| Title | NeuS: Learning Neural Implicit Surfaces by Volume Rendering for Multi-view Reconstruction |
|---|---|
| Author | Peng Wang Lingjie Liu Yuan Liu Christian Theobalt Taku Komura Wenping Wang |
| Conf/Jour | NeurIPS 2021 (Spotlight) |
| Year | 2021 |
| Project | NeuS: Learning Neural Implicit Surfaces by Volume Rendering for Multi-view Reconstruction (lingjie0206.github.io) |
| Paper | NeuS: Learning Neural Implicit Surfaces by Volume Rendering for Multi-view Reconstruction (readpaper.com) |
实现了三维重建:从多视角图片中重建出了 mesh 模型
Code: Totoro97/NeuS: Code release for NeuS (github.com)
Project Page
Neus 的总目标是实现从 2D 图像输入中以高保真度重建对象和场景。
现有的神经表面重建方法,如 DVR[Niemeyer 等人,2020]和 IDR[Yariv 等人,2020],需要前景掩码作为监督,很容易陷入局部最小值,因此在对具有严重自遮挡或薄结构的对象进行重建时面临困难。
最近的新视角合成神经方法,如 NeRF[Mildenhall 等人,2020]及其变体,使用体积渲染来产生具有优化鲁棒性的神经场景表示,即使对于非常复杂的对象也是如此。然而,从这种学习的隐式表示中提取高质量的表面是困难的,因为在表示中没有足够的表面约束。
在 NeuS 中,我们提出将表面表示为有符号距离函数(SDF)的零水平集,并开发了一种新的体积渲染方法来训练神经 SDF 表示。我们观察到,传统的体积渲染方法会导致固有的几何误差(即偏差)对于表面重建,因此提出了一个新的公式,它在一阶近似中没有偏差,从而即使在没有掩码监督的情况下也能实现更准确的表面重建。
在 DTU 数据集和 BlendedMVS 数据集上的实验证明,NeuS 在高质量表面重建方面优于现有技术,尤其是对于具有复杂结构和自遮挡的对象和场景。
优点&不足之处
优点
- 通过手动在 meshlab 中 clean 稀疏点云 ply 中其他噪音位置的点云,构建了一个精确的 bounds,可以将模型不包括背景且几乎没有噪声的生成出来
- 通过构建 SDF 场,其零水平集相比 NeRF 的密度场水平集(Threshold = 25),生成的 mesh 更加精细,或者说更加平滑
