重建动漫角色模型
CharacterGen: Efficient 3D Character Generation from Single Images
革命性成果:Sparc3D: Sparse Representation and Construction for High-Resolution 3D Shapes Modeling
目前的生产方式(手办/模型)
建立数字化3D模型(mesh)—>模型拆件
- 软件:Blender, ZBrush
3D打印(小批量,未来趋势)
使用3D打印工艺,进行模型拆件要除了便于组装外,还要有一定厚度(3D打印的模型必须要有足够的厚度),可以融合使用一些其他的组装件如铜柱等,拆件完后,在3D打印机软件中做支撑,然后进行打印(光固化树脂)
整体流程:
建模—>拆件—>(做支撑)—>3D打印—>打磨—>组装—>上色(涂装)
- 建模师根据2D图像进行建模(需要大量经验) ==> 多视图三维重建,且根据2D虚拟图像进行重建才有意义,如stable diffusion等文生图AI生成出来的图像(可以做到多视图),或者画师手工绘制的图像(单视图较为方便)。需要保证做出来的模型具有一定的稳定性,不能一碰就倒,要找好重心
- 拆件也需要一定的经验,哪里做凹陷,哪里连接用铜柱等等问题需要考虑
- 做支撑可以防止零件被悬空打印
- 3D打印有很多种方式FDM常见成本低、SLA成本高但精度高、SLS、SLM。未来趋势全彩3D打印机:2023年5款最佳全彩3D打印机
展望:
- 使用全彩3D打印机一体化地打印模型,省去了拆件、组装、上色等步骤,通过改进还可以省去做支撑(或者自动做支撑)
