| Title | UNISURF: Unifying Neural Implicit Surfaces and Radiance Fields for Multi-View Reconstruction |
|---|---|
| Author | Michael Oechsle Songyou Peng Andreas Geiger |
| Conf/Jour | ICCV 2021 (oral) |
| Year | 2021 |
| Project | UNISURF: Unifying Neural Implicit Surfaces and Radiance Fields for Multi-View Reconstruction (moechsle.github.io) |
| Paper | UNISURF: Unifying Neural Implicit Surfaces and Radiance Fields for Multi-View Reconstruction (readpaper.com) |
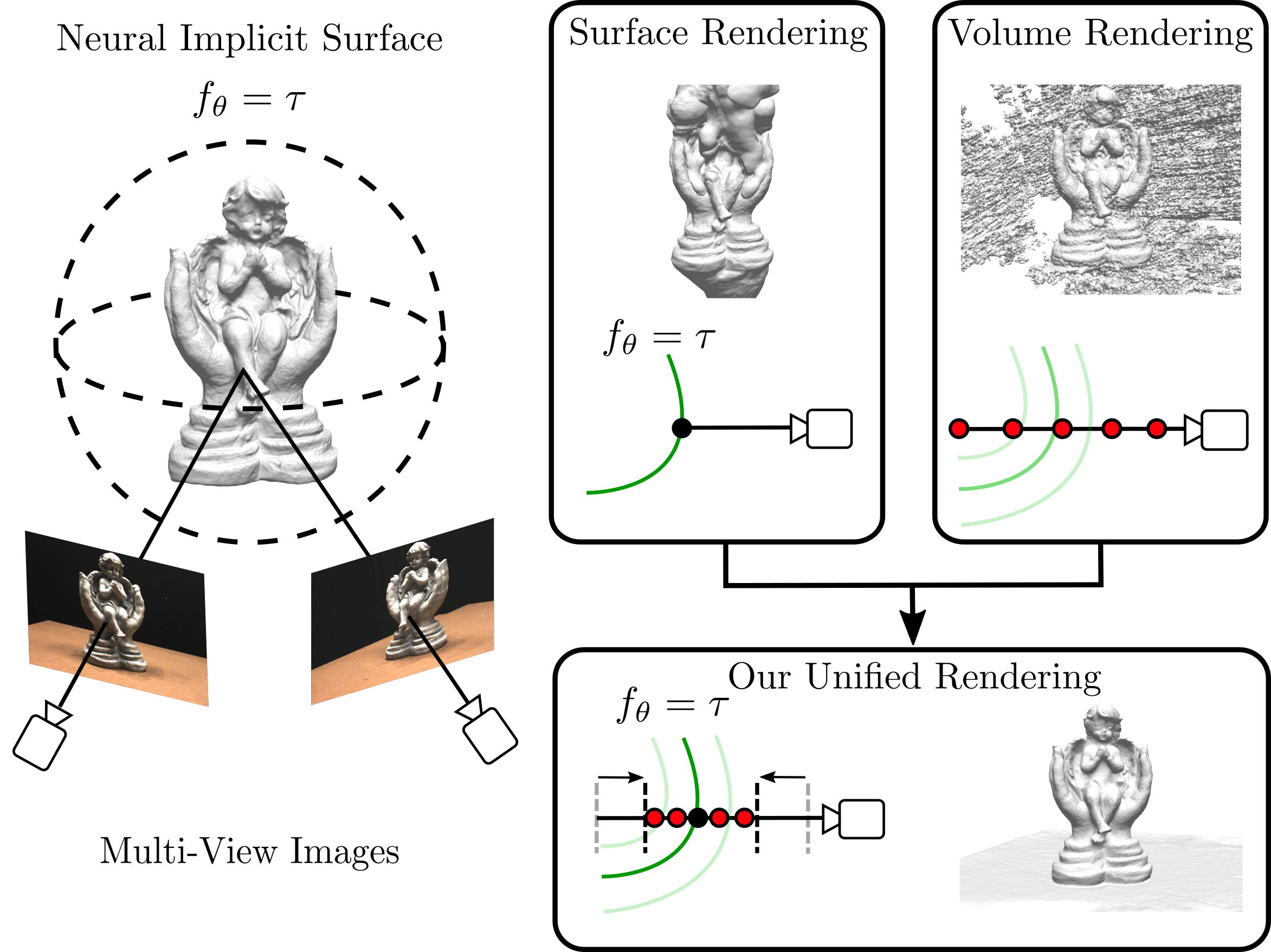
使用$\hat{C}(\mathbf{r})=\sum_{i=1}^No(\mathbf{x}_i)\prod_{j<i}\bigl(1-o(\mathbf{x}_j)\bigr)c(\mathbf{x}_i,\mathbf{d})$ 占据o来代替NeRF中的$\alpha$
将VR与SR结合起来,首先根据占据场获取表面的点$t_s$,然后在$t_s$的一个区间内均匀采样点来进行颜色场的优化(如果光线没有穿过物体,则使用分层采样)
Discussion and Conclusion
这项工作提出了UNISURF,一种统一的隐式表面和辐射场公式,用于在没有输入掩模的情况下从多视图图像中捕获高质量的隐式表面几何形状。我们相信神经隐式曲面和先进的可微分渲染程序在未来的3D重建方法中发挥关键作用。我们的统一公式显示了在比以前更一般的设置中优化隐式曲面的路径。
限制:通过设计,我们的模型仅限于表示固体,非透明表面。过度曝光和无纹理区域也是导致不准确和不光滑表面的限制因素。此外,在图像中很少可见的区域,重建的精度较低。在附录中更详细地讨论了限制。
在未来的工作中,为了从很少可见和无纹理的区域中解决歧义,先验是重建的必要条件。虽然我们在优化过程中加入了显式平滑先验,但学习捕获对象之间的规律性和不确定性的概率神经表面模型将有助于解决模糊性,从而实现更准确的重建。
AIR
神经隐式三维表示已经成为从多视图图像重建表面和合成新视图的强大范例。不幸的是,现有的方法,如DVR或IDR需要精确的过像素对象掩码Mask作为监督。
与此同时,神经辐射场已经彻底改变了新的视图合成。然而,NeRF的估计体积密度不允许精确的表面重建。
我们的关键见解是隐式表面模型和亮度场可以以统一的方式制定,使表面和体渲染使用相同的模型。这种统一的视角使新颖,更有效的采样程序和重建精确表面的能力无需输入掩模。我们在DTU、BlendedMVS和合成室内数据集上比较了我们的方法。我们的实验表明,我们在重建质量方面优于NeRF,同时在不需要掩模的情况下与IDR表现相当。
Introduction
从一组图像中捕捉3D场景的几何形状和外观是计算机视觉的基础问题之一。为了实现这一目标,基于坐标的神经模型在过去几年中已经成为三维几何和外观重建的强大工具。