- 对图片中深度突然变化的部分,sdf 也可以很好的重建出来
不足
- 对于无纹理物体(例如反光和阴影区域)的重建效果并不理想
- 需要手动在 meshlab 中 clean 稀疏点云 ply 中其他噪音位置的点云,这也是本文所说不需 mask 监督的方法
- (in paper:)一个有趣的未来研究方向是根据不同的局部几何特征,对不同空间位置具有不同方差的概率以及场景表示的优化进行建模
引言+相关工作
SDF 简单理解
SDF:输入一个空间中的点,输出为该点到某个表面(可以是曲面)最近的距离,符号在表面外部为正,内部为负。
给定一个物体的平面,我们定义 SDF 为空间某点到该平面距离为 0 的位置的点的集合(也就是物体表面的点)。如果空间中某点在物体表面之外,那么 SDF>0;反之如果空间中某点在物体表面之内,那么 SDF<0。这样子就可以找到物体表面在三维空间中的位置,自然而然的生成三维表面。
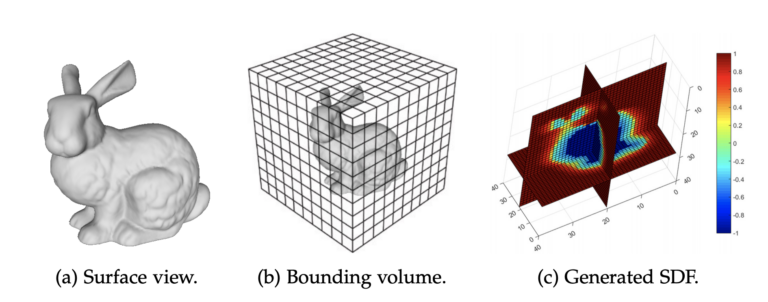
- mesh 是一种由图表示的数据结构,基于顶点、边、面共同组成的多面体。它可以十分灵活的表示复杂物体的表面,在计算机图形学中有着广泛的应用。从 nerf 输出的物理意义就可以想到,density 可以用来表示空间中沿光线照射方向的密度,那么我们可以通过基于密度的阈值来控制得到的 mesh。这种方法的好处是,训练好一个 nerf 的模型就可以得到一个 mesh 了。但是这种方式也有很大的缺点:一是训练结果会有很多噪音而且生成的 mesh 会有很多的空洞,二是很难控制一个合理的阈值。
- 这里我们可以考虑使用有向距离场(Signed distance function 简称 SDF)来取代 nerf 建模。使用 SDF 的一大好处是,SDF 函数本身在空间是连续的,这样子就不需要考虑离散化的问题。我们之后使用 Marching cubes 方法来生成 mesh。
- NeRF 生成一个带有密度和颜色信息的模型,通过使用 SDF 来代替密度,在密度大的地方表示为物体的表面,就可以生成一个 mesh 模型。
旷视 3d CV master 系列训练营二: 基于 NeRF 和 SDF 的三维重建与实践 - 知乎 (zhihu.com)
相较于以往的工作:

IDR 无法应对图片中深度突然变化的部分,这是因为它对每条光线只进行一次表面碰撞(上图(a)上),于是梯度也到此为止,这对于反向传播来说过于局部了,于是困于局部最小值,如下图 IDR 无法处理好突然加深的坑。
NeRF 的体积渲染方法提出沿着每条光线进行多次采样(上图(a)下)然后进行 α 合并,可以应对突然的深度变化但 NeRF 是专注于生成新视点图像而不是表面重建所以有明显噪声。
新的体积渲染方案:Neus,使用 SDF 进行表面表示,并使用一种新的体积渲染方案来学习神经 SDF 表示。
本文方法
