| Title | Ref-NeRF: Structured View-Dependent Appearance for Neural Radiance Fields |
|---|---|
| Author | Dor Verbin and Peter Hedman and Ben Mildenhall and Todd Zickler and Jonathan T. Barron and Pratul P. Srinivasan |
| Conf/Jour | CVPR 2022 (Oral Presentation, Best Student Paper Honorable Mention) |
| Year | 2022 |
| Project | Ref-NeRF (dorverbin.github.io) |
| Paper | Ref-NeRF: Structured View-Dependent Appearance for Neural Radiance Fields (readpaper.com) |
贡献:
- 借鉴Mip-NeRF的IPE,提出一种新的IDE来编码方向向量
- 表面法向通过Spatial MLP来预测,并通过$\mathcal{R}_{\mathrm{p}}=\sum_{i}w_{i}|\hat{\mathbf{n}}_{i}-\hat{\mathbf{n}}_{i}^{\prime}|^{2},$来正则化使得预测得到的法向量和进一步计算的反射更加平滑
- 这些MLP预测的法线往往比梯度密度法线更平滑
- $\hat{\mathbf{n}}(\mathbf{x})=-\frac{\nabla\tau(\mathbf{x})}{|\nabla\tau(\mathbf{x})|}.$Eq.3
- 计算反射光的新渲染方式$\mathbf{c}=\gamma(\mathbf{c}_d+\mathbf{s}\odot\mathbf{c}_s),$
- $\hat{\mathbf{\omega}}_r=2(\hat{\mathbf{\omega}}_o\cdot\hat{\mathbf{n}})\hat{\mathbf{n}}-\hat{\mathbf{\omega}}_o,$ Eq.4
- $L_{\mathrm{out}}(\hat{\mathbf{\omega}}_{o})\propto\int L_{\mathrm{in}}(\hat{\mathbf{\omega}}_{i})p(\hat{\mathbf{\omega}}_{r}\cdot\hat{\mathbf{\omega}}_{i})d\hat{\mathbf{\omega}}_{i}=F(\hat{\mathbf{\omega}}_{r}).$ 借鉴此BRDF,提出的Direction MLP 得出$c_s$
- 漫反射颜色$c_d$通过Spatial MLP预测得到
- s是高光色调
- 将空间MLP输出的瓶颈向量b传递到Direction MLP中,这样反射的亮度就可以随着3D位置的变化而变化。
- $\mathcal{R}_{\mathrm{o}}=\sum_{i}w_{i}\max(0,\hat{\mathbf{n}}_{i}^{\prime}\cdot\hat{\mathbf{d}})^{2}.$ 正则化项惩罚朝向远离相机的法线
局限:
- 编码导致的速度慢,和Spatial MLP的loss反向传播速度比Mip-NeRF慢
- 没有明确地模拟相互反射或非远距离照明
- 忽略互反射和自遮挡等现象
Limitation
- 编码和反向传播时速度慢
