| Title | NerfAcc: Efficient Sampling Accelerates NeRFs |
|---|---|
| Author | Li, Ruilong and Gao, Hang and Tancik, Matthew and Kanazawa, Angjoo |
| Conf/Jour | arXiv preprint arXiv:2305.04966 |
| Year | 2023 |
| Project | NerfAcc Documentation — nerfacc 0.5.3 documentation |
| Paper | NerfAcc: Efficient Sampling Accelerates NeRFs (readpaper.com) |
一种可以加速NeRF的高效采样策略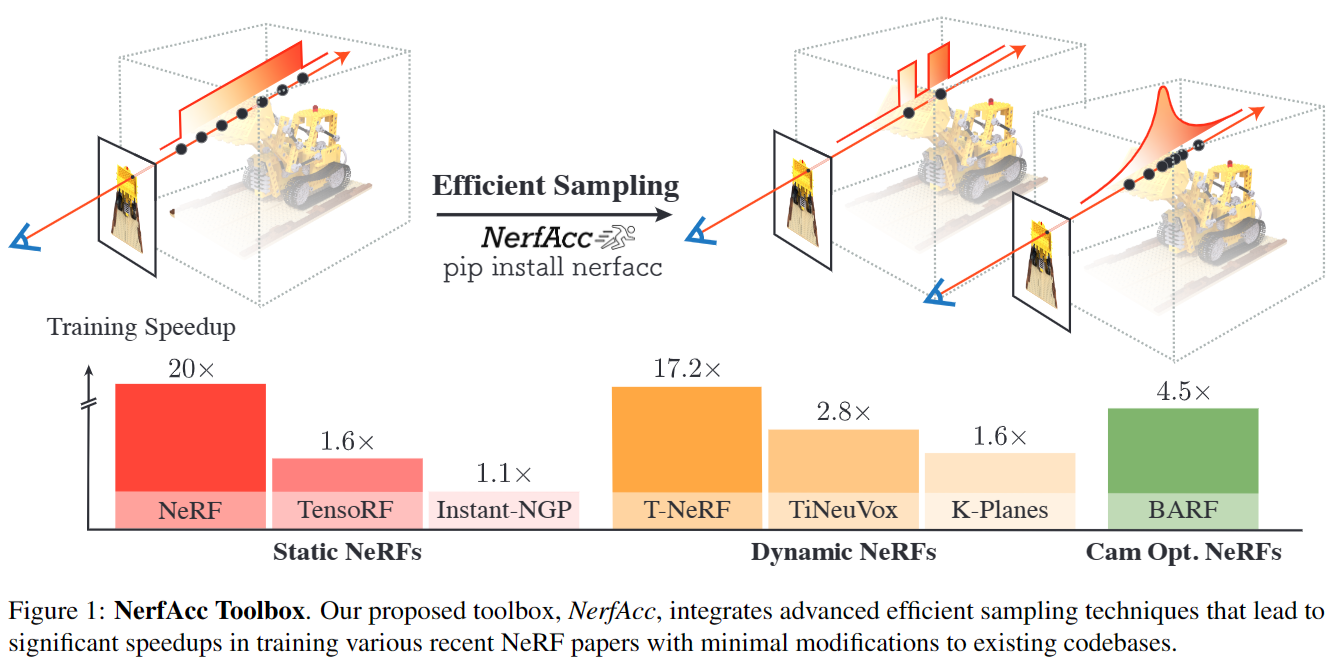
NerfAcc = Instant-NGP的Occupancy Grid + Mip-NeRF 360的Proposal Network
pip install nerfacc
用法
1 | import torch |
论文
AIR
Abstract and Introduction and Related Works
本文集中讨论各个采样方法对NeRF的加速效果,在统一透射率估计概念下,证明改进的采样通常适用于NeRF
为了促进未来的实验,提出了一个即插即用的Python工具箱——NerfAcc,提供了灵活的Api,将目前的采样方法合并进了NeRF的相关工作
可以使相关工作都有一定的加速
大多NeRF方法都有相似的体渲染pipeline:沿着光线创建采样点,然后通过$\alpha$累加
有大量工作集中在发展高效的辐射场表示,很少通过高效采样来对神经体渲染的计算花费进行关注,即使有在论文中也不是作为主要的方法被提出。
InstantNGP和Plenoxels都是用高定制的CUDA实现在光线行进时完成空间跳跃,与各自的辐射场实现紧密耦合。
本文揭示了各种采样方法的复杂性,其经常被忽视但很重要
- NeRF codebase:对NeRF的改进有很多,但每个代码库都是针对特定任务定制的,并且只支持一种采样方法
- 虽然这些方法都是同样的pipeline ,但是做迁移时依然困难:requires non-trivial efforts.
