| Title | Few-View Object Reconstruction with Unknown Categories and Camera Poses |
|---|---|
| Author | Hanwen Jiang Zhenyu Jiang Kristen Grauman Yuke Zhu |
| Conf/Jour | ArXiv |
| Year | 2022 |
| Project | FORGE (ut-austin-rpl.github.io) |
| Paper | Few-View Object Reconstruction with Unknown Categories and Camera Poses (readpaper.com) |
估计视图之间的相对相机姿态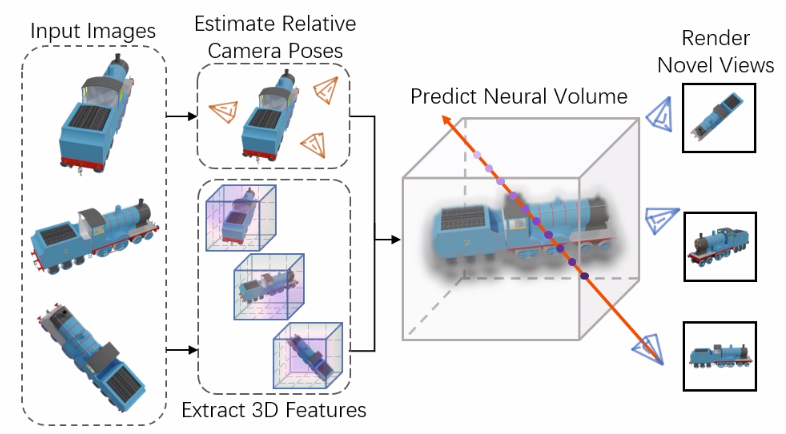
贡献:
- 2D提取voxel特征 —> 相机姿态估计 —> 特征共享+融合 —> MLP神经隐式重建 —> 渲染已有相机位姿的图片,并计算与gt之间的loss
- 新的损失函数
Conclusion
我们研究了在物体类别信息和相机姿态都未知的情况下,从几个视图重构物体的问题。我们的关键见解是利用形状重建和姿态估计之间的协同作用来提高这两项任务的性能。
我们设计了一个体素编码器和一个相对相机姿态估计器,它们以级联的方式进行训练。姿态估计器联合推断所有视图的姿态,并建立明确的三维跨视图对应关系。然后利用预测的姿态将从每个视图中提取的三维体素特征转换为共享的重建空间。然后预测神经体积,融合每个视图的信息。
我们的模型在重建和相对姿态估计方面明显优于现有技术。烧蚀研究也显示了我们设计的每个模块的有效性。我们希望我们的工作能够激励未来的努力,使物体重建广泛适用和可扩展,以捕获现实世界中的日常物体。
AIR
虽然物体重建近年来取得了很大的进步,但目前的方法通常需要密集捕获的图像和/或已知的相机姿势,并且在新的物体类别上泛化得很差。
为了在野外重建物体,这项工作探索了从一些没有已知相机姿势或物体类别的图像中重建一般的现实世界物体。我们工作的关键是用统一的方法解决两个基本的3D视觉问题-形状重建和姿态估计。我们的方法抓住了这两个问题的协同作用:可靠的相机姿态估计可以产生准确的形状重建,而准确的重建反过来又可以在不同视图之间产生鲁棒对应并促进姿态估计。
我们的方法FORGE预测每个视图的3D特征,并将它们与输入图像结合起来,建立跨视图对应关系,以估计相对相机姿势。然后通过估计的姿态将3D特征转换为共享空间,并融合到神经辐射场中。重建结果通过体绘制技术进行渲染,使我们能够在没有三维形状的情况下训练模型。
实验表明,FORGE可以可靠地从五个角度重构物体。我们的姿态估计方法在很大程度上优于现有的方法。预测姿态下的重建结果与使用地真姿态的重建结果相当。在新测试类别上的表现与训练期间看到的类别结果相匹配。
Introduction