- 使用三维重建算法可以更高效地获取三维模型,三维重建算法的最高形态是可以根据物体几张图片甚至一张图片,重建出高质量的模型。图片来源可以是画师手绘的一张图、随便拍的真实物体照片、网站上的各种物体图片等等
赛纳三维 J402PLUS SLA 立体光固化打印机
SLA/DLP/LCD 3D 打印支撑添加全解
钢模+注塑(大批量)
使用钢模+注塑的话,拆件
整体流程:
建模—>拆件—>开模(做钢模)—>批量注塑—>筛选—>打磨—>上色(手工+喷涂)—>分件分类+组装—>除尘+打包
Theory
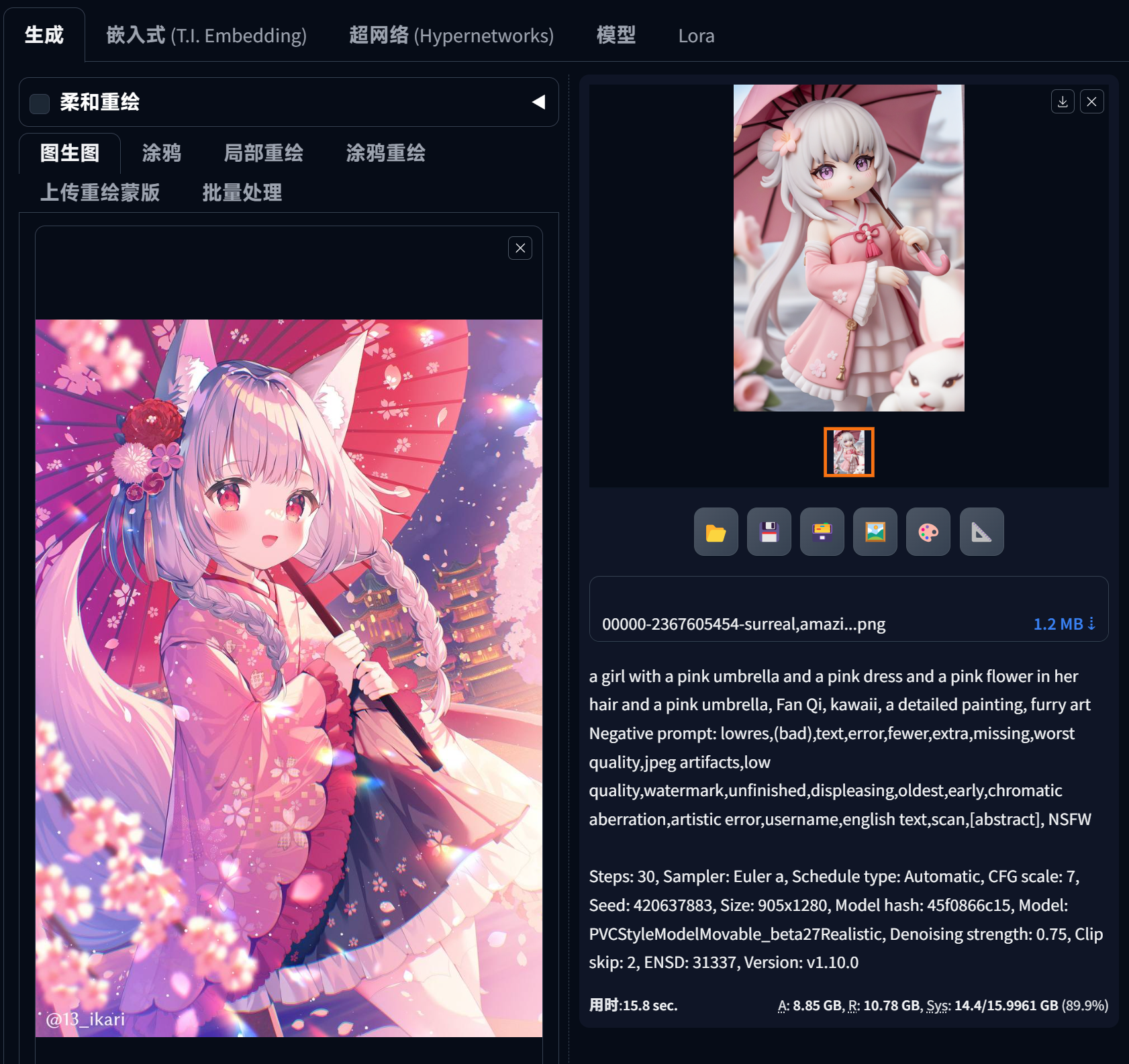
手办图像生成
[PVC Style Model]Movable figure model Pony - Pony1.60 | Stable Diffusion Checkpoint | Civitai Stable Diffusion PVC model

选择PVC,外挂VAE选择None
- Prompt:
- (score_9, score_8_up, score_7_up), source anime, figure
- surreal,amazing quality,masterpiece,best quality,awesome,inspiring,cinematic composition,soft shadows,Film grain,shallow depth of field,highly detailed,high budget,cinemascope,epic,color graded cinematic,atmospheric lighting,natural,figure,natural lighting,exqusite visual effect,delicate details