本文集中在通过经典的绘制技术从 2D 图像中学习编码 3D 空间中的几何和外观的隐式神经表示,限制在此范围内,相关工作可以大致分为基于表面渲染的方法和基于体积渲染的方法
- 基于表面渲染:假设光线的颜色仅依赖于光线与场景几何的交点的颜色,这使得梯度仅反向传播到交点附近的局部区域,很难重建具有严重自遮挡和突然深度变化的复杂物体,因此需要物体 mask 来进行监督
- 基于体积渲染:eg_NeRF,通过沿每条射线的采样点的 α-合成颜色来渲染图像。正如在介绍中所解释的,它可以处理突然的深度变化并合成高质量的图像。提取学习到的隐式场的高保真表面是困难的,因为基于密度的场景表示对其等值集缺乏足够的约束。
相比之下,我们的方法结合了基于表面渲染和基于体积渲染的方法的优点,通过将场景空间约束为带符号距离函数 SDF,但使用体积渲染来训练具有鲁棒性的 representation。 - 同时 UNISURF 也通过体积渲染学习隐式曲面。在优化过程中,通过缩小体积渲染的样本区域来提高重建质量。
UNISURF 用占用值来表示表面,而我们的方法用 SDF 来表示场景,(因此可以自然地提取表面作为场景的零水平集,产生比 UNISURF 更好的重建精度。)
方法
构建了一个无偏,且 collusion-aware 的权重函数 w(t) = T(t)ρ(t)
给定一组三维物体的 pose 图像,目标是重建该物体的表面,该表面由神经隐式 SDF 的零水平集表示。
为了学习神经网络的权重,开发了一种新的体积渲染方法来渲染隐式 SDF 的图像,并最小化渲染图像与输入图像之间的差异。确保了 Neus 在重建复杂结构物体时的鲁棒性优化。
渲染步骤
场景表示
被重构物体的场景表示为两个函数:
- f:将空间点的空间坐标映射为该点到物体的符号距离
- c:编码与点 x 和观察方向 v 相关联的颜色
这两个函数都被 MLP 编码,物体的表面有 SDF 的零水平集表示 $\mathcal{S}=\left\{\mathbf{x}\in\mathbb{R}^3|f(\mathbf{x})=0\right\}.$
定义概率密度函数 $\phi_s(x) =\frac{se^{-sx}}{(1+e^{-sx})^{2}}$
其为 sigmoid 函数的导数 $\Phi_s(x)=(1+e^{-sx})^{-1},\text{i.e.,}\phi_s(x)=\Phi_s’(x)$
Neus 与 NeRF 对比
相同点:
- 使用 NeRF 提出的频率编码方式进行位置编码
- 使用了从像素坐标到世界坐标系转换的方式来生成光线(o,d)
不同点之一——使用了不同的相机坐标变换:
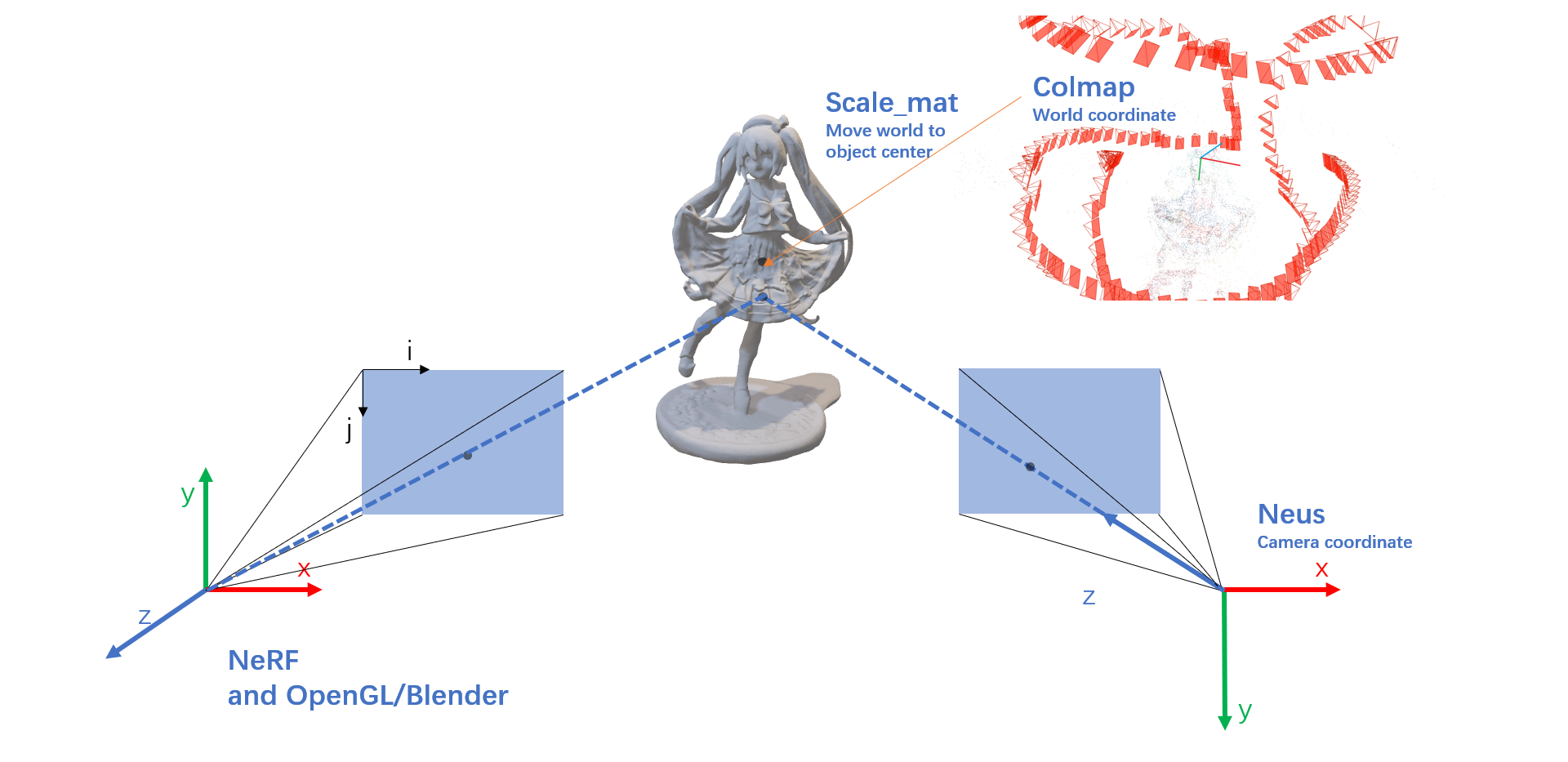
| Method | Pixel to Camera coordinate |
|---|---|