通过RGB相机镜头重建真实世界的物体在AR/VR应用[3,36]、嵌入式AI[23,46]和机器人[11,59]中至关重要。传统方法[15,27,41]依赖于密集捕获的图像进行基于优化的重建。对密集输入的严格要求阻碍了这些方法的广泛适用性。相比之下,少视图对象重建[61,63]旨在从真实世界对象的少量图像(如在线产品快照)快速创建3D模型。然而,现有的工作要么需要3D的地面真实监督来进行训练[7],要么需要经过良好校准的相机姿势来进行推理[13,63],而且往往局限于看到的物体类别[61]。为了有效地捕捉现实生活中的物体,我们渴望开发一种实用的方法,在不依赖物体类别或相机姿势的情况下执行一般的少视图物体重建。
在本文中,我们介绍了FORGE (Few-view Object Reconstruction that GEneralize),如图1所示。与在特定类别的规范空间中重构对象的类别级方法不同[12,53],FORGE将单个输入编码为各自相机空间中的3D特征。然后,它估计输入视图之间的相对相机姿态,并将3D特征转换为具有估计姿态的共享重建空间。这种设计消除了对每个类别的规范重构空间的需要,并使FORGE能够跨对象类别进行泛化。转换后的三维特征随后被聚合到一个神经体中。我们遵循NeRF[26],并使用可微体积渲染来预测神经体积的新视图。该模型通过渲染图像和原始输入图像之间的重建损失进行监督,而不需要对物体形状进行3D监督
最重要的挑战是估计视图之间的相对相机姿态。现有的相机姿态估计工作利用了二维图像的对应关系[22,42,64]。对于少视点目标重建,相机姿态的剧烈变化阻碍了鲁棒二维对应关系的建立。为此,我们设计了一种新的以三维特征和二维图像为输入的相对姿态估计器,利用三维特征的对应性来消除重投影歧义。此外,为了避免成对相对姿态估计中的复合误差[17,39],FORGE基于所有输入之间的对应关系来预测姿态。因此,它受益于3D对应,并具有相机配置的全局理解。
FORGE利用形状重建和姿态估计之间的协同作用来提高两者的性能。
- 我们首先用真实的相机姿势训练模型。使用地面真实相机姿势鼓励模型学习3D几何先验,以便从每个输入视图中提取一致的3D特征。
- 然后,我们学习了相对相机姿态估计器,该估计器在已建立的视图一致的三维特征空间中准确地建立了三维对应关系
为了评估FORGE的泛化能力,我们设计了一个新的数据集,与以前的数据集相比,它具有不同的目标类别和更严格的相机设置[45,57]。我们的结果表明,FORGE在重建和相对相机姿态估计方面都大大优于现有技术。在预测姿态下的重建质量与使用地真相对相机姿态的性能相匹配。此外,FORGE在新对象类别上表现出较强的泛化能力,几乎与在已知对象上的表现相当。此外,我们可以很容易地从预测的神经体积中获得准确的体素重建,证明了FORGE在理解3D几何形状方面的强大功能
我们强调我们的贡献如下:
i) 我们开发了一种推广到新对象类别的少视图对象重建方法;
ii) 设计了一种新的相对姿态估计模型来处理较大的相机姿态变化;
iii) 我们的实验证明了形状重建和姿态估计之间的协同作用,可以提高这两个任务的质量。我们致力于发布我们的代码和数据集,以实现可重复性和未来的研究。
Related Work
- Multi-View Reconstruction 从多视图图像中重建物体和场景一直是计算机视觉中存在已久的问题[44]。
- 传统方法,如COLMAP[41],以及基于学习的对应方法,如DeepV2D[48],已经取得了巨大的成功。然而,这些SLAM [4,15,48,69], SfM[41,47,48]和RGB-D配准[2]方法需要密集的视图输入和平滑的相机运动。