- 虽然Ref-NeRF在视图合成方面显著改善了之前表现最好的神经场景表示,但它需要增加计算量:评估我们的集成方向编码比计算标准位置编码稍微慢一些,并且通过空间MLP的梯度反向传播来计算法向量使我们的模型比mip-NeRF慢大约25%。
- 我们通过反射方向对出射亮度的重新参数化并没有明确地模拟相互反射或非远距离照明,因此在这种情况下,我们对mip-NeRF的改进减少了。
Conclusion
我们已经证明,先前用于视图合成的神经表示不能准确地表示和渲染具有镜面和反射的场景。
我们的模型Ref-NeRF引入了一种新的参数化和基于视图的外向辐射结构,以及法向量上的正则化器。
这些贡献使Ref-NeRF能够显著提高视图依赖外观的质量和场景合成视图中法向量的准确性。
我们相信这项工作在捕捉和再现物体和场景的丰富逼真外观方面取得了重要进展。
AIR
神经辐射场(Neural Radiance Fields, NeRF)是一种流行的视图合成技术,它将场景表示为连续的体积函数,由多层感知器参数化,提供每个位置的体积密度和依赖于视图的发射辐射。
虽然基于nerf的技术擅长表示具有平滑变化的视图依赖外观的精细几何结构,但它们往往无法准确捕捉和再现光滑表面的外观。
我们通过引入Ref-NeRF来解决这一限制,它用反射亮度的表示取代了NeRF对依赖于视图的照射亮度的参数化,并使用空间变化的场景属性集合来构造该函数。
我们表明,加上法向量上的正则化器,我们的模型显著提高了镜面反射的真实感和准确性。此外,我们表明,我们的模型的内部表示的外向辐射是可解释的和有用的场景编辑。
Introduction
神经辐射场(Neural Radiance Fields, NeRF)[24]使用神经体积场景表示从新颖的视点呈现引人注目的逼真的3D场景图像。给定场景中的任何输入3D坐标,“空间”多层感知器(MLP)在该点输出相应的体积密度,而“directional”MLP沿着任何输入观看方向输出该点的输出辐射。虽然NeRF渲染的视图依赖外观乍一看似乎是合理的,但仔细检查镜面高光会发现虚假的光泽伪影在渲染视图之间逐渐消失(图1),而不是以物理上合理的方式平滑地在表面上移动

与之前表现最好的神经视图合成模型mip-NeRF相比,Ref-NeRF显着改善了法向量(顶部行)和视觉真实感(其余行)。RefNeRF的改进在渲染帧(第2行和第3行)中很明显,在渲染视频(底部行极平面图像和补充视频)中更是如此,其光滑的高光在视图中真实地移动,而不是像mipNeRF那样模糊和褪色。图像PSNR(越高越好)和表面法向平均角度误差(越低越好)如图所示。
这些伪影是由NeRF(以及性能最好的扩展,如mipNeRF[2])的两个基本问题引起的。
- 首先,NeRF将每个点的出射亮度参数化为观看方向的函数,这很不适合插值。图2表明,即使是一个简单的玩具设置,场景的真实亮度功能也会随着视角方向的变化而迅速变化,特别是在高光周围。因此,NeRF只能从训练图像中观察到的特定观看方向准确地渲染场景点的外观,并且其对新视点的光滑外观的插值效果较差。
- 其次,NeRF倾向于使用物体内部的各向同性发射器来“伪造”镜面反射,而不是由表面上的点发出的与视图相关的辐射,从而导致物体具有半透明或“雾蒙蒙”的外壳。
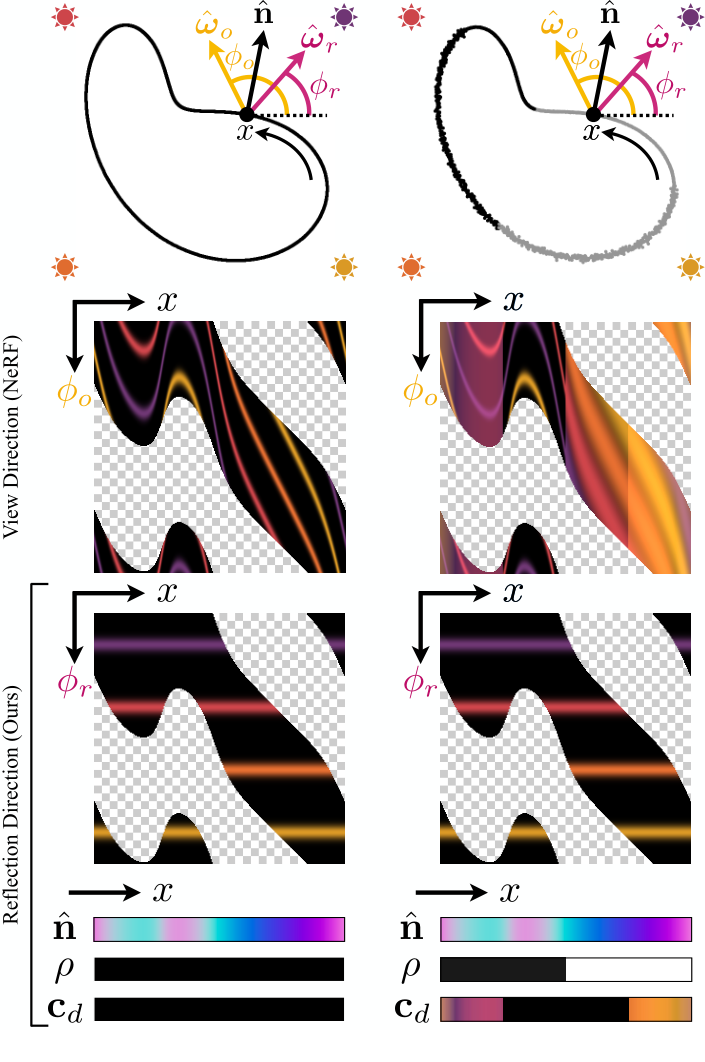
在NeRF和RefNeRF中,使用沿x参数化表面曲线的二维位角辐射切片,在彩色灯光下对光滑物体进行了显示。由于NeRF(中行)使用视角$φ_o$作为输入,当呈现有光泽的反射率(左)或空间变化的材料(右)时,它必须在高度复杂的函数之间进行插值,例如如图所示的不规则弯曲的彩色线条。相比之下,Ref-NeRF(下行)使用法向量$φ_n$和反射角$φ_r$来参数化辐射,并在其空间MLP中添加漫射颜色cd和粗糙度ρ,这使得即使对于有光泽或空间变化的材料,辐射函数也可以简单地建模。灰色棋盘格表示在x位置表面下的方向。
