Terminology/Jargon
- Human Radiance Fields
- 3D Clothed Human Reconstruction | Digitization
Application
- 三维重建设备:手持扫描仪或 360 度相机矩阵(成本高)
- 复刻一个迷你版的自己
Method
- Depth&Normal Estimation(2K2K)
- Implicit Function(PIFu or NeRF)
- Generative approach Generative Models Reconstruction
Awesome Human Body Reconstruction
| Method | 泛化 | 数据集监督 | 提取 mesh 方式 | 获得纹理方式 |
|---|---|---|---|---|
| 2k2k | 比较好 | (mesh+texture:)depth、normal、mask、rgb | 高质量深度图 —> 点云 —> mesh | 图片 rgb 贴图 |
| PIFu | 比较好 | 点云(obj)、rgb(uv)、mask、camera | 占用场 —> MC —> 点云,mesh | 表面颜色场 |
| NeRF | 差 | rgb、camera | 密度场 —> MC —> 点云,mesh | 体积颜色场 |
| NeuS | 差 | rgb、camera | SDF —> MC —> 点云,mesh | 体积颜色场 |
| ICON | 非常好 | rgb+mask、SMPL、法向量估计器 DR | 占用场 —> MC —> 点云,mesh | 图片 rgb 贴图 |
| ECON | 非常好 | rgb+mask、SMPL、法向量估计器 DR | d-BiNI + SC(shape completion) | 图片 rgb 贴图 |
人体三维重建方法综述
Implicit Function
方法 0:训练隐式函数表示
(eg: NeRF、PIFu、ICON)
DoubleField(多视图)
问题:需要估计相机位姿,估计方法有一定的误差,视图少时误差更大
Depth&Normal Estimation
方法 1:深度估计+多视图深度图融合 or 多视图点云配准
(2K2K-based)
深度估计: 2K2K、MVSNet、ECON…
多视图深度图融合:DepthFusion: Fuse multiple depth frames into a point cloud