- Negative:
- engrish text, low quality, worst quality, score_4,score_3,score_2,score_1,ugly,bad feet, bad hands
- lowres,(bad),text,error,fewer,extra,missing,worst quality,jpeg artifacts,low quality,watermark,unfinished,displeasing,oldest,early,chromatic aberration,artistic error,username,english text,scan,[abstract],
1 | 1.更倾向于PVC的起始标签(Starting tags that lean more towards PVC): |
ControlNet:
- Unit0 Canny, Pixel Perfect,Allow Preview,Canny,预处理器选canny,My prompt is more important
- Unit1 tilecolorfix, Pixel Perfect,Allow Preview,tilecolorfix,预处理器选tilecolorfix,My prompt is more important
难点:
- 现有的图生图模型无法根据手绘图片合理的(保留原始风格)生成手办(PVC)风格图片
- 必须要有针对Full Body的强控制
背景移除
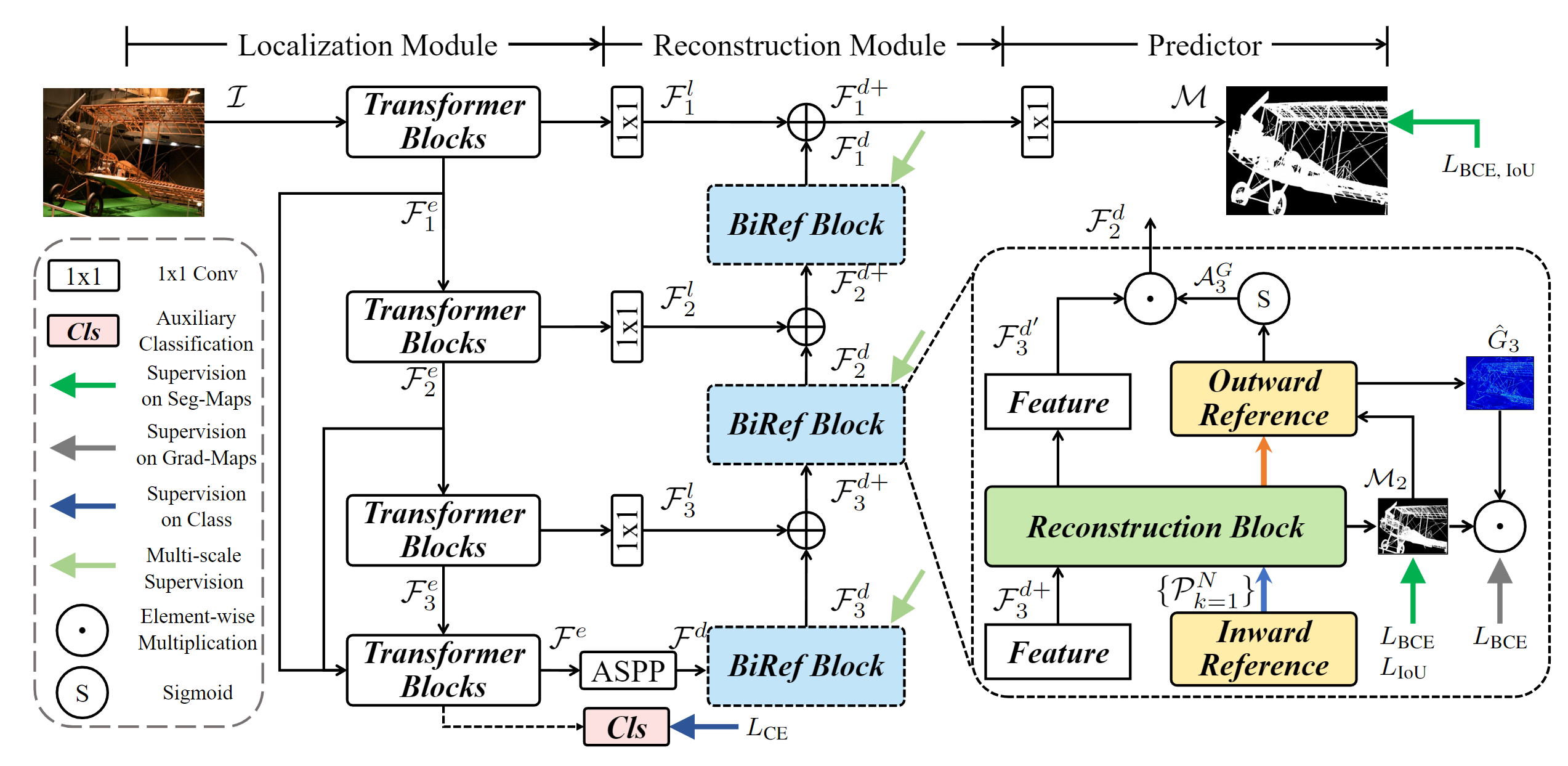