NeRF简单的使用观察方向来作为MLP输入,插值得到颜色,函数建模起来很复杂
Ref-NeRF使用更复杂的体渲染函数,输入包括法向量,反射角以及漫反射颜色和粗糙度,可使用的输入参数很多,因此函数的建模很简单
我们的关键见解是,构建NeRF对视图依赖外观的表示可以使底层功能更简单,更容易插值。我们提出了一个模型,我们称之为Ref-NeRF,它通过提供观看向量对局部法向量的反射作为输入,而不是观看向量本身,来重新参数化NeRF的定向MLP。图2(左栏)表明,对于一个由光滑物体组成的玩具场景,在远处照明下,这个反射辐射函数在整个场景中是恒定的(忽略光照遮挡和相互反射),因为它不受表面方向变化的影响。因此,由于定向MLP作为插值内核,我们的模型能够更好地“共享”附近点之间的外观观察,从而在插值视图中呈现更逼真的视图依赖效果。我们还引入了一个集成的定向编码技术,我们将外向的亮度结构成明确的漫射和高光组件,以允许反射的亮度功能保持平滑,尽管在场景中材料和纹理的变化。
虽然这些改进至关重要地使Ref-NeRF能够准确地插值依赖于视图的外观,但它们依赖于反映从NeRF的体积几何估计的法向量的观看向量的能力。这就出现了一个问题,因为NeRF的几何形状是模糊的,并且不是紧密地集中在表面上,并且它的法向量too noisy,对于计算反射方向是有用的(如图1的右列所示)。我们用一种新的体积密度正则化器改善了这个问题,它显著提高了NeRF法向量的质量,并鼓励体积密度集中在表面周围。使我们的模型能够计算准确的反射向量并呈现真实的镜面反射,如图1所示。
主要贡献:
- 基于观测向量对局部法向量的反射,NeRF的出射亮度的重新参数化(第3.1节)。
- 集成方向编码(第3.2节),当与漫射和高光颜色的分离(第3.3节)相结合时,使反射的亮度函数能够在不同材质和纹理的场景中平滑地插值。
- 一种将体积密度集中在表面周围并改善NeRF法向量方向的正则化方法(第4节)。
我们将这些变化应用于mip-NeRF[2]之上,mip-NeRF是目前表现最好的视图合成神经表示。我们的实验表明,Ref-NeRF产生了最先进的新视点渲染,并大大提高了以前高镜面或光滑物体的最佳视图合成方法的质量。此外,我们的外向辐射结构产生可解释的组件(法向量,材料粗糙度,漫射纹理和高光色调),使令人信服的场景编辑能力。
Related Work
我们回顾了NeRF和用于真实感视图合成的相关方法,以及用于捕获和渲染镜面外观的计算机图形学技术。
- 3D scene representations for view synthesis 视图合成,即使用一个场景的观察图像来从新的未观察到的摄像机视点渲染图像的任务,是计算机视觉和图形学领域一个长期存在的研究问题。
- 在可能密集捕获场景图像的情况下,简单的光场插值技术[12,18]可以呈现高保真度的新视图。然而,在大多数情况下,光场的详尽采样是不切实际的,因此从稀疏捕获的图像中进行视图合成的方法重建3D场景几何,以便将观察到的图像重新投影到新的视点中[8]。
- 对于具有光滑表面的场景,一些方法明确地构建虚拟几何来解释反射的运动[17,33,35]。早期的方法使用三角形网格作为几何表示,并通过启发式[7,9,42]或学习式[13,32]混合算法重新投影和混合多个捕获的图像来呈现新的视图。最近的研究使用了体积表示,如体素网格[20]或多平面图像[10,23,37,41,48],它们比网格更适合基于梯度的优化。虽然这些离散的体积表示可以有效地用于视图合成,但它们的立方缩放限制了它们表示大型或高分辨率场景的能力