最近的许多方法使用连续隐式函数参数化神经网络作为几何图形的三维表示[3,8,12,31,32,37,41,43,47,57]或外观[34,38,39,40,47,52,61]。这些神经网络三维表示在多视图图像的几何重建和新视图合成方面显示出令人印象深刻的性能。神经隐式多视图重建除了选择三维表示形式(如占用场、无符号距离场或有符号距离场)外,渲染技术是实现多视图重建的关键。虽然其中一些作品将隐式表面表示为水平集,从而渲染表面的外观[38,52,61],但其他作品通过沿着观察光线绘制样本来整合密度[22,34,49]。
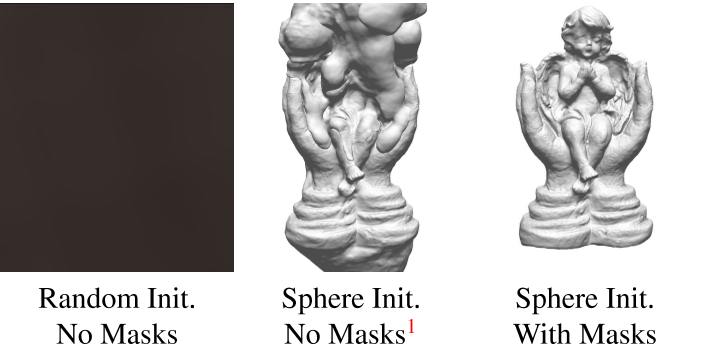
在现有的工作中,表面渲染技术在三维重建中表现出了令人印象深刻的性能[38,61]。然而,它们需要逐像素对象掩码作为输入和适当的网络初始化,因为表面渲染技术只在表面与射线相交的局部提供梯度信息。直观地说,optimizing wrt. 局部梯度可以看作是应用于初始神经表面的迭代变形过程,初始神经表面通常被初始化为一个球体。为了收敛到一个有效的表面,需要额外的约束,如掩码监督,如图2所示。
==现有工作2021由于依赖mask,因此只能用于对象级重建,而无法重建大场景==
相反,像NeRF[34]这样的体绘制方法在新视图合成方面也显示了令人印象深刻的结果,also对于更大的场景。然而,作为底层体积密度水平集提取的表面通常是非光滑的(NeRF用密度来提取零水平集表面是非光滑的),并且由于辐射场表示的灵活性而包含伪影,这在存在歧义的情况下不能充分约束 3D 几何,见图 3。

贡献:在本文中,我们提出了 UNISURF(统一UNIfied 神经Neural 隐式Implicit SUrface 和辐射场Radiance)隐式表面和辐射场的原则性统一框架,目标是从一组 RGB 图像重建实体(即不透明)对象。我们的框架结合了表面渲染的好处和体绘制的好处,从而能够从没有掩码的多视图图像重建准确的几何图形。通过恢复隐式曲面,我们能够在优化过程中逐渐降低采样区域进行体绘制。从大采样区域开始,可以在早期迭代期间捕获粗略的几何图形并解决歧义
在后面的阶段,我们抽取更接近表面的样本,提高了重建精度。我们表明,我们的方法能够在DTU MVS数据集[1]上在没有掩码监督的情况下捕获精确的几何图形,获得了与最先进的隐式神经重建方法(如IDR[61])竞争的结果,这些方法使用强掩码监督。此外,我们还在BlendedMVS数据集[60]的场景以及来自SceneNet[29]的合成室内场景上展示了我们的方法。
Related Work
- 3D Reconstruction from Multi-View Images
- 从多个图像重建三维几何结构一直是一个长期存在的计算机视觉问题[14]。在深度学习时代之前,经典的多视图立体(MVS)方法[2,4,5,7,20,20,20,48,50,51]要么关注跨视图匹配特征[4,48],要么关注用体素网格表示形状[2,5,7,20,27,42,50,54,55]。前一种方法通常有一个复杂的管道,需要额外的步骤,如融合深度信息[9,30]和网格划分[18,19],而后一种方法由于立方内存要求而限制在低分辨率。相比之下,用于3D重建的神经隐式表示不会受到离散伪影的影响,因为它们通过具有连续输出的神经网络的水平集表示表面。
- 最近基于学习的MVS方法试图取代经典MVS管道的某些部分。例如,一些作品学习匹配2D特征[15,21,26,56,62],融合深度图[11,46],或者从多视图图像中推断深度图[16,58,59]。与这些基于学习的MVS方法相反,我们的方法在优化过程中只需要弱2D监督。此外,我们的方法产生了高质量的3D几何图形,并合成了逼真的、一致的新视图
- Neural Implicit Representations