Bilateral Reference for High-Resolution Dichotomous Image Segmentation | PDF
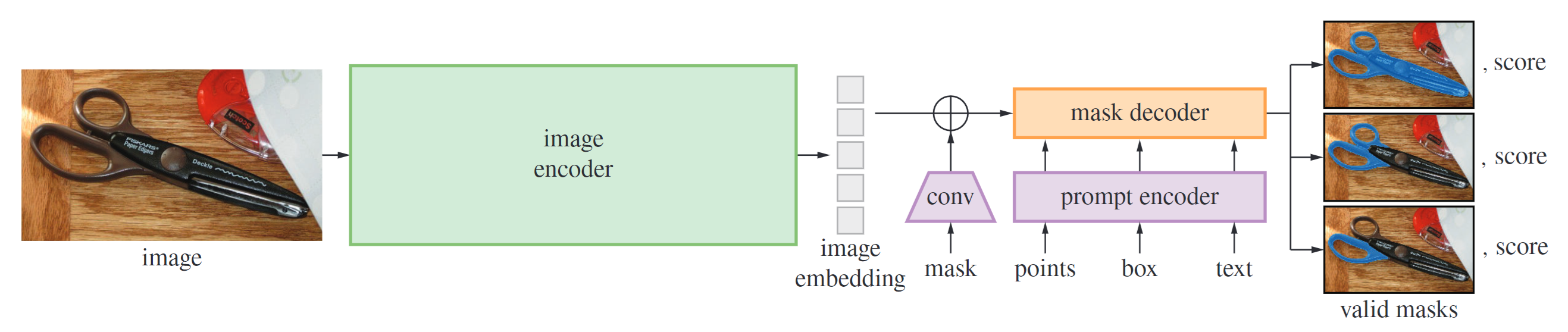
(SAM) facebookresearch/segment-anything: The repository provides code for running inference with the SegmentAnything Model
(SAM 2) facebookresearch/segment-anything-2: The repository provides code for running inference with the Meta Segment Anything Model 2
额外先验估计
Normal Image
Stable-X/StableNormal: StableNormal: Reducing Diffusion Variance for Stable and Sharp Normal
Depth Image
Fine-Tuning Image-Conditional Diffusion Models is Easier than You Think扩散模型
一致性多视图生成
与训练的视频生成模型+位姿(微调)生成多视图图像
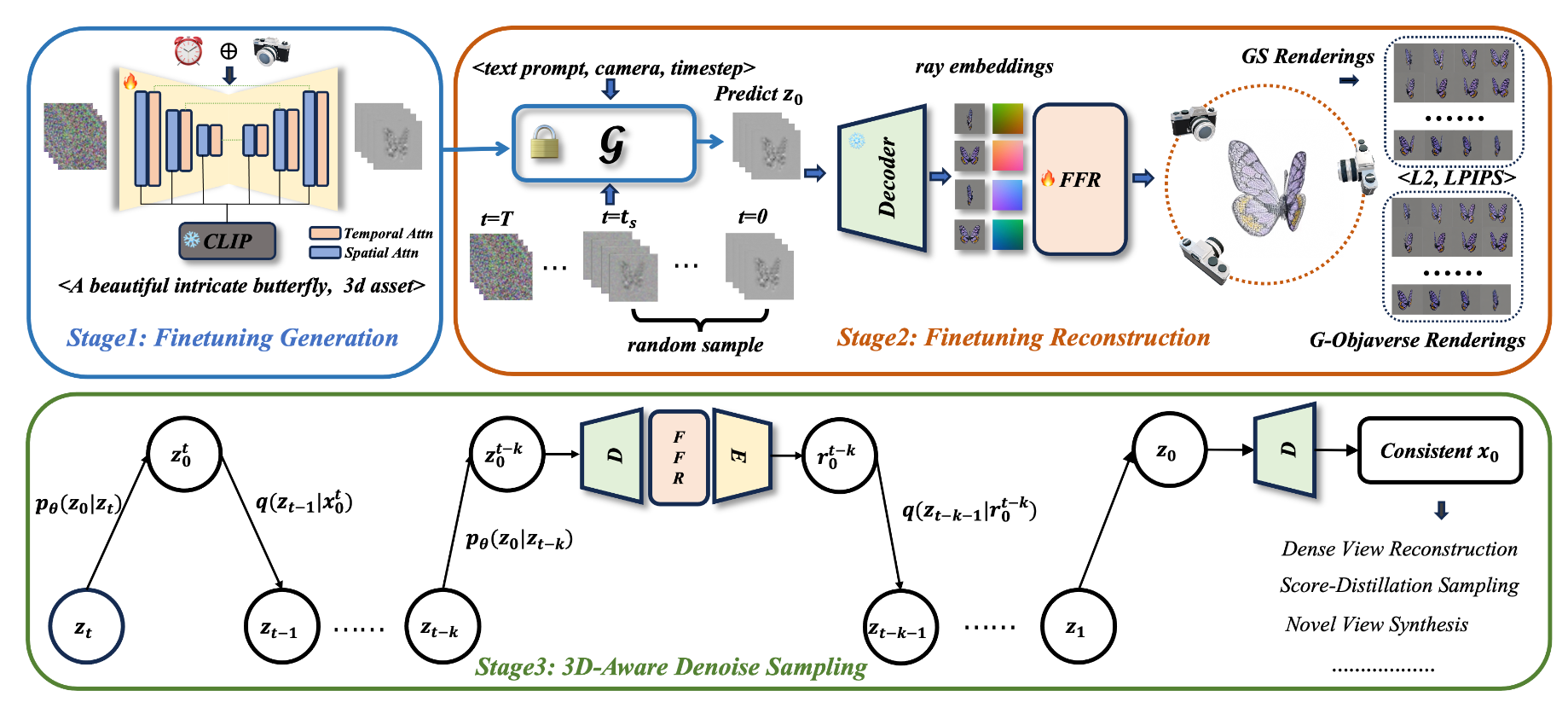
它可以在单个消费级 GPU 上同时生成 100 多个一致的目标视图,以任何相机姿势的任意数量的参考视图为条件。
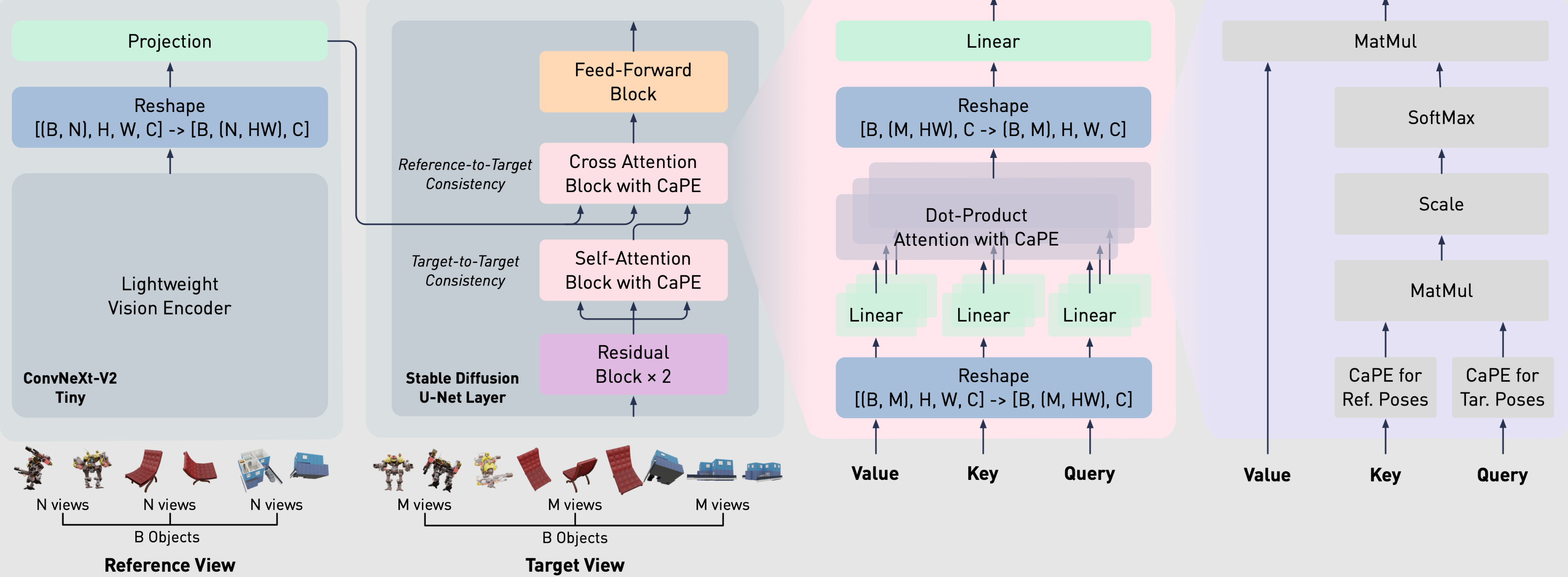
