| Title | ShadowNeuS: Neural SDF Reconstruction by Shadow Ray Supervision |
|---|---|
| Author | Jingwang Ling and Zhibo Wang and Feng Xu |
| Conf/Jour | CVPR |
| Year | 2023 |
| Project | ShadowNeuS (gerwang.github.io) |
| Paper | ShadowNeuS: Neural SDF Reconstruction by Shadow Ray Supervision (readpaper.com) |
方法:假设场景不发光,且忽略相互反射
- 从二值阴影图像中获得可见表面的入射亮度,然后处理更复杂的RGB图像
- 入射光辐射$C_\mathrm{in}(x,l)=L\prod_{i=1}^N(1-\alpha_i)$, 从单视图、多光源中重建出3D shape
- $\mathcal{L}_\mathrm{shadow}=|\widehat{C}_\mathrm{in}-I_\mathrm{s}|_1.$
- 出射光辐射$C(x,-\mathbf{v})=(\rho_d+\rho_s)C_{\mathrm{in}}(x,l)(l\cdot\mathbf{n})$
- $\mathcal{L}_\mathrm{rgb}=|\widehat{C}-I_\mathrm{r}|_1$
表现:outperforms the SOTAs in single-view reconstruction, and it has the power to reconstruct scene geometries out of the camera’s line of sight.
Limitations
大量的实验证明了所提出的阴影射线监督在重建神经场景中的有效性。然而,作为对阴影射线建模的早期尝试,我们的方法是基于几个假设的。我们假设场景不发光,忽略相互反射来简化光建模。我们观察到一些薄结构过于复杂,在我们的重建中仍然可能缺失。这是一个普遍的限制,可以通过薄结构神经SDF的进展得到改善,正如最近的工作[10,27]。
Conclusion
与NeRF监控摄像机光线相比,我们在神经场景表示中实现了阴影光线的完全可微监控。该技术可以从单视图多光观测中进行形状重建,并支持纯阴影和RGB输入。我们的技术对点和方向光都很有效,可以用于3D重建和重照明。提出了一种多射线采样策略,以解决表面边界对阴影射线定位的挑战。实验表明,该方法在单视图重建方面优于sota,并且具有在相机视线之外重建场景几何形状的能力。
AIR
通过监督场景和多视图图像平面之间的摄像机光线,NeRF为新视图合成任务重建神经场景表示。另一方面,光源和场景之间的阴影光线还需要考虑。因此,我们提出了一种新的阴影射线监督方案,该方案既优化了沿射线的采样,也优化了射线的位置。通过监督阴影光线,我们成功地从多个光照条件下的单视图图像中重建了场景的神经SDF。给定单视图二元阴影,我们训练一个神经网络来重建一个不受相机视线限制的完整场景。通过进一步建模图像颜色和阴影光线之间的相关性,我们的技术也可以有效地扩展到RGB输入。我们将我们的方法与以前的工作进行了比较,在挑战性的任务上:从单视图二进制阴影或RGB图像中重建形状,并观察到显著的改进
Introduction