- 另一项工作旨在仅使用稀疏甚至少数视图作为输入,其中出现了两种主要流。
- 第一种类型是无姿势的。例如3D- r2n2[7]和pix2vox++[58]直接聚合了所有输入的3D信息。SRT[40]利用大型变压器模型构建了一种无几何的方法。然而,无几何的方法很难推广到看不见的类别,因为缺乏意识到交叉视图对应的操作。
- 另一种方法是姿势感知,其中相机姿势用于将每个视图的特征对齐到一个共同的重建空间[13,30,31,33,54],并且它们受益于使用地面真实相机姿势。在本文中,我们开发了一种姿态感知方法,该方法以统一的方式预测形状和相对相机姿态,而在推理过程中不使用地面真实相机姿态。
- Volumetric 3D and Neural Radiance Fields 三维显式体积表示,特别是体素网格,已广泛用于对象建模[7,8,13,28,38,50,60]和场景建模[16,49]。
- 近年来,鉴于隐式表征在3D视觉任务上取得了令人印象深刻的成果[25,32],NeRF[26]采用隐式神经辐射场进行3D体积表征。NeRF及其变体实现了对复杂几何和外观建模的坚实能力[24,34,35,43,66]。尽管如此,NeRF使用一个全局MLP来拟合每个场景,这很难优化,而且泛化程度有限。
- 针对传统NeRF方法的局限性,提出了两种方法。
- 第一种是将二维图像特征集成到MLP中[37,55,63],由于3D-2D投影,MLP对相机姿态误差很敏感。
- 第二种是使用半隐式辐射场,其中辐射场附加到体素网格[20]。
- 此外,为了使亮度场更具通用性,一些工作[6,62,67]训练了3D编码器,这些编码器直接从图像中预测基于体素的亮度场。然而,MVSNeRF[6]被设置为固定数量的附近视图,ShelfSup[62]预测规范空间中的辐射场,NeRFusion[67]需要地面真实相机姿势。相比之下,我们的模型从原始图像中预测基于体素的亮度场,可以使用使用预测姿势的任意数量的视图进行融合。
- Reconstruction from Images without Poses.
- 使用体积表示的姿态感知重建方法的一个缺点是需要精确的相机姿态。许多作品都假定可以获得地面真实的相机姿势[13,26,45],这限制了它们的适用性。BARF[18]和NeRS[65]对关节的形状和位姿进行了优化。然而,它们仍然依赖于高度精确的初始姿势。FvOR[61]提出了一个使用密集点对应的姿态初始化模块,但需要三维形状监督。
- 另一项工作[17,28,51]利用了形状和姿势之间的协同作用。GRNN[51]训练了一个相对姿态估计器,并将其用于重建过程中的姿态预测。VideoAE[17]通过解除形状和姿态的纠缠,在完全无监督学习下学习相对相机姿态和3D表示。
- 然而,这两个作品从原始的2D视图中预测相对的相机姿势,这使得它们很难处理看不见的类别,无纹理的物体,以及由于2D模糊性而导致的大的姿势变化。
- 我们的方法在世界坐标中预测相对相机姿态。我们使用预测的姿势进行交叉视图融合,将形状和姿势预测与底层3D形状的感知联系起来。
Overview
研究了在不包含相机姿态和类别信息的少量RGB图像中重建目标的问题。