Cycle3D: High-quality and Consistent Image-to-3D Generation via Generation-Reconstruction Cycle
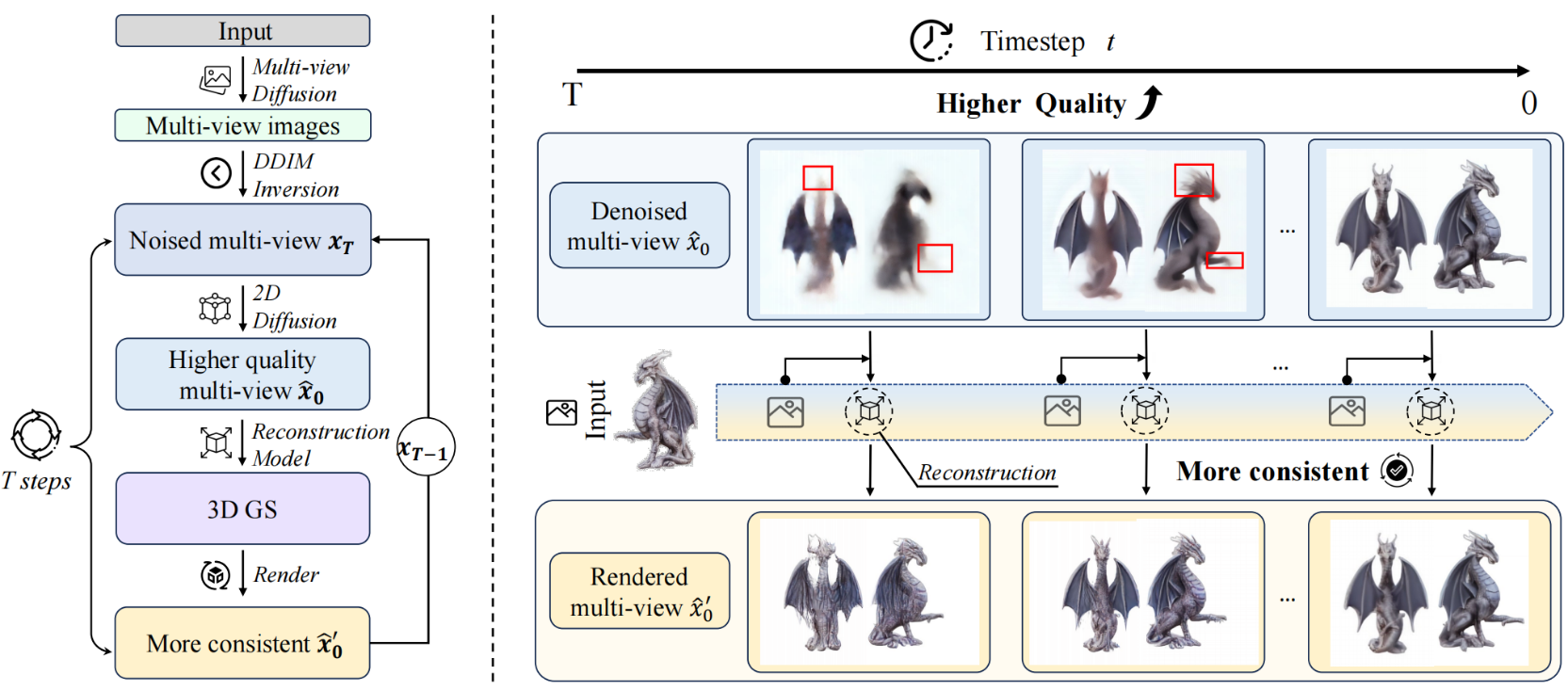
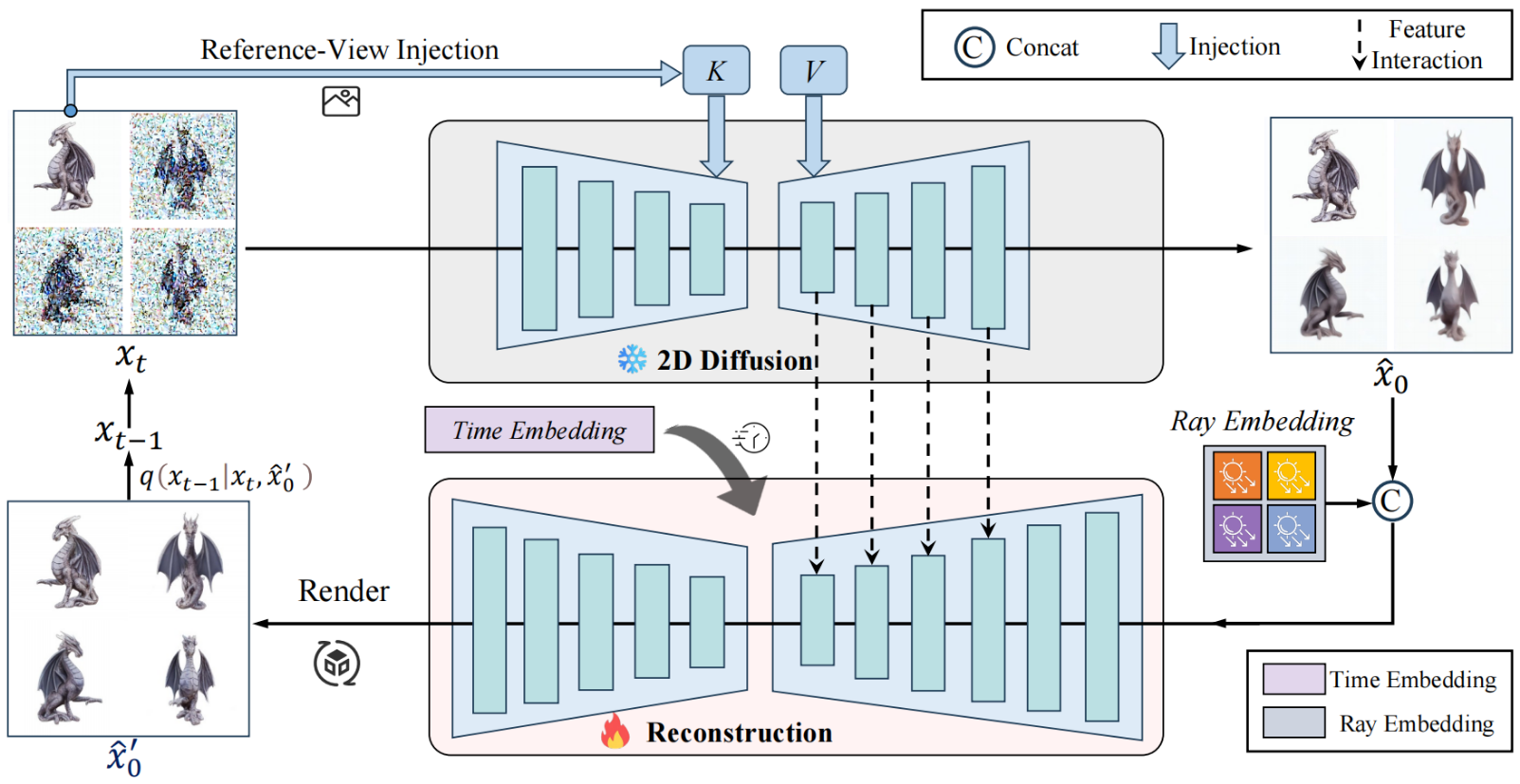
多视图三维重建
NeRF-based 的 NeuS 系列
3DGS-based 的 显示高斯体优化
Related Work
some github repo:
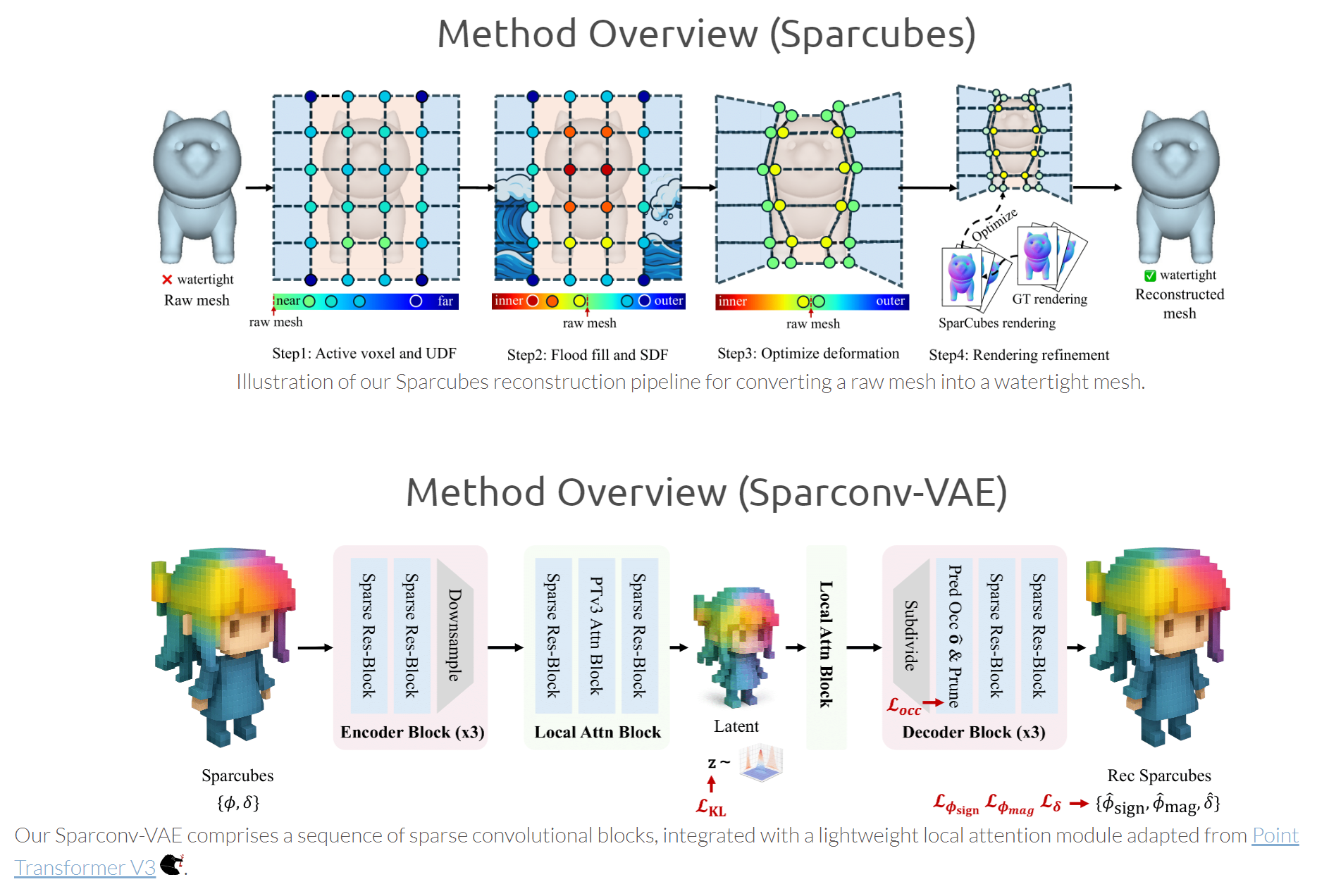
Sparc3D
Sparc3D: Sparse Representation and Construction for High-Resolution 3D Shapes Modeling
效果非常厉害(细节丰富),一些小瑕疵:这里发一发我遇到的问题吧 · Issue #5 · lizhihao6/Sparc3D
- 人物面部崩坏


Dataset

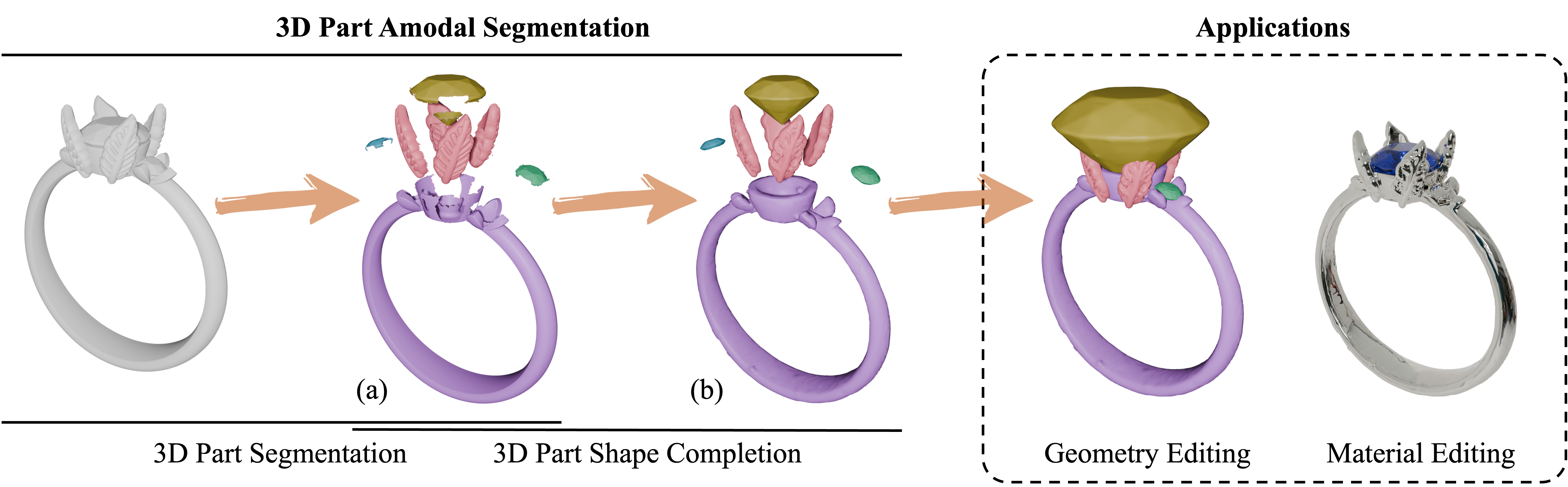
HoloPart
3D模型拆件+分别补全
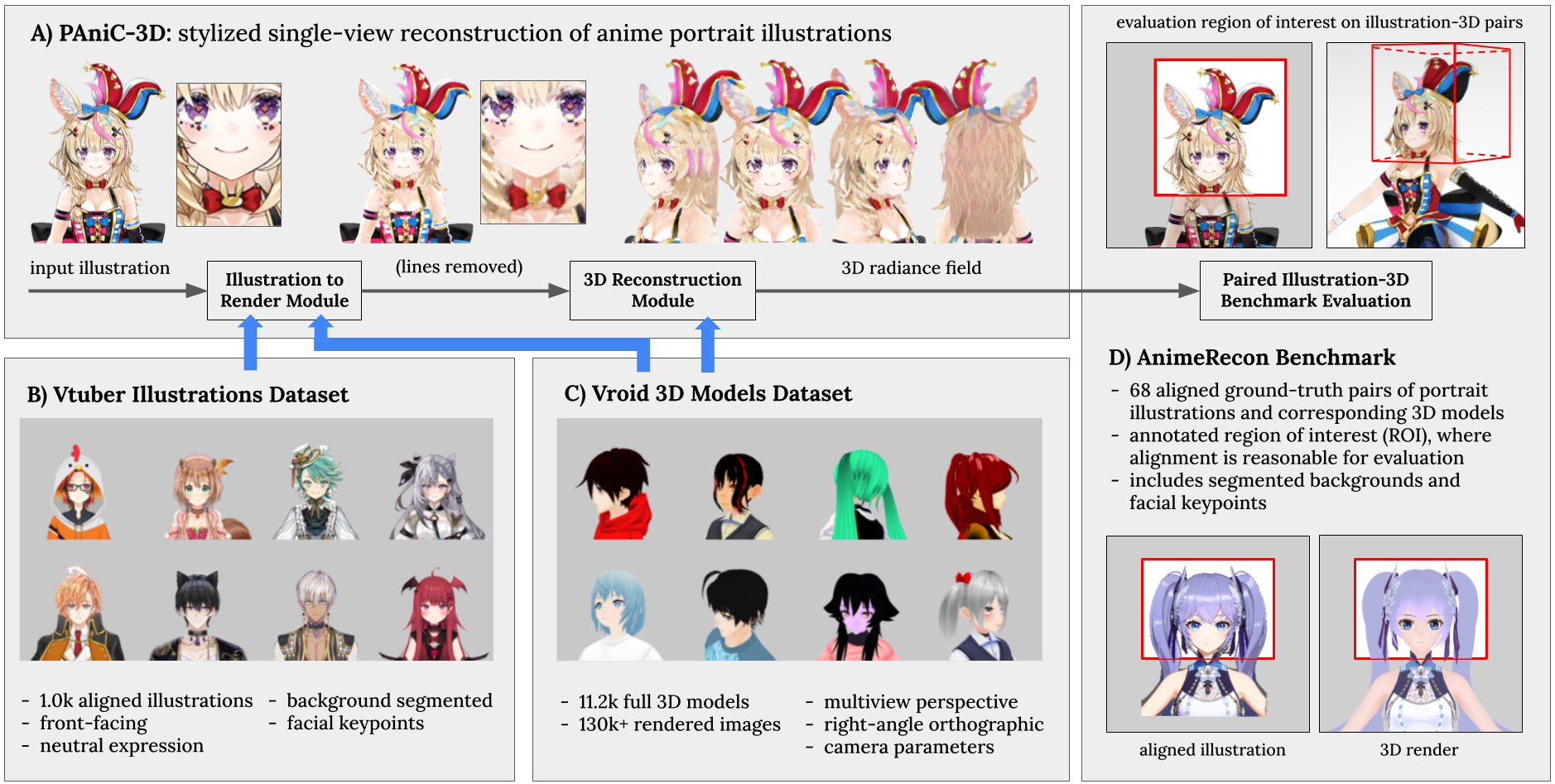
PAniC-3D
用去除线条后的2D image进行建模,得到3D radiance field
NOVA-3D
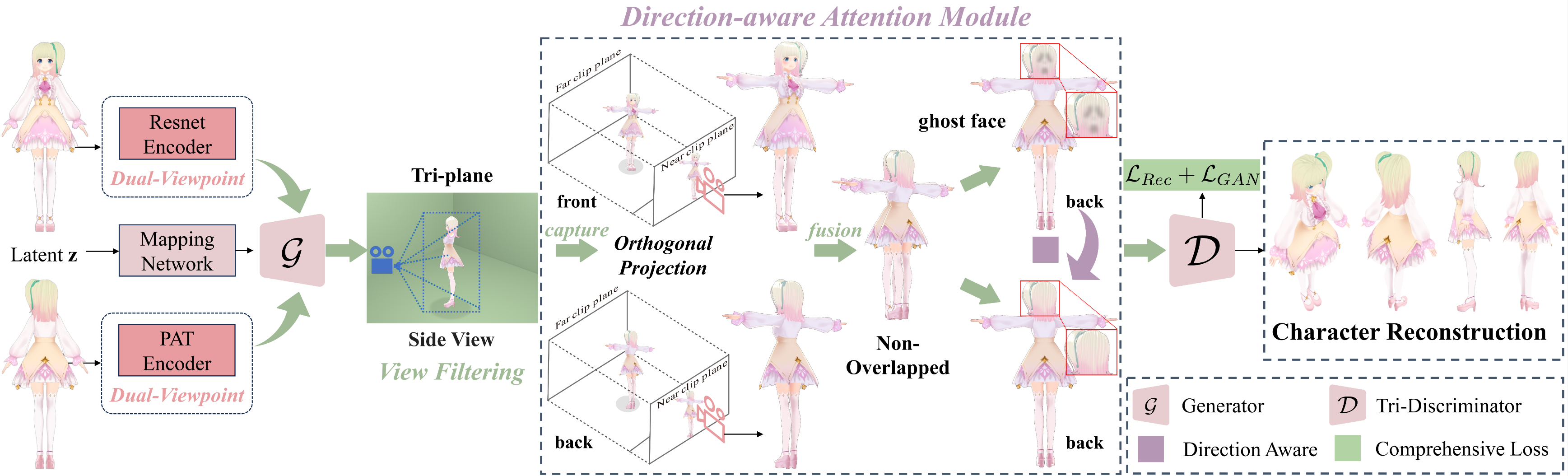
NOVA-3D: Non-overlapped Views for 3D Anime Character Reconstruction
GAN网络,从Non-overlapped Views(Sparse-view)中重建模型