- 需要相机位姿,位姿估计有误差
- 更准确的位姿: BA(Bundle Adjusted 光束法平差,优化相机 pose 和 landmark)
多视图点云配准:Point Cloud Registration
- 点云配准(Point Cloud Registration) 2K 生成的多角度点云形状不统一
问题:无法保证生成的多视角深度图具有多视图一致性
Generative approach
方法 2:生成式方法由图片生成点云
Generative approach(Multi-view image、pose (keypoints)… —> PointCloud)
- 扩散模型
- 直接生成点云 BuilDiff
- 生成三平面特征+NeRF RODIN
- 多视图 Diffusion DiffuStereo
- GAN 网络生成点云 SG-GAN
- 生成一致性图片+NeRF
- 参考 BuilDiff,构建网络(PVCNNs 单类训练)
- 是否更换扩散网络 DiT-3D,可以学习显式的类条件嵌入(生成多样化的点云)
- 是否依靠 SMPL,根据 LBS(Linear Blending Skinning)将人体 mesh 变形到规范化空间
- Video2Avatar (NeRF-based)将整个人体规范化后采样
- EVA3D 将 NeRF 融入 GAN 生成图片,并与真实图片一同训练判别器(人体规范化后分块 NeRF)
问题:直接生成点云或者对点云进行扩散优化,会花费大量的内存
混合方法
方法 3:组合深度估计 + 生成式方法(缝合多个方法)
HaP:深度估计+SMPL 估计+Diffusion Model 精细化
问题:依赖深度估计和 SMPL 估计得到的结果
方法 4:隐函数 + 生成式方法 + 非刚ICP配准
DiffuStereo:NeRF(DoubleField) + Diffusion Model + non-rigid ICP (不开源)
三维重建方法流程对比
Implicit Function
NeRF
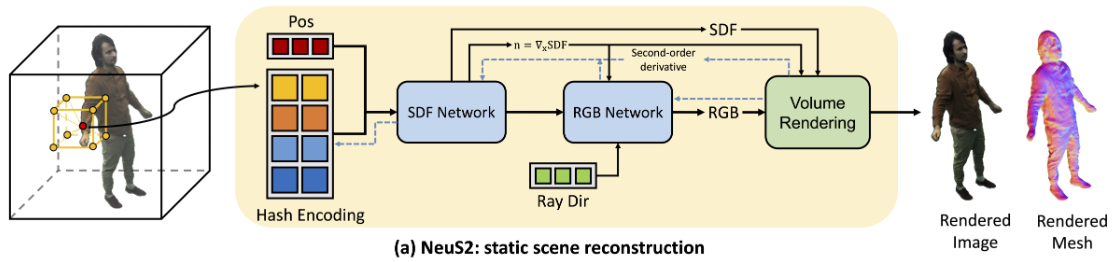
预测每个采样点 sdf 和 feature 向量
$(sdf,\mathbf{feature})=f_\Theta(\mathbf{e}),\quad\mathbf{e}=(\mathbf{x},h_\Omega(\mathbf{x})).$