| NeRF | $\vec d = \begin{pmatrix} \frac{i-\frac{W}{2}}{f} \\ -\frac{j-\frac{H}{2}}{f} \\ -1 \\ \end{pmatrix}$ , $intrinsics = K = \begin{bmatrix} f & 0 & \frac{W}{2} \\ 0 & f & \frac{H}{2} \\ 0 & 0 & 1 \\ \end{bmatrix}$ |
| Neus | $\vec d = intrinsics^{-1} \times pixel = \begin{bmatrix} \frac{1}{f} & 0 & -\frac{W}{2 \cdot f} \\ 0 & \frac{1}{f} & -\frac{H}{2 \cdot f} \\ 0 & 0 & 1 \\ \end{bmatrix} \begin{pmatrix} i \\ j \\ 1 \\ \end{pmatrix} = \begin{pmatrix} \frac{i-\frac{W}{2}}{f} \\ \frac{j-\frac{H}{2}}{f} \\ 1 \\ \end{pmatrix}$ |
不同点:
体渲染、采样方式、训练出来的网络模型以及 near、far 计算方式
| Project | Neus | NeRF |
|---|---|---|
| 渲染函数 | $C(\mathbf{o},\mathbf{v})=\int_{0}^{+\infty}w(t)c(\mathbf{p}(t),\mathbf{v})\mathrm{d}t$ | $\mathrm{C}(r)=\int_{\mathrm{t}_{\mathrm{n}}}^{\mathrm{t}_{\mathrm{f}}} \mathrm{T}(\mathrm{t}) \sigma(\mathrm{r}(\mathrm{t})) \mathrm{c}(\mathrm{r}(\mathrm{t}), \mathrm{d}) \mathrm{dt}$ |
| 权重 | $\omega(t)=T(t)\rho(t),\text{where}T(t)=\exp\left(-\int_0^t\rho(u)\mathrm{d}u\right)$ 无偏、且遮挡 | $w(t)=T(t)\sigma(t) , \text { where } \mathrm{T}(\mathrm{t})=\exp \left(-\int_{\mathrm{t}_{\mathrm{n}}}^{\mathrm{t}} \sigma(\mathrm{r}(\mathrm{s})) \mathrm{ds}\right)$ 遮挡但有偏 |
| 不透明度密度函数 | $\rho(t)=\max\left(\frac{-\frac{\mathrm{d}\Phi_s}{\mathrm{d}t}(f(\mathbf{p}(t)))}{\Phi_s(f(\mathbf{p}(t)))},0\right)$ | $\sigma(t) = \sigma_{i}=raw2alpha(raw[…,3] + noise, dists)$ |