- NeRF frameworks:将多种NeRF方法融合进一个框架,例如NeRF-Factory、Nerfstudio和Kaolin-Wisp。
- NeRF- factory提供了一系列具有原始实现的NeRF变体如NeRF++、Mip-NeRF、Mip-NeRF360等等,并专注于全面的基准测试。
- Nerfstudio整合了现有文献中介绍的关键技术,并为社区提供了易于构建的模块化组件
- Kaolin-Wisp实现了一组基于体素的NeRF论文
- 然而,这些框架旨在鼓励研究人员在框架内进行开发,而对使用自己的代码库的用户没有好处
- 本文NeRFAcc即插即用,可以方便地整合到自己的代码库中
Importance Sampling via Transmittance
目前有许多采样方法
- Plenoxels uses a sparse gridInstant
- NGP uses an occupancy grid
- NeRF employs a coarse-to-fine strategy
- Mip-NeRF 360 proposes proposal networks.
- 他们以完全不同的方式运行
transmittance is all you need for importance sampling
每个方法本质上都有他自己的沿光线创建透射率估计的方式:transmittance estimator
这种观点可以使得不同的方法可以在本文NeRFAcc中统一起来
Formulation
高效采样在图形学中是一个被广泛讨论的问题,其中重点是识别对最终渲染做出最重要贡献的区域。这一目标通常通过重要性抽样来实现,其目的是根据概率密度函数(PDF)——$p(t)$ 在$t_{near},t_{far}$间来分布样本,通过积分计算累积分布函数(CDF)样本采用逆变换采样法生成。$\begin{aligned}F(t)=\int_{t_n}^tp(v)dv,\end{aligned}$
采样点:$t=F^{-1}(u)\quad\text{where}\quad u\sim\mathcal{U}[0,1].$
每个采样点的贡献由权重表示:$w(t)=T(t)\sigma(t)$
颜色:$C(\mathbf{r})=\int_{t_n}^{t_f}T(t)\:\sigma(t)\:c(t)\:dt$
$T(t)=\exp\left(-\int_{t_n}^t\left.\sigma(s)\:ds\right).\right.$
因此:$p(t)=T(t)\sigma(t)$ ,则累计分布函数由$\begin{aligned}F(t)=\int_{t_n}^tp(v)dv\end{aligned}$:
因此,对CDF进行逆采样相当于对透射率T(t)进行逆采样。一个透射率估计量足以确定最优样本。直观地说,这意味着在透射率变化很快的区域(这正是光线照射到物体表面时所发生的情况)周围放置更多的样本,累计透光率可以通过$1-T(t)$直接计算而不需要积分计算。