预测每个采样点颜色值
$\mathbf c=c_{\Upsilon}(\mathbf x,\mathbf n,\mathbf v,sdf,\mathbf{feature})$,$\mathbf n=\nabla_\mathbf x sdf.$
体渲染像素颜色
$\hat{C}=\sum_{i=1}^n T_i\alpha_i c_i$, $T_i=\prod_{j=1}^{i-1}(1-\alpha_j)$ ,$\alpha_i=\max\left(\frac{\Phi_s(f(\mathbf{p}(t_i))))-\Phi_s(f(\mathbf{p}(t_{i+1})))}{\Phi_s(f(\mathbf{p}(t_i)))},0\right)$
训练得到 MLP,根据 MarchingCube 得到点云
PIFu
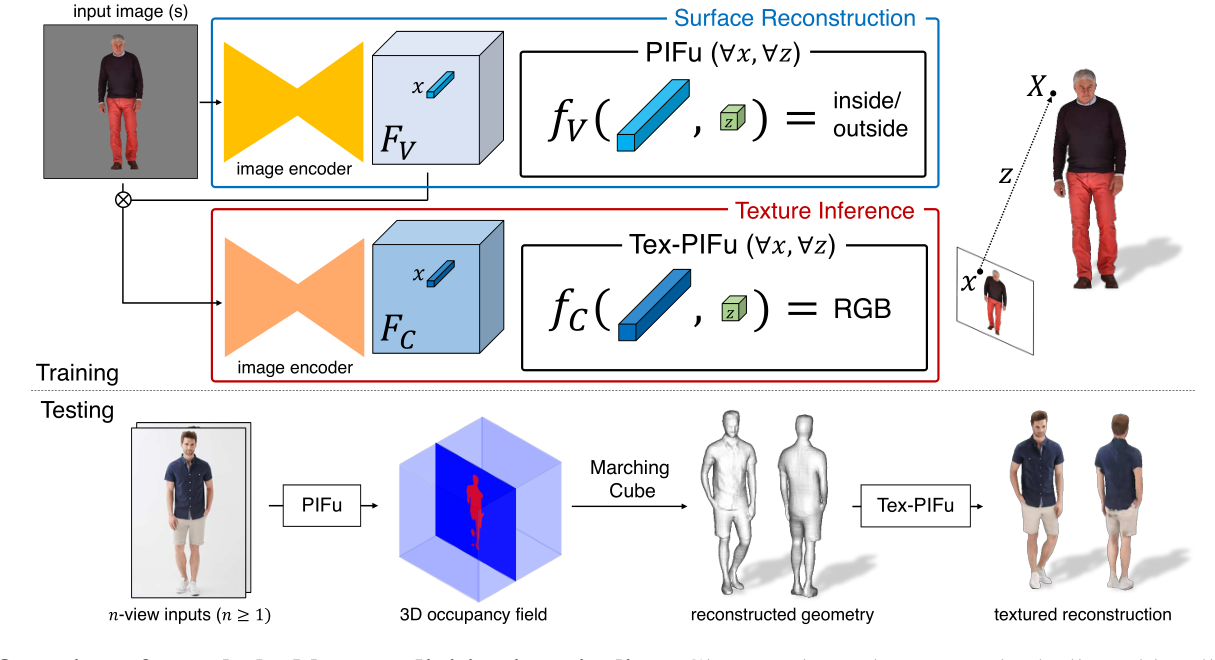
将输入图像中每个像素的特征通过 MLP 映射为占用场
Depth&Normal Estimation
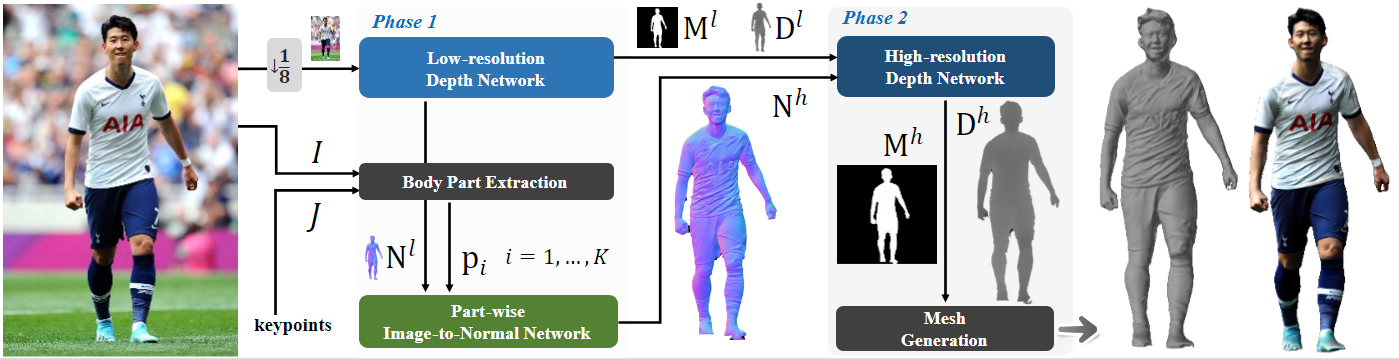
预测低分辨率法向量图和深度图,$\hat M$ 为预测出的 mask
$\mathbf{D}^l=\hat{\mathbf{D}}^l\odot\hat{\mathbf{M}}^l$, $\hat{\mathbf{D}}^l,\hat{\mathbf{M}}^l,\mathbf{N}^l=G^l_{\mathbf{D}}(I^l)$
预测高分辨率 part 法向量图,M 为变换矩阵
$\bar{\mathbf{n}}_i=G_{\mathbf{N},i}(\bar{\mathbf{p}}_i,\mathbf{M}_i^{-1}\mathbf{N}^l)$, $\bar{\mathbf{p}}_i=\mathbf{M}_i\mathbf{p}_i,$
拼接为高分辨率整体法向量图
$\mathbf{N}^h=\sum\limits_{i=1}^K\left(\mathbf{W}_i\odot\mathbf{n}_i\right)$ ,$\mathbf{n}_i=\mathbf{M}_i^{-1}\bar{\mathbf{n}}_i$
预测高分辨率深度图
$\mathbf{D}^h=\hat{\mathbf{D}}^h\odot\hat{\mathbf{M}}^h$,$\hat{\mathbf{D}}^h,\hat{\mathbf{M}}^h=G^h_{\mathbf{D}}(\mathbf{N}^h,\mathbf{D}^l)$