| 离散化 | $\hat{C}=\sum_{i=1}^n T_i\alpha_i c_i$ $T_i=\prod_{j=1}^{i-1}(1-\alpha_j)$ $\alpha_i=\max\left(\frac{\Phi_s(f(\mathbf{p}(t_i))))-\Phi_s(f(\mathbf{p}(t_{i+1})))}{\Phi_s(f(\mathbf{p}(t_i)))},0\right)$ | $\hat{C}(\mathbf{r})=\sum_{i=1}^{N} T_{i}\alpha_{i}\mathbf{c}_{i}$ $\hat{C}(\mathbf{r})=\sum_{i=1}^{N} T_{i}\left(1-\exp \left(-\sigma_{i} \delta_{i}\right)\right) \mathbf{c}_{i}$ $T_{i}=\exp \left(-\sum_{j=1}^{i-1} \sigma_{j} \delta_{j}\right)$ |
| 精采样 | 使用 sdf_network 得到的 sdf 求出 cos,并得到估计的 sdf,求出$\alpha$和 weight,用权重逆变换采样 | 经过 MLP 得到$\sigma$,求出$\alpha$和 weight,用权重逆变换采样 |
| 网络模型 | 隐式 SDF 场 | 隐式密度点云场 |
| near_far | 根据光线的原点和方向向量计算 | 不同的数据集有不同的计算方式 |
权重函数,Neus(右),NeRF(左)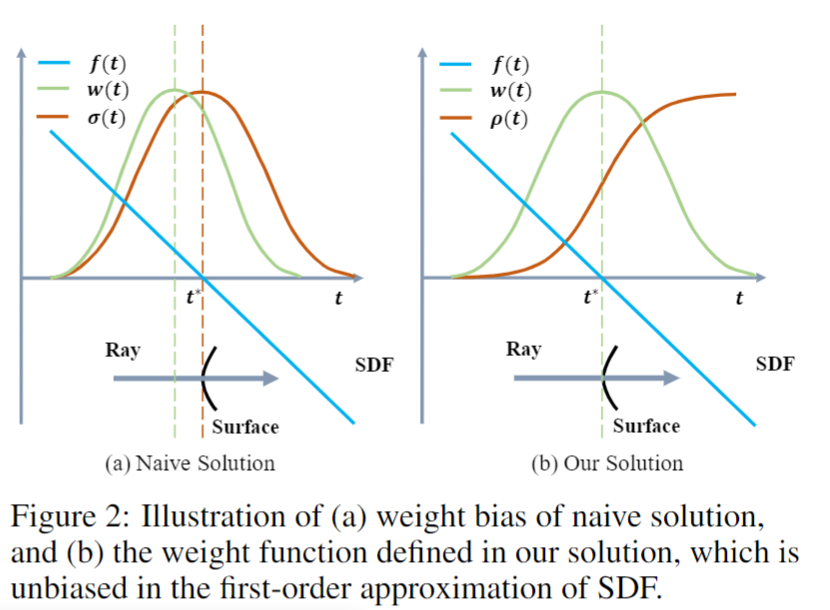
训练损失函数
loss 函数:
颜色损失:$\mathcal{L}_{color}=\frac{1}{m}\sum_k\mathcal{R}(\hat{C}_k,C_k).$
Eikonal term,类似IDR:$\mathcal{L}_{r e g}=\frac{1}{n m}\sum_{k,i}(|\nabla f(\hat{\mathbf{p}}_{k,i})|_{2}-1)^{2}.$
IGR:$\mathcal{L}_{mask}=\mathrm{BCE}(M_k,\hat{O}_k)$
- 沿着相机 ray 的权重之和:$\hat{O}_k=\sum_{i=1}^n T_{k,i}\alpha_{k,i}$
- 是否使用 mask 监督: (BCE 是二值交叉熵损失):$M_{k} ∈ {0, 1}$
实验
Dataset:DTU&BlendedMVS
DTU: 15 个场景、1600 × 1200 像素
BlendedMVS:7 个场景、768 × 576 像素
Baseline
表面重建方法:
- IDR:高质量表面重建,但需要前景 mask 监督