由于NeRF场景几何不是预定义的,而是动态优化的,在NeRF优化过程中,辐射场在迭代之间发生变化,需要在每一步k动态更新透射率估计量$\mathcal{F}:T(t)^{k-1}\mapsto T(t)^k.$
从不断变化的辐射场中准确估计透射率变得更加困难,目前的方法是使用either exponential moving average (EMA) or stochastic gradient descent (SGD)来作为更新函数$\mathcal{F}$,我们注意到也许有其他的更新函数可以被探索出来。
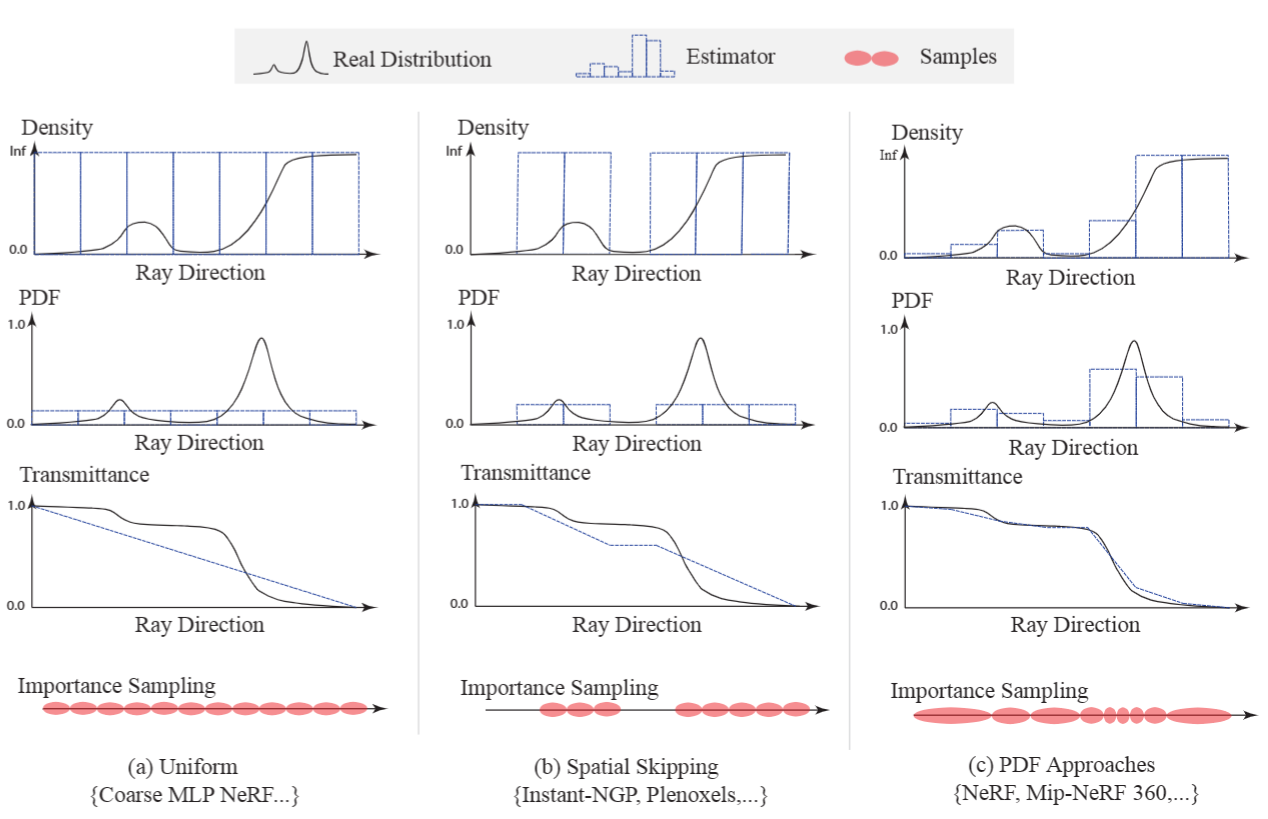
现有的高效采样方法:
- Uniform.每个点对结果的贡献相等,采样过程相当于沿射线均匀采样。Note!!!:每个使用均匀采样的NeRF模型都固有地假设这种线性透射率衰减
- Spatial Skipping.识别空区域并在采样期间跳过它们,用保守阈值对射线的密度进行二值化。为了在优化期间更新透射率估计器:
- InstantNGP直接更新cached density通过exponential moving average (EMA) :
- $\sigma(t_i)^k=\gamma\cdot\sigma(t_i)^{k-1}+(1-\gamma)\cdot\sigma(t_i)^k$
- Plenoxels通过渲染损失的梯度下降来更新密度
- InstantNGP直接更新cached density通过exponential moving average (EMA) :
- PDF方法.用离散样本沿射线直接估计PDF
- NeRF中粗网络训练使用体积渲染损失来输出一组密度,然后进行逆变换采样
- Mip-NeRF中在粗网络使用一个小得多的MLP,即Proposal Network,以加快PDF的构建
- 两者都是使用梯度下降法来更新透射率估计器

$T(t_{i}) = 1-F(t_{i})=1-\int_{t_n}^{t_i}p(v)dv$
Design Spaces
Choice of Representations. 显式or隐式,体素or点云orSDFor占据场
透光率估计器可以使用显式体素,MLP或混合表示。根据估计量是否显式,它可以使用基于规则的EMA或带有一些监督的梯度下降进行更新。
通常基于体素的估计器比隐式估计器更快,但是有更多的aliasing issues混叠问题。
透过率估计器的表示可以显著受益于辐射场表示的进步。例如,Nerfacto模型对亮度场和采样模块使用最新的混合表示HashEncoding,在野外设置中实现了最佳的质量-速度权衡。
Handling Unbounded Scenes.