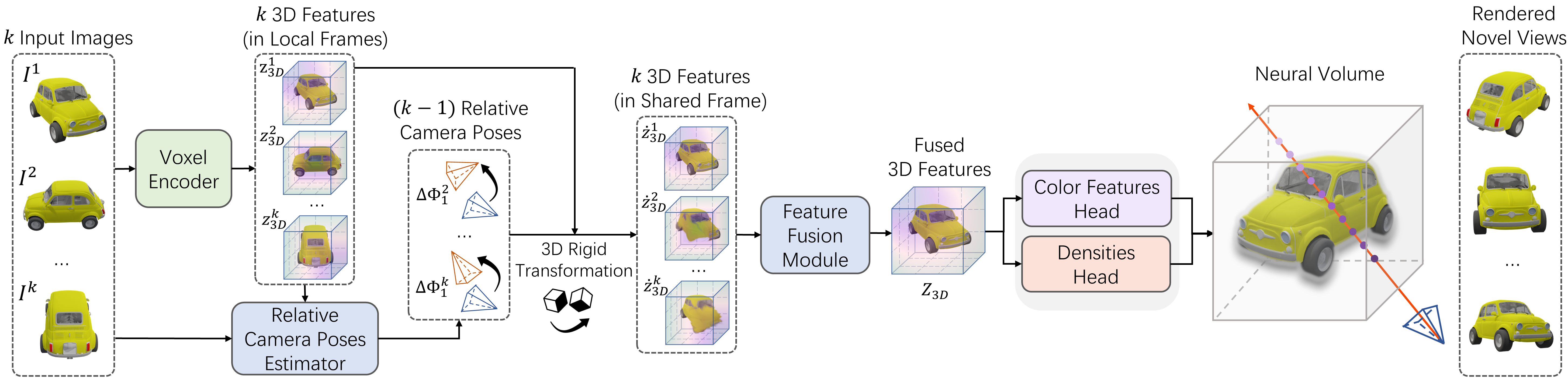
如图2所示,我们的模型FORGE从2D图像和从中提取的3D特征中学习相机姿态估计。为了处理少数视图之间的大姿态变化,我们的姿态估计器联合预测所有输入图像的相对相机姿态,而不是将成对姿态估计链接起来。为了处理来自新类别的对象,我们避免学习特定类别的先验。FORGE在自己的相机空间中提取每个视图的3D特征,并将其转换为具有估计的相对相机姿势的共享重建空间。因此,我们摆脱了特定于范畴的正则空间进行重构。
在共享重建空间中,我们使用特征融合模块对单视图三维特征进行信息聚合。然后,解码器头根据融合的特征预测神经体积。我们使用体绘制技术来产生重建结果。在训练过程中,我们渲染输入视图的结果,并使用基于2d的渲染损失作为监督。FORGE可以在没有物体几何形状的任何3D监督的情况下进行训练。我们设计了一个新的损失函数来学习跨视图一致的3D特征。此外,我们可以通过简单的阈值从神经体中获得准确的体素重建。下面我们将详细介绍FORGE和训练协议。
Method
模型的输入为由相关相机$\mathcal{C}=\{C^i|i=1,…,k\}$捕捉的k个图像观测值$\begin{aligned}\mathcal{I}=\{I^i|i=1,…,k\}\end{aligned}$
模型预测:
i) 所有视图的3D特征$\mathcal{Z}_{3D}=\{z_{3D}^{i}|i=1,…,k\}$;
ii) 相对相机位姿$\Delta\Phi_i=\{\Delta\Phi_i^j|j=1,…,k;j\neq i\},\Delta\Phi_1^j\in\mathbb{SE}(3),$其中$\Delta\Phi_{i}^{j}$为相机$C^j$相对于相机$C^i$的位姿,设第i帧为规范帧。
然后将这些特征通过相机的相对姿态变换到相机$C^i$的帧中,并进行融合来预测神经辐射场V。默认情况下,我们使用第一帧作为规范帧$C^i$,如果没有另行指定的话。我们将在下面详细介绍每个组件。
Voxel Encoder
对于视图$I^{i},$编码器$F_{3D}$将其编码为3D体素特征$z_{3D}=F_{3D}(I)$,其中$z_{3D}^i\in\mathbb{R}^{c\times d\times h\times u}$。
我们使用ResNet-50[10]提取二维特征图$z_{2D}^i=F_{2D}(I)$,其中$z_{2D}^i\in\mathbb{R}^{C\times h\times w}.$ 然后我们在$\mathbb{R}^{(C/d)\times d\times h\times w}$中将$z_{2D}^{i}$重构为3D体素特征作为去投影操作。我们最后对其执行一个3D卷积以进行细化,这将3D通道大小更改为c。
Relative Camera Pose Estimator
在姿态变化较大的情况下,估计相对相机姿态可能是一个不适定问题——两个视图之间共享的可见物体部分可能很小,这使得很难建立跨视图对应关系。此外,在2D图像或特征地图上建立2D对应关系[22,42]在3D-2D投影模糊的情况下是脆弱的。
我们引入了两种互补的新型姿态特征提取器。
如图3所示,我们使用全局姿态特征提取器,将所有2D视图作为输入,并对所有帧的姿态进行联合推理。