近年来,神经场[45]被用于三维场景的表征。由于能够使用紧凑的神经网络连续参数化场景,因此它达到了卓越的质量。神经网络的性质使其能够适应3D视觉中的各种优化任务,包括基于图像的[30,53]和基于点云的[28,33]等长期存在的问题。因此,越来越多的研究使用神经场作为三维场景的表征来完成各种相关任务。
其中,NeRF[29]是将部分基于物理的光传输[40]纳入神经场的代表性方法。光传输描述了光从光源到场景,然后从场景到相机的传播。NeRF考虑后一部分沿相机光线(从相机穿过场景的光线)建模场景和相机之间的相互作用。通过将不同视点的摄像机光线与相应的记录图像进行监督,NeRF优化了一个神经场来代表场景。然后,NeRF通过优化后的神经场,从新的视点投射相机光线,生成新的视点图像。
然而,NeRF并没有对从场景到光源的光线进行建模,这促使我们考虑:我们能否通过监督这些光线来优化神经场?这些光线通常被称为阴影光线,因为从光源发出的光可以被沿着光线的场景粒子吸收,从而在场景表面产生不同的光可见性(也称为阴影)。通过记录表面的入射光,我们应该能够监督阴影光线来推断场景几何。
鉴于这一观察,我们推导出一个新的问题,即监督阴影光线以优化表示场景的神经场,类似于对相机光线建模的 NeRF。与NeRF中的多个视点一样,我们使用不同的光方向多次照亮场景,以获得足够的观测。对于每个照明,我们使用固定相机将场景表面的光可见性记录为阴影射线的监督标签。由于通过 3D 空间连接场景和光源的光线,我们可以重建不受相机视线限制的完整 3D 形状。
当使用相机输入监督阴影光线时,我们解决了几个挑战。在NeRF中,每条射线的位置可以由已知的相机中心唯一确定,但阴影射线需要由场景表面确定,这是没有给出的,尚未重建。我们使用迭代更新策略来解决这个问题,其中我们从当前表面估计开始对阴影射线进行采样。更重要的是,我们将采样位置可微到几何表示,从而可以优化阴影射线的起始位置。然而,这种技术不足以在深度突然变化的表面边界处推导出正确的梯度,这与最近在可微渲染的发现相吻合[2,21,24,42,56]。因此,我们通过聚合从多个深度候选开始的阴影射线来计算表面边界。它仍然是有效的,因为边界只占少量的表面,但它显著提高了表面重建质量。此外,摄像机记录的RGB值编码了表面的出射辐射,而不是入射辐射。出射辐射是光、材料和表面取向的耦合效应。我们建议对材料和表面方向进行建模,以分解来自RGB输入的入射辐射,以实现重建,而不需要阴影分割(图1中的第1行和第2行)。由于材料建模是可选的,我们的框架还可以采用二值阴影图像[18]来实现形状重建(图1中的第3行)。

我们将我们的方法与以前的单视图重建方法(包括基于阴影和基于 RGB)进行比较,并观察到形状重建的显着改进。理论上,我们的方法处理了 NeRF 的双重问题。因此,比较这两种技术的相应部分可以启发读者在一定程度上更深入地了解神经场景表示的本质,以及它们之间的关系。
贡献总结:
- 利用光可见性从多个光照条件下从阴影或RGB图像重建神经SDF的框架。
- 一种阴影射线监督方案,通过模拟沿阴影射线的物理相互作用来包含可微光可见性,并有效地处理表面边界。
- 与之前关于 RGB 或二进制阴影输入的工作进行比较,以验证重建场景表示的准确性和完整性。
Related Work
- Neural fields for 3D reconstruction.神经场[45]通常使用多层感知器(MLP)网络参数化3D场景,该网络将场景坐标作为输入。它可以像点云[28,33]这样的3D约束来监督,以重建三维形状的隐式表示。也可以通过可微渲染从多视图图像优化神经场 [2, 30, 53]。