对于无界区域也就是$t_{near},t_{far}$之外的区域,沿着射线密集取样是不可能的。与图形渲染中使用的mipmap类似,一般的解决方案是随着光线走得更远而进行更粗的采样,因为更远的物体在图像平面上出现的像素更少
这可以通过创建一个双目标映射函数来实现: $\Phi:s\in[s_{n},s_{f}]\mapsto\dot{t}\in[t_{n},+\infty]$,相关论文引入了不同的映射函数
Discussions
Pros and Cons.
- uniform assumption采样是最容易实现的,但在大多数情况下效率最低
- Spatial skipping更有效的技术,因为大多数3D空间是空的,但它仍然在被占用但闭塞的区域内均匀采样,这些区域对最终渲染贡献不大
- PDF-based estimators 通常提供更准确的透射率估计,使样本更集中在高贡献区域(例如,表面),并在空区域和遮挡区域中更分散。
- 然而,这也意味着样本总是在整个空间中展开,没有任何跳跃。此外,由于(1)沿射线估算透光率的分段线性假设或(2)透光率估计器的潜在体素表示,目前的方法都在体渲染中引入了混叠效应。
- 最近的一项工作,Zip-NeRF,解决了与这两个确切问题相关的混叠问题(在他们的工作中称为“z-混叠”和“xy-混叠”),这在我们的统一框架下自然揭示出来。
Implementation Difficulties.
- 目前有效采样的实现都是高度定制的,并与每篇论文中提出的特定辐射场紧密集成。例如,在Instant-NGP和Plenoxels中,空间跳过是用定制的CUDA内核实现的。Mip-NeRF 360、K-planes和Nerfacto实现了一个提议网络,但它与它们的存储库紧密集成,只能支持存储库附带的有限类型的辐射场
- 然而,如前所示,采样过程独立于辐射场表示,因此它应该很容易在不同的NeRF变体之间转移。由于各种各样的实现细节,从头开始正确地实现有效的采样方法通常需要大量的工作。因此,拥有一个易于从存储库转移到存储库的实现对于支持NeRF的未来研究是有价值的。
Insights from Unified Formulation.
- 通过透射率估计器来理解采样光谱,为研究新的采样策略铺平了道路。例如,我们的框架揭示了来自Instant-NGP的占用网格和来自Mip-NeRF 360的建议网络不是相互排斥的,而是互补的,因为它们都旨在估计沿射线的透射率
- 因此,将它们结合起来变得很简单:首先可以使用占用网格计算透光率,然后使用建议网络细化估计的透光率。这样既可以跳过空白空间,又可以将样品集中到表面上。我们在第4.4节中探讨了这种方法,并证明它克服了提案网络方法的局限性,该方法总是对整个空间进行采样。此外,该公式可能会揭示诸如如何利用深度信息或其他先验信息增强采样程序等问题,我们鼓励读者进一步研究。
NerfAcc Toolbox
Design Principles
这个库的设计目标如下:
- Plug-and-play.
