,并提出了潜在的未来方向。
Representations
任何算法的基础都是数据表示。对于图像,像素是学术界和工业界都使用的表示。不幸的是,3D模型没有这样的统一表示。事实上,研究人员已经为3D生成任务提出了广泛的表示。
在这个调查中,我们关注的是本质上是三角形网格的表示。我们还考虑了可以很容易地转换为三角形网格的表示,例如CSG(Constructive Solid Geometry)树和参数曲面。我们还将讨论隐式表示,如体素网格和神经隐式,因为它们是最流行的表示,尽管它们在转换为三角形网格时可能面临问题,例如创建过多的顶点和三角形。
CSG模型 :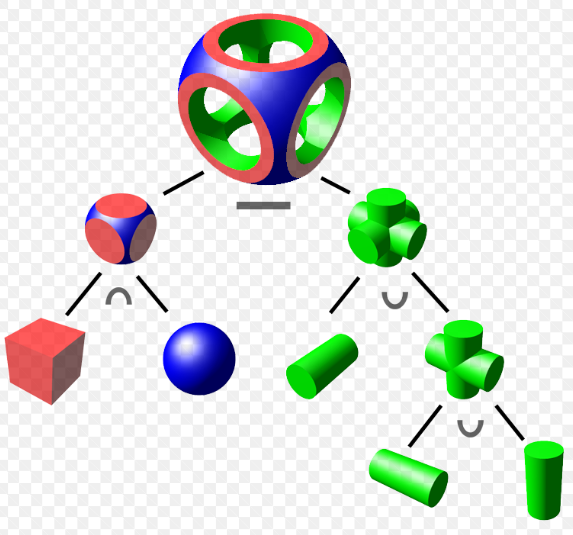
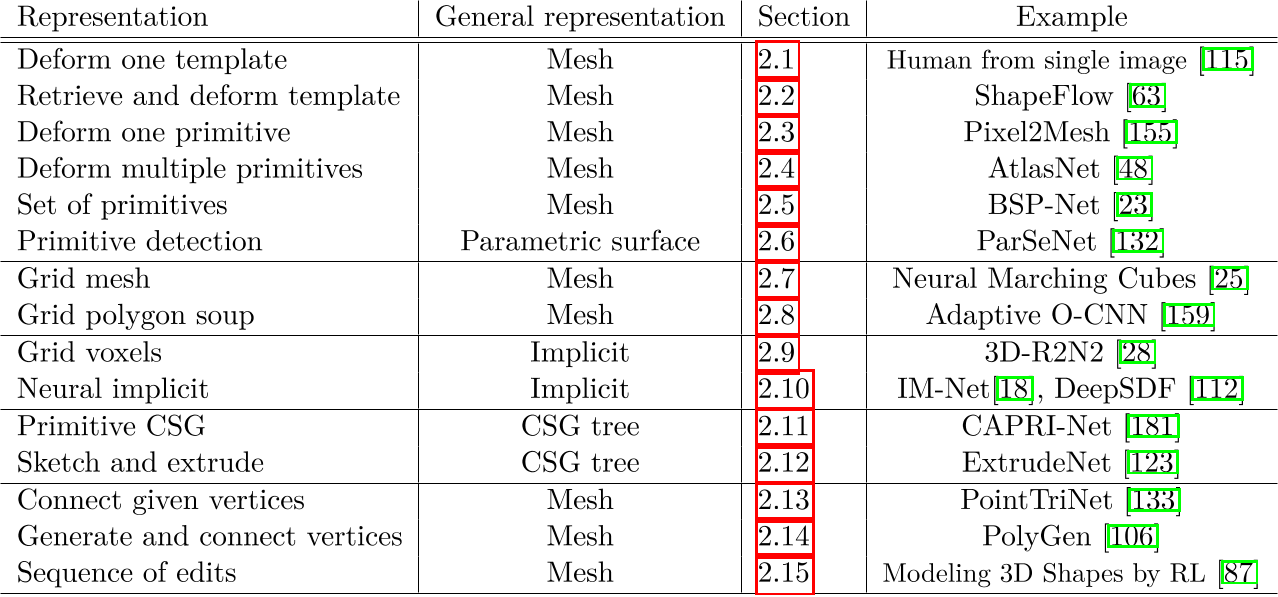
表2.1列出了深度学习网格重建方法中使用的表示的总结。请注意,虽然没有考虑输出点云的方法,但其中一些方法使用点来表示隐式字段,因此可以很容易地提取3D形状。