- 最近,神经隐式函数作为3D几何[3,8,12,31,32,37,41,43,47,57]和外观[22,24,34,38,39,40,47,49,52]的有效表示出现了,因为它们连续地表示3D内容,无需离散化,同时具有较小的内存占用。这些方法大多需要三维监控。然而,最近的一些工作[23,34,38,52,61]证明了直接从图像进行训练的可微分渲染[23,34,38,52,61]。我们将这些方法分为两组:表面渲染和体渲染。
- 表面渲染方法,包括DVR[38]和IDR[61],直接确定物体表面的亮度,并使用隐式梯度提供可微分的渲染公式。这允许从多视图图像优化神经隐式曲面。调节观看方向允许IDR捕捉高水平的细节,即使是非兰伯曲面的存在。然而,DVR和IDR都要求所有视图的像素精确对象掩码作为输入。相比之下,我们的方法可以在不需要掩模的情况下进行类似的重建。
- NeRF[34]和后续研究[6,28,35,36,44,45,49,53,63]通过学习沿光线的辐射场的alpha合成来使用体渲染。该方法在新视图合成上取得了令人印象深刻的效果,并且不需要掩模监督。然而,恢复的三维几何形状远不能令人满意,如图3所示。后续的一些作品(Neural Body [44] D-NeRF[45]和NeRD[6])使用NeRF的体积密度提取网格,但都没有考虑直接优化表面。与这些作品不同的是,我们的目标是捕获精确的几何形状,并提出一种可以证明接近极限表面渲染的体绘制公式
Background
从多视图图像中学习神经隐式3D表示的两个主要组成部分是3D表示和连接3D表示和2D观察的渲染技术。本节提供了关于隐式表面和体积辐射表示的相关背景,我们在本文中统一了固体(非透明)物体和场景的情况。
- Implicit Surface Models
- 占用网络[31,38]将曲面表示为二元占用分类器的决策边界,并通过神经网络参数化
- $o_\theta(\mathbf{x}):\mathbb{R}^3\to[0,1]$
- 其中$x∈ \mathbb{R}^3$为三维点,θ为模型参数。曲面定义为占据概率为二分之一的所有3D点的集合$\mathcal{S}=\{\mathbf{x}_s|o_\theta(\mathbf{x}_s)=0.5\}.$
- 为了将颜色与表面上的每个3D点xs相关联,可以将颜色场$c_\theta(\mathbf{x}_s)$与占用场$o_{\theta}(\mathbf{x}).$联合学习,从而预测特定像素/射线r的颜色:$\hat{C}(\mathbf{r})=c_\theta(\mathbf{x}_s)$
- 其中$x_s$是通过沿着射线r进行根查找来检索的,具体参见[38]。占用场$o_θ$和颜色场$c_θ$的参数 θ由[24,38,61]中描述的通过梯度下降优化重建损失来确定。
- 虽然表面渲染允许准确地估计几何形状和外观,但现有的方法强烈依赖于物体掩模的监督,因为表面渲染方法只能推断与表面相交的射线。
- $o_\theta(\mathbf{x}):\mathbb{R}^3\to[0,1]$
- 占用网络[31,38]将曲面表示为二元占用分类器的决策边界,并通过神经网络参数化
- Volumetric Radiance Models
- 与隐式表面模型相比,NeRF[34]将场景表示为彩色体积密度,并通过alpha混合将辐射沿光线进行整合[25,34]。更具体地说,NeRF使用神经网络将3D位置$x∈R^3$和观看方向$d∈R^3$映射到体积密度$σ_{θ}(x)∈R^{+}$和颜色值$c_{θ}(x, d)∈R^{3}$