- Efficiency & Flexibility.
- Radiance Field Complexity.包括基于密度的辐射场和基于SDF的辐射场等等、静态和动态场景等等
Implementation Details
NerfAcc结合了两种可以与辐射场表示解耦的高级采样方法,即来自Instant-NGP的占用网格和来自Mip-NeRF 360的提议网络。
伪代码:
Sample as Interval.
使用$(t_{0}, t_{1}, r)$表示每个采样点(沿着第r条射线的区间的开始t0和结束t1),这种基于间隔的表示提供了三个关键优势:
- 首先,将样本表示为区间而不是单个点,可以支持基于锥形射线的抗混叠研究如Mip-NeRF和MipNeRF 360。
- 其次,由于几乎在所有情况下ti都不需要梯度,使用(t0, t1, r)而不是(x0, x1)来表示间隔,可以将采样过程从可微计算图中分离出来,从而最大化其速度。
- 最后,附加到每个样本上的射线id r支持不同数量的样本跨越一个打包张量的射线,我们将在下一段中讨论。在Nerfstudio中采用了类似的表示来支持各种辐射场。
Packed Tensor.
为了支持空间跳变采样,有必要考虑到每条射线可能导致不同数量的有效样本。将数据存储为具有形状(n_rays, n_samples,…)的张量和具有形状(n_rays, n_samples,…)的额外掩码,以指示哪些样本是有效的,但是当大部分空间为空时,会导致显着的低效内存使用。为了解决这个问题,在NerfAcc中,我们将样本表示为形状为(all_samples,…)的“压缩张量”,其中只存储有效的样本(参见算法1)。为了跟踪每个样本的相关射线,我们还托管了一个形状为(n_rays, 2)的整数张量,它存储了压缩张量中的起始索引和该射线上的样本数量。这种方法类似于Instant-NGP和PyTorch3D中使用的方法。
1 | ray0_id_in_packed = (n_rays,2)[0][0] #第0条光线在压缩张量中的起始索引 |
No Gradient Filtering.
在重要性采样后,不准确的透射率估计可能导致一些样本位于空白或闭塞的空间,特别是在占用网格等空间跳过方法中。这些样本可以在包含在PyTorch的可微计算图中之前通过使用禁用梯度的辐射场来评估它们的透射率来进行过滤。由于在滤波过程中不需要反向传递,这比在计算图中保留所有样本要快得多(~ 10倍)。实际上,在此过程中,透射率低于10−4的样品被忽略,对渲染质量几乎没有影响。请注意,该策略的灵感来自于Instant-NGP的实现。
Case Studies
我们在七篇论文中展示了NerfAcc在三种类型的NeRF上的灵活性:
- 静态NeRF (NeRF, TensoRF, Instant-NGP );
- 动态nerf (D-NeRF, K-Planes TiNeuVox );
- 以及用于相机优化的NeRF变化(BARF)
尽管这些方法中的许多,例如Instant-NGP, TensoRF, TiNeuVox和K-Planes,已经在效率上进行了高度优化,但我们仍然能够大大加快它们的训练速度,并在几乎所有情况下获得略好的性能。值得一提的是,TensoRF, TiNeuVox, K-Planes和BARF的实验是通过将NerfAcc集成到官方代码库中进行的,大约需要更改100行代码。我们的实验结果,包括我们的基线结果,如表2a,2b和2c所示,所有这些实验都是在相同的物理环境下进行的,使用单个NVIDIA RTX A5000 GPU进行比较。除了本文报道的实验外,NerfAcc还被集成到一些流行的开源项目中,如用于基于密度的nerf的nerfstudio,以及用于基于sdf的nerf的sdfstudio和instant-nsr-pl。