- NeRF[29]在具有复杂几何形状的场景中展示了显著的新视图合成质量。然而,NeRF中的密度表示对于正则化和提取场景表面并不容易。
- 因此,[31,43,52]提出将NeRF与表面表示相结合,重建高质量和定义良好的表面。虽然上述所有工作都需要已知的相机视点,[12,25,44]BARF等探索联合优化具有神经场的相机参数。
- NeRF不对光源进行建模,并假设场景发出光。这个假设适用于视图合成,但不是重新照明。一些作品将 NeRF 扩展到重新照明,其中阴影是一个重要的因素。[3, 4, 56] 需要共定位的相机光设置来避免捕获图像中的阴影。[5, 6, 57] 假设环境光平滑并忽略阴影。[11,35,39,49,51,59]采用以光方向为条件的神经网络对光相关阴影进行建模。其中,[11,49,51,58,59]首先使用多视图立体重建几何图形,并使用固定几何计算阴影。这些作品都没有细化几何图形以匹配捕获的图像中的阴影。然而,我们表明,通过利用阴影中的信息从头开始重建完整的 3D 形状。
- Single-view reconstruction. [17, 47, 54] 探索了从少数或一张图像重建神经场,但它们需要在预训练网络中进行数据驱动的先验,因此与我们的范围不同。非视距成像[32,38,46]采用瞬态传感器捕获时间分辨信号,使重建相机视图截锥之外的场景。光度立体[9,23]从定向光下捕获的图像重建表面法线。法线可以集成以产生深度图,但需要非平凡的处理 [7, 8]
- Shape from Shadows. 阴影表示遮挡引起的不同入射辐射,提供场景几何线索。从阴影重建形状的历史悠久为一维曲线[16,19]、二维高度图[14,34,37,55]和三维体素网格[22,36,48]。这些工作通常在不同的光方向下捕获,以获得对阴影的充分观察。阴影显示了这些工作重建表面细节[55]和复杂的薄结构[48]的潜力。该领域最近的工作是 DeepShahadow [18],它从阴影重建神经深度图。[41]也采用了具有固定照明但多个视点的不同设置,该设置集成了阴影映射来重建神经表示。同时独立,[50] 建议同时在神经场重建中使用阴影和阴影。特别是,他们在由根查找定位的不可微表面点计算阴影,使其依赖于可微阴影计算。我们提出了完全可微的阴影射线监督,优化了阴影射线样本和表面点,实现了纯阴影或RGB图像的神经场重建。
Ray Supervision in Neural Fields
本节首先揭示NeRF[29]训练中作为监督相机射线的本质。从那里,我们发现了一个可推广到任意射线的射线监督方案。该方案使阴影射线能够监督神经场景表示的优化是可行的。
Camera ray supervision in NeRF
NeRF 旨在优化神经场以适应感兴趣的场景。为了获得场景的观察,NeRF 需要在具有已知相机参数的多个相机视点记录图像。每个图像像素记录从已知方向穿过已知相机中心的相机光线的入射辐射。由于 NeRF 没有对外部光源进行建模并假设光是从场景粒子发射以简化具有固定照明的场景建模,因此入射辐射实际上归因于沿相机光线无穷小粒子的光吸收和发射的综合影响。为了拟合观察,NeRF 使用可微分体渲染来模拟神经场中的相同相机光线。NeRF使用求积来近似体渲染中的连续积分,采样N个距离$t_{1},\cdots,t_{N}$,从相机中心o沿相机射线方向v开始。利用场景密度$\sigma_{i}$和每个样本点$\mathbf{p}(t_i)=o+t_i\mathbf{v},$发射亮度$c_{i}$,摄像机处的估计亮度C可表示为:
$C(\mathbf{o},\mathbf{v})=\sum_{i=1}^{N}T_{i}\alpha_{i}c_{i},$方程式(1)
其中$\alpha_{i}=1-\exp{(-\sigma_{i}(t_{i+1}-t_{i}))}$ 是离散不透明度,$T_i=\exp(-\sum_{j=1}^{i-1}\sigma_j\cdot(t_{j+1}-t_j))$ 表示光透射率,即发射光的比例从点$\mathbf{p}(t_i)$到达相机。在像素处记录的入射辐射可用于监督模拟辐射 C。NeRF在每次迭代中对相机光线的随机子集进行训练。由于神经场接收来自许多摄像机光线在不同视点方向上行进的监督信号,因此它获得足够的场景信息来优化这些光线穿过空间中的神经场。
Generalized ray supervision
NeRF 可以监督相机光线以优化神经场的原因是多视图相机将辐射记录为光线的标签。此外,由于每个相机都经过校准,每个记录的光线的 3D 位置和方向都是明确定义的。我们可以将多视角相机的每个像素视为一个“射线传感器”,记录特定光线的入射亮度,因为每个像素在训练中独立使用。这些射线传感器是NeRF技术的关键。更一般地说,如果我们让“射线传感器”记录场景中的其他类型的光线,也可以实现场景重建。这促使我们考虑我们是否可以监督其他光线并设计光线传感器来记录它们的辐射。
Shadow ray supervision
由于相机光线在神经场景重建方面取得了巨大成功,作为光传输中的对应物,连接场景和从源的射线,也就是阴影光线,也应该能够用于重建神经场景。我们首先考虑一个理想的设置,其中许多假设的射线传感器被放置在不同但已知位置的场景中,如图 2 所示。为了沿着阴影光线观察场景,我们用已知的方向光来说明场景。每条射线传感器都捕获一条射线,该射线从光方向传递传感器。与 NeRF 不同,由于我们对源进行建模,我们假设场景不会发出光,这在物理上更正确并且可以简化以下过程。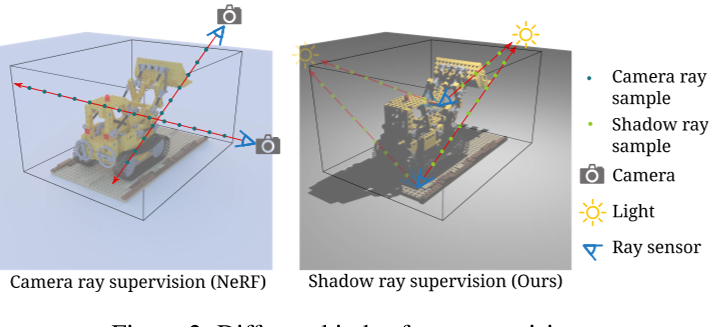
因此,射线传感器处的传入光是从光源发出的,并由沿射线的无穷小的粒子吸收。使用与等式1: $C(\mathbf{o},\mathbf{v})=\sum_{i=1}^{N}T_{i}\alpha_{i}c_{i},$类似的正交。 我们可以将神经场中模拟的传入辐射表示为
$C_\mathrm{in}(x,l)=L\prod_{i=1}^N(1-\alpha_i),$
其中,L为光源的强度,x为射线传感器的位置,l为光方向。为了获得足够的信息来约束优化,我们要求阴影光线在不同的方向上对场景进行分层。因此,我们逐个照亮具有多个光方向的场景,并每次记录传入的辐射。由于 NeRF 已经证明了这种光线监督方案的成功,因此在这里重建神经场景也很有希望。
Shadow ray supervision with a single-view camera
$C_\mathrm{in}(x,l)=L\prod_{i=1}^N(1-\alpha_i),$方程式(2)
请注意,在上述公式中,我们采用假设射线传感器来记录光方向上的入射辐射和场景中的已知位置。这些射线传感器是理想的,因为它们被放置在场景中的期望位置,总是面对光线。在这些强有力的假设下,可以对阴影射线获得足够的监督。然而,与NeRF不同的是,这些射线传感器很难在实际设置中实现,其中射线传感器只是多视角相机的像素。在本节中,我们将为真正的捕获设置提出一个更实用的设置。
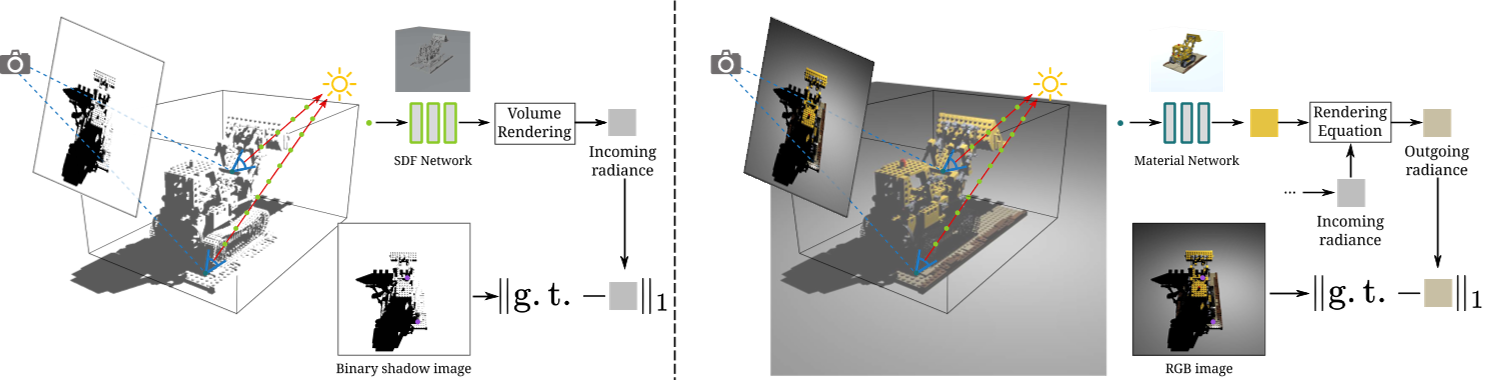