我们还构建了一个成对姿态特征提取器,该提取器在预测的3D特征上计算显式的3D对应关系。
该设计在三个方面有利于姿态估计:
i)全局姿态特征提取器允许信息在所有帧之间传递。它利用来自其他视图的信息(这些视图可能与规范视图共享更大的可见部分)来推断查询视图的相对位置。此外,在2D中对姿态进行全局推理比在3D特征中要便宜得多;
ii)在预测的3D特征上找到3D对应,避免了3D- 2D模糊问题,使姿态估计更加准确;
iii)姿态估计器的多模态输入(2D视图和3D特征)使其更具鲁棒性。
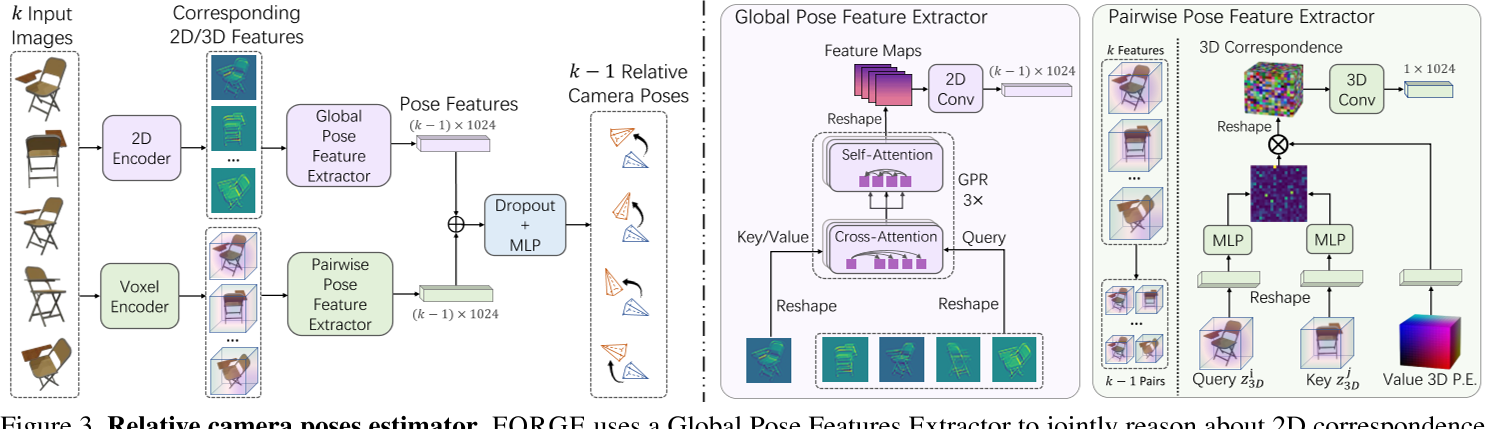
Global Pose Feature Extractor
全局姿态特征提取器吸收所有视图并联合预测姿态特征,记为$p_g\in\mathbb{R}^{(k-1)\times1024},$ 对应于所有k−1个查询视图$\mathcal{I}_{q}$。
我们使用另一个2D主干提取每个视图的2D特征图,记为$\mathbb{Z}_{2D}^{\prime}=\{z_{2D}^{\prime i}|i=1,…,k\},z_{2D}^{\prime i}\in \mathbb{R}^{h^{\prime}\times w^{\prime}\times1024}$。然后,我们将规范视图特征重塑为一维向量$k_g\in\mathbb{R}^{N_{2D}\times1024}$,其中$N_{2D}=h^{\prime}\cdot w^{\prime}.$。我们同样重构了k−1个查询视图特征$q_g\in\mathbb{R}^{N_q\times\tilde{1024}}$,其中${N_{q}=(k-1)\cdot N_{2D}.}$。然后使用多个全局姿态特征推理(GPR)模块来推断姿态特征。具体来说,每个GPR模块包括两个标准多头transformer[52]块。
- 在第一个转换块中,我们执行交叉关注,其中查询是查询视图的特征$\text{q}_g$,键和值是规范视图的特征$k_{g}$。块解释每个查询视图和规范视图之间的2D对应关系。
- 然后对更新后的查询视图特征执行自关注。它通过相互引用信息来共同改进所有查询视图的对应线索。
在GPR模块之后,我们将更新后的查询视图特征重塑为2D,并使用2D卷积将2D分辨率降至1,以获得全局姿态特征pg。
Pairwise Pose Feature Extractor
成对姿态特征提取器构建k−1个特征对,其中每个特征对由来自查询视图和规范视图的3D特征组成。然后分别预测它们的姿势特征。以查询视图$I^{i}$和规范视图$I^{1}$为例。输入为三维体素特征$z_{3D}^{i},z_{3D}^{1}$,输出为相对姿态特征$p_{l}^{i}\in\mathbb{R}^{1\times1024}.$。