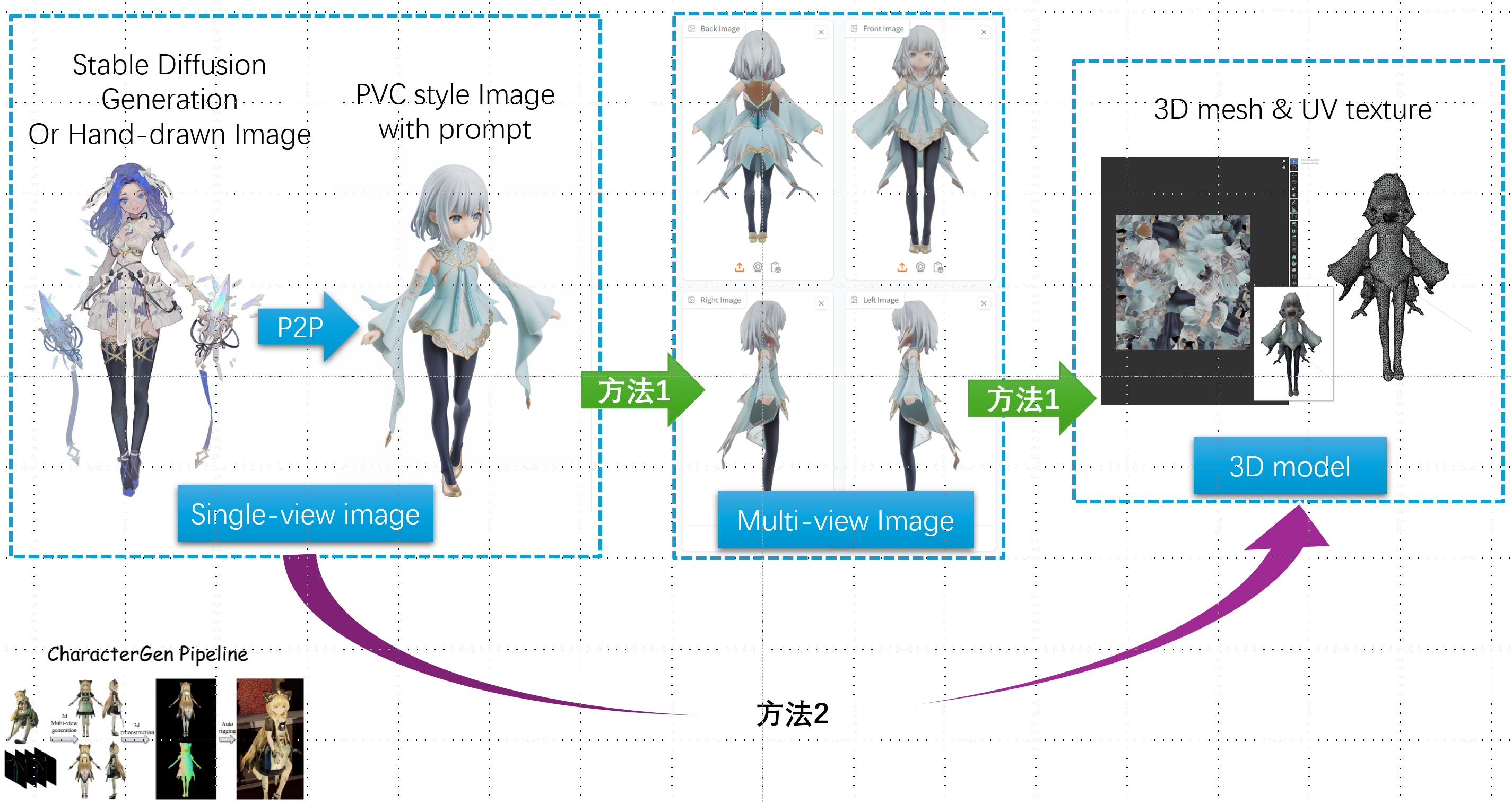
CharacterGen
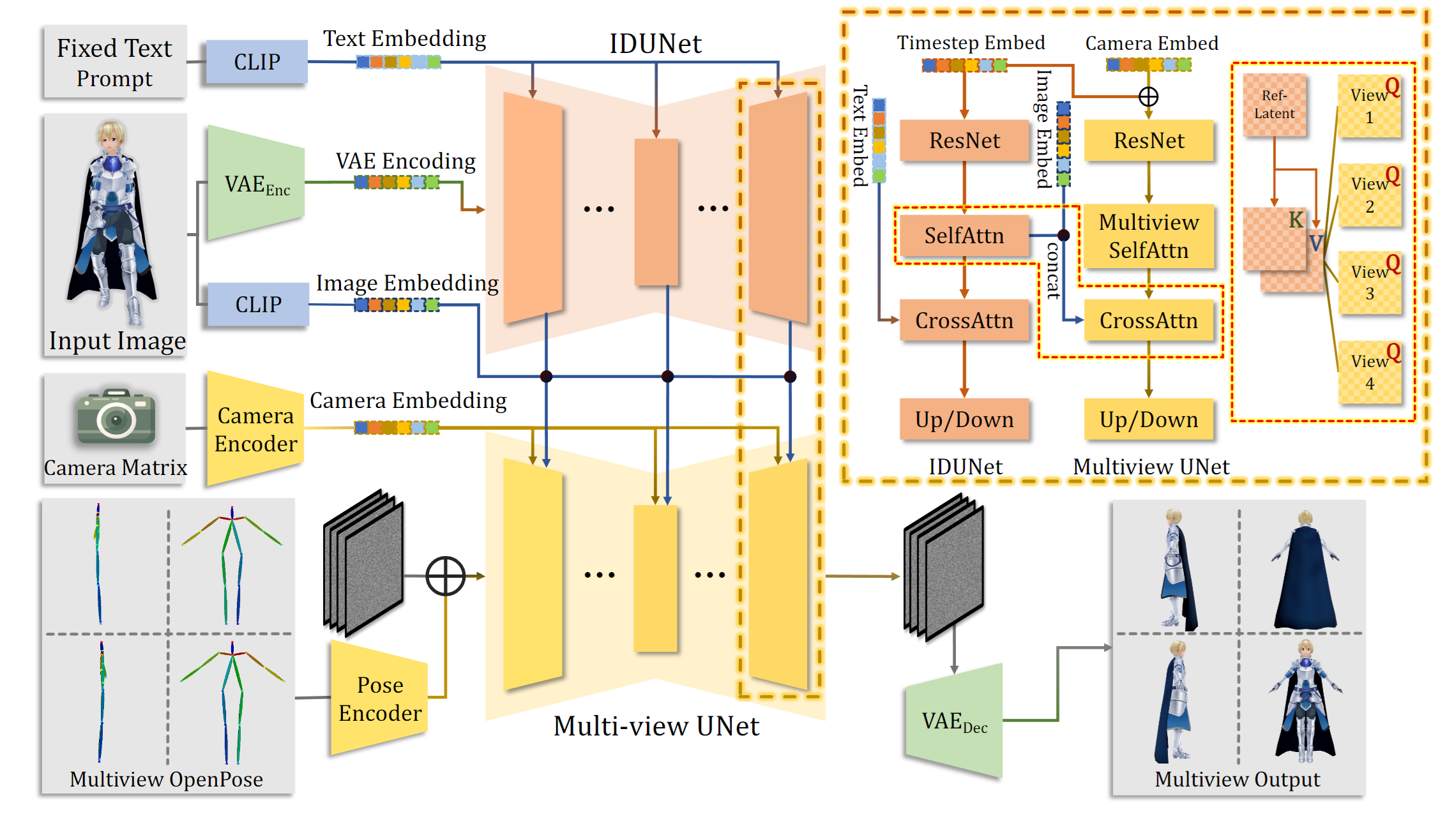
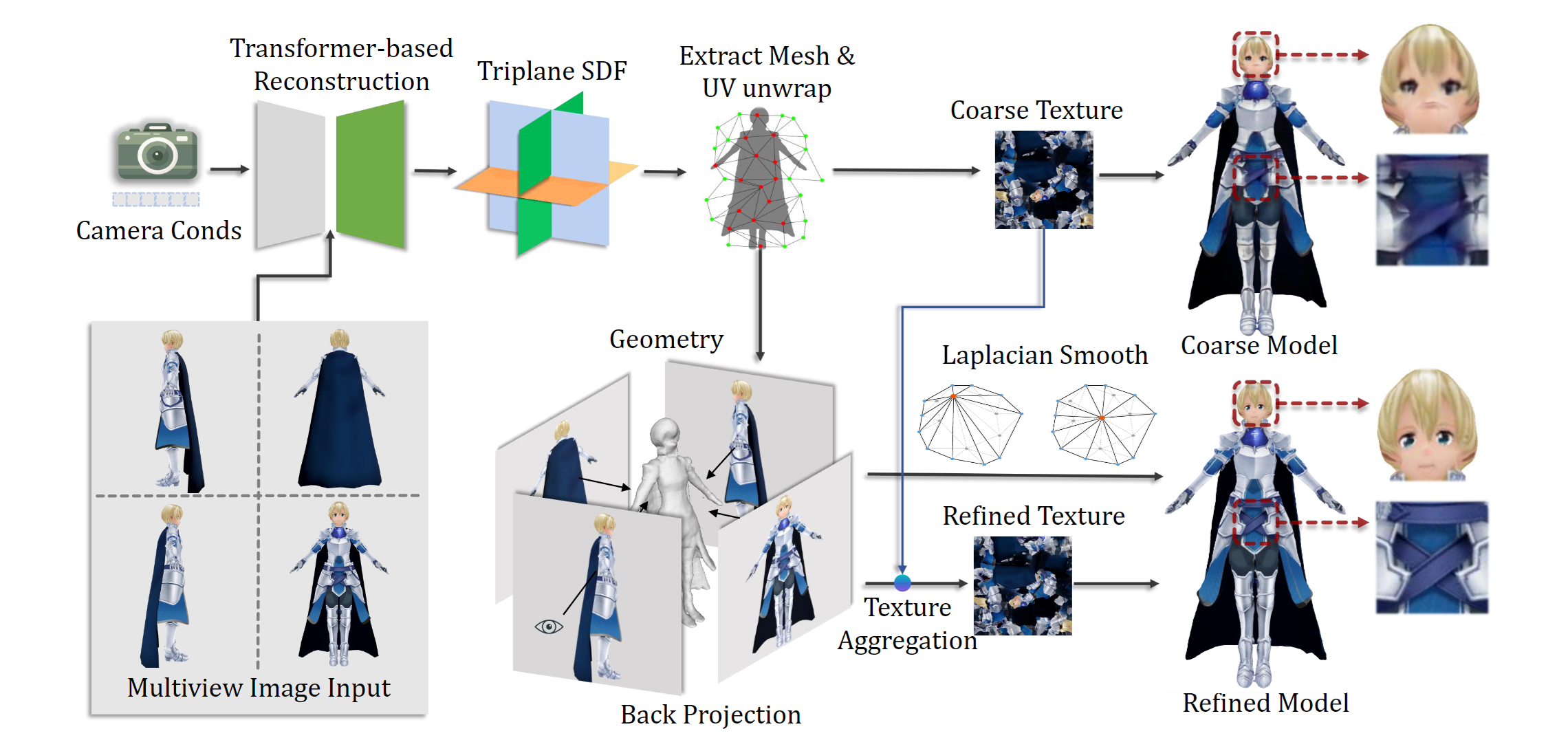
CharacterGen: Efficient 3D Character Generation from Single Images
- 多视图图像生成,由于特殊姿势的一致性多视图很难,本文提出了将输入的图像转换到canonical space中
- 三维重建:基于NeRF和Transformer参考了LRM: Large Reconstruction Model for Single Image to 3D
- 在Objaverse dataset上pre-train,然后再本文数据集Anime3D上Fine-tune,为了引入更多的人体先验
- 为了得到跟好的模型,使用 Triplane SDF 替换密度场
- 网络提取和UV map获取,参考了Deep Marching Tetrahedra: a Hybrid Representation for High-Resolution 3D Shape Synthesis,但是DMTet的UV展开过程中会损失外观信息。此外,UV的分辨率比直接渲染的分辨率大,多个texels可能投影到相同的像素上,为了解决这一问题,本文将四个视图投影到UV map上(通过depth test消除occluded texels没理解)
- 单纯的叠加还不行(会导致角色身体轮廓出现噪声texels),本文使用相机方向向量与normal texture map作内积,内积大于-0.2的texels抛弃掉