- 最近基于坐标的神经表示范式用MLP取代了传统的离散表示,该MLP从任何连续输入的3D坐标映射到该位置的场景的几何形状和外观。NeRF[24]是一种用于真实感视图合成的有效的基于坐标的神经表示,它将场景表示为阻挡和发射与视图相关的光的粒子场。NeRF启发了许多后续的工作,将其神经体场景表示扩展到应用领域,包括动态和可变形场景[26],化身动画[11,27],甚至摄影旅游[21]。我们的工作重点是改进NeRF的核心组件:视图依赖外观的表示。我们相信,这里提出的改进可以用于改善上述许多NeRF应用程序的渲染质量。
- 我们的方法的一个关键组成部分考虑相机光线反射的NeRF的几何形状。这一想法被最近的作品所分享,这些作品扩展了NeRF,通过将外观分解为场景照明和材料来实现重照明[3 - 5,36,45,47]。至关重要的是,我们的模型将场景structures成不需要具有精确物理含义的组件,因此能够避免这些作品需要做出的强烈简化假设(例如已知照明[3,36],无自遮挡[4,5,45],单一材料场景[45]),以恢复照明和材料的明确参数表示。我们的工作还侧重于提高从NeRF几何中提取的法向量的平滑性和质量。最近将NeRF的神经体积表示与神经隐式表面表示相结合的研究也实现了这一目标[25,39,43]UNISURF,Neus。然而,这些方法主要关注从其表示中提取的等值面的质量,而不是呈现的新视图的质量,因此它们的视图合成性能明显低于性能最好的nerf类模型。
- Efficient rendering of glossy appearance 我们的工作灵感来自计算机图形学中用于表示和渲染依赖于视图的镜面和反射外观的开创性方法,特别是基于预计算的技术[29]。
- 在我们的定向MLP中编码的反射亮度函数类似于预过滤的环境地图[15,31],它们被引入用于高光外观的实时渲染。预过滤的环境图利用了这样的洞察力,即从表面发出的光可以被视为入射光和(径向对称的)双向反射分布函数(BRDF)的球面卷积,该函数描述了表面的材料特性[30]。在存储这个卷积结果之后,通过简单地索引到预先过滤的环境地图中,通过观察向量关于法向量的反射方向,可以有效地渲染与物体相交的光线。
- 我们的工作不是渲染预定义的3D资产,而是利用这些计算机图形学的见解来解决计算机视觉问题,我们正在从图像中恢复场景的可渲染模型。此外,我们的定向MLP对反射辐射的表示在计算机图形学中使用的预过滤环境地图表示的基础上进行了关键的改进:我们的定向MLP可以表示由于光照和场景属性(如材料粗糙度和纹理)的空间变化而导致的反射辐射的空间变化,而前面描述的技术需要计算和存储每个可能材料的离散预过滤辐射地图。
- 我们的工作也受到了计算机图形学中一系列工作的启发,这些工作重新参数化了directional函数,如BRDF[31,34]和外向辐射[42],以改进插值和压缩。
NeRF Preliminaries
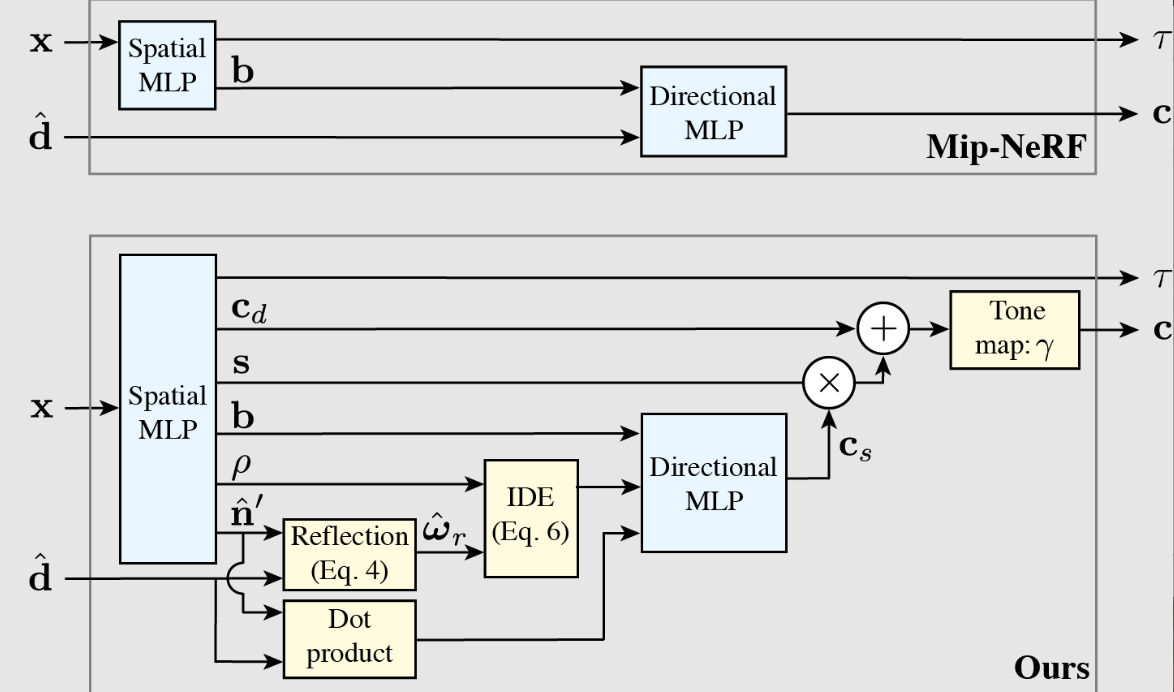
NeRF[24]将场景表示为发射和吸收光的粒子的体积场。给定任何输入3D位置x, NeRF使用空间MLP输出体积粒子的密度τ (x)以及“瓶颈bottleneck”向量b(x),该向量与视图方向d一起提供给第二个定向MLP,该方向d输出该3D位置上粒子发出的光的颜色c(x, d)(见图4的可视化)。请注意,Mildenhall等人[24]在他们的工作中使用了单层定向MLP,而之前的工作通常将NeRF的空间和定向MLP组合为单个MLP。