例如,“Shape As Points”[117]提出了一个点到网格层,使用泊松曲面重构的可微公式[73,74],将形状表示为一组具有法线的点的隐式场。另一方面,“Analytic Marching”[81]等作品可以从神经隐式表示中提取精确的多边形网格,未来神经隐式和显式网格之间的差距可能会缩小。
Deform one template
变形单一模板网格生成不同姿态的形状
Retrieve and deform template
首先为目标对象检索最合适的模板,然后对模板进行变形,以获得最佳性能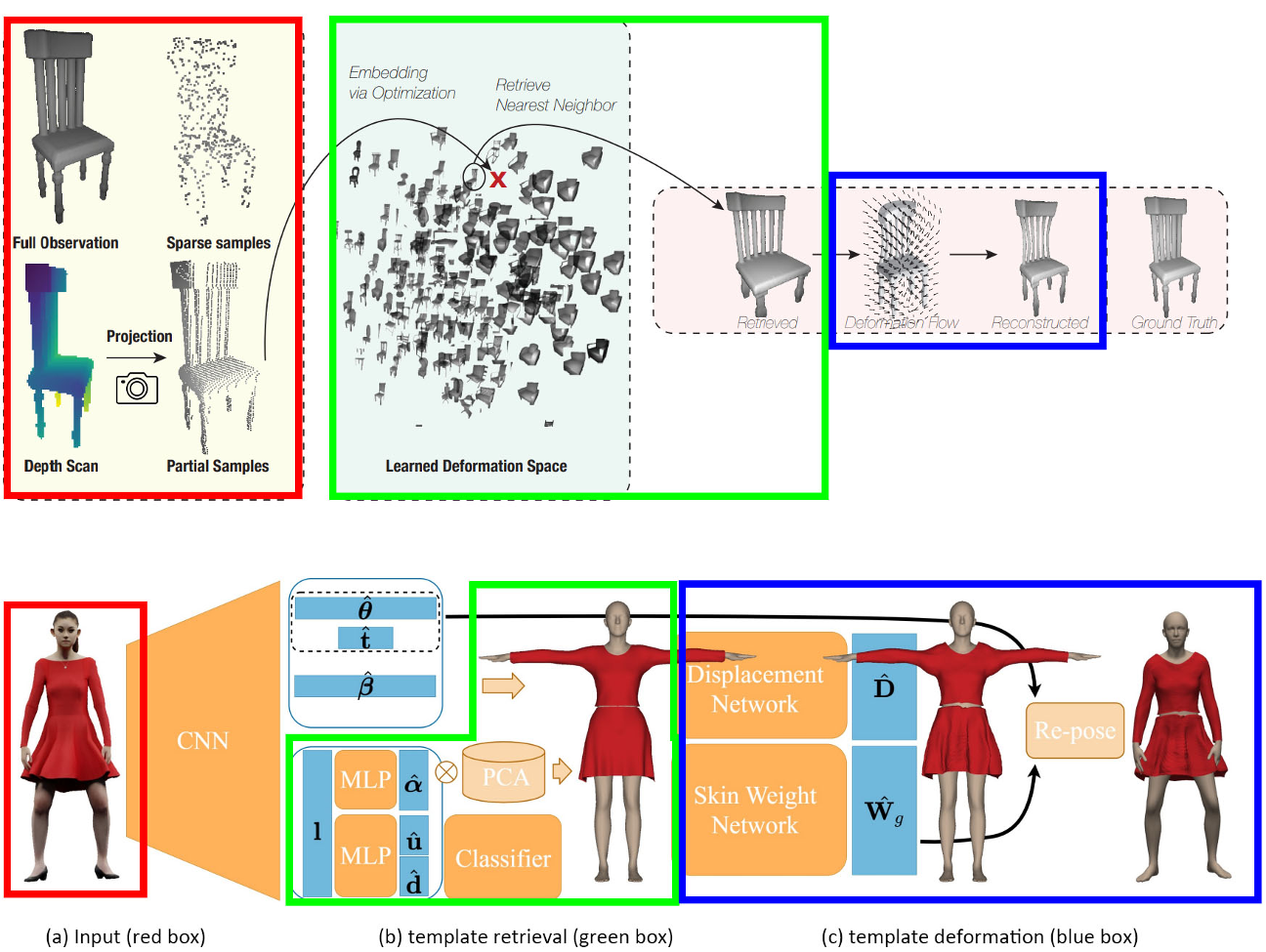
Deform one primitive
对于一般的形状重建任务,特别是在只有二维图像监督的情况下重建三维形状时,可以使用原始initial形状作为初始形状,并对其进行变形以接近目标形状
最常用的primitive是一个简单的球体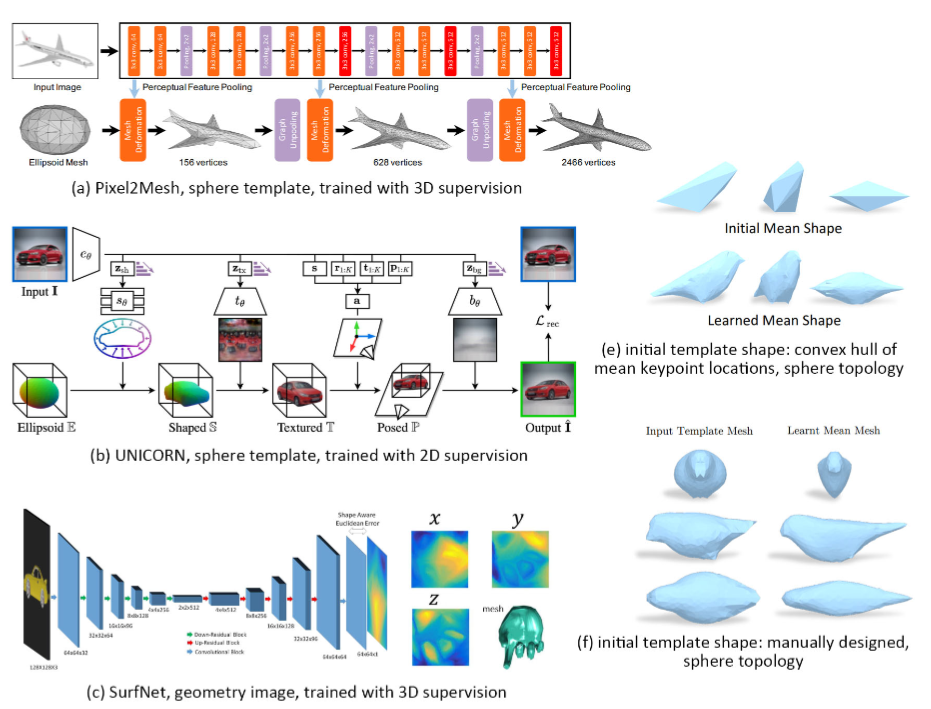

Deform multiple primitives
