| Title | Volume Rendering of Neural Implicit Surfaces |
|---|---|
| Author | Lior Yariv, Jiatao Gu, Yoni Kasten, Yaron Lipman |
| Conf/Jour | NeurIPS 2021 Oral presentation |
| Year | 2021 |
| Project | Volume Rendering of Neural Implicit Surfaces (lioryariv.github.io) |
| Paper | Volume Rendering of Neural Implicit Surfaces (readpaper.com) |
将 NeRF 的密度场替换为 SDF,提出了详细的采样算法

Abstract
神经体绘制最近越来越流行,因为它成功地从一组稀疏的输入图像合成了一个场景的新视图。到目前为止,通过神经体绘制技术学习的几何图形是使用通用密度函数建模的。此外,使用密度函数的任意水平集提取几何形状本身,导致有噪声,通常是低保真度的重建。本文的目标是改进神经体绘制中的几何表示和重建。我们通过将体积密度建模为几何形状的函数来实现这一点。这与之前将几何形状建模为体积密度函数的工作形成对比。更详细地说,我们将体积密度函数定义为应用于有符号距离函数(SDF)表示的拉普拉斯累积分布函数(CDF)。这种简单的密度表示有三个好处:
(i)它为在神经体绘制过程中学习到的几何图形提供了有用的归纳偏置inductive bias;
(ii)它有利于不透明度近似误差的限制,从而导致观察光线的精确采样。准确的采样是重要的,以提供几何和辐射的精确耦合;并且
(iii)它允许在体积渲染中有效地无监督地解除形状和外观的纠缠。将这种新的密度表示应用于具有挑战性的场景多视图数据集,产生高质量的几何重建,优于相关基线。此外,由于两者的解除纠缠,在场景之间切换形状和外观是可能的。
Introduction
体渲染定义 & 最新的神经体渲染优点+缺点
体渲染[21]是通过所谓的体渲染积分在光场中渲染体积密度的一组技术。最近有研究表明,将密度和光场都表示为神经网络,可以通过仅从稀疏的输入图像集中学习,从而实现对新视图的出色预测。这种神经体绘制方法在[24]中提出,并由其后续研究[38,3]发展,以一种可微的方式将积分近似为 alpha-composition,允许同时从输入图像中学习。虽然这种耦合确实可以很好地概括新的观看方向,但密度部分在忠实地预测场景的实际几何形状方面并不成功,通常会产生嘈杂的、低保真的几何近似。
本文 VolSDF 方法主要思想+优点
我们提出 VolSDF 为神经体渲染中的密度设计一个不同的模型,从而在保持视图合成质量的同时更好地近似场景的几何形状。关键思想是将密度表示为到场景表面的带符号距离的函数,参见图 1。这样的密度函数有几个好处。首先,它保证存在一个定义良好的表面来产生密度。这为解纠缠密度和光场提供了有用的归纳偏置,从而提供了更精确的几何近似。其次,我们表明这种密度公式允许沿每条射线的不透明度的近似误差的边界。该边界用于对观察光线进行采样,以便在体渲染积分中提供密度和光场的忠实耦合。例如,如果没有这样的界限,沿射线(像素颜色)计算的亮度可能会遗漏或扩展表面部分,导致不正确的亮度近似。
并行研究方向——基于表面渲染方法的缺点
一个密切相关的研究,通常被称为神经隐式曲面[25,42,15],一直专注于使用神经网络隐式地表示场景的几何形状,使表面渲染过程可微分。这些方法的主要缺点是它们需要遮罩将物体与背景分开。此外,学习直接渲染表面往往会由于优化问题而产生多余的部分,这可以通过体绘制来避免。从某种意义上说,我们的工作结合了两个世界的优点:体积渲染和神经隐式表面。
具体实施+更好的结果
我们通过重建 DTU[13]和 BlendedMVS[41]数据集的表面来证明 VolSDF 的有效性。与 NeRF[24]和 NeRF++[44]相比,VolSDF 产生了更精确的表面重建,与 IDR[42]相比,VolSDF 产生了更精确的重建,同时避免了使用对象掩模。此外,我们展示了用我们的方法解除纠缠的结果,即切换不同场景的密度和光场,这在基于 nerf 的模型中被证明是失败的。