两个MLP在点$\mathbf{x}_{i}=\mathbf{o}+t_{i}\hat{\mathbf{d}}$处沿发源于o方向为d的射线进行查询,返回密度$\{\tau_{i}\}$和颜色$\{c_{i}\}$。这些密度和颜色使用数值正交[22]进行alpha合成,得到光线对应像素的颜色:$\mathbf{C}(\mathbf{o},\hat{\mathbf{d}})=\sum_iw_i\mathbf{c}_i,$ $w_i=e^{-\sum_{j<i}\tau_j(t_{j+1}-t_j)}\left(1-e^{-\tau_i(t_{i+1}-t_i)}\right).$ Eq.1
对MLP参数进行了优化,以最小化每个像素的预测颜色$\mathbf{C}(\mathbf{o},\hat{\mathbf{d}})$与其从输入图像中获取的真实颜色$\mathbf{C}_{gt}(\mathbf{o},\hat{\mathbf{d}})$之间的L2差异
$\mathcal{L}=\sum_{\mathrm{o,\hat{d}}}|\mathbf{C}(\mathbf{o},\hat{\mathbf{d}})-\mathbf{C}_{\mathrm{gt}}(\mathbf{o},\hat{\mathbf{d}})|^{2}.$ Eq.2
在实践中,NeRF使用两组mlp,一组是粗的,一组是细的,以分层采样的方式,两者都经过训练以最小化公式2中的损失
先前基于nerf的模型通过使用空间MLP来预测任何3D位置的单位向量[3,47],或使用相对于3D位置的体积密度梯度来定义场景中的法向量场[4,36] :$\hat{\mathbf{n}}(\mathbf{x})=-\frac{\nabla\tau(\mathbf{x})}{|\nabla\tau(\mathbf{x})|}.$Eq.3
Structured View-Dependent Appearance
在本节中,我们将描述Ref-NeRF如何将每个点的出射亮度结构为(预过滤的)入射亮度、漫射颜色、材料粗糙度和镜面色调tint,这比通过视图方向参数化的出射亮度函数更适合于整个场景的平滑插值。通过在我们的定向MLP中明确地使用这些组件(图4),Ref-NeRF可以准确地重现镜面高光和反射的外观。此外,我们的模型的外向辐射的分解使场景编辑
Reflection Direction Parameterization
对比NeRF直接使用视图方向,我们将输出亮度作为视图方向关于局部法向量反射的函数重新参数化: $\hat{\mathbf{\omega}}_r=2(\hat{\mathbf{\omega}}_o\cdot\hat{\mathbf{n}})\hat{\mathbf{n}}-\hat{\mathbf{\omega}}_o,$ Eq.4
式中,$\hat{\omega}_o=-\hat{\mathbf{d}}$为空间中某点指向摄像机的单位向量,$\hat n$为该点处的法向量。如图2所示,这种重新参数化使镜面外观更适合插值。
对于反射视图方向旋转对称的BRDFs,即对于某些叶瓣函数lobe function p满足$f(\hat{\mathbf{\omega}}_i,\hat{\mathbf{\omega}}_o) = p(\hat{\mathbf{\omega}}_r\cdot\hat{\mathbf{\omega}}_i)$的BRDF(包括Phong等brdf[28]),忽略互反射和自遮挡等现象,视相关辐射度仅是反射方向$\hat{\mathbf{\omega}}_r$的函数:
$L_{\mathrm{out}}(\hat{\mathbf{\omega}}_{o})\propto\int L_{\mathrm{in}}(\hat{\mathbf{\omega}}_{i})p(\hat{\mathbf{\omega}}_{r}\cdot\hat{\mathbf{\omega}}_{i})d\hat{\mathbf{\omega}}_{i}=F(\hat{\mathbf{\omega}}_{r}).$Eq.5
因此,通过查询具有反射方向的定向MLP,我们有效地训练它作为$\hat{\omega}_{r}$的函数输出该积分。由于菲涅耳效应等现象[15],更一般的BRDF可能会随着视图方向与法向量之间的角度而变化,因此我们还向定向MLP输入了$\hat{\mathbf{n}}\cdot\hat{\hat{\omega}}_{o}$,以允许模型调整底层BRDF的形状。
Integrated Directional Encoding
在具有空间变化的材料的现实场景中,radiance不能单独表示为反射方向的函数。较粗糙的材料外观随反射方向变化缓慢,而较光滑或光泽的材料外观变化迅速。我们引入了一种技术,我们称之为集成定向编码(IDE),它使定向MLP能够有效地表示具有任何连续值粗糙度的材料的辐射度函数。我们的IDE受到mip-NeRF[2]引入的集成位置编码的启发,它使空间MLP表示预过滤的抗混叠体积密度。
首先,我们不是像在NeRF中那样用一组正弦波编码方向,而是用一组球面谐波$\{Y_{\ell}^{m}\}.$编码方向。这种编码得益于在球体上的静止性,这一特性对欧几里得空间中位置编码的有效性至关重要[24,38]。
接下来,我们通过编码反射向量的分布而不是单个向量,使定向MLP能够推断具有不同粗糙度的材料。我们用von Mises-Fisher (vMF)分布(也称为归一化球形高斯分布)对单位球上定义的分布进行建模,以反射向量$\hat{\omega}_{r}$为中心,浓度参数κ定义为逆粗糙度$\kappa=1/\rho.$。粗糙度ρ由空间MLP(使用softplus激活)输出,并决定表面的粗糙度:较大的ρ值对应于具有更宽vMF分布的更粗糙的表面。我们的IDE使用在这个vMF分布下的一组球面谐波的期望值来编码反射方向的分布Eq.6
$\mathrm{IDE}(\hat{\mathbf{\omega}}_r,\kappa)=\left\{\mathbb{E}_{\hat{\mathbf{\omega}}\sim\mathrm{vMF}(\hat{\mathbf{\omega}}_r,\kappa)}[Y_\ell^m(\hat{\mathbf{\omega}})]\colon(\ell,m)\in\mathcal{M}_L\right\},$
$\mathcal{M}_{L}=\{(\ell,m):\ell=1,…,2^{L},m=0,…,\ell\}.$
在我们的补充中,我们证明了vMF分布下任意球谐的期望值有如下简单的封闭表达式:$\mathbb{E}_{\hat{\mathbf{\omega}}\sim\mathrm{vMF}(\hat{\mathbf{\omega}}_r,\kappa)}[Y_\ell^m(\hat{\mathbf{\omega}})]=A_\ell(\kappa)Y_\ell^m(\hat{\mathbf{\omega}}_r),$Eq.7
并且第$\ell$个衰减函数A (κ)可以用一个简单的指数函数很好地近似:$A_{\ell}(\kappa)\approx\exp\left(-\frac{\ell(\ell+1)}{2\kappa}\right).$ Eq.8