单一原始形状的变形限制了重构形状的拓扑结构和表示能力,因此自然的解决方案是拟合多个原始形状。然而,这种表现方式主要用于直接的3D监控;从二维图像监督重建三维形状可能过于复杂和不可控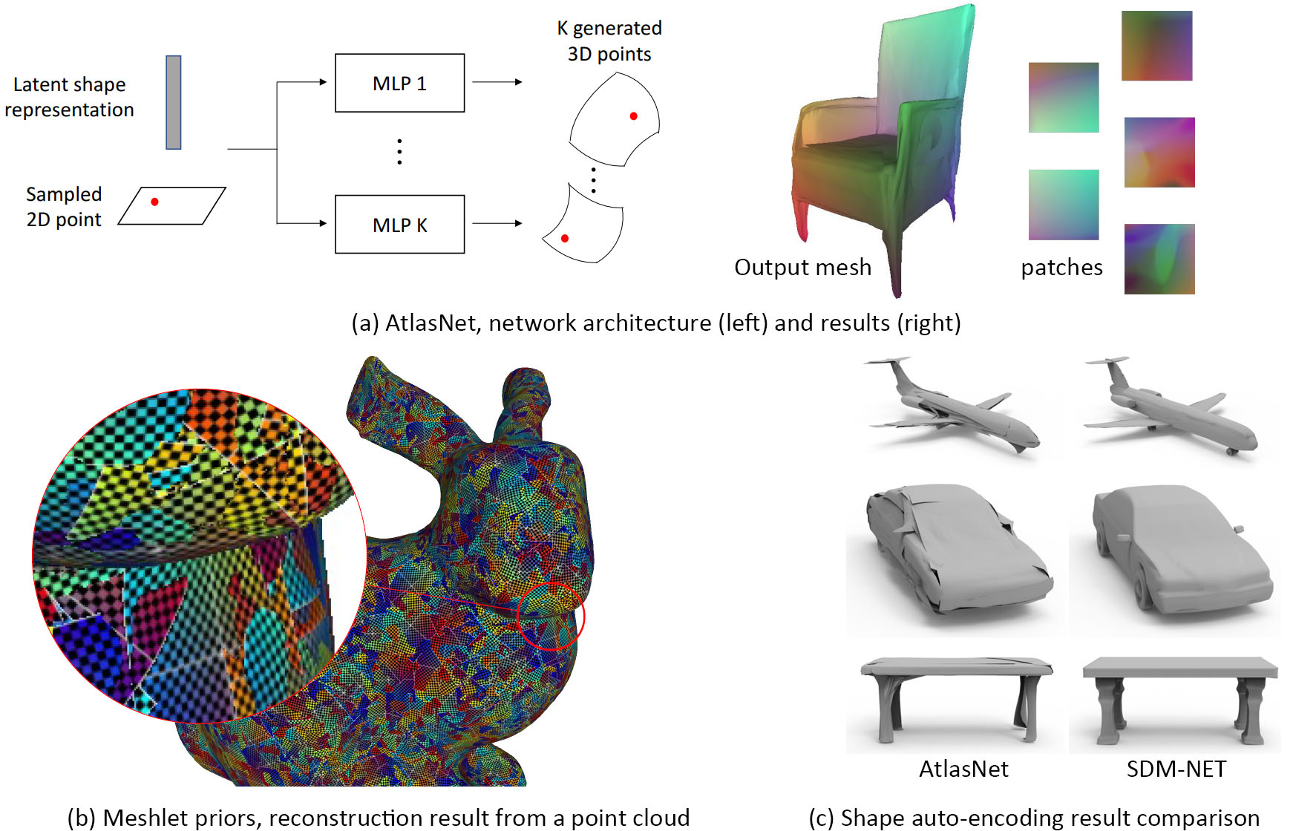
Set of primitives
关键的区别在于,在“变形多个基元”中,基元网格通过神经网络进行变形。在“基元集合”中,每个基元只是由一组参数定义的基元,因此不存在变形网络
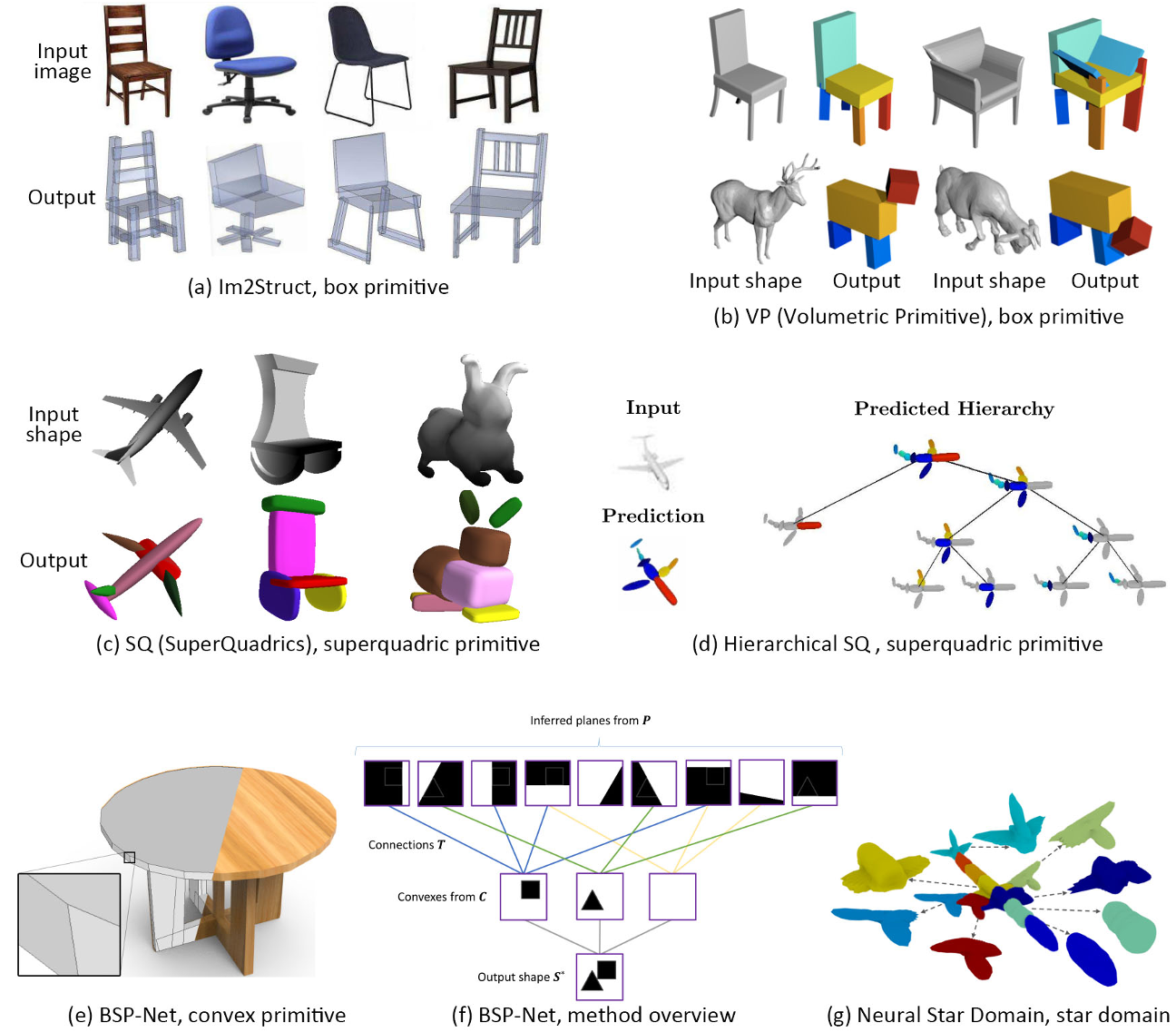
Primitive detection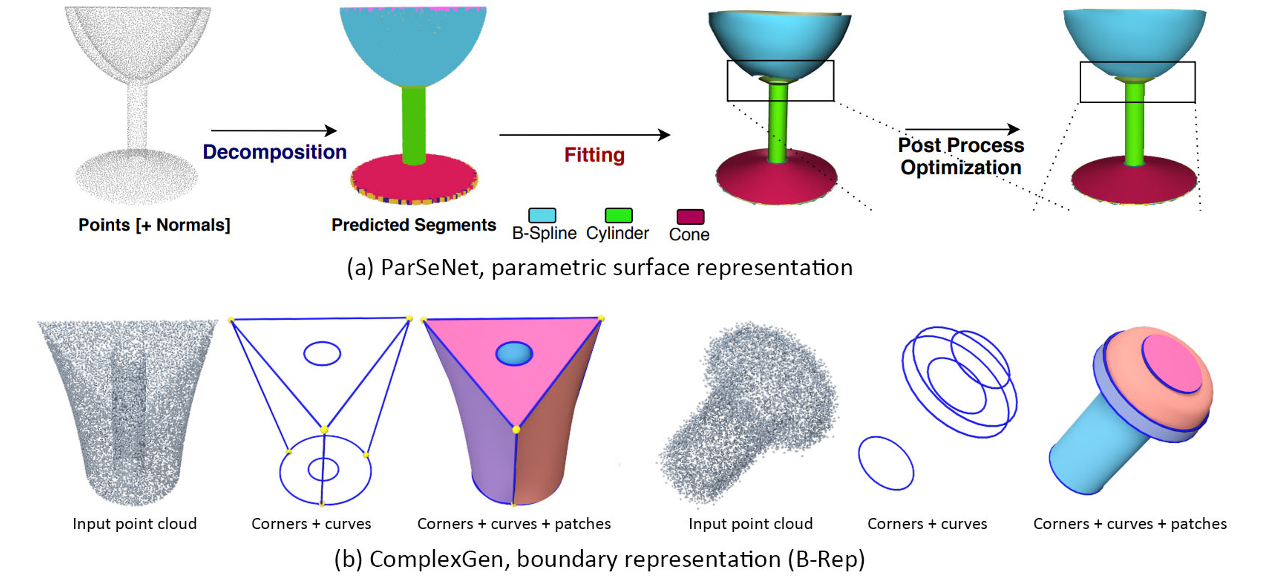
Grid mesh 点云MC到表面mesh
受行军立方体(Marching Cubes, MC)[96]、双重轮廓(Dual contoring, DC)[66]和行军四面体(Marching Tetrahedra, MT)[35]等在规则网格结构上运行的经典等曲面算法的启发,已经提出了几种方法来生成规则的参数网格,以便可以一个单元一个单元地提取表面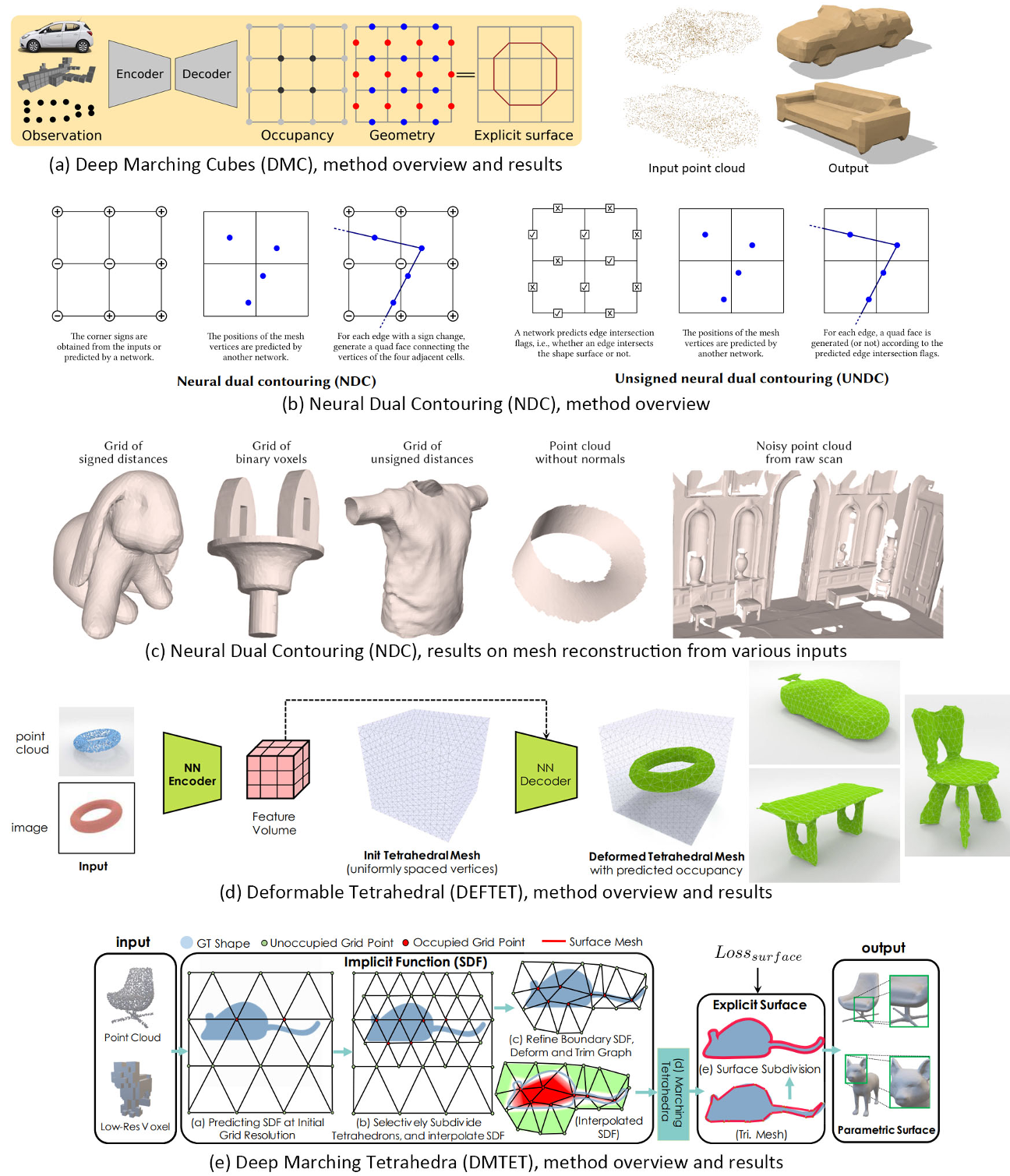