- DVR,没有比较
体积渲染方法: - NeRF:我们使用 25 的 threshold 从学习的密度场中提取网格(在补充材料中验证了为什么用 25 做阈值)
广泛使用的经典 MVS 方法:(MVS:Multi-View Stereo Reconstruction 多视点立体重建) - colmap:从 colmap 的输出点云中,使用 Screened Poisson Surface Reconstruction 重建 mesh
UNISURF:将表面渲染与以占用场做场景表示的体积渲染统一起来
实现细节
设感兴趣的物体在单位球体内,每批采样 512 条光线,单个 RTX2080Ti:14h(with mask),16h(without mask)
对于 w/o mask ,使用 NeRF++对背景进行建模,网络架构和初始化方案与 IDR 相似
环境配置:
autodl 镜像:
Miniconda conda3
Python 3.8(ubuntu20.04)
Cuda 11.8conda create -n neus python=3.8pip install -r requirements.txtpip --default-timeout=1000 install torch==1.9.0+cu111 torchvision==0.10.0+cu111 torchaudio==0.9.0 -f https://download.pytorch.org/whl/torch_stable.html
命令行运行程序:
python exp_runner.py --mode train --conf ./confs/wmask.conf --case <case_name> # 带 mask 监督python exp_runner.py --mode train --conf ./confs/womask.conf --case <case_name> # 不带 mask 监督
case_name 是所选物体数据集文件夹的名称
如果训练过程中中断,可以设置--is_continue 来进行加载最后的 ckpt 继续训练:python exp_runner.py --mode train --conf ./confs/wmask.conf --case <case_name> --is_continue
训练生成的结果会保存在根目录下 exp 文件夹下,可以看到 meshes 文件夹中保存了训练过程中的 mesh 模型,但面片较少。需要比较精细的 mesh 模型需要运行python exp_runner.py --mode validate_mesh --conf <config_file> --case <case_name> --is_continue # use latest checkpoint