一般来说,我们从单视图相机进行阴影射线监督,这可能是先前公式中射线传感器的实用替代方案。我们类似地用$l$方向的光照亮场景。假设场景是不透明的,因此相机准确地捕捉到可见表面的出射辐射。我们考虑两种类型的相机输入:二值阴影图像[18]和RGB图像,如图3所示。
- 二值阴影图像使用输出亮度来确定一个点是否被照亮,这可以看作是二值化入射亮度的近似值。
- RGB图像是一种更复杂的情况,记录了材料、表面方向和入射辐射的综合影响。
我们将首先考虑更直接的情况,当我们可以从二值阴影图像中获得可见表面的入射亮度,然后处理更复杂的RGB图像。
我们的方法概述。所提出的阴影射线监督可以应用于两种输入类型的单视图神经场景重建:二值阴影图像(左)和RGB图像(右)。对于二进制输入,我们首先使用体绘制计算阴影射线的入射亮度。然后,我们构造了一个光度损失来训练神经SDF以匹配阴影。对于 RGB 输入,我们进一步使用材料网络和渲染方程将传入的辐射转换为传出辐射。训练SDF和材料网络以匹配地面真实颜色。
然而,另一个挑战是,给定记录的像素值,我们仍然不知道可见表面点的确切深度。因此,我们将场景观察作为相机观察方向在未知深度的点处的出射亮度。这个问题由提出的技术处理,这些技术确定深度并将传出辐射与入射辐射联系起来。
我们将场景表示为符号距离函数 (SDF) $\mathcal{S}=\big\{u\in\mathbb{R}^{3}|f(u)=0\big\},$ 的零水平集,其中 f 是一个神经网络,它回归输入 3D 位置的符号距离。相机可见的3D点是相机光线和SDF之间的第一个交点。请注意,这里相机光线仅用于确定表面点,而不是构建监督,这是阴影光线的工作。具体来说,射线行进[53]用于计算当前SDF的交点x。然后我们可以通过体绘制计算交点处的入射辐射度$C_{\mathrm{in}}(x,l)$。由于我们正在建模SDF而不是密度场,我们将Eq.(2)$C_\mathrm{in}(x,l)=L\prod_{i=1}^N(1-\alpha_i),$中的离散不透明度$\alpha_{i}$替换为NeuS[43]中SDF得到的不透明度$\alpha_{i}$,如
$\alpha_i=\max\left(1-\frac{\Phi_s(f(p(t_{i+1})))}{\Phi_s(f(p(t_i)))},0\right),$方程式(3)
其中$\begin{aligned}\Phi_s(x)=(1+e^{-sx})^{-1}\end{aligned}$ 是 sigmoid 函数,s 是控制等式的可学习标量参数。 Eq.(2) 接近体积渲染或表面渲染。
Differentiable intersection points
为了在给定SDF的情况下定位交点x,光线行进是最直接的选择。然而,由于不可微,容易被深度不正确的表面点误导,导致结果更差。为了使用反向传播的梯度优化交点,我们使用隐式微分 [1, 53],这使得交点可微到 SDF 网络参数为:
$\widehat{x}=x-\frac{v}{n\cdot v}f(x),$方程式(4)
- v 是相机光线方向
- $n=\nabla_{\mathbf{x}}f(x)$从SDF网络导出的表面法线
然后,我们使用 $C_{\mathrm{in}}(\widehat{x},\mathbf{l})$ 作为交点 x 处的可微辐射。由于x充当阴影射线的起始位置,它可以通过Eq.(2)的梯度进行优化。当计算的入射辐射度$:C_{\mathrm{in}}(\widehat{x},\mathbf{l})$与监督不一致时,SDF网络可以优化沿阴影光线的符号距离和光线的起始位置以适应观测。