Related work
Neural Scene Representation & Rendering
传统上,三维场景建模采用隐式函数[27,12,5]。由于多层感知器(MLP)的表达能力强且占用内存少,最近的研究主要集中在基于 MLP 的模型隐式函数上,包括场景(几何和外观)表示[10,23,22,26,28,33,40,31,39]和自由视图渲染[37,18,34,29,19,24,17,44,38,3]。特别是,NeRF[24]开辟了一条研究路线(见[7]概述),将神经隐式函数与体绘制结合起来,以实现逼真的渲染结果。然而,从预测密度中寻找合适的阈值提取曲面并非易事,并且恢复的几何形状远不能令人满意。此外,沿着光线对点进行采样以呈现像素是使用从另一个网络近似的不透明度函数完成的,而不保证正确的近似。
Multi-view 3D Reconstruction
在过去的几十年里,基于图像的三维表面重建(多视点立体)一直是一个长期存在的问题。经典的多视图立体方法通常是基于深度的[2,35,9,8]或基于体素的[6,4,36]。
例如,在 COLMAP [35]一种典型的基于深度的方法中,提取图像特征并在不同视图之间进行匹配以估计深度。然后对预测的深度图进行融合,得到密集的点云。为了获得曲面,采用了额外的网格划分步骤,例如泊松曲面重构[14]。然而,这些具有复杂管道的方法可能会在每个阶段积累错误,并且通常会导致不完整的 3D 模型,特别是对于非朗伯曲面,因为它们不能处理视图相关的颜色。相反,尽管它通过直接在一个体积中建模对象来生成完整的模型,但由于内存消耗高,基于体素的方法的分辨率很低。
最近,基于神经的方法如 DVR[25]、IDR[42]、NLR[15]也被提出用于从多视图图像中重建场景几何。然而,由于梯度难以传播,这些方法需要精确的对象掩码和适当的权值初始化。
与我们在这里的工作相独立,[30]UNISURF 也使用隐式表面表示合并到体绘制中。特别是,他们用占用网络代替了局部透明函数[22]。这允许在损失中添加表面平滑项,从而提高所得表面的质量。与他们的方法不同,我们使用带符号距离表示,用 Eikonal 损失进行正则化[42,11],没有任何显式平滑项。此外,我们表明,使用带符号距离的选择允许不透明度近似误差的边界,促进对密度 suggested family 的体积渲染积分的近似。
Method
在本节中,我们将介绍一种新的体积密度参数化,定义为转换的有符号距离函数。然后我们将展示这个定义如何促进体渲染过程。特别是,我们推导了不透明度近似的误差范围,并因此设计了一个近似体渲染积分的采样程序。
Density as transformed SDF
将密度转换为与 SDF 有关的函数:$\sigma(\boldsymbol{x})=\alpha\Psi_\beta\left(-d_\Omega(\boldsymbol{x})\right),$
- α、β > 0 为可学习参数
- $\Psi_{\boldsymbol{\beta}}$ 为零均值β标度拉普拉斯分布的累积分布函数(CDF):$\Psi_\beta(s)=\begin{cases}\frac{1}{2}\exp\left(\frac{s}{\beta}\right)&\text{if }s\leq0\\1-\frac{1}{2}\exp\left(-\frac{s}{\beta}\right)&\text{if }s>0\end{cases}$
- SDF 值定义:$1_\Omega(\boldsymbol{x})=\begin{cases}1&\mathrm{if~}\boldsymbol{x}\in\Omega\\0&\mathrm{if~}\boldsymbol{x}\notin\Omega\end{cases},\quad\text{and} d_\Omega(\boldsymbol{x})=(-1)^{\mathbf{1}_\Omega(\boldsymbol{x})}\min_{\boldsymbol{y}\in\mathcal{M}}\left|x-\boldsymbol{y}\right|_2,$ $\mathcal{M}=\partial\Omega$ 为边界表面