- 对观察方向的调节允许建模与视图相关的效果,如镜面反射[34,40],并在违反朗伯假设的情况下提高重建质量[61]。让我们表示相机中心的位置。给定沿射线$\mathbf{r}=\mathbf{o}+t\mathbf{d},$的N个样本$\{\mathbf{x}_i\}$, NeRF使用数值正交近似像素/射线r的颜色:
- $\hat{C}(\mathbf{r}) =\sum_{i=1}^NT_i\left(1-\exp\left(-\sigma_\theta(\mathbf{x}_i)\delta_i\right)\right)c_\theta(\mathbf{x}_i,\mathbf{d}) ,T_{i} =\exp\left(-\sum_{j<i}\sigma_\theta(\mathbf{x}_j)\delta_j\right)$
- 其中$T_{i}$为沿射线的累积透过率,$\delta_i=|\mathbf{x}_{i+1}-\mathbf{x}_i|$为相邻样品之间的距离。由于Eq.(3)是可微的,因此密度场$σ_θ$和颜色场$c_θ$的参数θ可以通过优化重构损失来估计。详见[34]。
- 虽然由于NeRF的体积亮度表示,它不需要对象掩模进行训练,但从体积密度中提取场景几何图形需要仔细调整密度阈值,并由于密度场中存在的模糊性而导致伪影,如图3所示。
Method
与也适用于非固体场景(如雾、烟)的NeRF相反,我们将焦点限制在可以用3D表面和依赖于视图的表面颜色表示的固体物体上。我们的方法利用了这两者,体积辐射表示能力来学习粗糙的场景结构,而不需要掩模监督,以及表面渲染,作为一个感应偏差,通过一组精确的3D表面来表示对象,从而实现精确的重建。
Unifying Surface and Volume Rendering
$\hat{C}(\mathbf{r})=\sum_{i=1}^N\alpha_i(\mathbf{x}_i)\prod_{j<i}\bigl(1-\alpha_j(\mathbf{x}_j)\bigr)c(\mathbf{x}_i,\mathbf{d})$
将$\alpha$值替换为占据值o
α值:$\alpha_i(\mathbf{x})=1-\exp\left(-\sigma(\mathbf{x})\delta_i\right).$。假设物体为实体,则α为离散占用指标变量$o\in\{0,1\}$,其值为自由空间0 = 0,占用空间0 = 1:
$\hat{C}(\mathbf{r})=\sum_{i=1}^No(\mathbf{x}_i)\prod_{j<i}\bigl(1-o(\mathbf{x}_j)\bigr)c(\mathbf{x}_i,\mathbf{d})$
我们将此表达式识别为固体物体的成像模型[55],其中项$\begin{aligned}o(\mathbf{x}_i)\prod_{j<i}\left(1-o(\mathbf{x}_j)\right)\end{aligned}$对于沿光线 r的第一个被占用的样本$x_i$求值为1,对于所有其他样本求值为0。$\prod_{j<i}(1-o(\mathbf{x}_j))$是可见性指标,如果在样本$x_i$之前不存在j<i的被占用样本xj,则可见性指标为1。因此,C(r)取沿射线r的第一个被占用样本的颜色$C(x_i, d)$。
为了统一隐式表面和体积亮度模型,我们直接用连续占用场$o_{θ}(1)$来参数化o,而不是预测体积密度σ。按照[61],我们在曲面法向量n和几何网络的特征向量h上对颜色场$c_{θ}$进行条件调整,这在经验上诱导了一个有用的偏差,这也在[61]中观察到对于隐式曲面的情况。重要的是,我们统一的配方允许体积和表面渲染