图3说明了我们的集成方向编码具有直观的行为;通过降低κ来增加材料的粗糙度对应于衰减编码的高阶球面谐波,从而产生更宽的插值核,从而限制了所表示的视相关颜色中的高频。
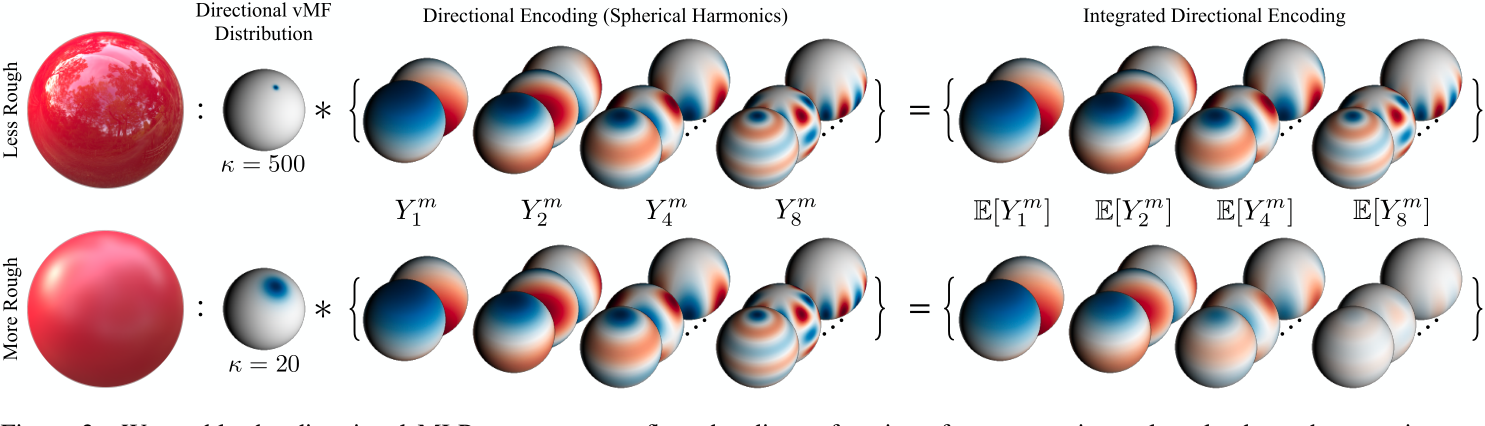
我们使用集成的方向编码使定向MLP能够表示任何连续值粗糙度的反射亮度函数。编码的每个分量都是一个球谐函数与一个具有浓度参数κ的vMF分布卷积,由我们的空间MLP输出(相当于vMF下球谐的期望)。较少粗糙的位置接收更高频率的编码(顶部),而更多粗糙的区域接收衰减的高频编码。我们的IDE允许在不同粗糙度的位置之间共享照明信息,并允许编辑反射率。
Diffuse and Specular Colors
我们通过分离漫射和高光组件进一步简化了出射亮度的函数,使用漫射颜色(根据定义)仅是位置的函数。我们修改空间MLP以输出漫射色$c_d$和高光色调s,并将其与定向MLP提供的高光色$c_s$相结合以获得单个颜色值:$\mathbf{c}=\gamma(\mathbf{c}_d+\mathbf{s}\odot\mathbf{c}_s),$Eq.9
式中$\odot$为元素乘法,$\gamma$为固定色调映射函数,将线性颜色转换为sRGB[1],并将输出颜色剪辑为lie[0,1]。
Additional Degrees of Freedom
照明的相互反射和自遮挡等效果会导致照明在场景中的空间变化。因此,我们将空间MLP输出的瓶颈向量b传递到定向MLP中,这样反射的亮度就可以随着3D位置的变化而变化。
Accurate Normal Vectors
虽然上一节中描述的出射辐射结构为镜面插值提供了更好的参数化,但它依赖于对体积密度的良好估计,以促进准确的反射方向矢量。然而,基于nerf的模型所恢复的体积密度场存在两个局限性:
1) 根据方程3的体积密度梯度估计的法向量通常非常嘈杂(图1和图5);
2) NeRF倾向于通过在物体内部嵌入发射器并使用“雾蒙蒙的”漫射表面部分遮挡它们来“伪造”镜面高光(见图5)。这是一个次优的解释,因为它要求表面上的漫射内容是半透明的,这样嵌入的发射器就可以“发光”。
我们通过使用预测法线来计算反射方向来解决第一个问题:
对于沿着射线的每个位置$x_i$,我们从空间MLP输出一个3向量,然后我们将其归一化以获得预测法线$\hat{\mathbf{n}}_i^{\prime}.$
我们使用一个简单的惩罚将这些预测的法线与沿每条射线$\{\hat{\mathbf{n}}_{i}\}$的潜在密度梯度法线样本联系起来:$\mathcal{R}_{\mathrm{p}}=\sum_{i}w_{i}|\hat{\mathbf{n}}_{i}-\hat{\mathbf{n}}_{i}^{\prime}|^{2},$ Eq.10
其中,$w_i$为第i个样本沿射线的权重,定义如式1。这些MLP预测的法线往往比梯度密度法线更平滑,因为梯度算子在MLP的有效插值核上起到了高通滤波器的作用[38]。
我们通过引入一个新的正则化术语来解决第二个问题,该术语惩罚“背向”的法线,即朝向远离相机的法线,沿着有助于光线渲染颜色的光线的样本$\mathcal{R}_{\mathrm{o}}=\sum_{i}w_{i}\max(0,\hat{\mathbf{n}}_{i}^{\prime}\cdot\hat{\mathbf{d}})^{2}.$ Eq.11
这种正则化在“雾蒙蒙”的表面上起着惩罚作用:当样本“可见”(高$w_i$)并且体积密度沿着射线减小时(即,$\hat{\mathbf{n}}_i^{\prime}$与射线方向$\hat{\mathrm{d}}$之间的点积为正),样本就会受到惩罚。这种法线方向的损失使我们的方法无法将镜面解释为隐藏在半透明表面下的发射器,并且由此产生的改进法线使Ref-NeRF能够计算精确的反射方向,用于查询定向MLP