深度图转点云
Generative approach
Diffusion Model Network
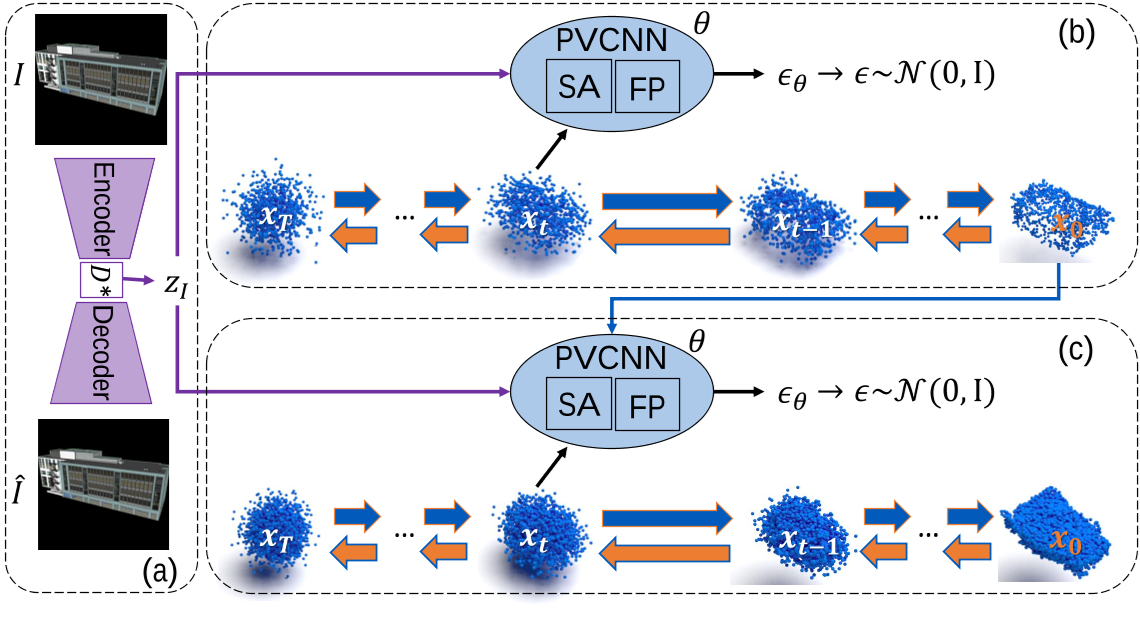

3D CNN: PVCNN、PointNet、PointNet++
2D CNN: 3D-aware convolution(RODIN)
GAN
Paper about Human Reconstruction👇
NeRF-based Human Body Reconstruction
HISR
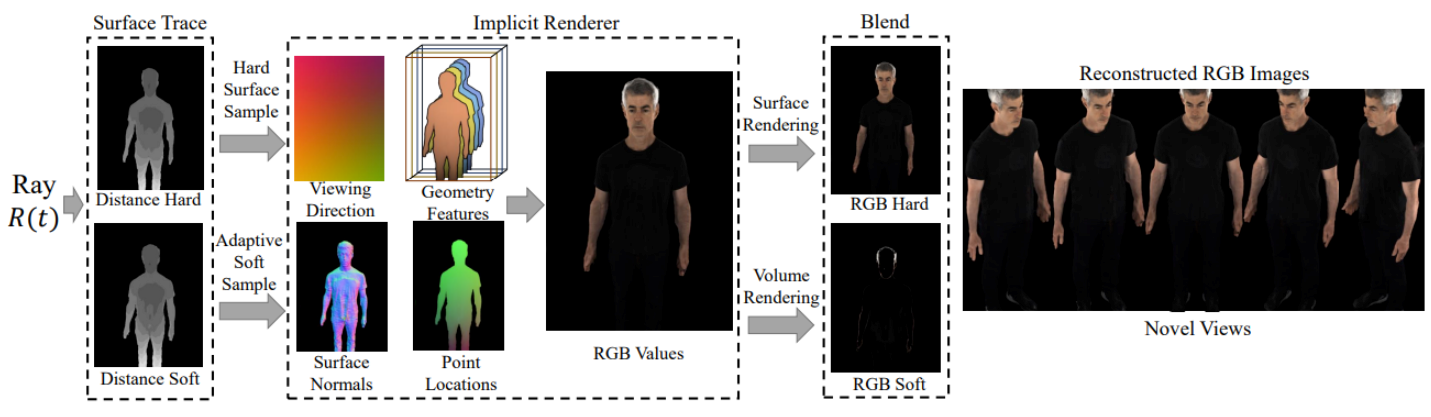
- 对不透明区域(例如身体、脸部、衣服)执行基于表面的渲染
- 在半透明区域(例如头发)上执行体积渲染
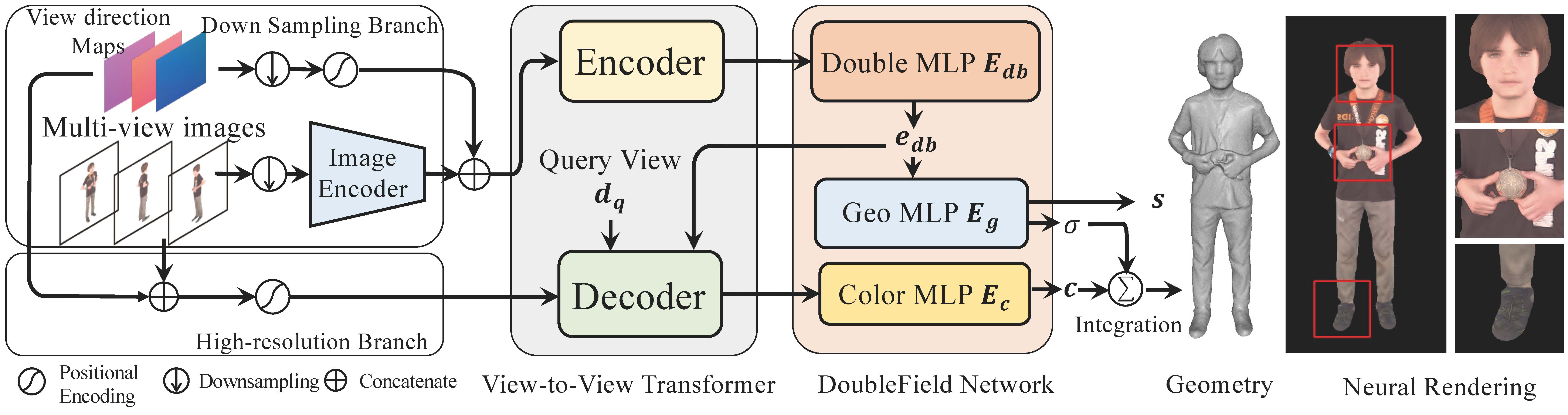
DoubleField
DoubleField Project Page (liuyebin.com)
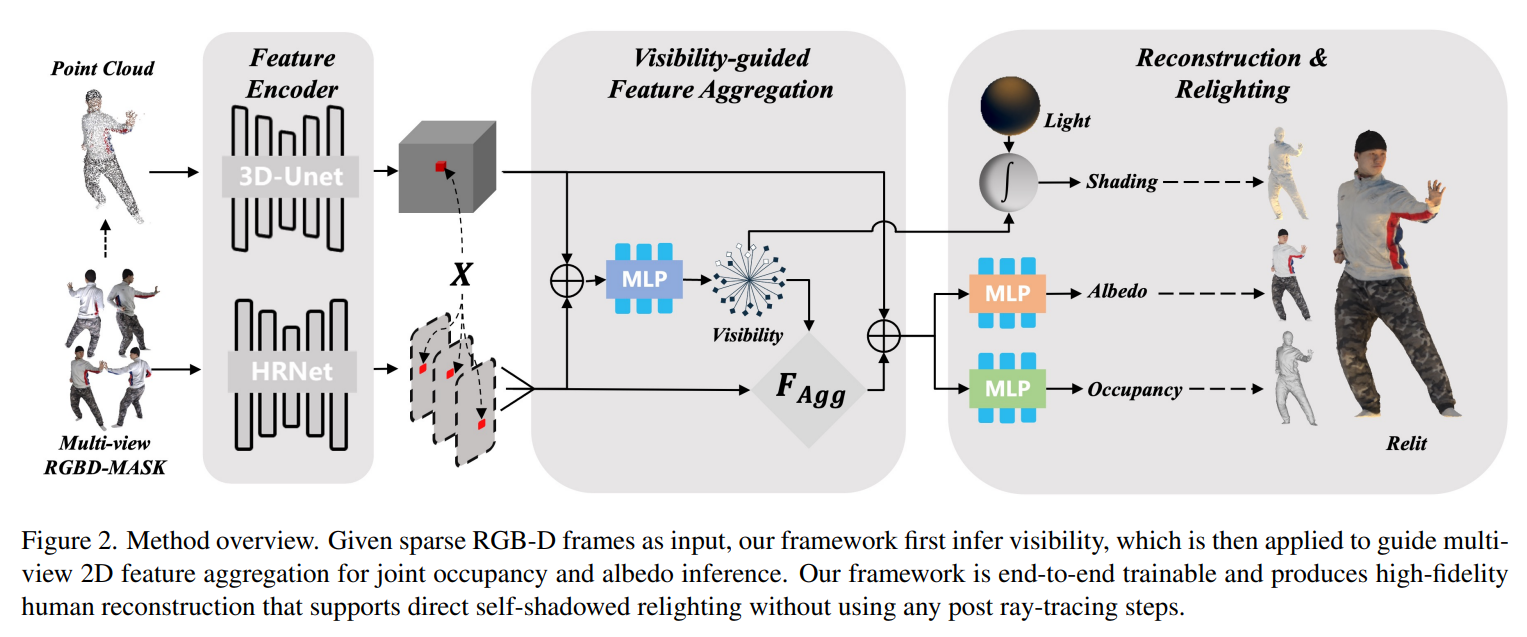
Learning Visibility Field for Detailed 3D Human Reconstruction and Relighting
Learning Visibility Field for Detailed 3D Human Reconstruction and Relighting (thecvf.com)

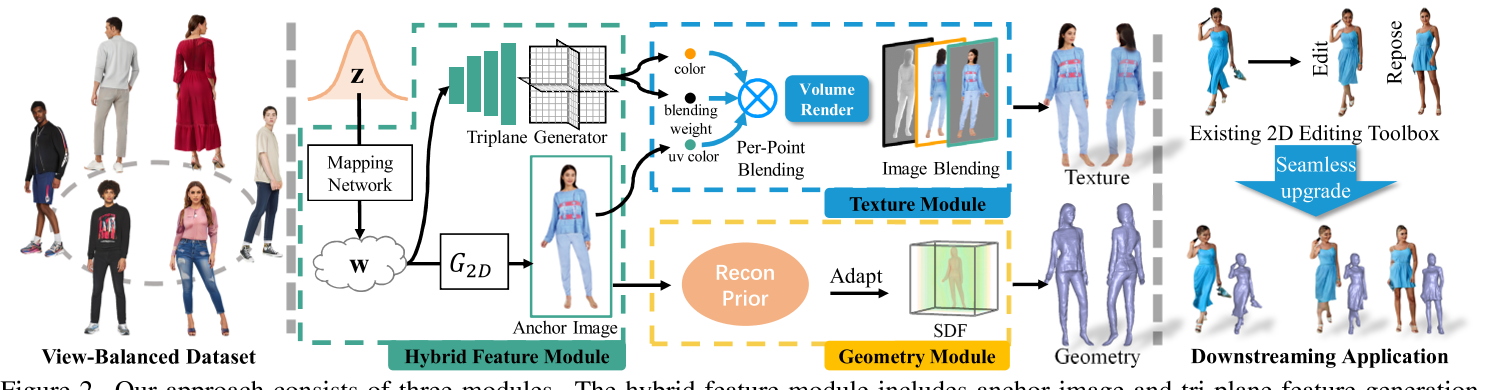
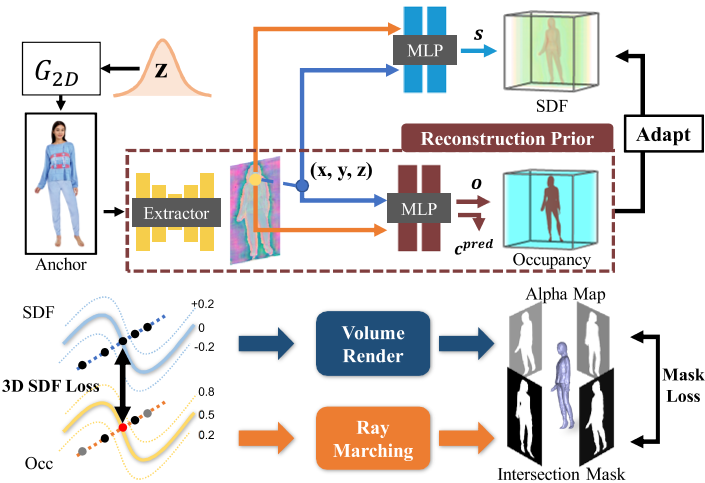
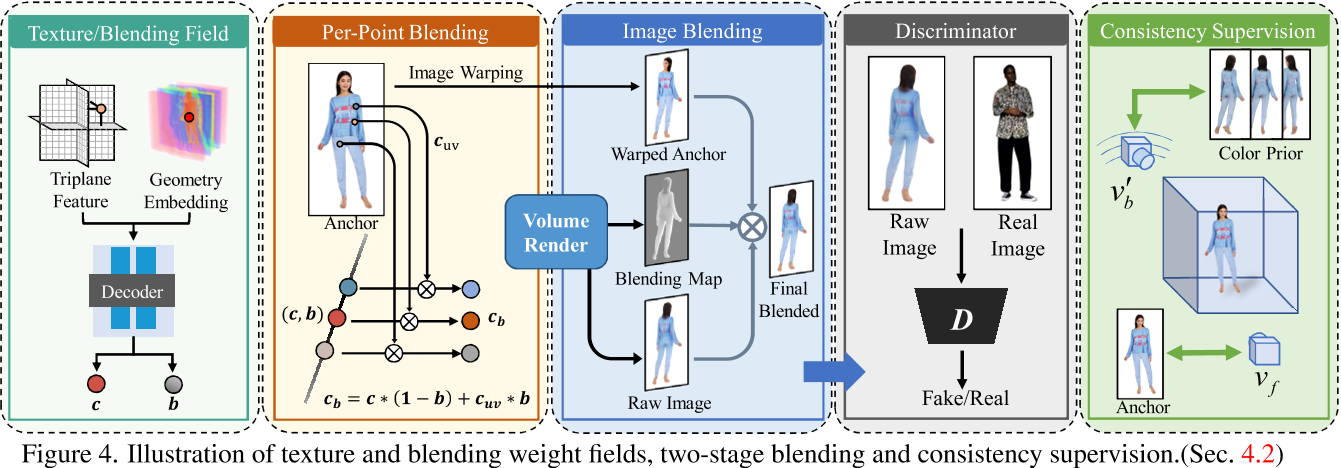
HumanGen
HumanGen: Generating Human Radiance Fields with Explicit Priors (suezjiang.github.io)
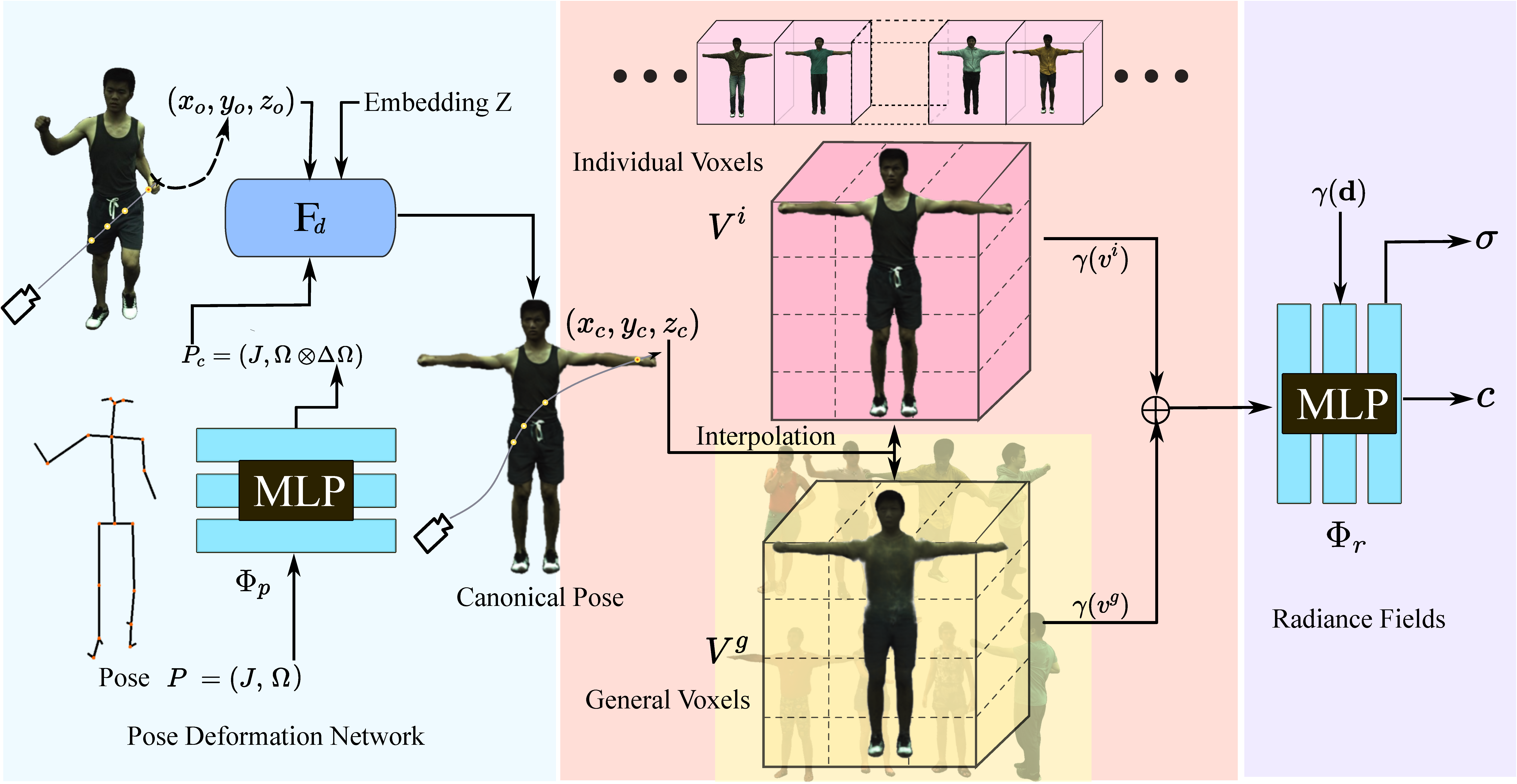
GNeuVox
GNeuVox: Generalizable Neural Voxels for Fast Human Radiance Fields (taoranyi.com)