具体来说,我们在$\mathbb{R}^{N_{3D}\times c}$中将三维特征重塑为一个一维向量,其中$N_{3D}=d \cdot h \cdot w.$。然后我们计算相似张量$S^i=z_{3D}^i\cdot(z_{3D}^1)^T,$,其中$(\cdot)^T$是转置运算。得到对应关系为$Corr_{1D}^i=S^{i}\cdot PE_{1D},$,其中$PE_{1D}$为扩展后的高维三维位置嵌入[52]。位置嵌入表示每个体素在高维空间中的位置。$PE\in\mathbb{R}^{d\times h\times w\times c}$ ,$Corr_{1D}^i\in\mathbb{R}^{N_{3D}\times c}.$。我们将其重塑为一个三维体$Corr^i\in\mathbb{R}^{d\times\hat{h}\times w\times c}$。
对于volume的每个体素,其特征表示其相应体素位置在高维空间规范视图3D特征中的位置。最后,我们使用3D卷积将其缩小到分辨率1,得到相对姿态特征$p_{l}^{i}$ of $\{I^{i},I^{1}\}.$。我们将所有查询视图的特征连接起来作为最终输出$p_l\in\mathbb{R}^{(k-1)\times1024}$。
Pose Prediction
我们将两个特征提取器预测的姿态特征连接起来,得到最终的特征p。我们使用MLP来回归相对相机姿态$\Delta\Phi_{i}=\{\Delta\Phi_{1}^{j}|j=2,…,k\}$表示k−1个查询视图。为了防止模型过度拟合任何一个提取的特征,我们在训练期间在MLP之前使用概率为0.6的Dropout层。
Feature Fusion Module
Feature Transformation
一般情况下,我们使用刚体变换$T_{i}^{j}=\Phi^{j}\cdot(\Phi^{i})^{-1}$将相机$C^i$帧中的一个三维点变换到相机$C^j$帧中,其中$(\cdot)^{-\ddot{1}}$为逆运算,Φ为相机姿态。给定k−1个查询视图提取的3D特征,我们使用相机姿势将它们转换为规范视图的相机帧。具体来说,查询视图的相机姿态由$\Phi^{i}=\Phi^{1}\cdot\Delta\Phi_{1}^{i}$计算,其中$Φ_1$为固定的规范姿态。将变换后的三维特征记为:$\dot{z}_{3D}=\{\dot{z}_{3D}^i|i=1,…,k\}.$。
View Fusion
对于变换后的3D特征$\dot{\mathbb{Z}}_{3D}$,我们首先对它们进行平均池化。池化的3D特征作为初始化,使用ConvGRU将perview特征依次融合到最终的3D特征$Z_{3D}$中[1]。具体来说,融合序列由相对相机姿势决定,我们首先融合更接近规范视图的视图特征。当预测的相机姿态有噪声时,平均池化操作保留低频信号,顺序融合恢复高频细节。
Neural Volume-based Rendering
受NeRF[26]的启发,我们用辐射场重建物体。这些领域,表示为神经体积,以完全前馈的方式预测。
Definition and Prediction
我们将神经体积表示为$V:=(V_{\sigma},V_{f})$,其中$V_{\sigma}$为密度值,$V_{f}$为神经特征。它们有助于重建物体的几何形状和外观。给定融合后的三维特征volume $Z_{3D}$,我们使用由多个三维卷积层组成的两个预测头分别预测$V_{\sigma}$和$V_{f}$。
Volume Rendering