多视角渲染python exp_runner.py --mode interpolate_<img_idx_0>_<img_idx_1> --conf <config_file> --case <case_name> --is_continue # use latest checkpoint
eg1: clock_wmask
1 | python exp_runner.py --mode train --conf ./confs/wmask.conf --case bmvs_clock #带mask |

除了主体模型外还有一些噪音
Neus: (结果与 resolution 无关)
- 使用 Neus 时,精细化模型参数设置为
resolution=512可能与此有关 - 改为
resolution=1024运行一下 validate_mesh
虽然运行后,面数更多了,但是细节处依然不清楚,可能需要继续增加训练的步数
- 看代码后:resolution 可以增加 object 的分辨率,再缩放到物体实际大小
- 可以看到 vertices 和 faces 都增加了,但由于 sdf 生成的相同,因此表面变得更精细,但细节处不清楚的地方依然不清楚
eg2: bear_womask
1 | python exp_runner.py --mode train --conf ./confs/womask.conf --case bmvs_bear #没有mask |

运行后,mesh 模型的面很少
1 | 将mesh模型精细化 |

eg3: Miku
模型不够理想
1 | python exp_runner.py --mode train --conf ./confs/womask.conf --case Miku |
效果:

- 底下的圆盘在 sparse_points.ply 中没有剔除干净,所以会出现额外的突出
- 面部表情、裙子装饰等细小部位不够细致,腿部也不够细致
- 头发部位 and 鞋子也由于在点云中没有完全去除噪点,因此会有额外的噪声被建模出来
0 to 38 render video:

Neus 如何给模型加纹理:
How to reconstruct texture after generating mesh ? · Issue #48 · Totoro97/NeuS (github.com)
1 | # get texture or say color |
- 这里采用了
dirs = -gradients来做渲染网络输入的观察方向,渲染网络输出的 color 值不是很准确- 由于 Miku 的表面较为复杂,训练时其表面法向与观察方向并不在一条直线上,因此在推理过程中这样设置的话生成的 color 值不准
渲染自定义视角的视频
根据中间两个 img 进行插值,中间插入生成的新视图图片
1 | python exp_runner.py --mode interpolate_<img_idx_0>_<img_idx_1> --conf <config_file> --case <case_name> --is_continue # use latest checkpoint |