- 对于overlapping的texels,选择back投影后RGB最接近coarse texture的值
- 最后使用Poisson Blending将projected texels与原始texels混合,以减少seams
- 使用了Modular Primitives for High-Performance Differentiable Rendering | PDF NvDiffRast渲染器进行高效光栅化
texels(纹理元素,纹素)
CoNR
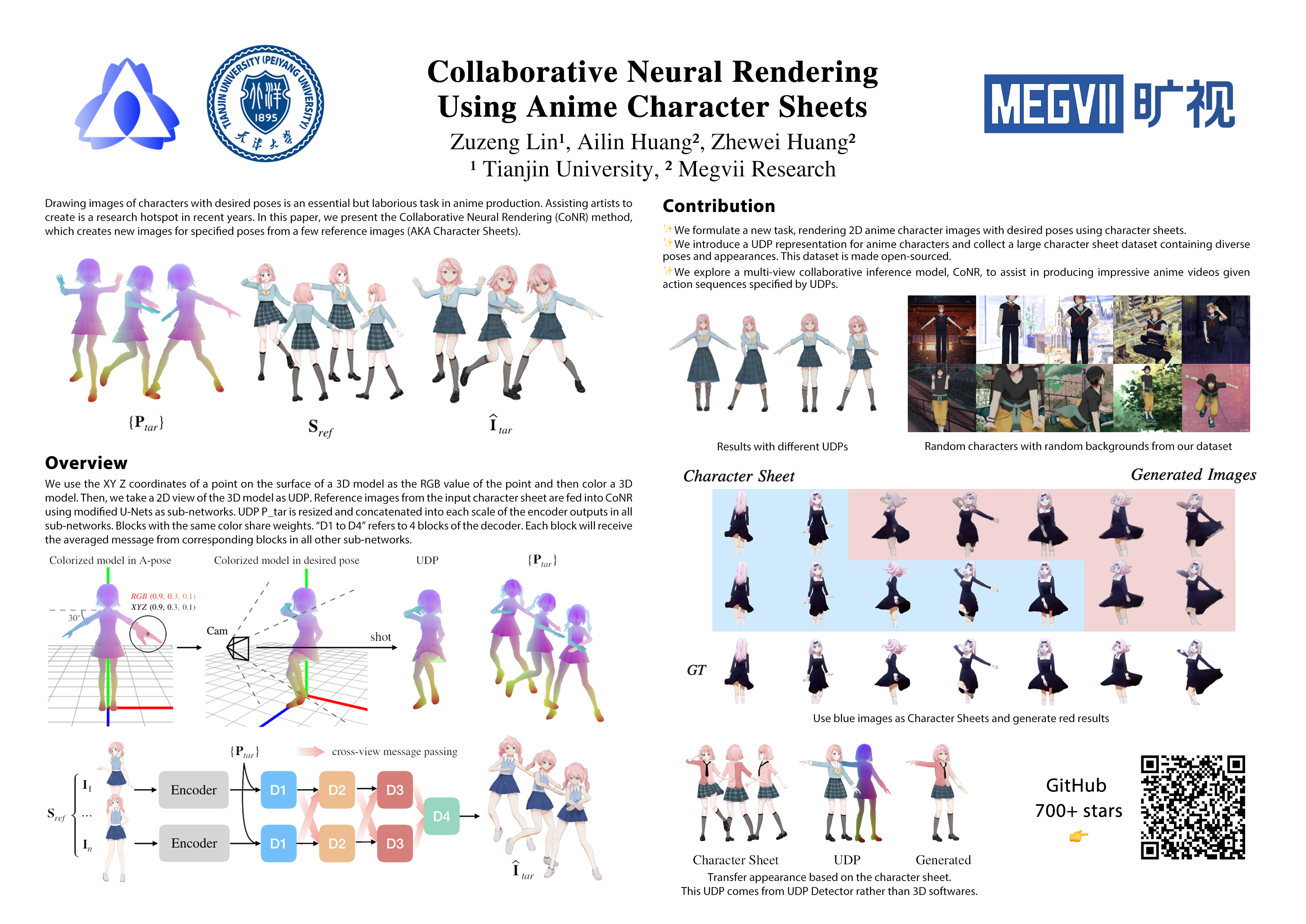
CoNR:二次元视频生成AI背后的故事 - 知乎 不算Reconstruction,因为最终目标不是模型,而是用模型得到的新视图图像
Collaborative Neural Rendering using Anime Character Sheets (CoNR)
- 网络1是UDP Detector,相当于给一张手绘图,可以粗略估计3D模型 (UDP检测器后接泊松表面重建算法,可以得到一个粗略灰模)。
- 这样静态的“单张”3D灰模可以变成一个运动的“序列”。(比如,可以通过现有的自动化绑定技术(RigNet或基于模板的方法)或者其他网上的半自动绑定工具(比如Adobe Mixamo)得到一个可操作的模型,然后通过现有的基于物理的仿真技术或基于视觉的动作捕捉(如OpenPose,Posenet等)来套用各种真人视频中动作等等。)
- 网络2是CoNR,相当于从手绘人设图和3D模型上进行“转描”
特色是可以处理张数较少的手绘的二次元人物(不像3D扫描、Nerf那样需要转台和上百个视角的图像),并且输出的结果是人物在A-Pose下的灰模