Multiple shadow rays at boundaries
我们观察到,Eq.(4)中的$\hat x$只沿相机方向变化。当用记录的图像监督$C_\mathrm{in}(\widehat{x},\mathbf{l})$时,会在表面边界对应的像素处产生问题。在表面边界,像素跨越不同深度的不相连区域,其中每个区域占据像素区域的一部分。当$\hat x$垂直于相机方向v移动时,通过改变与每个区域成比例的面积,可以显著改变表面边界处的计算亮度。如果我们只从一个区域开始采样一条阴影光线,就会导致不正确的梯度,类似于可微网格渲染的情况[21,24]。
因此,我们首先获得一个对应于表面边界的像素子集Ω,并使用[56]中的表面行走程序为每个边界像素获取可微分的面积比$w$。然后我们在像素内的不同深度处找到两个交点$x_{\mathrm{n}}$和$x_{\mathrm{f}}$,并分别计算它们的入射亮度$\dot{C}_{\mathrm{in}}(\widehat{x}_{\mathrm{n}},l)$和$\dot{C}_{\mathrm{in}}(\widehat{x}_{\mathrm{f}},l)$。计算像素p对应的入射辐亮度时,我们将边界像素处的入射辐亮度平均为 Eq.5
然后,我们可以用二值阴影图像上的像素$I_{s}$来监督计算得到的入射辐射$\widehat{C}_\mathrm{in}$: $\mathcal{L}_\mathrm{shadow}=|\widehat{C}_\mathrm{in}-I_\mathrm{s}|_1.$ Eq.6
Decomposing incoming radiance by inverse rendering
为了处理RGB图像,我们结合了一个由材料、入射光和表面方向组成的逆渲染方程。我们将非朗伯BRDF建模为漫射分量$ρ_{d}$和镜面分量$ρ_{s}$。根据[23,49],我们使用球面高斯基的加权组合将镜面分量ρs表示为:$\rho_s=y^TD(h,n)$,其中$\cdot\mathbf{h}=\frac{\mathbf{l}-\mathbf{v}}{|\mathbf{l}-\mathbf{v}|}$为光方向l与视场方向−v之间的半向量(v为观察方向),D为镜面基,y为镜面系数。我们对另一个MLP网络g进行建模,以回归表面位置x处的材料性质$(\mathbf{\rho}_{d},\mathbf{y})=g(\mathbf{x})$。
点x处的出射辐射可表示为$C(x,-\mathbf{v})=(\rho_d+\rho_s)C_{\mathrm{in}}(x,l)(l\cdot\mathbf{n})$ Eq.7
边界像素对应的出射亮度$\widehat{C}$是多个样本的加权组合,类似于Eq.(5)。现在我们可以使用RGB图像上的像素$I_r$来监督计算的亮度: $\mathcal{L}_\mathrm{rgb}=|\widehat{C}-I_\mathrm{r}|_1$ Eq.8
Light source modeling
我们的技术支持定向光或点光作为光源来计算式(2)中的入射辐亮度。对于定向光,所有阴影射线的光方向$l$和强度$L$都是已知的,并且是均匀的。对于点光,我们计算点x处的光方向和光强为$L=\frac{L_p}{|q-x|_2^2},l=\frac{q-x}{|q-x|_2}$ Eq.9, 式中$L_{p}$为标量点光强,q为光位置