Generalizable Neural Voxels for Fast Human Radiance Fields (readpaper.com)
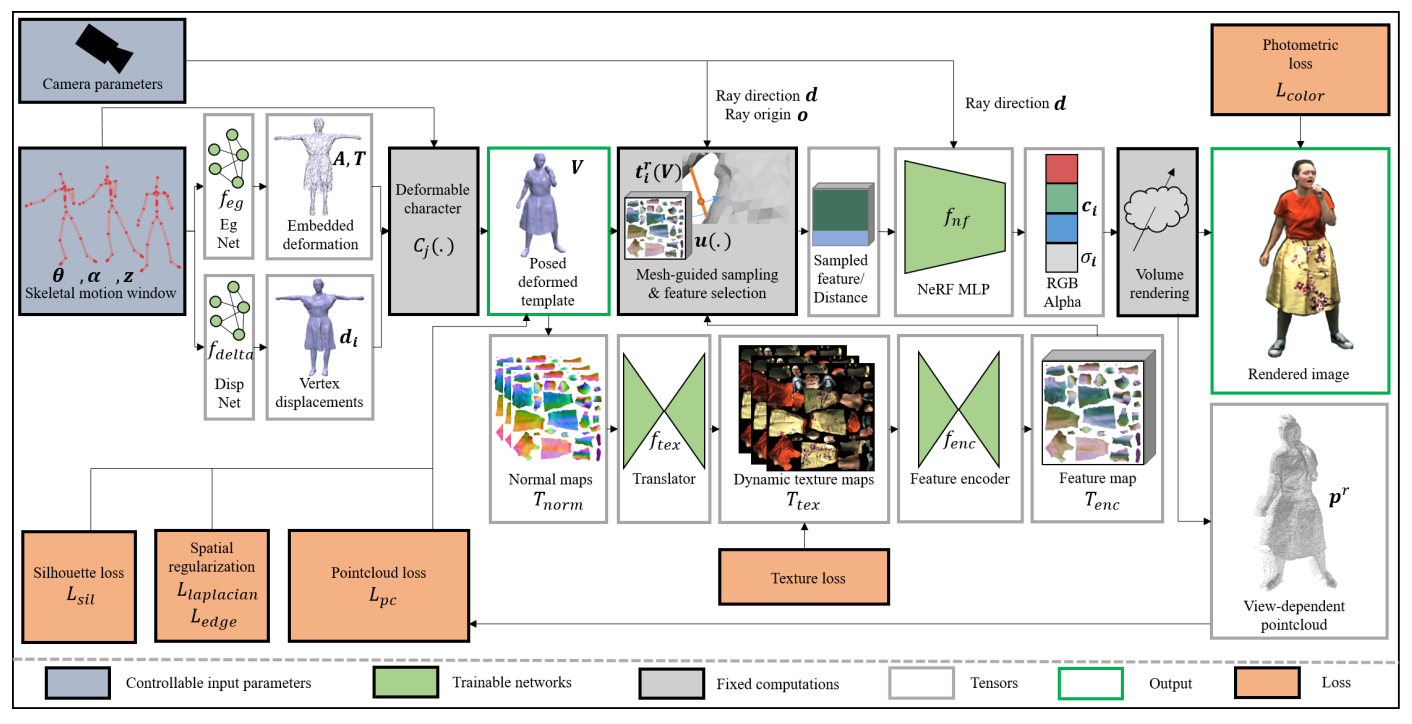
CAR
HDHumans
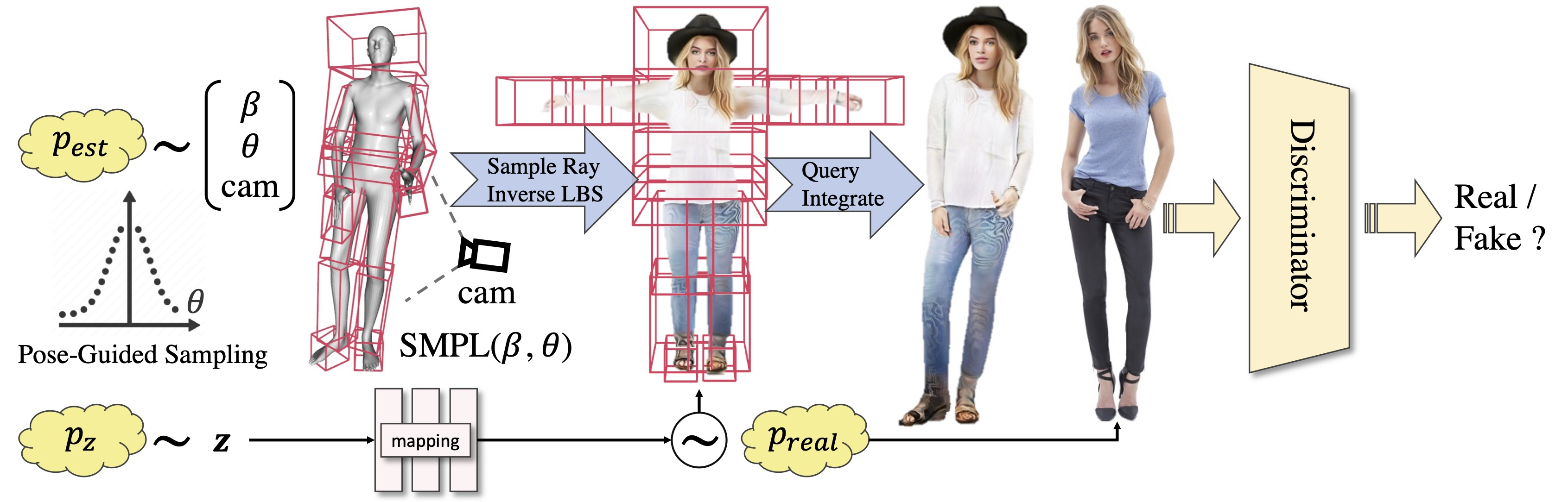
EVA3D 2022
Compositional Human body
质量很低
Idea:
- 将人体分为几个部分分别训练
- 将 NeRF 融合进 GAN 的生成器中,并与一个判别器进行联合训练
Cost:
- 8 NVIDIA V100 Gpus for 5 days
EVA3D - Project Page (hongfz16.github.io)
EVA3D: Compositional 3D Human Generation from 2D Image Collections (readpaper.com)
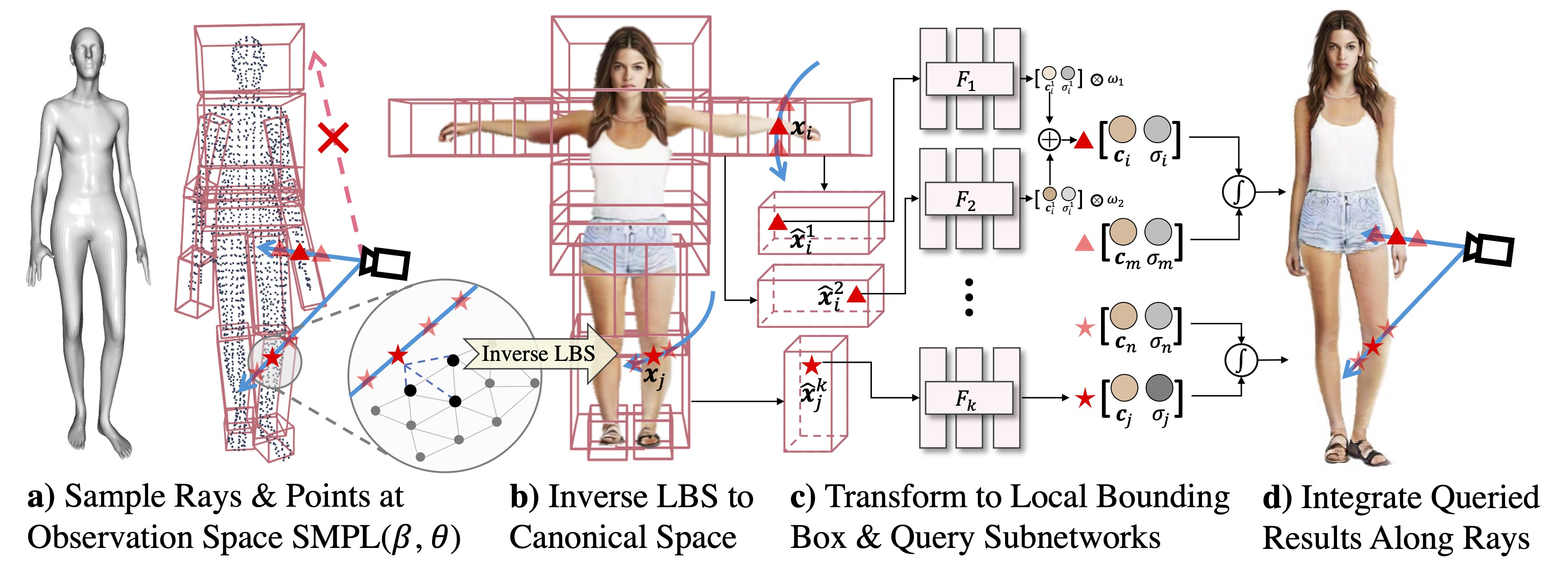
Dynamic
3DGS-Avatar
3DGS-Avatar: Animatable Avatars via Deformable 3D Gaussian Splatting (neuralbodies.github.io)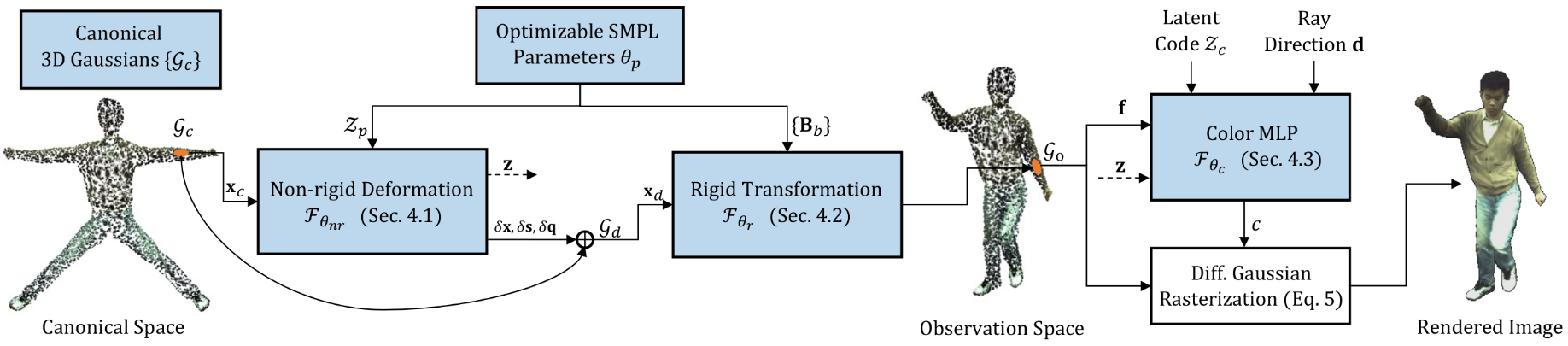
GaussianAvatar
Projectpage of GaussianAvatar (huliangxiao.github.io)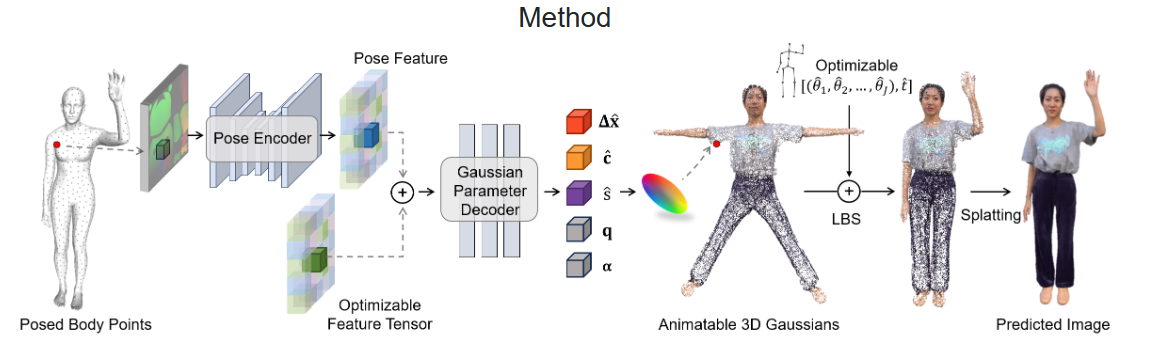
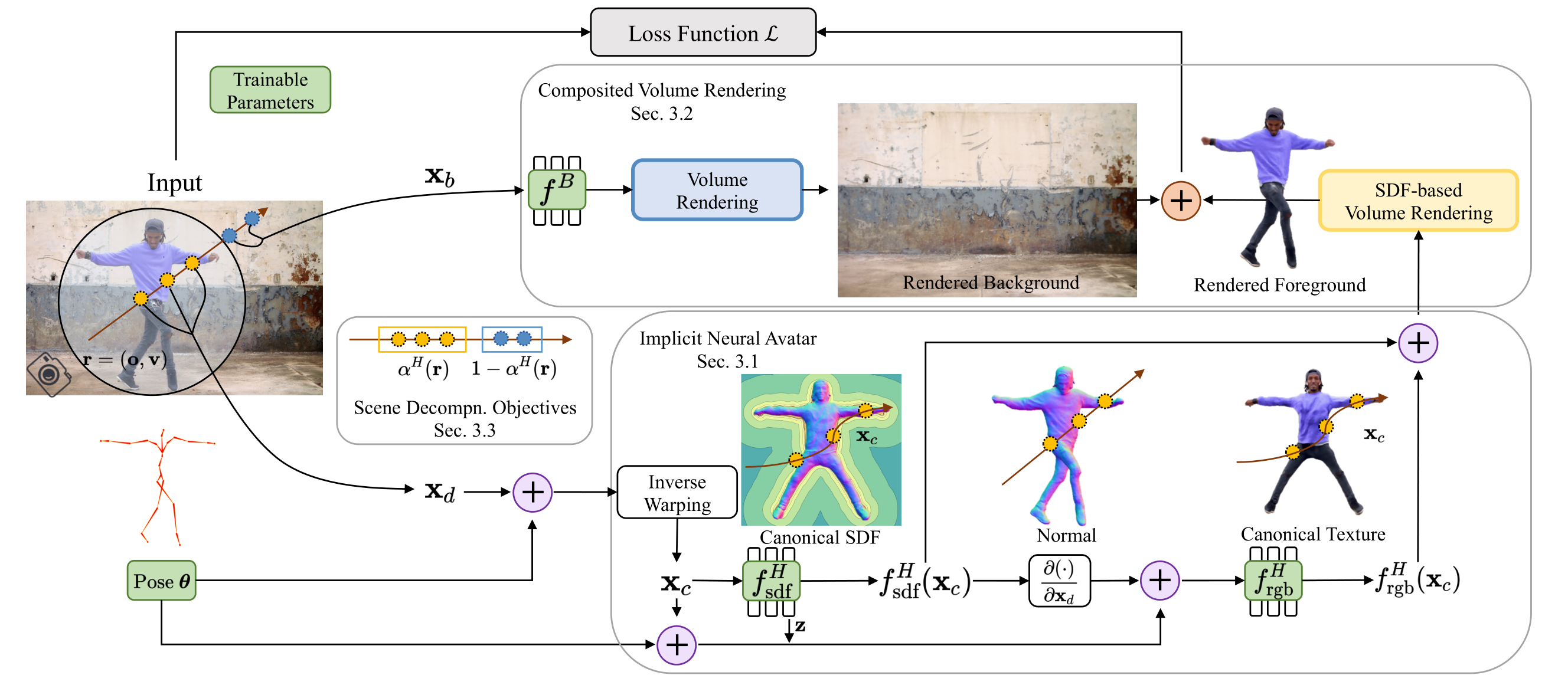
Vid2Avatar
Vid2Avatar: 3D Avatar Reconstruction from Videos in the Wild via Self-supervised Scene Decomposition
Vid2Avatar: 3D Avatar Reconstruction from Videos in the Wild via Self-supervised Scene Decomposition (moygcc.github.io)
Im4D
Im4D (zju3dv.github.io)
Im4D: High-Fidelity and Real-Time Novel View Synthesis for Dynamic Scenes