$x_s$是沿着射线r得到的坐标,$n_s,h_s$分别是$x_s$出的法向量和几何特征。请注意,x依赖于占位场$o_θ$,但为了清晰起见,我们在这里去掉了这个依赖关系。
这种统一公式的优点是,它既可以直接在表面上渲染,也可以在整个体块上渲染,从而在优化过程中逐渐消除歧义。正如我们的实验所证明的那样,将两者结合起来对于在没有mask监督的情况下获得准确的重建确实至关重要。能够通过根查找快速恢复表面S使更有效的体渲染,先后聚焦和细化对象表面,我们将在4.3节中描述。此外,表面渲染可以实现更快的新视图合成,如图5所示。
Loss Function
$\mathcal{L}=\mathcal{L}_{rec}+\lambda\mathcal{L}_{reg}$
- reconstruction loss $\mathcal{L}_{rec}=\sum_{\mathbf{r}\in\mathcal{R}}|\hat{C}_{v}(\mathbf{r})-C(\mathbf{r})|_{1}$
- Surface regularization $\mathcal{L}_{reg}=\sum_{\mathbf{x}_s\in\mathcal{S}}|\mathbf{n}(\mathbf{x}_s)-\mathbf{n}(\mathbf{x}_s+\boldsymbol{\epsilon})|_2$
其中,R为minibatch中所有像素/射线的集合,S为对应表面点的集合,C(R)为像素/射线R的观测颜色,ε为一个小的随机均匀三维扰动。
x处的法线$\mathbf{n}(\mathbf{x}_s)=\frac{\nabla_{\mathbf{x}_s}o_\theta(\mathbf{x}_s)}{|\nabla_{\mathbf{x}_s}o_\theta(\mathbf{x}_s)|_2}$可以用双反向传播来计算
Optimization
隐式曲面模型的关键假设[38,61]是,只有与曲面第一个交点处的区域对渲染方程有贡献。然而,这个假设在早期迭代中是不正确的,因为在早期迭代中曲面没有很好地定义。因此,现有的方法[38,61]需要强有力的mask监管。相反,在随后的迭代中,当评估Eq.(7)中的体绘制方程时,关于近似曲面的知识对于绘制信息样本是有价值的。因此,我们在体绘制过程中使用了一个采样间隔单调递减的训练计划来绘制样本,如图4所示
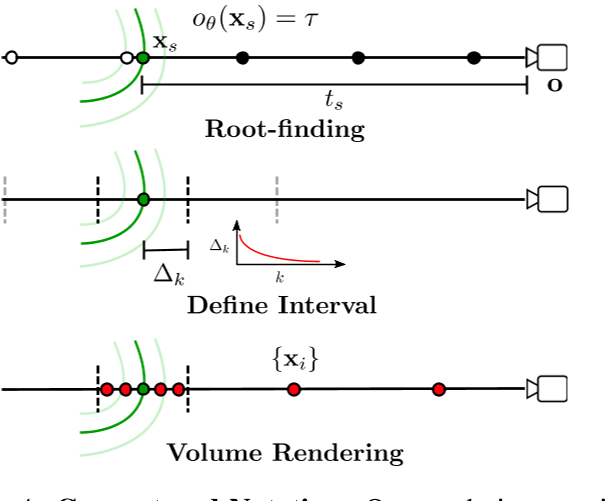
首先,我们在占用场oθ中寻找表面$x_s$(绿色)。其次,我们在表面周围定义一个间隔,以采样点$\{x_i\}$(红色)进行体渲染。
换句话说,在早期的迭代中,样本{$x_i$}覆盖了整个优化体积,有效地引导了使用体绘制的重建过程。在以后的迭代中,样本{$x_i$}在估计的表面附近被拉近。由于可以通过寻根直接从占用场oθ估计表面[38],这就消除了像NeRF那样需要分层两阶段采样的需要。我们的实验表明,这个过程对于估计精确的几何图形特别有效,同时它允许在早期迭代中解决歧义。
More formally, let $\mathbf{x}_s=\mathbf{o}+t_s\mathbf{d}.$ We obtain samples $\mathbf{x}_i=\mathbf{o}+t_i\mathbf{d}.$ by drawing N depth values $t_i$ using stratified sampling within the interval $[ts − ∆, ts + ∆]$centered at $t_s$:
$t_i\sim\mathcal{U}\left[t_s+\left(\frac{2i-2}N-1\right)\Delta,t_s+\left(\frac{2i}N-1\right)\Delta\right]$
在训练过程中,我们从较大的间隔∆max开始,并逐渐减少∆,以便使用以下衰减时间表对表面进行更准确的采样和优化$\Delta_k=\max(\Delta_{\max}\exp(-k\beta),\Delta_{\min})$
其中k为迭代次数,β为超参数。事实上,可以证明,当∆→0和n→∞时,体绘制(7)确实接近曲面绘制(8):$C_v (r)→C_s(r)$。补充材料中提供了这个极限的正式证明。
正如我们的实验所证明的那样,(14)中的衰减调度对于捕获详细的几何图形至关重要,因为它将训练开始时的大型和不确定体积的体绘制与训练结束时的表面渲染结合起来。为了减少自由空间伪影,我们将这些样本与相机和表面之间随机采样的点结合起来。对于没有曲面相交的光线,我们对整个光线进行分层采样。
Implementation Details
- Architecture与Yariv等人[61]类似,我们使用带有Softplus激活函数的8层MLP,占用场$o_θ$的隐藏维数为256。我们初始化网络,使得决策边界是一个球体[13]。相比之下,辐射场$c_θ$被参数化为4层的ReLU MLP。我们使用傅里叶特征[34]在k倍频阶对3D位置x和观看方向d进行编码。根据经验,我们发现3D位置x的k = 6和观看方向d的k = 4效果最好。
- 占用场MLP:layer = 8 , neurons = 256 , activation = softplus, init_sphere
- 颜色场MLP:layer = 4 , neurons = 256 , activation = ReLU
- 编码采用频率编码,位置x的k=6,方向d的k=4
- Optimization在所有的实验中,我们的模型适合单一场景的多视图图像。在模型参数优化过程中,我们首先对一个视图进行随机采样,然后根据相机的本征和外征对该视图进行M像素/射线R的采样。接下来,我们渲染所有射线来计算Eq.(9)中的损失函数。对于寻根,我们使用256个均匀采样点并应用割线方法,共8步[31]。对于我们的渲染过程,我们在区间内使用N = 64个查询点,在相机和区间下界之间的空闲空间中使用32个查询点。区间衰减参数为β = 1.5e−5,∆min = 0.05,∆max = 1.0。我们使用Adam,学习率为0.0001,每次迭代优化M = 1024像素,在200k和400k迭代后进行两个衰减步骤。总的来说,我们训练我们的模型进行了45万次迭代。
- Inference我们的方法允许推断三维形状以及合成新的视图图像。对于合成图像,我们可以用两种不同的方式渲染我们的表现,我们可以使用体渲染或表面渲染。在图5中,我们展示了两种渲染方法导致相似的结果。然而,我们观察到表面渲染比体渲染快。
- 为了提取网格,我们采用了[31]中的多分辨率等值面提取(MISE)算法。我们使用$64^{3}$作为初始分辨率,分3步对网格进行上采样,没有基于梯度的细化。

Experimental Evaluation
我们在广泛使用的DTU MVS数据集[17]上,对我们的方法与现有方法(IDR [61], NeRF [34], COLMAP[48])进行了定性和定量比较。
其次,我们展示了来自blendedmvs dataset[60]的样本和来自the SceneNet dataset[29]的场景合成渲染的定性比较。
第三,我们分析了消融研究中的渲染程序和损失函数。在补充中,我们提供了LLFF数据集[33]上的结果。