在整篇论文中,我们使用梯度密度法线进行可视化和定量评估,因为它们直接展示了底层恢复场景几何的质量。
Experiments
我们在mip-NeRF[2]上实现了我们的模型,这是一个减少混叠的NeRF的改进版本。我们使用与mip-NeRF相同的空间MLP架构(8层,256个隐藏单元,ReLU激活),但我们使用了比mip-NeRF更大的方向MLP(8层,256个隐藏单元,ReLU激活),以更好地表示高频反射辐射分布。
我们使用与之前的视图合成工作相同的定量指标[2,24,45]PSNR, SSIM[40]和LPIPS[46]用于评估渲染质量,平均角误差(MAE)用于评估估计的法向量。
虽然NeRF[24]使用的“Blender”数据集包含了各种复杂几何形状的物体,但它在材料多样性方面受到严重限制:大多数场景主要是Lambertian的。为了探索更具挑战性的材料属性,我们创建了一个额外的“Shiny Blender”数据集,其中有6个不同的光滑物体在类似NeRF数据集的条件下在Blender中渲染(每个场景100个训练和200个测试图像)。表1中的定量结果突出了我们的模型在渲染这些高度镜面场景的新视图方面比mip-NeRF(以前表现最好的技术)具有显著优势。
我们还包括三个改进版本的mip-NeRF,它们都有一个8层定向MLP,分别是:
1)没有额外的组件;
2)在定向MLP中附加视点方向的法向量(如IDR[44]和VolSDF [43]);
3)我们的方向损失应用于mipNeRF的密度梯度法向量。
我们的方法在新颖的视图渲染质量和法向量精度方面明显优于所有这些改进的变体,都是以前表现最好的神经视图合成方法。
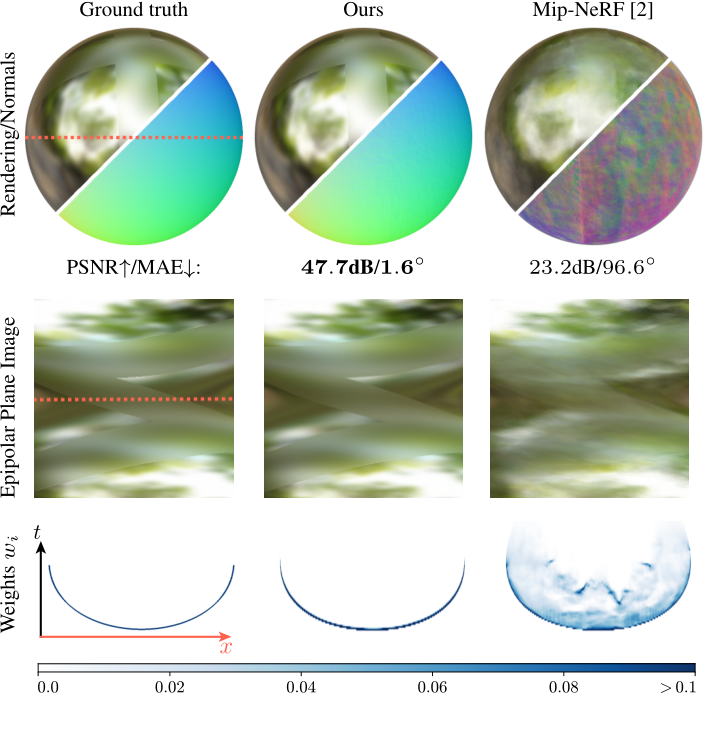
- 虽然PhySG[45]恢复更准确的法线,但它需要真实的对象掩码(所有其他方法只需要RGB图像),并且产生明显更差的渲染。图5展示了我们使用数据集中的一个对象的方法的影响:
- 虽然mip-NeRF[2]无法恢复具有两个粗糙度的简单金属球体的几何形状和外观,但我们的方法产生了近乎完美的重建。图9显示了该数据集的另一个可视化示例,展示了我们的模型在恢复法向量和渲染镜面方面的改进。
我们还将Ref-NeRF与来自原始NeRF论文[24]的标准Blender数据集上的最新神经视图合成基线方法进行了比较。表2显示,我们的方法在所有图像质量指标上优于所有先前的工作。与mip-NeRF相比,我们的方法在法向量的MAE方面也有了很大的提高(35%)。虽然混合表面体积VolSDF表示[43]恢复的法向量略准确(MAE低15%),但我们的PSNR比他们的高得多(6dB)。此外,VolSDF倾向于过度平滑几何,这使得我们的结果在质量上优于检查(参见图6)。
除了这两个合成数据集之外,我们还在一组3个Real Captured Scenes真实捕获的场景上评估了我们的模型。我们捕获了一个“轿车”场景,并使用了稀疏神经辐射网格论文[14]中的“花园球体”和“玩具车”捕获。图8和我们的补充表明,我们渲染的镜面反射和恢复的法向量通常在这些真实场景中更加准确。
我们的外向辐射结构使视图一致的场景编辑。虽然我们没有将外观进行完整的反向渲染分解为brdf和照明,但我们的各个组件的行为直观,并实现了从标准NeRF无法实现的视觉上合理的场景编辑结果。图7显示了场景组件的示例编辑,我们的补充视频包含了演示编辑模型的视图一致性的其他示例。