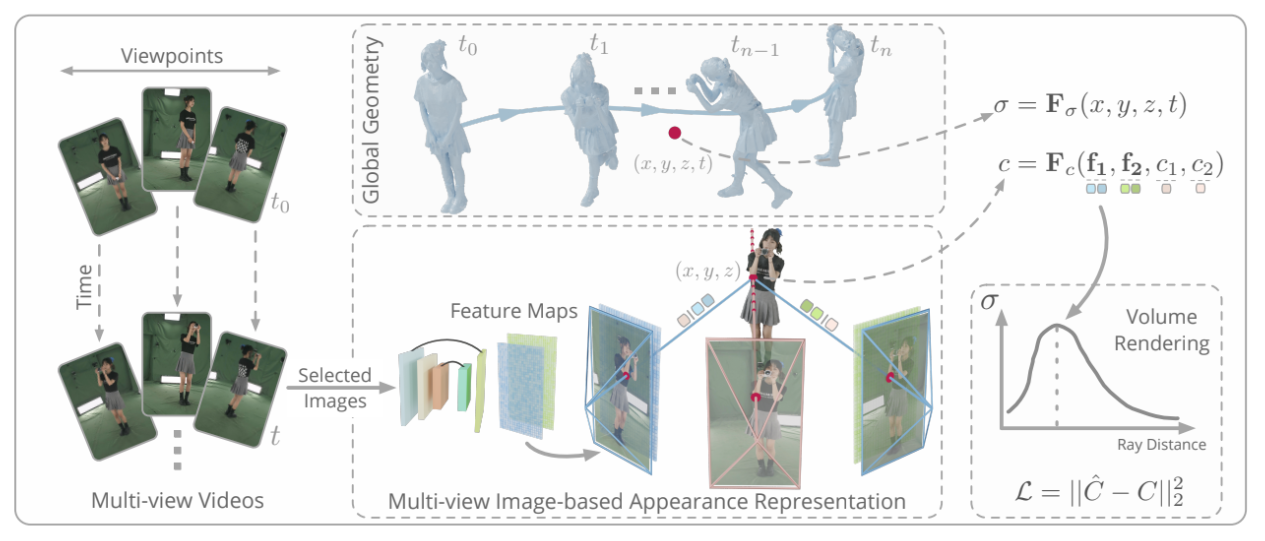
HumanRF
HumanRF: High-Fidelity Neural Radiance Fields for Humans in Motion (synthesiaresearch.github.io)
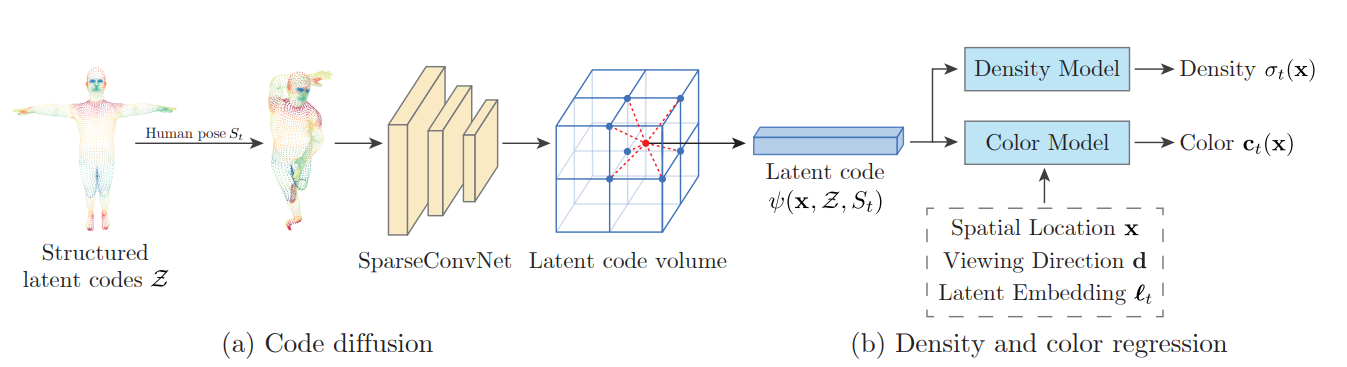
Neural Body
首先在SMPL6890个顶点上定义一组潜在代码,然后
使用Total Capture: A 3D Deformation Model for Tracking Faces, Hands, and Bodies (readpaper.com)
从多视图图片中获取SMPL参数$S_{t}$
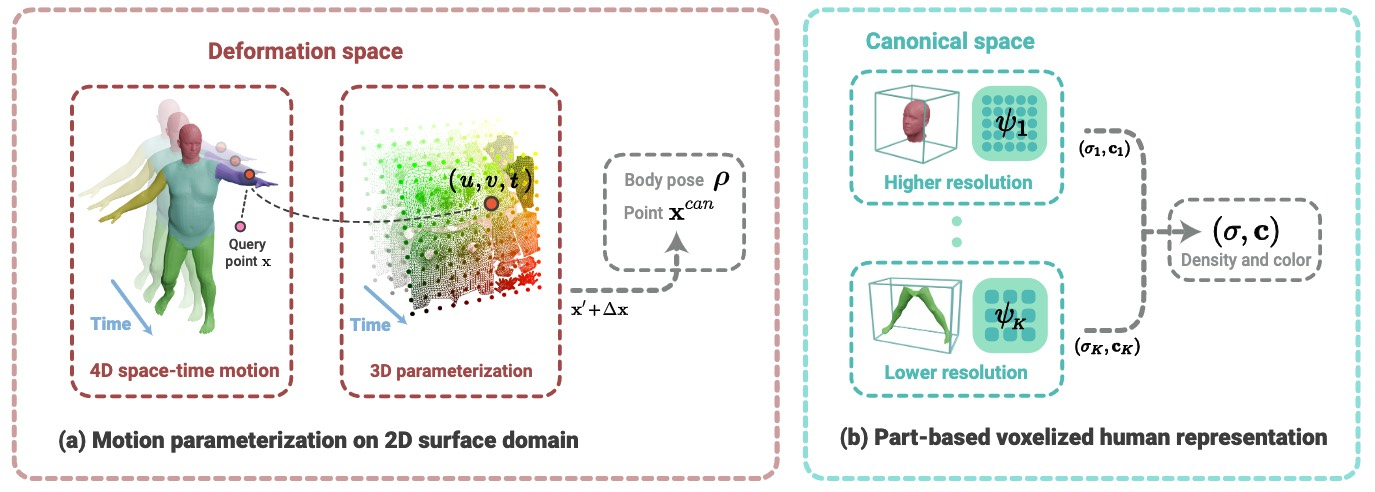
InstantNVR
Learning Neural Volumetric Representations of Dynamic Humans in Minutes (zju3dv.github.io)
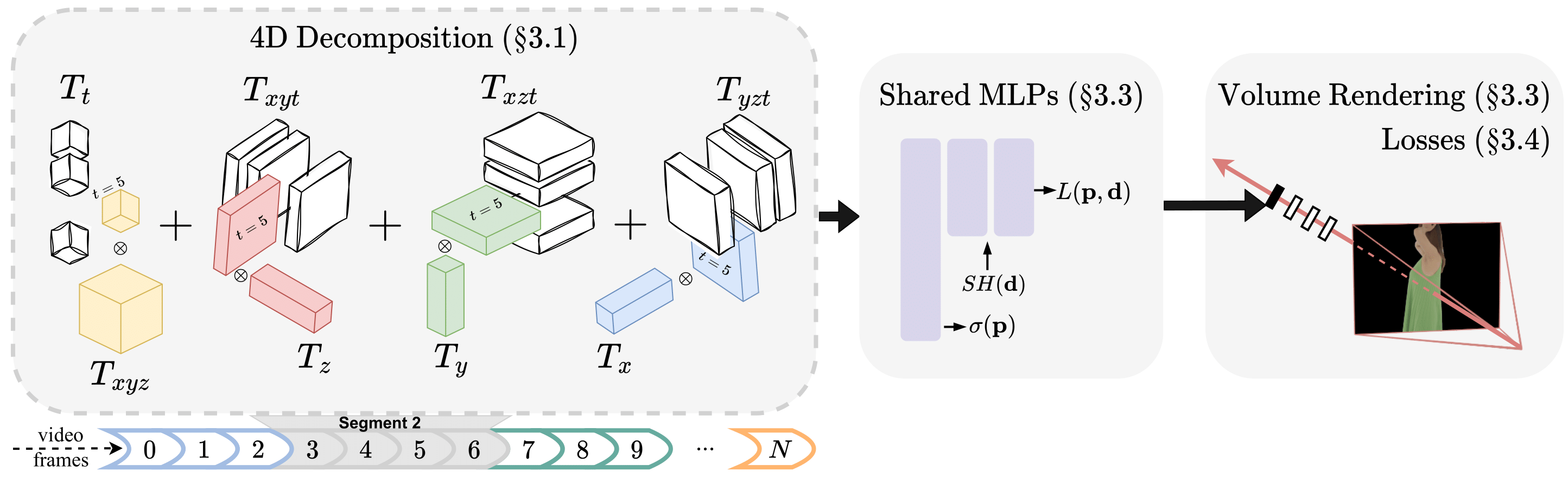
4K4D
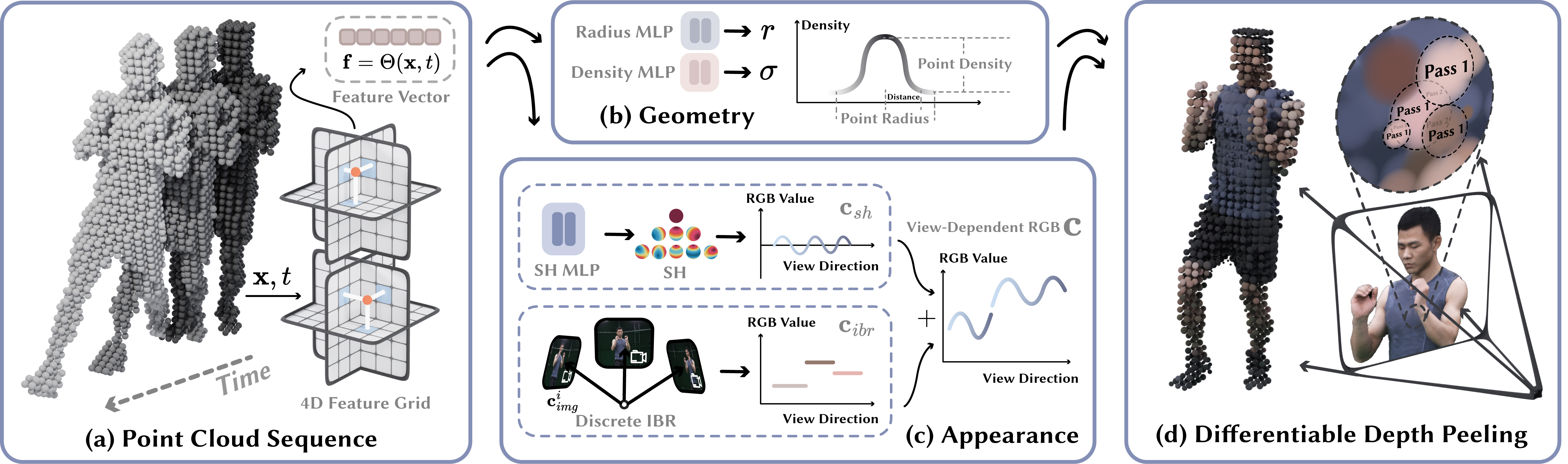
D3GA
D3GA - Drivable 3D Gaussian Avatars - Wojciech Zielonka
多视图视频作为输入 + 3DGS + 笼形变形
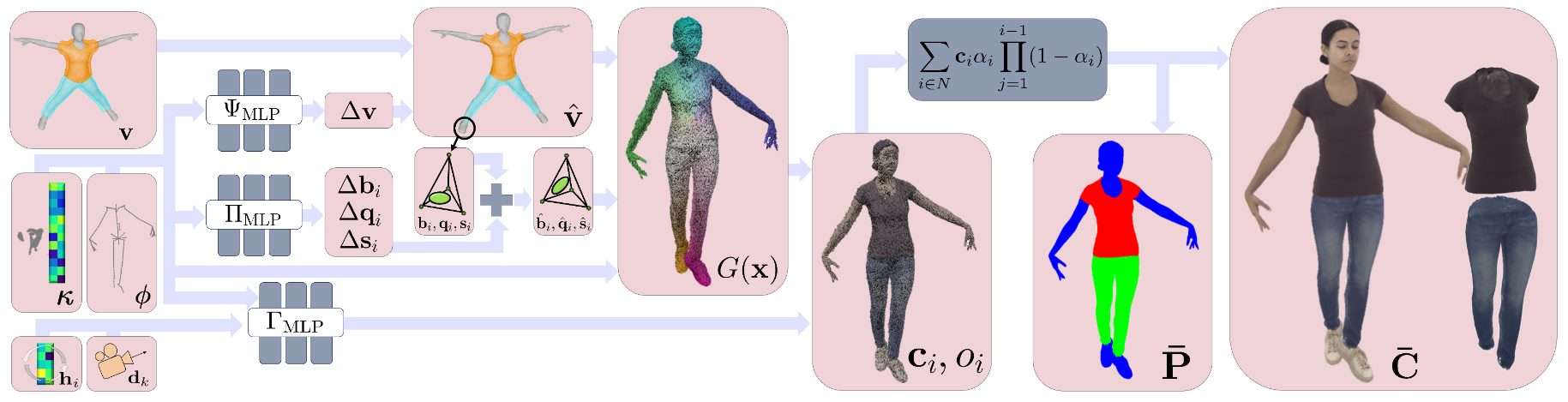
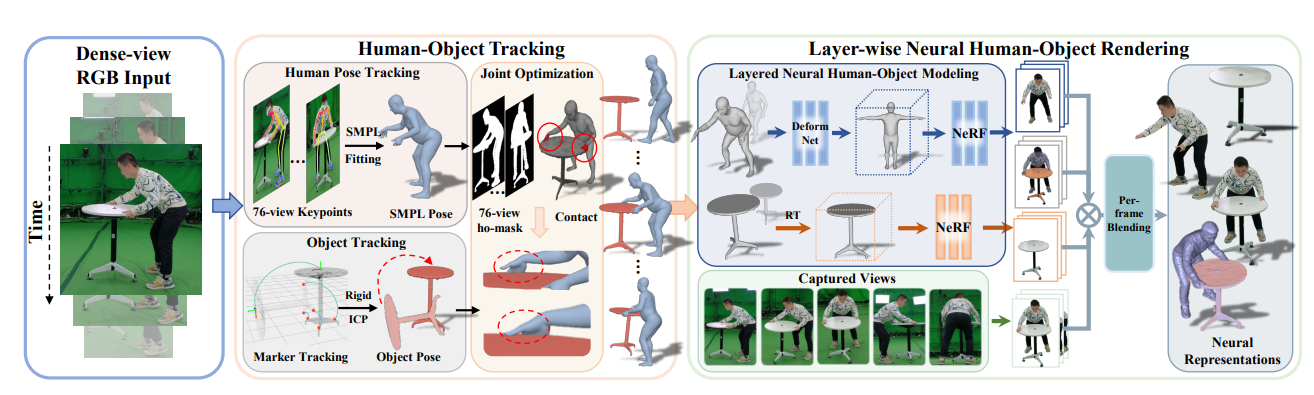
Human-Object Interactions
Instant-NVR
NeuralDome
NeuralDome (juzezhang.github.io)
PIFu Occupancy Field
PIFu: Pixel-Aligned Implicit Function for High-Resolution Clothed Human Digitization
PIFu: Pixel-Aligned Implicit Function for High-Resolution Clothed Human Digitization (shunsukesaito.github.io)
PIFuHD