Toon3D
动漫中的环境场景,动漫中的手绘图像没有3D一致性,本文致力解决这一问题
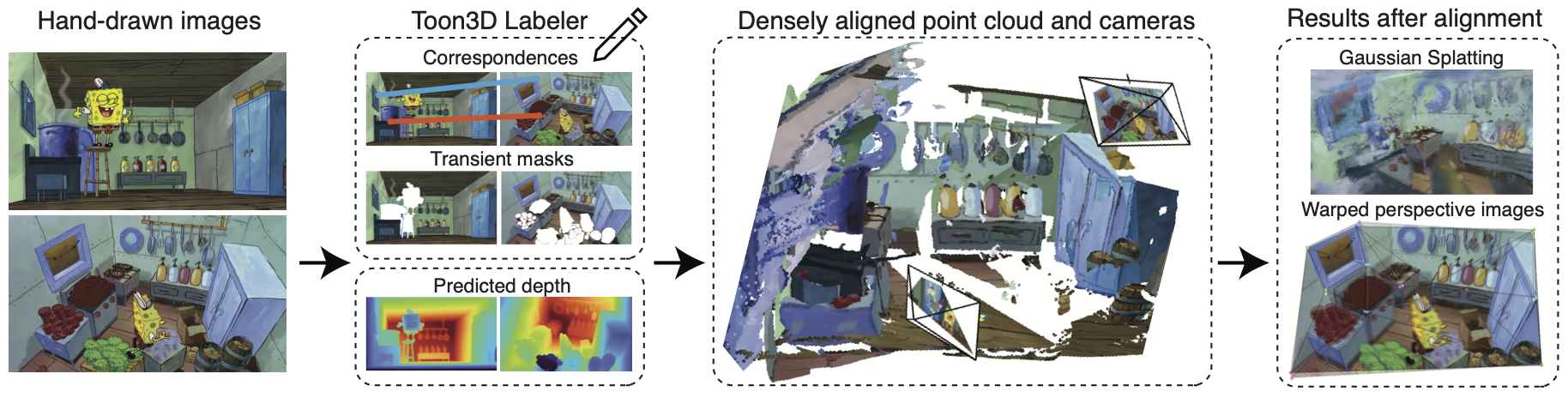
数据集生成
- Marigold 进行深度估计
- SAM 进行mask获取
- 自制的Toon3D Labeler进行
Sketch-A-Shape
从草图中生成3D shape (across voxel, implicit, and CAD representations and synthesize consistent 3D shapes)
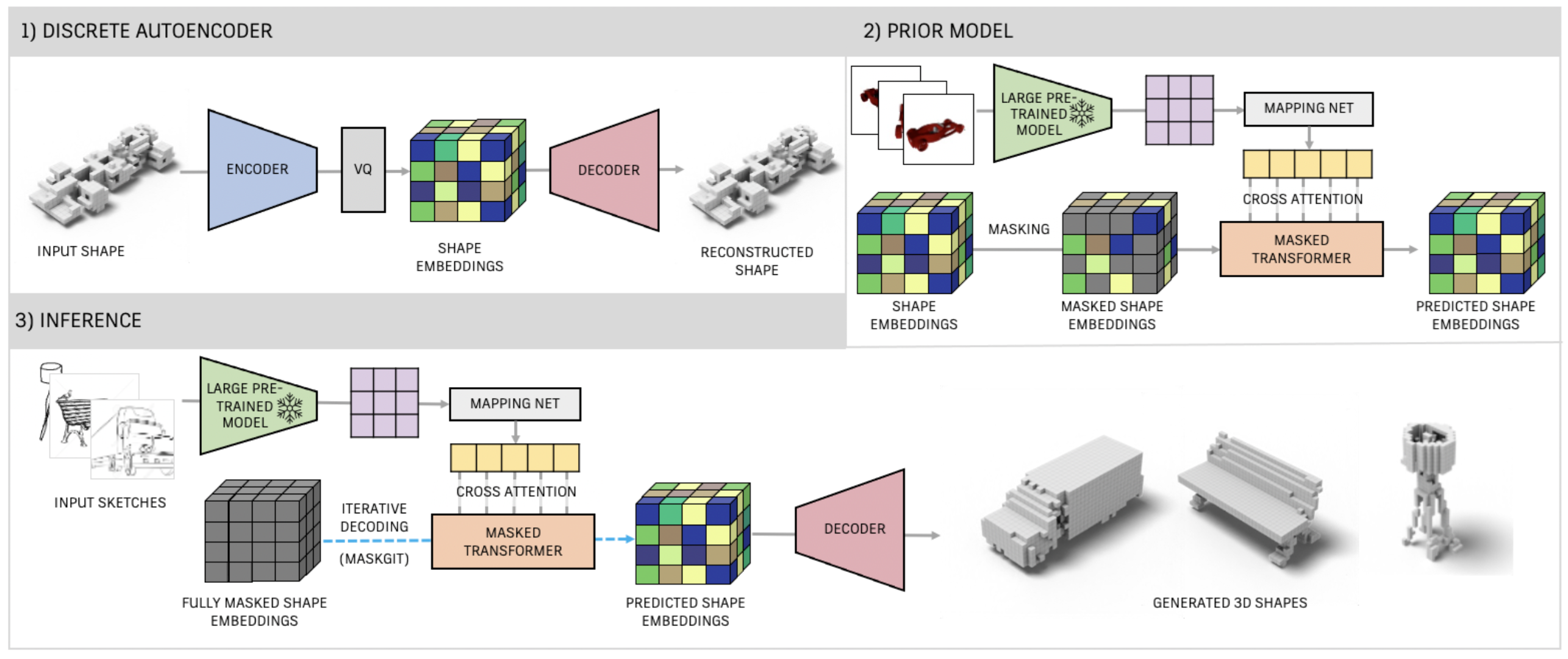
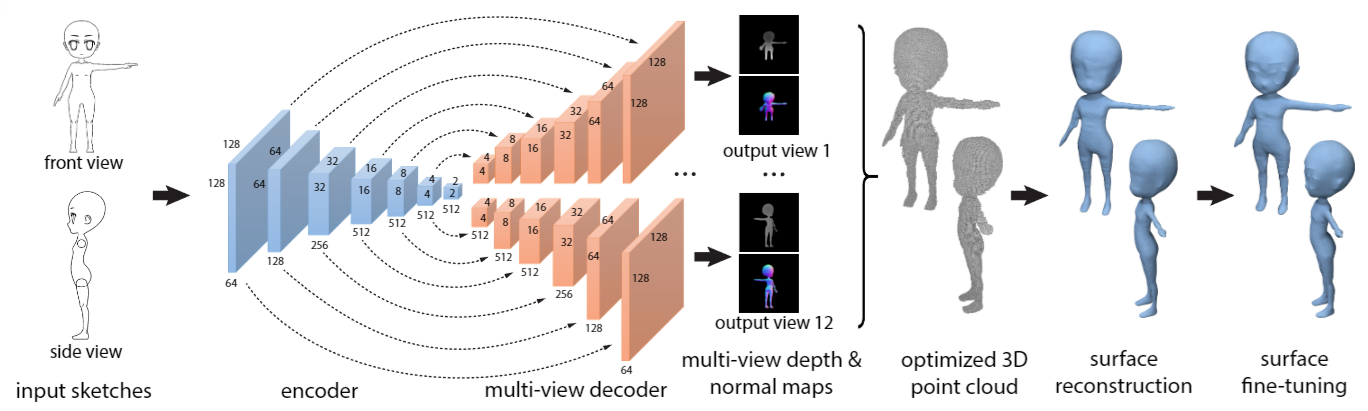
ShapeFromSketches
3D Shape Reconstruction from Sketches via Multi-view Convolutional Networks:
很简单的思路,就是直接输入sketches 然后使用卷积构建单个编码器和两个解码器,生成多个视图的depth 和 normal maps,然后出点云
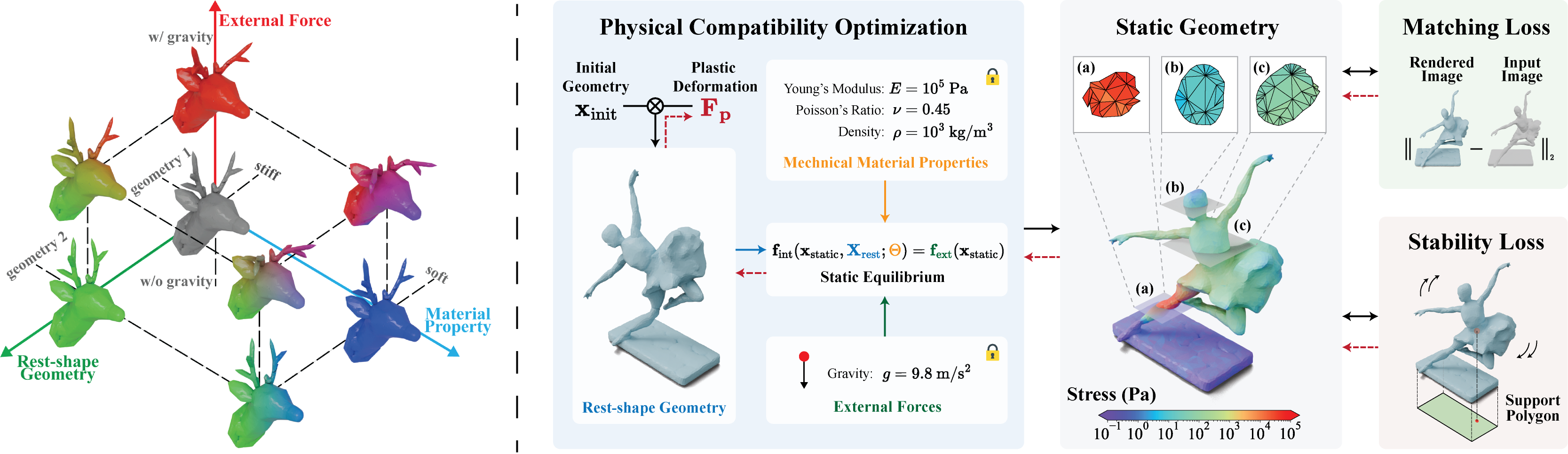
Physically Compatible 3D Object Modeling from a Single Image
Physically Compatible 3D Object Modeling from a Single Image
通过融合物理信息,可以让重建出来的模型,通过3D打印后,可以稳稳地站立在桌面上