Grid polygon soup
八叉树状网络结构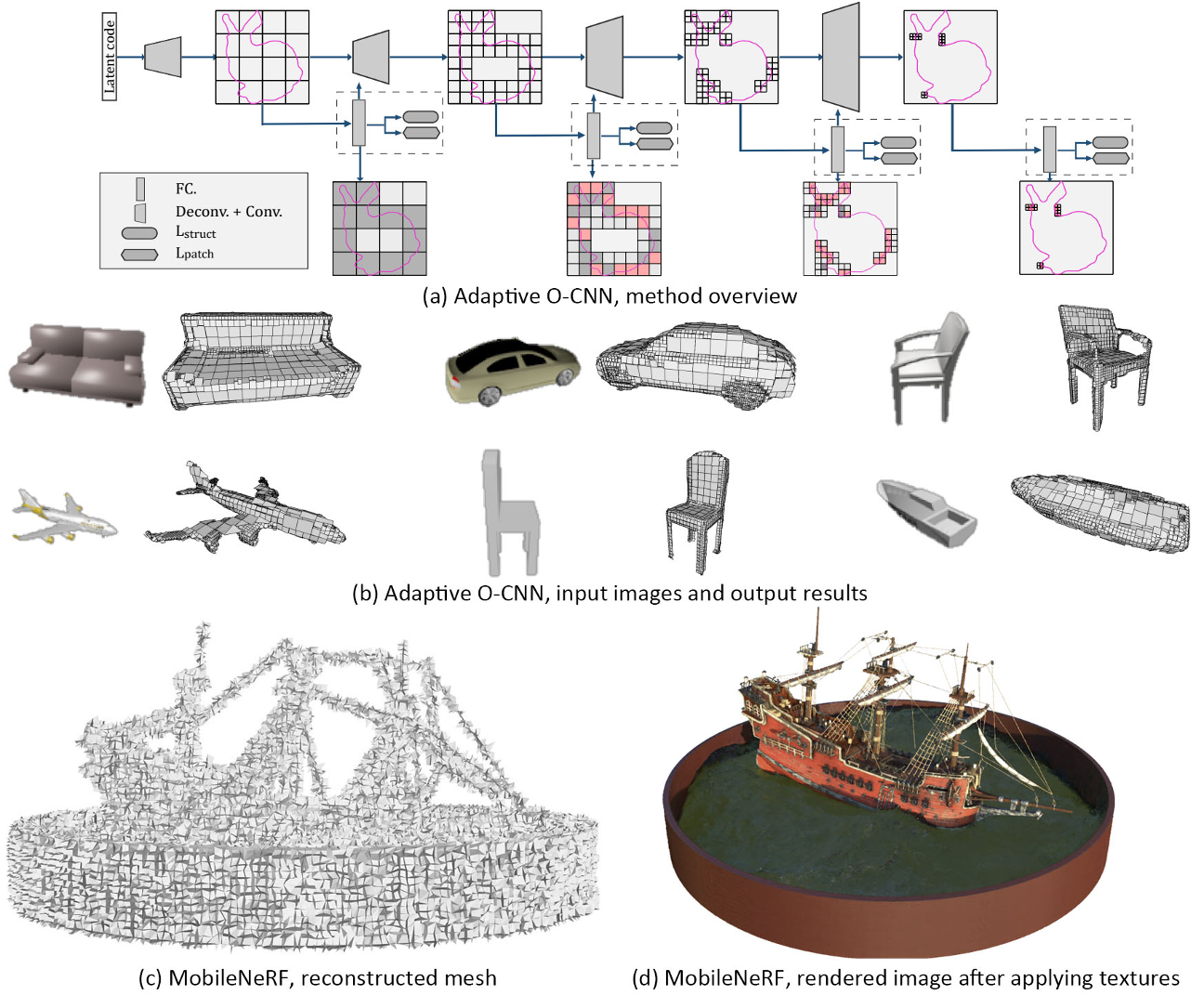
Grid voxels
voxels :Occupancy or signed distance grids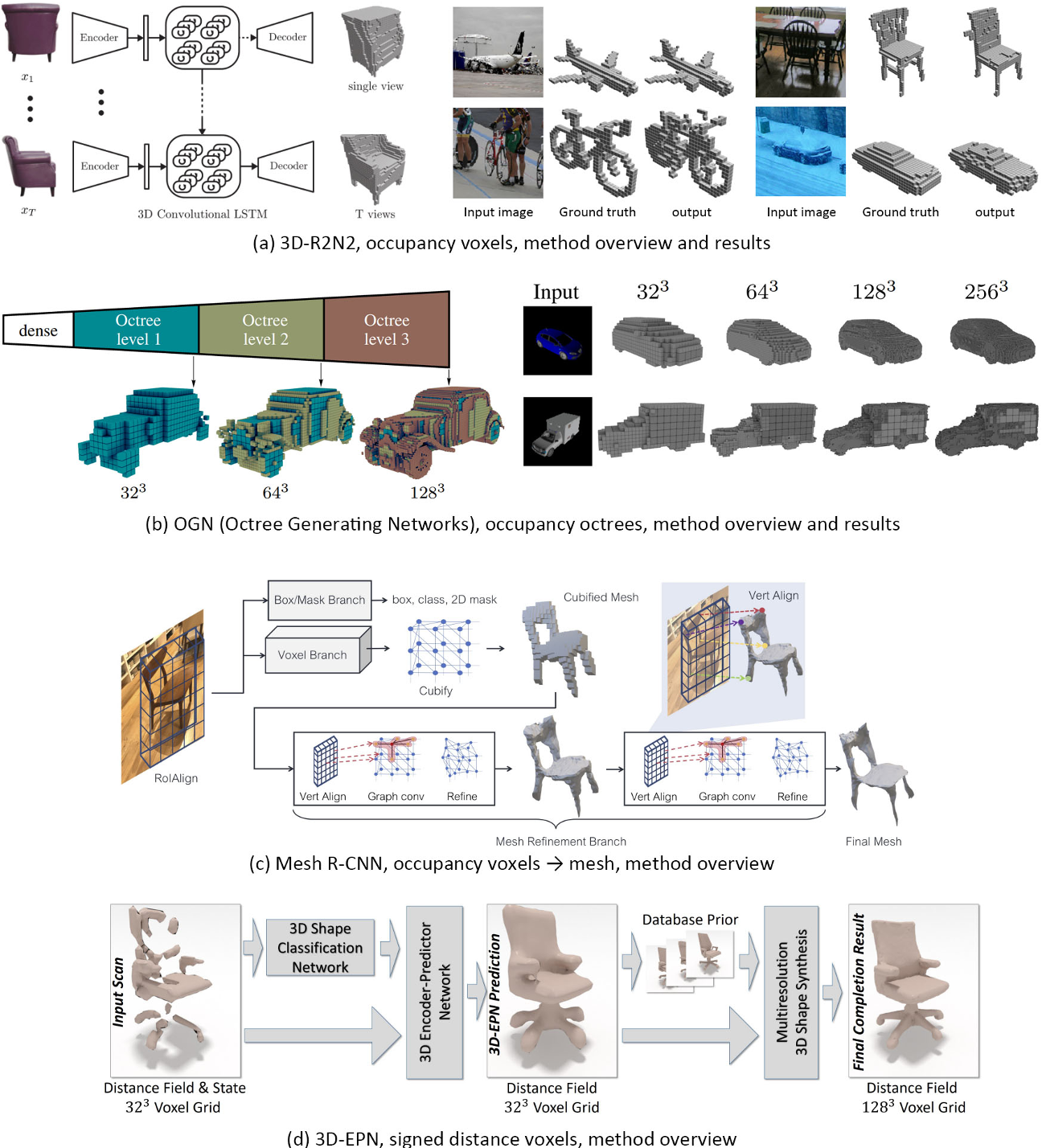
Neural implicit
Primitive CSG
构造立体几何CSG(Constructive Solid Geometry),它是CAD(计算机辅助设计)模型的常见表示,其中原始形状(如多面体、椭球体和圆柱体)通过布尔运算符(如并、交和差)合并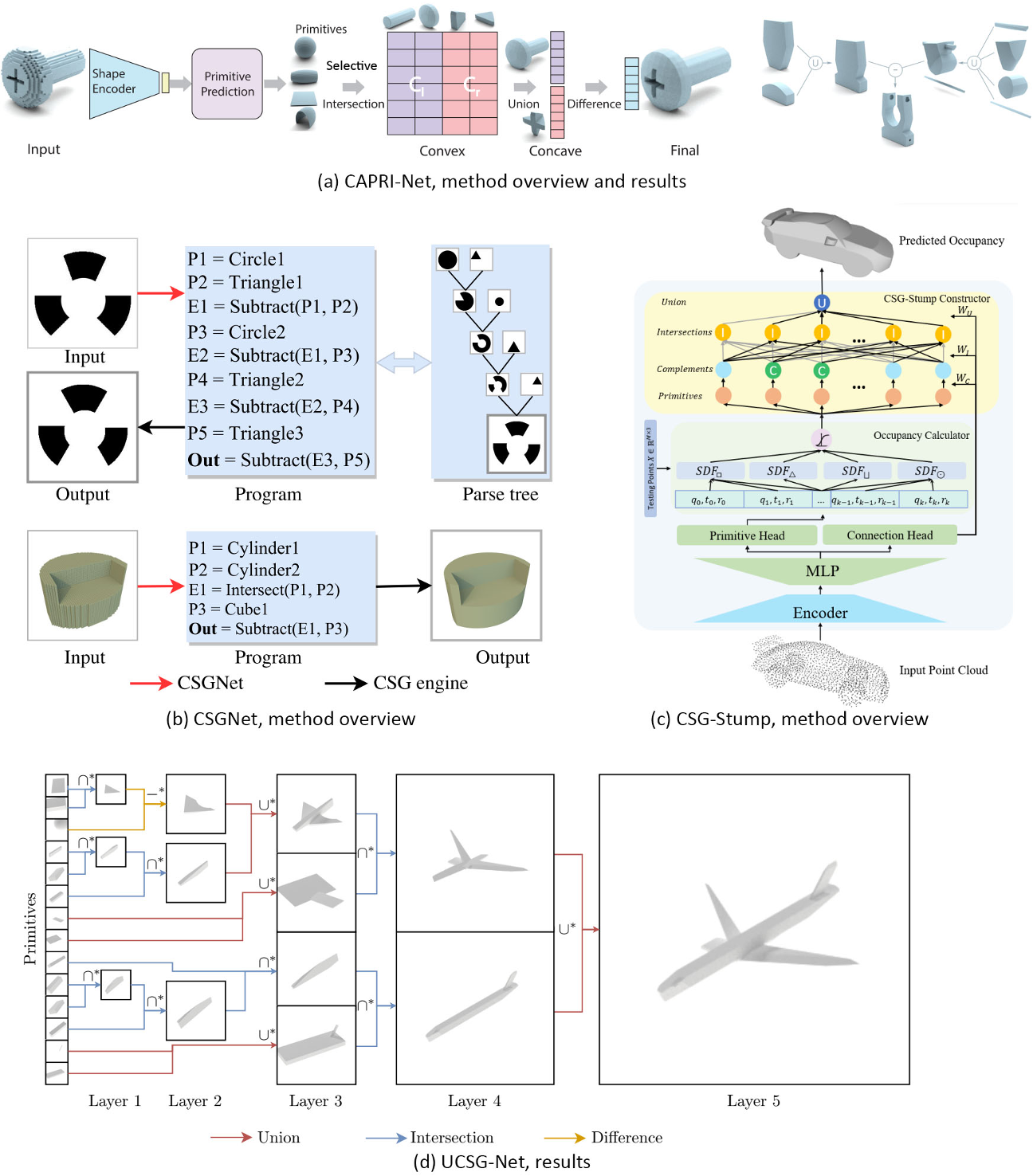
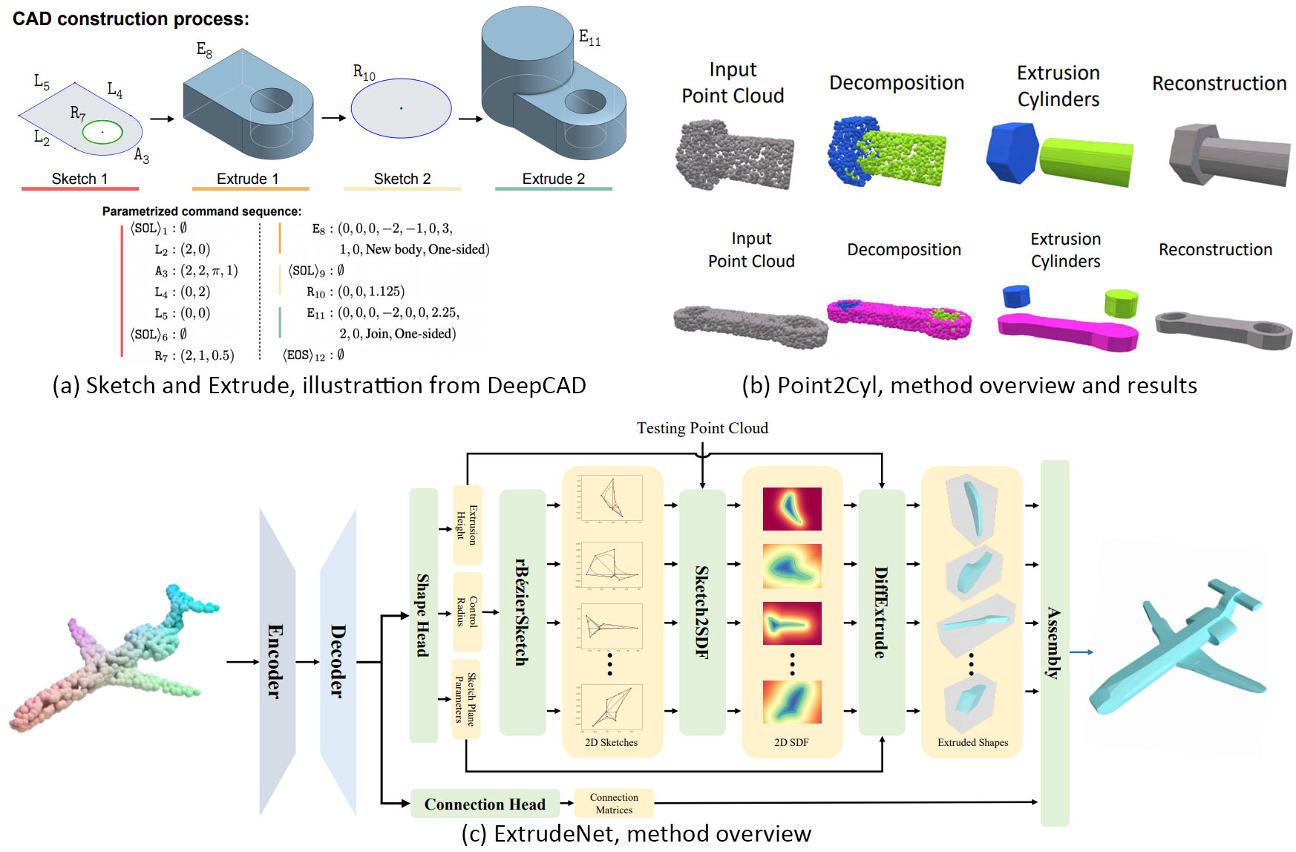
Sketch and extrude