- Static NeRFs.在本任务中,我们实验了三种NeRF变体,包括原始的基于mlp的NeRF、TensoRF和Instant-NGP。我们展示了NerfAcc在有界场景(NeRF-Synthetic数据集,Tank&Template数据集)和无界场景(360数据集)上与基于mlp和基于体素的辐射场一起工作。值得注意的是,使用NerfAcc,可以用纯Python代码训练一个instantngp模型,并获得比官方纯CUDA实现稍好的性能,如表2a所示。
- Dynamic NeRFs. 在本任务中,我们将NerfAcc工具箱应用于T-NeRF, K-Planes和TiNeuVox,涵盖了合成(D-NeRF)和“野外”captures1(伴随HyperNeRF)。当应用占用网格方法来加速这些动态方法时,我们在所有帧之间共享占用网格,而不是用它来表示静态场景。换句话说,我们不是用它来表示一个区域在单个时间戳上的不透明度,而是用它来表示该区域在所有时间戳上的最大不透明度。这不是最优的,但仍然使渲染非常有效,因为这些数据集中有有限的移动。
- NeRFs for Camera Optimization.在本任务中,我们使用NerfAcc工具箱对带有摄动相机的NeRFSynthetic数据集进行BARF。目标是对多视点图像的辐射场和相机外源进行联合优化。我们观察到,NerfAcc提供的空间跳跃采样加快了训练速度,显著提高了图像质量和相机姿态重建。这些改进可以归因于我们的抽样过程中强制的稀疏性。这一发现可能为未来的研究提供有趣的途径。
- Analysis of Different Sampling Approaches.表2a中的结果表明,占用网格和提议网络采样之间的选择可以显著影响不同数据集上的运行时间和性能。由于每种方法都依赖于一组不同的超参数,因此通过扫描超参数空间来系统地比较两种方法是至关重要的。我们改变了占用网格的分辨率和行进步长,以及提议网络方法的样本数量和提议网络的大小。我们在图5中绘制了NeRF-Synthetic和Mip-NeRF 360数据集的每种方法的帕累托曲线。
- 该分析表明,占用网格采样适用于NeRF-Synthetic数据集,而提议网络方法在360数据集上表现更好。这可能是因为NeRF-Synthetic数据集包含更多可以使用占用网格方法有效跳过的空白空间。然而,在真实的、无界的数据中,占用网格方法的使用受到边界框和缺乏可跳过的空白空间的限制,这使得建议网络方法更加有效。这些实验使用了来自Instant-NGP的辐射场,具有相同的训练配方。
Combined Sampling
第3节中介绍的透光率估计器的统一概念的一个好处是,它可以直接结合两种不同的采样方法,因为它们本质上都提供了可用于重要性采样的透光率估计。例如,我们发现简单地在提议网络的顶部堆叠一个占用网格,可以显著减少光线的数量,并缩小NeRF-Synthetic数据集上剩余光线的近远平面。与仅使用建议网络进行重要性采样相比,这将导致质量的提高,从31.40dB提高到32.35dB,并将训练时间从5.2分钟减少到4.3分钟。图6显示了一个带有FICUS场景的示例,其中使用组合采样清除了浮动对象。本实验使用Instant-NGP中的HashEncoding作为亮度场表示。
Conclusions
总之,本文强调了先进的采样方法对提高神经辐射场(NeRF)优化和渲染效率的重要影响。我们证明了先进的采样可以显著加快各种最近的NeRF论文的训练,同时保持高质量的结果。NerfAcc是一个灵活的Python工具箱,它的开发使研究人员能够轻松地将高级采样方法合并到nerf相关方法中。探索和比较先进的采样方法是开发更有效和更容易获得的基于nerf的方法的重要步骤。所提出的结果还表明,通过先进的采样策略,可以进一步研究提高NeRF和其他相关技术的性能。