PIFuHD: Multi-Level Pixel-Aligned Implicit Function for High-Resolution 3D Human Digitization
PIFuHD: Multi-Level Pixel-Aligned Implicit Function for High-Resolution 3D Human Digitization (shunsukesaito.github.io)
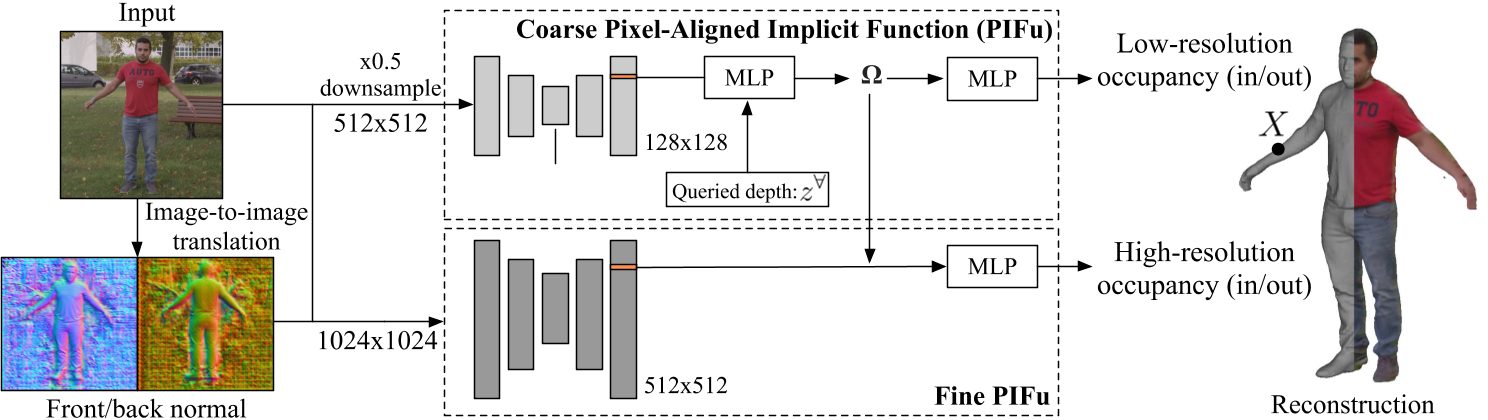
PIFu for the Real World
X-zhangyang/SelfPIFu—PIFu-for-the-Real-World: Dressed Human Reconstrcution from Single-view Real World Image (github.com)
PIFu for the Real World: A Self-supervised Framework to Reconstruct Dressed Human from Single-view Images (readpaper.com)
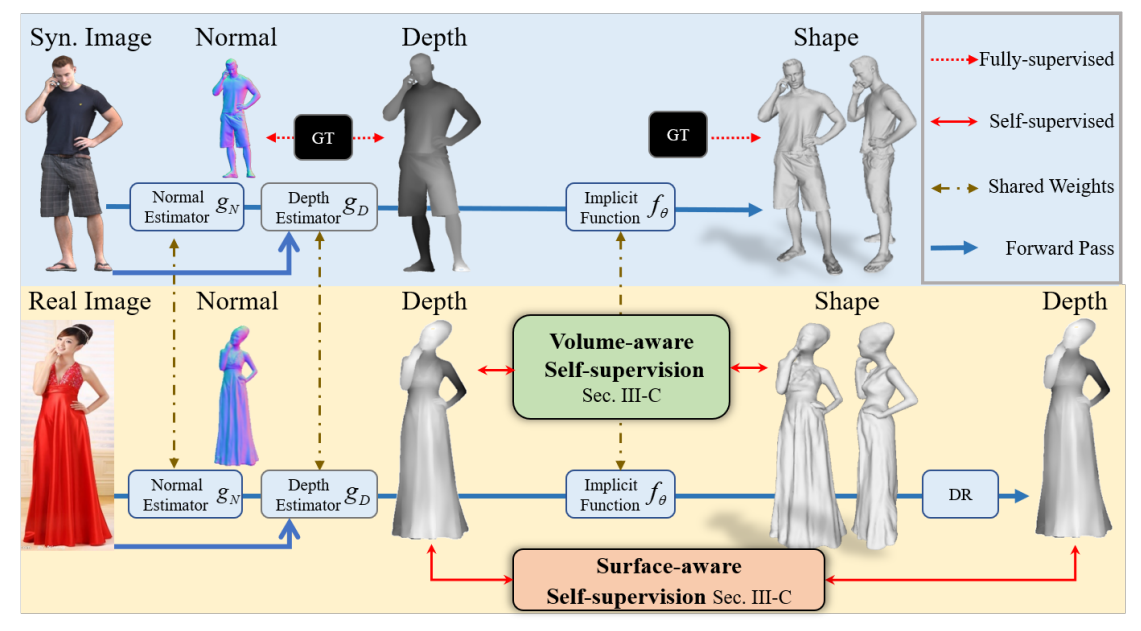
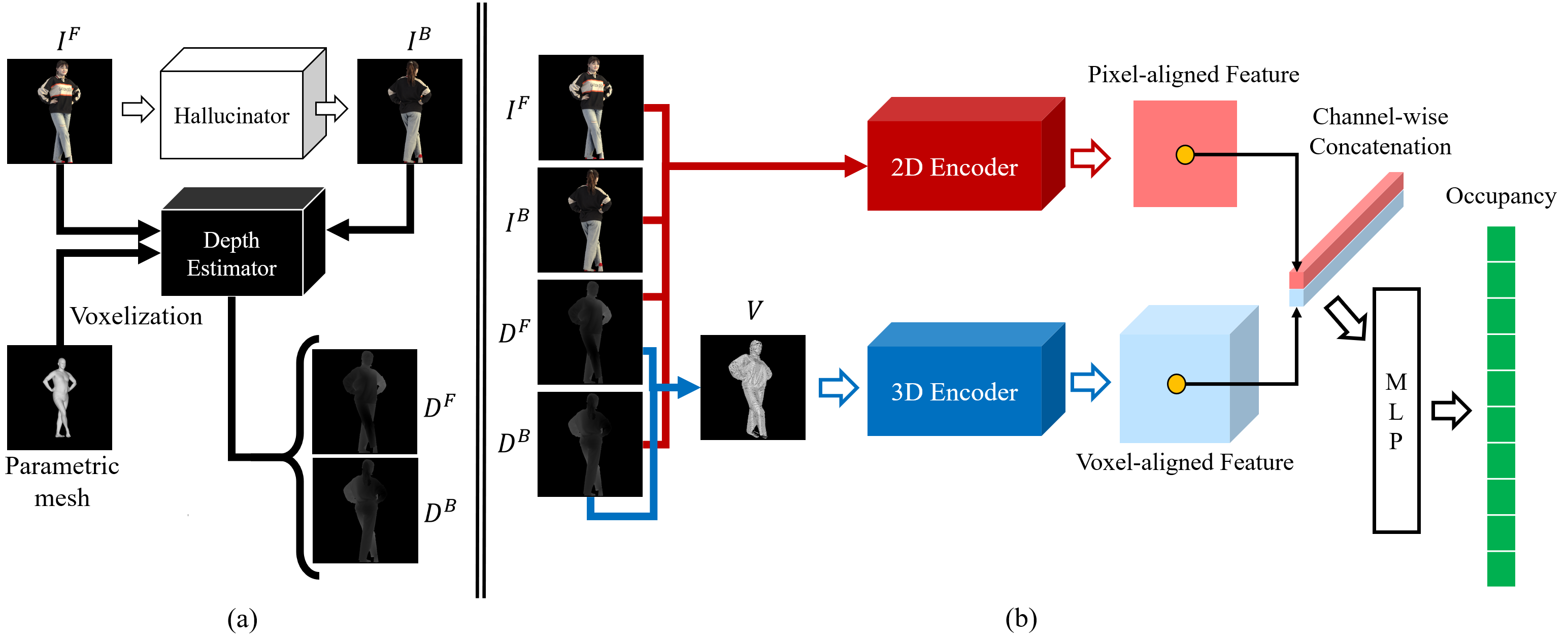
DIFu
DIFu: Depth-Guided Implicit Function for Clothed Human Reconstruction (eadcat.github.io)
DIFu: Depth-Guided Implicit Function for Clothed Human Reconstruction (thecvf.com)
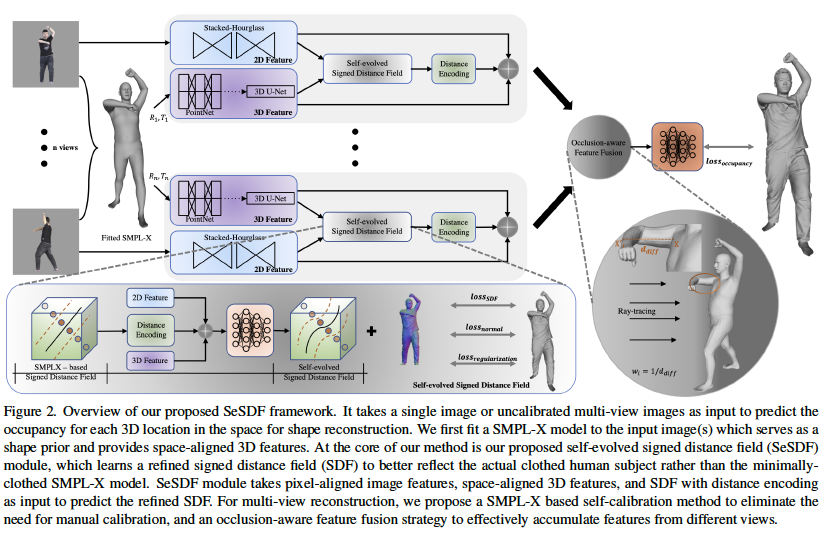
SeSDF
SeSDF: Self-evolved Signed Distance Field for Implicit 3D Clothed Human Reconstruction (yukangcao.github.io)
SeSDF: Self-evolved Signed Distance Field for Implicit 3D Clothed Human Reconstruction (readpaper.com)
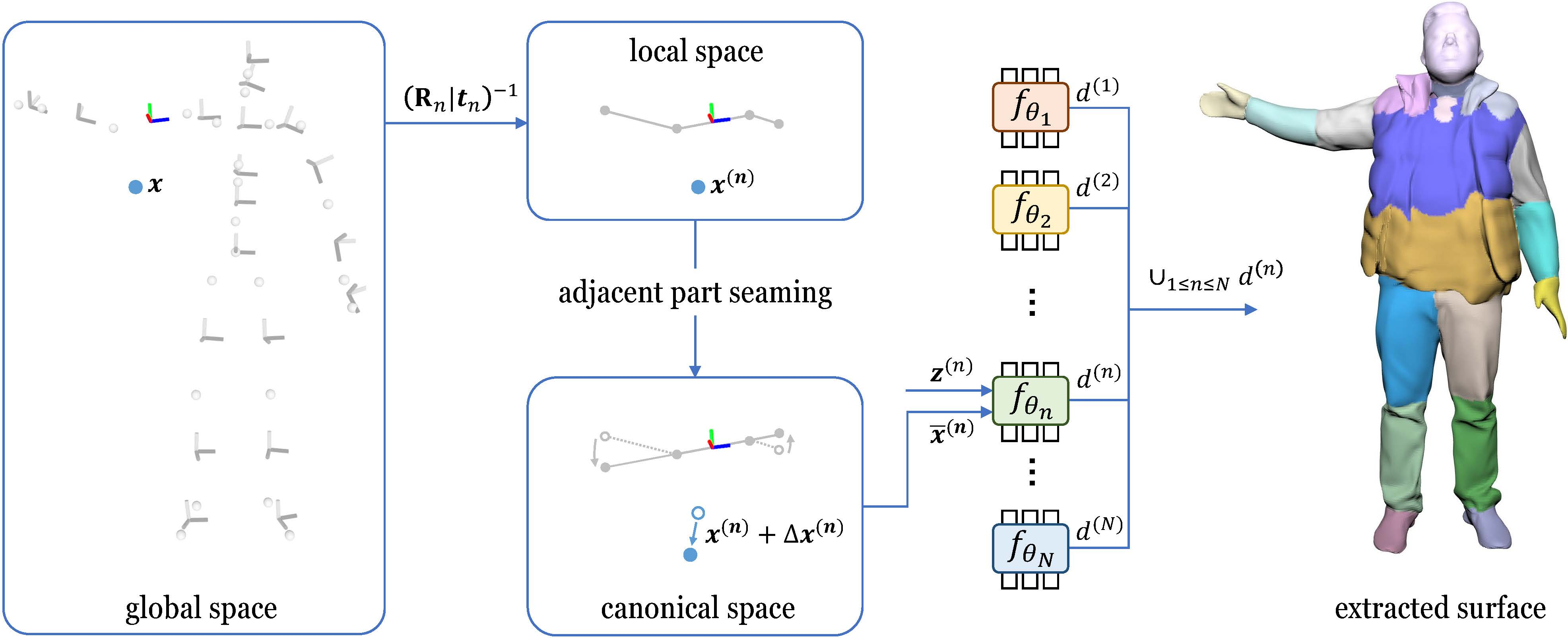