Training
为了正则化网络以输出有效的SDF,我们在M个样本点上添加一个Eikonal损失[15]为
$\mathcal{L}_{\mathrm{eik}}=\frac{1}{M}\sum_{i}^{M}(|\nabla f(p_{i})|_{2}-1)^{2}.$ Eq.10
我们训练Eikonal损失with Eq.(6)或Eq.(8),这取决于是否使用二进制阴影图像或RGB图像作为监督
我们的技术主要是在地面物体的有界场景上进行评估。为了约束摄像机光线,我们将不与SDF相交的摄像机光线设置为与地面相交。为了解决单视角输入的比例模糊问题,以精确的比例重建场景,我们假设地平面的位置和方向已知。更多关于地平面处理的讨论可以在补充材料中找到。
Experiments
Implementation details
对于二进制阴影输入和RGB输入,我们采用了类似于Neus[43]的SDF MLP网络。当处理RGB输入时,SDF网络输出一个额外的256维特征向量。它将与3D位置和表面法线连接,通过另一个MLP网络回归漫反射和高光系数。在训练过程中,我们在每批中随机选择4张图像,对每张图像采样256个像素位置作为监督信号。通过射线行进来定位相机光线交叉点,并使用从这些交叉点开始的表面行走过程[56]来计算可能的表面边界。我们对网络进行了150k次迭代训练,在单个RTX 2080Ti上大约需要24小时。更多的实现细节可以在补充材料中找到。
Evaluation
为了证明在场景重建中利用阴影光线信息的能力,我们在单视图二进制阴影图像和多个已知光方向下捕获的RGB图像上评估了我们的方法。我们首先与支持类似输入的最先进方法进行定性和定量比较。然后,通过综合消融研究来评估阴影射线监测方案的有效性。最后,我们展示了该方法的更多结果和应用。
上述实验在三个数据集上进行。
- 首先,我们使用DeepShadow[18]发布的数据集,其中包含六个场景在不同点光下的二进制阴影图像。每个场景都是类似地形的,并由垂直向下的摄像机捕捉到。对于其他视点捕获的更复杂的场景,我们发现没有公开可用的数据集可以满足我们的需求。因此,我们构建新的合成和真实数据集进行全面评估。
- 对于合成数据,我们使用来自NeRF合成数据集[29]的对象渲染八个场景。每个测试用例都是通过添加一个水平面来建模地面,将对象放置在平面上,并使用Blender[13]渲染场景来构建的。我们渲染二进制阴影图像和分辨率800×800的RGB图像。为了测试不同的光类型,我们用100个方向光和100个点光渲染每个场景。我们选择在上半球随机采样的光,类似于NeRF中的相机位置选择。我们的合成数据集具有镜面效果的现实材料。透明度和相互反射被禁用,因为这些效果超出了我们的假设。
- 我们还捕获了一个真实的数据集,以研究我们的方法对真实捕获设置的适用性。对于每个场景,我们将物体放在地面上,仅用手持手机手电筒照亮场景,并用固定摄像机捕捉它。当手持手电筒在场景中移动时,我们捕获了大约40个RGB图像,并获得类似[4]的光位置。我们在地面上放置一个棋盘,并用相同的固定摄像机捕捉额外的图像来校准地面。所用数据集的摘要请参见表1。
Metrics
由于比较的方法输出了可见区域的深度图或法线图,我们还通过L1的深度误差(depth L1)和在可见前景区域计算的平均角误差(normal MAE)的正态误差来评估单视图重建的质量。值得注意的是,由于一些比较方法输出的深度图没有特定的比例尺,因此深度L1是在使用ICP将深度图与地面真实值对齐后计算的。