eg: 1 to 2
 to
to 
Neus 使用自制数据集
自定义数据集 colmap 操作
自己拍一组照片: 手机或者相机 绕 物体拍一周,每张的角度不要超过 30°(保证有 overlap 区域)
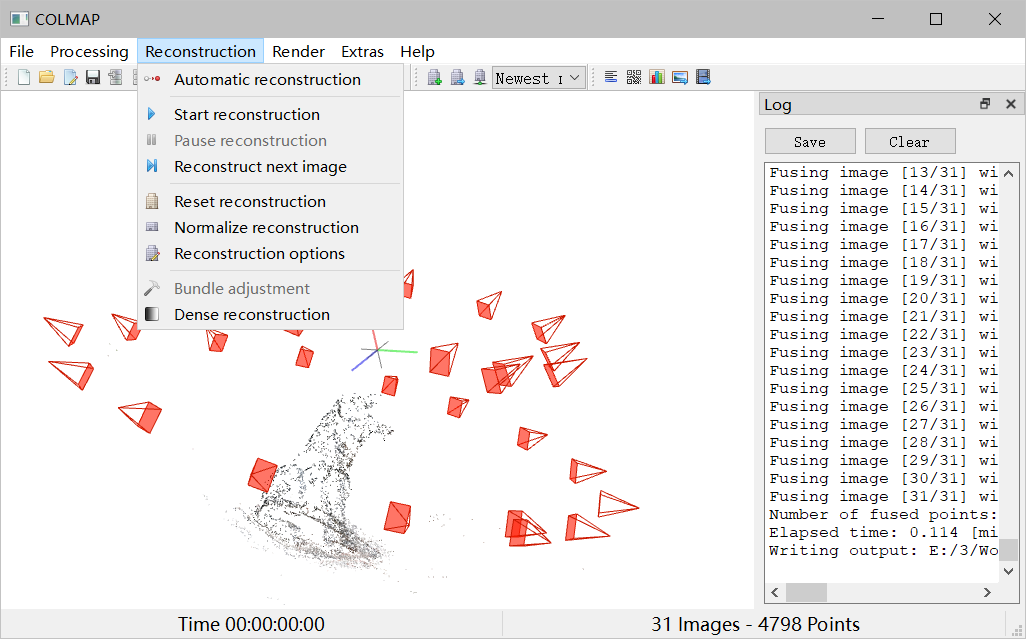
打开 colmap.bat 进入 gui 界面,点击Reconstruction,再点击Automatic reconstruction
workspace folder:选择 workspace 文件夹,注意不支持中文路径
Image folder:选择存放多视角图像的数据文件夹,注意不支持中文路径
Data type:选择 Individual images
Quality:看需要选择,选择 High 重建花费的时间最长,重建的质量不一定最好;
在 COLMAP 中看生成的稀疏点云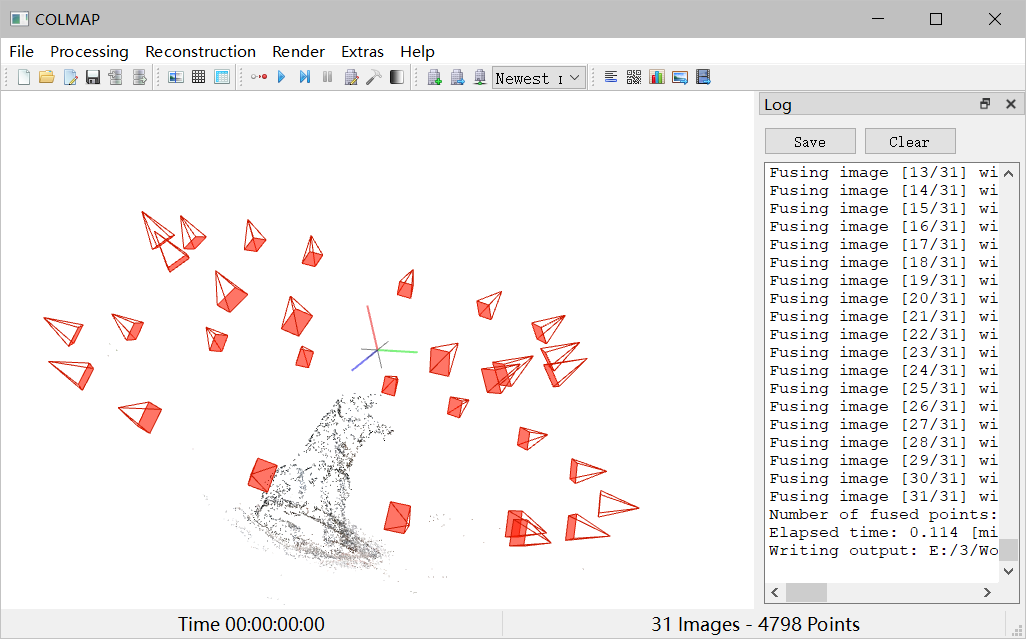
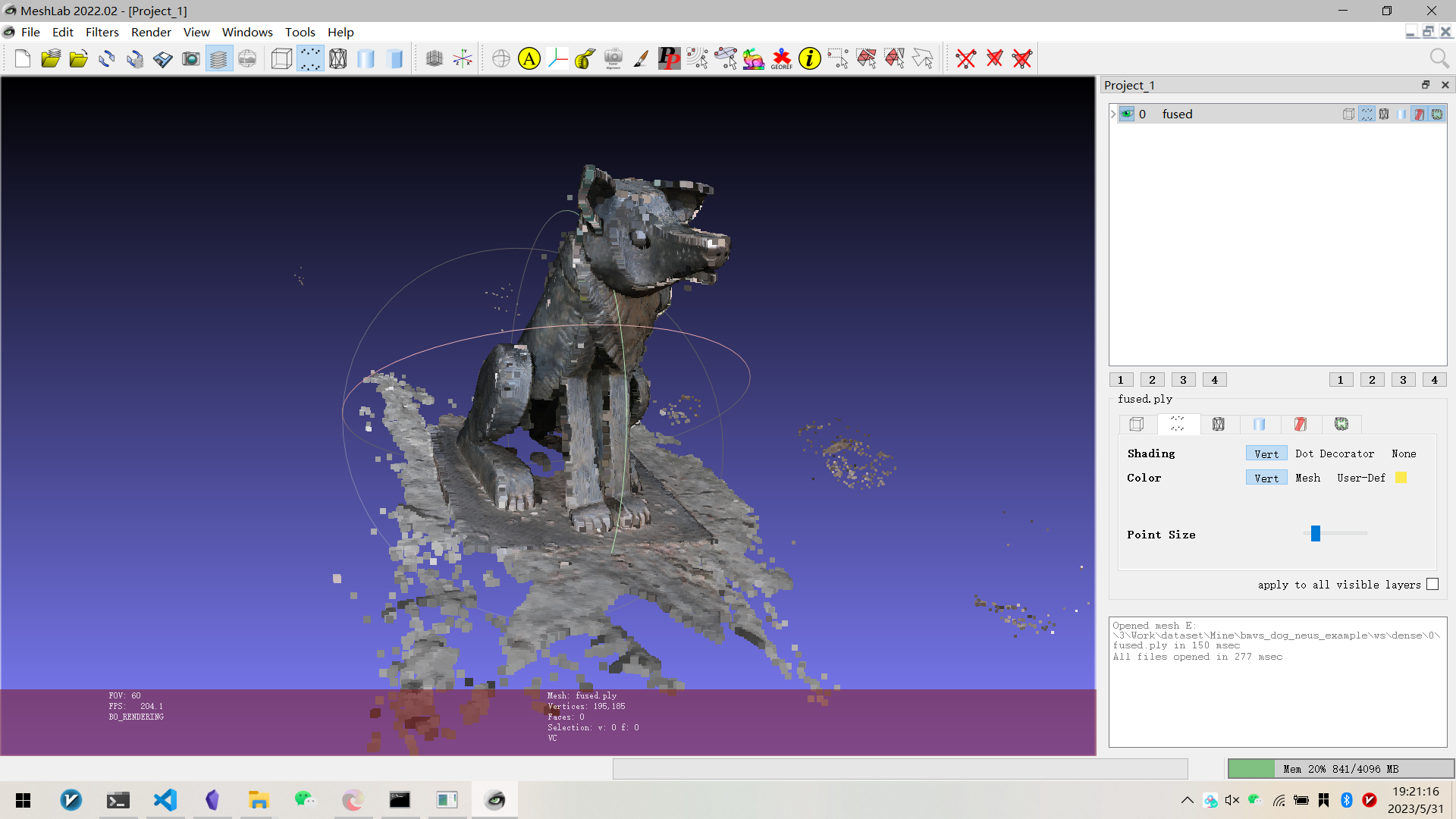
在 workspace folder 文件夹->dense->0 文件夹下找到 fused.ply 数据,用 meshlab 中打开可以看到稠密的三维重建的结果。
在 Meshlab 中查看生成的稠密点云
Neus 命令操作
两个文件夹:image 和 mask,一个文件
image 文件夹就是 rgb 图片数据,算法默认支持 png 格式。
mask 文件夹包含的是模型的前景图像,前景和后景以黑色和白色区分,如果配置文件选择 withou mask,其实这个文件夹的数据是没有意义的。但必须有文件,且名称、图像像素要和 image 的图像一一对应。
最后是 cameras_sphere.npz 文件,它包括了相机的属性和图像的位姿信息等,这个是需要我们自己计算的。官方给出了两种计算方案,第二种是用 colmap 计算 npz 文件。
使用 Colmap 生成 npz 文件
可以提前通过 colmap 运行得到 sparse/0/中的文件,或者通过 img2poses 中的 run_colmap()生成,然后再得到 sparse_points.ply
1 | cd colmap_preprocess |
将会生成:${data_dir}/sparse_points.ply,在 meshlab 中选择多余部分的 Vertices,并删除,然后保存为${data_dir}/sparse_points_interest.ply.
然后
1 | python gen_cameras.py ${data_dir} |
就会在 ${data_dir}下生成 preprocessed,包括 image、mask 和 cameras_sphere.npz