“素描和挤压”也是CSG的一种表现形式。然而,与“原始CSG”不同的是,在“原始CSG”中,CSG操作只使用原始3D形状,这种表示方式更类似于创建CAD模型的工作流程,通过重复绘制2D轮廓,然后将该轮廓挤压到3D体中
Connect given vertices
从点云重建网格,因为它只连接点云中的给定顶点。这些方法可以通过是否推断出形状的内外区域来进行分类,从而生成封闭的网格
Generate and connect vertices
该表示首先通过神经网络生成一组网格顶点,然后有选择地将这些顶点连接起来,形成另一个神经网络的网格面。该方法可以直接生成三维网格作为索引面集,但由于其极高的复杂性,很少被使用。
Sequence of edits
Reconstruction from Voxels
在本节中,我们回顾了从占位网格或符号距离重建形状的作品。基于动机,我们将作品集合分为两类:形状超分辨率和形状解析,其中
- 形状超分辨率从输入体素中重建更详细和视觉上令人愉悦的形状
- 形状解析将输入体素分解为原语和CSG序列,用于逆向工程CAD形状。
请注意,从部分体素重建完整形状,即形状补全,也是一个活跃的研究领域,由于本调查的范围,我们将不讨论。
Shape super-resolution

Shape parsing
Reconstruction from Point Clouds
在本节中,我们回顾了从点云重建物体和场景的作品,有或没有点法线。我们将这些方法分为两类:一类基于显式表示,另一类基于隐式表示。
- 具有显式表示的方法可以直接输出网格,但通常不能保证表面质量,例如,它们可能不是水密的,可能包含无流形和自相交。
- 采用隐式表示的方法可以保证生成无自交的水密流形网格,但它们需要一种等曲面算法来从隐式域中提取网格。
Explicit representation
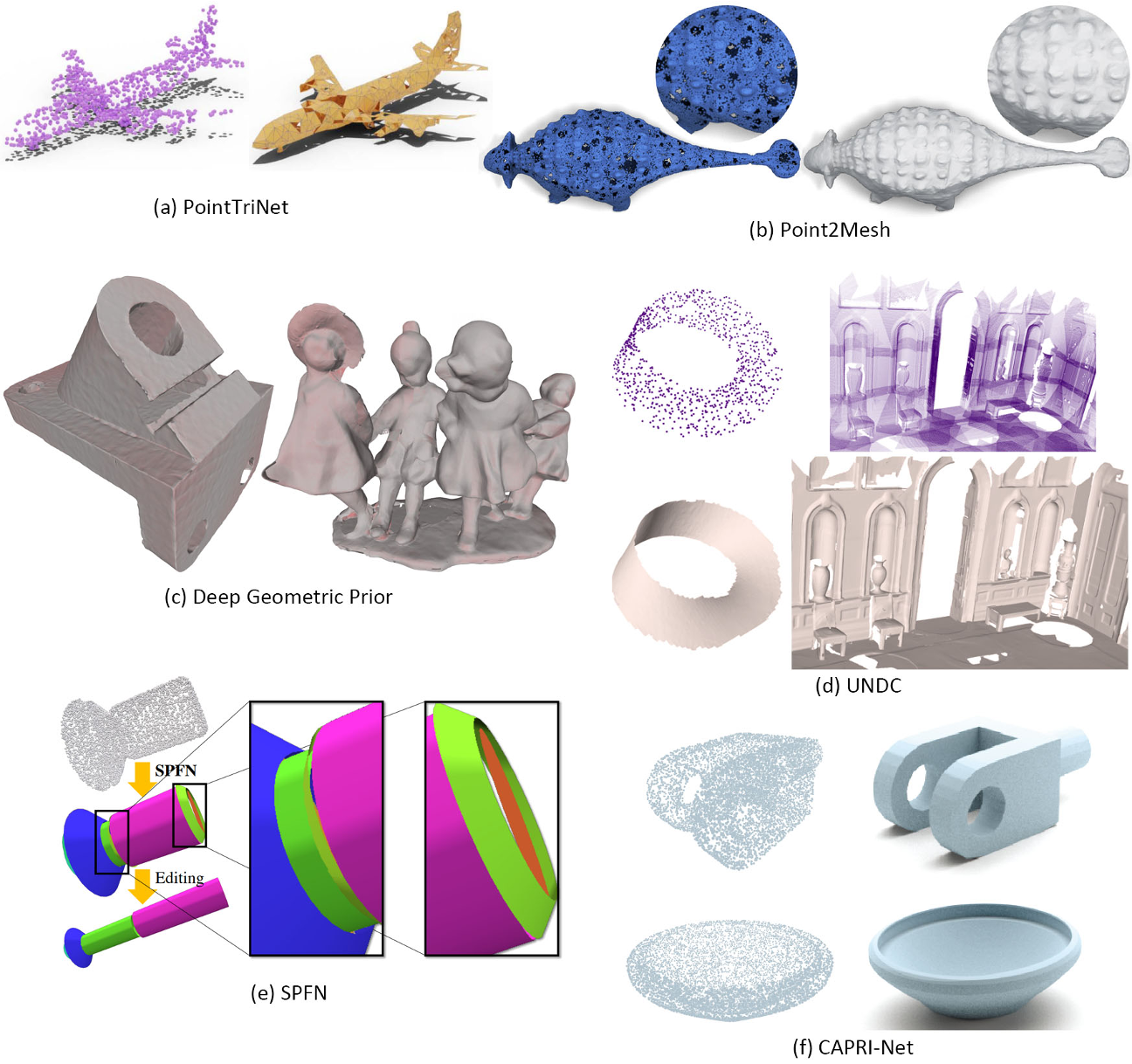
Implicit representation
- Overfit a single shape
- Divide space into local cube patches
- 3D CNN then local neural implicit