我们使用体绘制在2D上读出预测的神经体积为$(\hat{I},\hat{I}_\sigma)=\pi(V,\Phi),$,其中Φ为相机姿态,$\hat{I}\mathrm{and}\hat{I}_{\sigma}$为渲染的图像和掩码。我们遵循NeRF中的体渲染技术[26]。不同的是,对于每个3D查询点p,我们通过插值相邻体素网格来获得其3D特征。此外,我们首先渲染一个特征映射,然后使用几个2D卷积来预测最终的RGB图像[29]。
Training Protocol
我们分三个阶段训练FORGE。
- 首先,我们在ground-truth pose下使用$L_{3D}=L_{mv}+L_{corr}$训练体素编码器(第4.1节)、融合模块(第4.3节)和体渲染器(第4.4节)
- 具体来说,$L_{mv}$是应用在所有输入视图上的二维光度损失。
交叉视图一致性损失$L_{corr}$的设计是为了促使从不同视图提取的同一对象部分对应的特征在特征空间中接近,从而使重建结果更加连贯。完善的特征空间也受益于基于对应的姿态估计,因为使用我们的基于相似性的方法在特征空间中查找跨视图对应变得更加容易。我们计算渲染结果的损失。
我们将输入视图分成两组:我们使用一组(n个视图)来构建神经体积,并使用另一组(k−n个视图)的相机来渲染结果,反之亦然。第二组视图的重构应该是合理的。
$L_{corr}=\frac{1}{k-n}\Sigma_{i=n+1}^{k}L_{2D}(I_{\sigma}^{i},\ddot{I}_{\sigma}^{i},I^{i},\ddot{I}^{i}),$其中,$\ddot{I}\mathrm{~and~}\ddot{I}_\sigma$是使用视图子集作为输入呈现的结果。
- 其次,我们用损失$L_{pose}=||\Phi-\hat{\Phi}||^{2}$训练相对相机姿态估计器,其中$\Phi,\hat$是真实的和预测的相对相机姿态。两个姿态特征提取器分别进行训练,然后一起进行微调。
- 最后,我们使用上述所有损失对模型进行端到端的微调。我们从经验上观察到,单阶段训练导致崩溃。我们推测姿态估计器依赖于来自初始化良好的体素编码器的表示。
Experiments
new dataset: Kubric Synthetic Dataset.
实现细节。输入分辨率为256 × 256。我们使用k = 5张图像,分为2和3个视图,来计算跨视图一致性损失。我们设$λ_{img} = 5$, $λ_{p} = 0.02$, $λ_{pose} = 1$。神经体积包含$64^3$个体素。我们在每条光线上采样64个点进行渲染。有关更多培训详情,请参阅附录。
我们采用标准的新视点合成指标PSNR(以dB为单位)和SSIM[56]来评估重建结果。我们还评估了相对相机姿态误差。
campare
在重建方面,我们与PixelNeRF[63]和SRT[40]在地真位摆下进行比较,验证FORGE学习三维几何先验的能力。
对于相对姿态估计,我们比较了
i)基于2d的VideoAE[17], 8点TF[39],它们分别预测每个查询视图的姿态;
ii)基于2d的RelPose[64],共同估计所有相对姿势,
iii)基于3d的Gen6D,分别预测每个查询视图的姿态。所有的姿态估计基线都是用真实姿态训练的。