这样定义可以看出:当 $\beta$ 接近0时,所有点的密度 $\sigma$ 趋近于 $\alpha 1_\Omega(\boldsymbol{x})$
从直观上看,密度σ模拟了一个均匀的固体,密度α恒定,在固体边界附近平滑减小,其中平滑量由β控制。
Volume rendering of σ
$I(\boldsymbol{c},\boldsymbol{v})=\int_0^\infty L(\boldsymbol{x}(t),\boldsymbol{n}(t),\boldsymbol{v})\tau(t)dt,$ 体渲染过程即沿着一条光线的期望像素
在 NeRF 提出的体渲染公式中,有两个重要的量:
- The volume’s opacity O , or its transperancy T
- transperancy T 表示光粒子成功穿过
[c, x(t)]段而没有碰撞的概率 $T(t)=\exp\left(-\int_0^t\sigma(\boldsymbol{x}(s))ds\right),$ - opacity O 是补概率 $O(t)=1-T(t).$
- 这种情况可以将 O 看作 CDF ,则 PDF $\tau(t)=\frac{dO}{dt}(t)=\sigma(\boldsymbol{x}(t))T(t)$
- transperancy T 表示光粒子成功穿过
- the light field L. 与点坐标,法向量以及观察方向有关
- 增加光场对法线方向的依赖性是因为普通材料的 brdf 通常是相对于表面法线进行编码的,这有助于在表面渲染中进行解纠缠
体渲染公式离散形式:$I(c,v)\approx\hat{I}_{\mathcal{S}}(c,v)=\sum_{i=1}^{m-1}\hat{\tau}_iL_i,$
- S 为光线上的采样点集
- $\hat{\tau}_i\approx\tau(s_i)\Delta s$ 使用采样点处的密度 + 区间长度来近似
采样很重要,PDF 集中在物体边界附近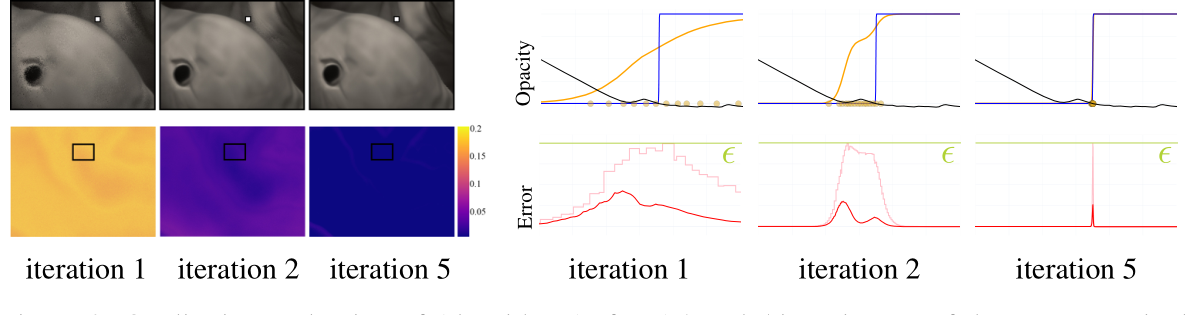
Bound on the opacity approximation error
目的:通过控制一些超参数,使得透明的近似误差存在一个上界
给定一系列采样点,根据某个 $t\in(0,M],\text{assume }t\in[t_k,t_{k+1}],$ 得到:
$\int_0^t\sigma(x(s))ds=\widehat{R}(t)+E(t),\quad\mathrm{~where~}\widehat{R}(t)=\sum_{i=1}^{k-1}\delta_i\sigma_i+(t-t_k)\sigma_k$ ,其中 E(t)指近似的误差
则相应的不透明度函数的近似: $\widehat{O}(t)=1-\exp\left(-\widehat{R}(t)\right).$ ,目的是得到 [0,M] 上近似于 $\widehat{O}\approx O.$ 的 uniform bound
采样策略:给定一个 $\epsilon$
- 引理 1:足够密集的采样点,保证误差上界 $B_{T,\epsilon} < \epsilon$
- 引理 2:固定的采样点个数,如果要想得到的误差上界< $\epsilon$,则需要满足 $\beta\geq\frac{\alpha M^2}{4(n-1)\log(1+\epsilon)}$ , M 为采样 t 的上界
Sampling algorithm
Survey: nerf + surface enhancements - Jianfei Guo (longtimenohack.com)
- 初始化采样:均匀采 $n=128$ 个点;然后根据引理 2 选取一个 $\beta_+$ (大于当前 $\beta)$ 保证 $\epsilon$ 被满足,迭代最大5次上采样点,直到采样足够充足使得网络现在的 $\beta$ 就能够满足上界 $<\epsilon;$ (如果5次上采样以后还是不行,就选取最后一次送代的那个 $\beta_+$,而不是现在网络自己的 $\beta$