- Point cloud encoder then local neural implicit
- Implicit field defined by points
- Octrees
Reconstruction from Single Images
从单个图像重构形状的方法可以根据它们在训练过程中接受的监督分为两类。
- 一类是用地面真实三维形状作为监督来训练的。这类方法通常在ShapeNet上进行训练[17]。
- 另一类是只训练单视图图像作为监督。单视图图像意味着每个对象只有一个图像用于训练,而多视图图像则是每个对象有来自不同视点的多个图像。这类方法通常在具有球形或圆盘拓扑形状的鸟、车、马和脸的图像数据集上进行训练。
With 3D supervision
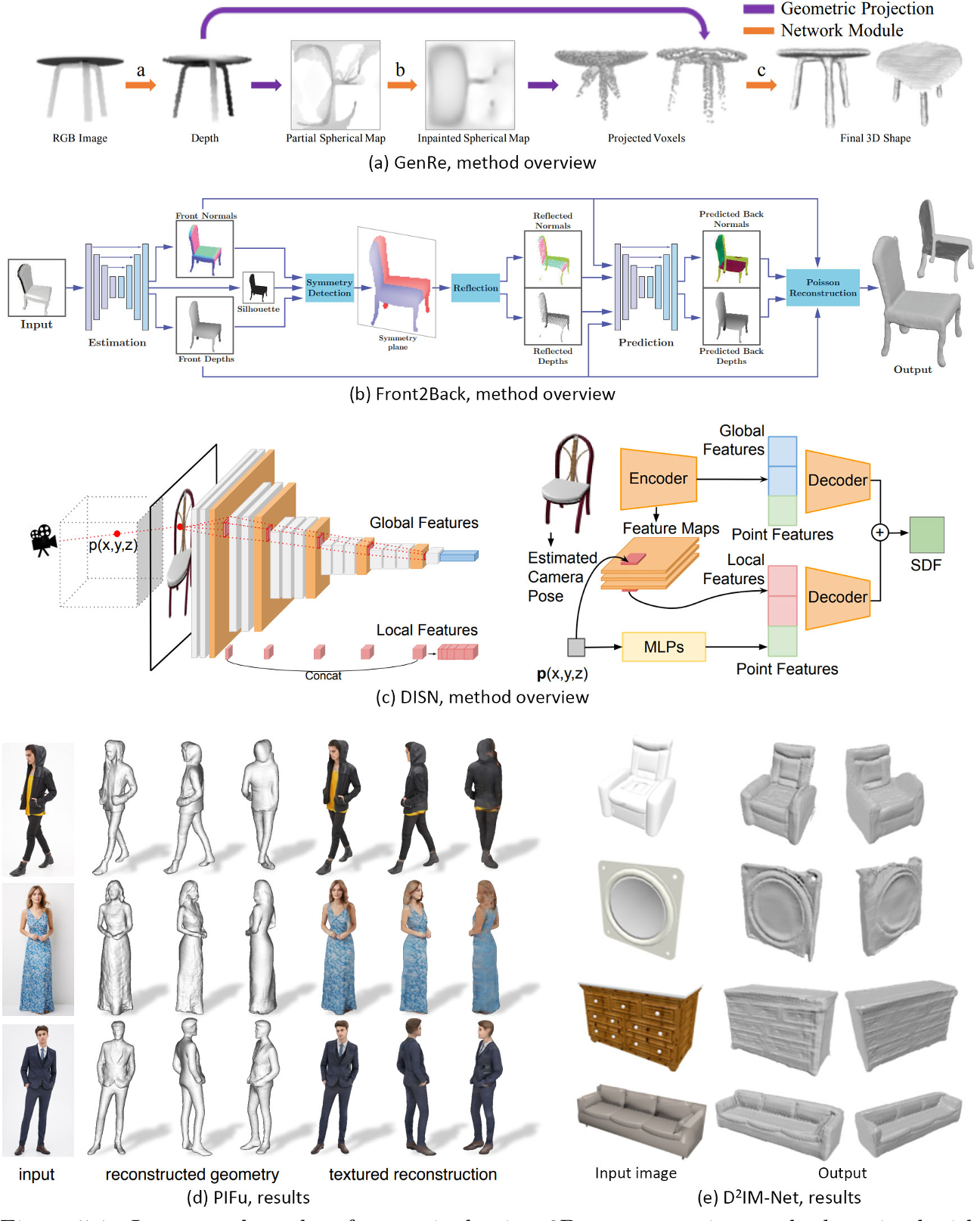
With 2D supervision
Reconstruction from Multi-View Images
大多数方法是使用基于网格或神经隐式的可微渲染算法,或基于NeRF的射线推进体渲染公式的方法,对多个输入图像过度拟合单个形状或场景[101]。
Differentiable rendering on explicit representation
Surface rendering on implicit representation
本节中的方法都有一个可微分的渲染公式,假设每个输入图像都给出了对象分割掩码,并且每个光线最多与表面相交一次(每条光线只有一个交点用于梯度传播)。
Volume rendering on implicit representation
本节的方法采用nerf风格的射线推进体绘制算法。对于每一个像素,相机都会发射一束穿过它的光线。沿着射线对许多点进行采样。每个采样点携带密度(“不透明度”)和亮度(视相关的RGB颜色),由MLP预测。最后的像素颜色是所有采样点相对于其密度的累积亮度,类似于alpha合成。这些方法通常不需要目标分割蒙版,它们以某种方式用定义良好的神经隐式场表示点密度,从而可以通过等曲面提取形状的表面。