- 为了能够减小 $\beta_+$,同时保证 $\epsilon$ 被满足,上采样添加 $n$ 个采样点
- 每个区间采的点的个数和该区间当前 error bound 值成比例
- 由均值定理,区间 $(\beta,\beta_+)$ 中一定存在一个 $\beta_{*}$ 刚好让 error bound 等于 $\epsilon$
- 所以用二分法(最大10个迭代)来找这样的一个 $\beta_{*}$ 来更新 $\beta_{+}$
- 为了能够减小 $\beta_+$,同时保证 $\epsilon$ 被满足,上采样添加 $n$ 个采样点
- 用最后的上采样点和选取的 $\beta$ 来估计一个 $\hat{O}$ 序列
- 用估计出来的 $\hat{O}$ 序列来 inverse CDF 采样一组 ($m=64$) fresh new 的点来算 $\hat{O}$

Training
描述网络结构及如何训练
可学习参数:$\theta=(\varphi,\psi,\beta).$
损失函数:$\mathcal{L}(\theta)=\mathcal{L}_{\mathrm{RGB}}(\theta)+\lambda\mathcal{L}_{\mathrm{SDF}}(\varphi)$
- $\mathcal{L}_{\mathrm{RGB}}(\theta)=\mathbb{E}_p\left|I_p-\hat{I}_{\mathcal{S}}(c_p,v_p)\right|_1$
- $\mathcal{L}_{\mathrm{SDF}}(\varphi)=\mathbb{E}_{\boldsymbol{y}}\left(\left|\nabla d(\boldsymbol{y})\right|_2-1\right)^2$
Experiments
我们在具有挑战性的多视图三维表面重建任务中评估了我们的方法。我们使用两个数据集:DTU[13]和 BlendedMVS[41],它们都包含从多个视图捕获的具有不同材料的真实物体。在第 4.1 节中,我们展示了 VolSDF 的定性和定量三维表面重建结果,与相关基线进行了比较。在 4.2 节中,我们证明,与 NeRF[24]相比,我们的模型能够成功地解开捕获物体的几何形状和外观。
Multi-view 3D reconstruction
描述如何在某一数据集上与其他方法进行对比
数据集包含什么?数据集选取哪几个物体?其他方法如何设定参数?定性定量结果(图表)?所提出方法在哪方面更好?
也可以拎出来单独与 SOTA 比较一下
Disentanglement of geometry and appearance
两个版本的 NeRF 在这些场景中都不能产生正确的解纠缠,而 VolSDF 成功地切换了两个物体的材料。我们将此归因于使用方程 2 中的密度注入的特定 inductive 偏置。
Conclusions
我们介绍了 VolSDF,一个隐式神经表面的体绘制框架。我们将体积密度表示为学习到的表面几何的带符号距离函数的转换版本。这个看似简单的定义提供了一个有用的归纳偏置,允许几何(即密度)和光场的解纠缠,并且比以前的神经体渲染技术改进了几何近似。此外,它允许约束不透明度近似误差opacity approximation error,导致高保真采样的体积渲染积分。
未来有几个有趣的工作方向。
- 首先,尽管在实践中工作得很好,但我们没有证明采样算法的正确性。我们相信提供这样的证明,或者找到一个有证明的算法版本将是一个有用的贡献。总的来说,我们相信在体绘制中使用边界可以改善学习和解纠缠,并推动该领域向前发展。
- 其次,我们目前的公式假设密度均匀;将其扩展到更一般的密度模型是一个有趣的未来工作方向。
- 第三,既然可以以无监督的方式学习高质量的几何形状,那么直接从图像集合中学习动态几何形状和形状空间将是很有趣的。
- 最后,尽管我们没有看到我们的工作对社会产生直接的负面影响,但我们确实注意到,从图像中精确重建几何形状可能被用于恶意目的。