UNIF
UNIF: United Neural Implicit Functions for Clothed Human Reconstruction and Animation | Shenhan Qian
UNIF: United Neural Implicit Functions for Clothed Human Reconstruction and Animation (readpaper.com)
Structured 3D Features
Reconstructing Relightable and Animatable Avatars
Enric Corona
Structured 3D Features for Reconstructing Relightable and Animatable Avatars (readpaper.com)
X,3d fea,2d fea —> transformer —> sdf, albedo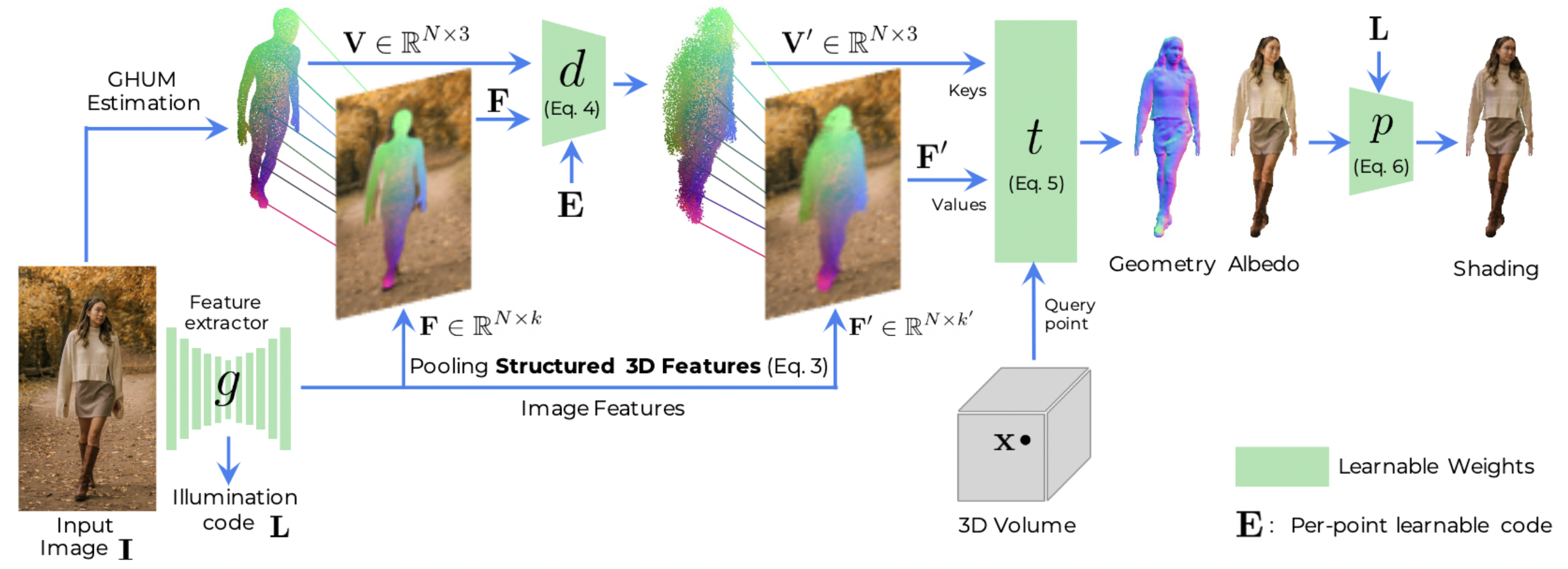
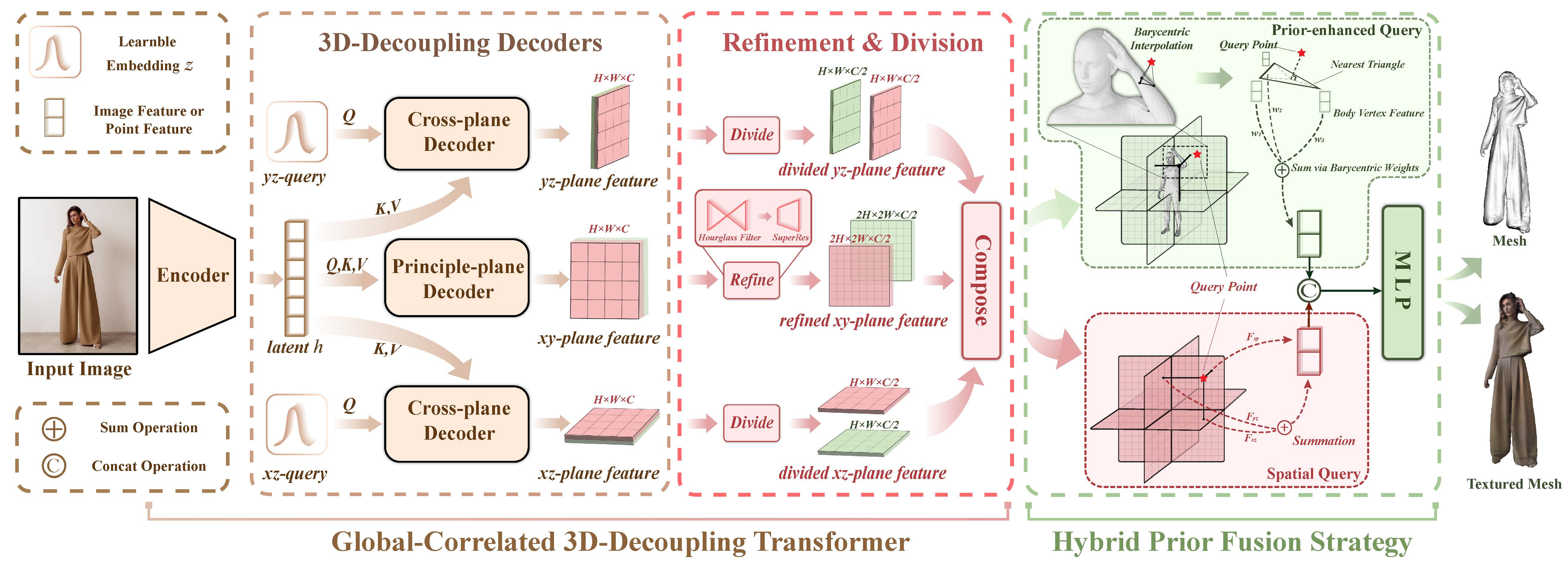
GTA
Global-correlated 3D-decoupling Transformer for Clothed Avatar Reconstruction (river-zhang.github.io)
Global-correlated 3D-decoupling Transformer for Clothed Avatar Reconstruction (readpaper.com)
Get3DHuman
GAN + PIFus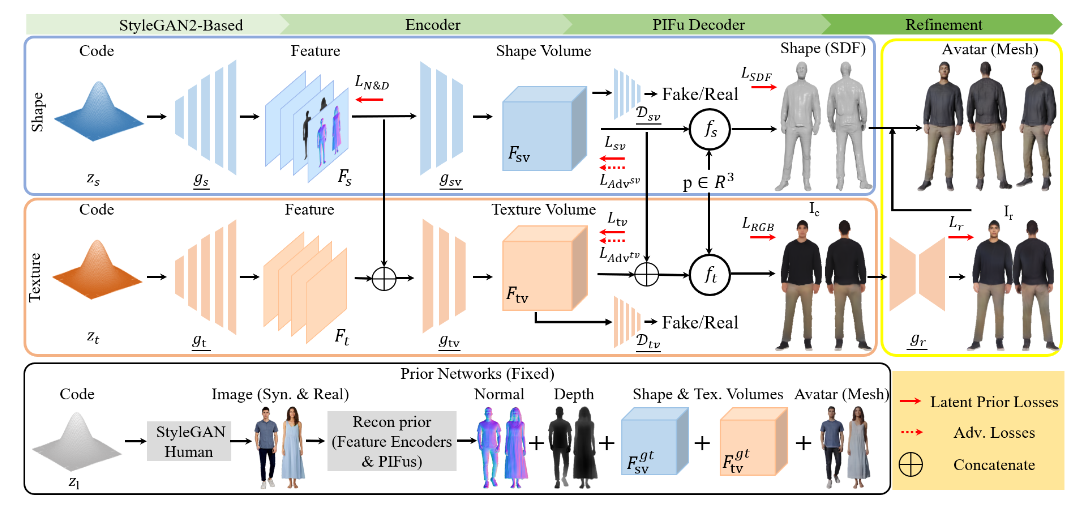
DRIFu
kuangzijian/drifu-for-animals: meta-learning based pifu model for animals (github.com)
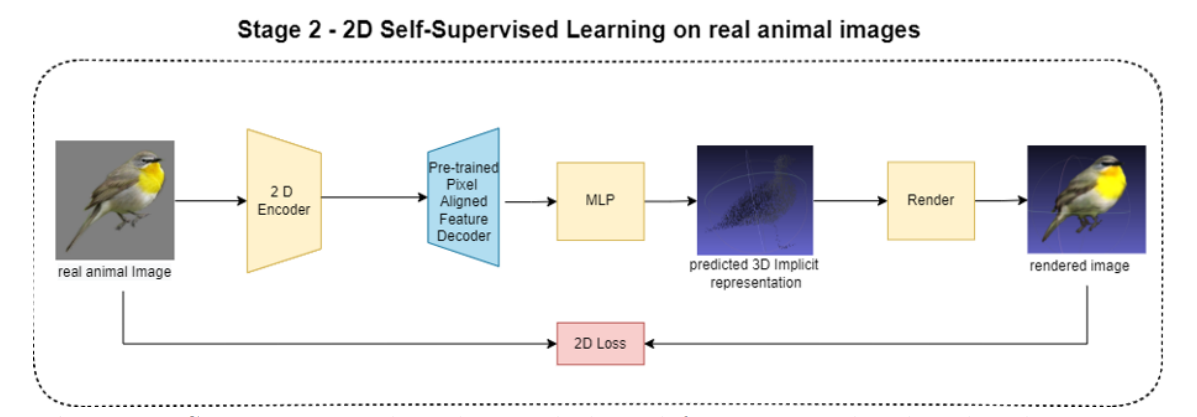
鸟类PIFu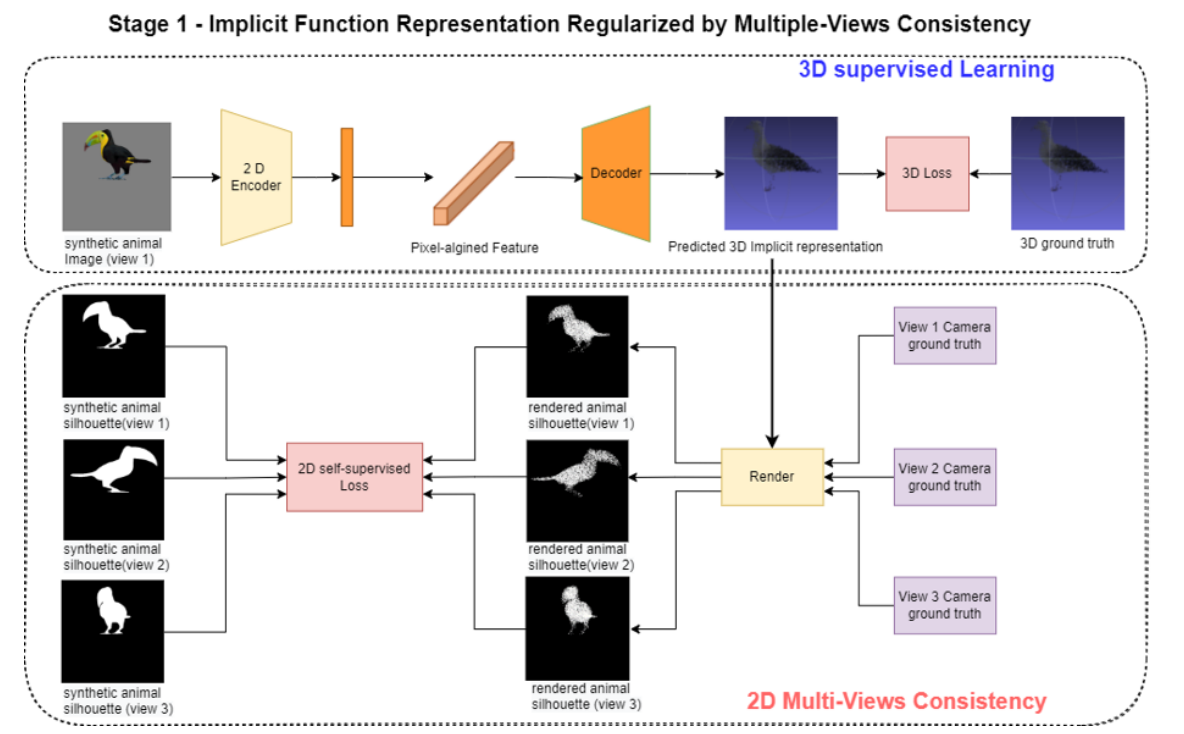
SIFU
SIFU Project Page (river-zhang.github.io)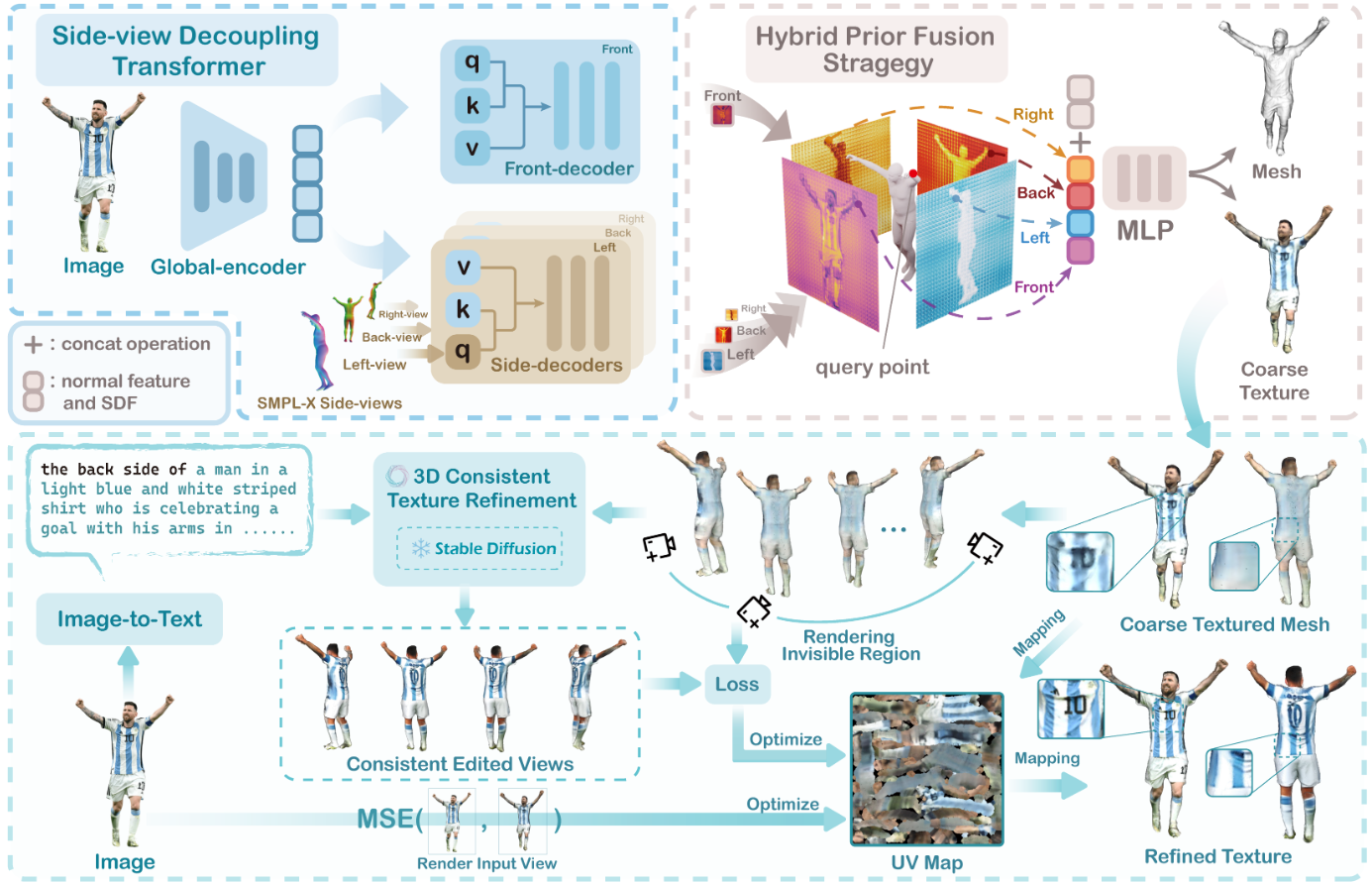
Depth&Normal Estimation
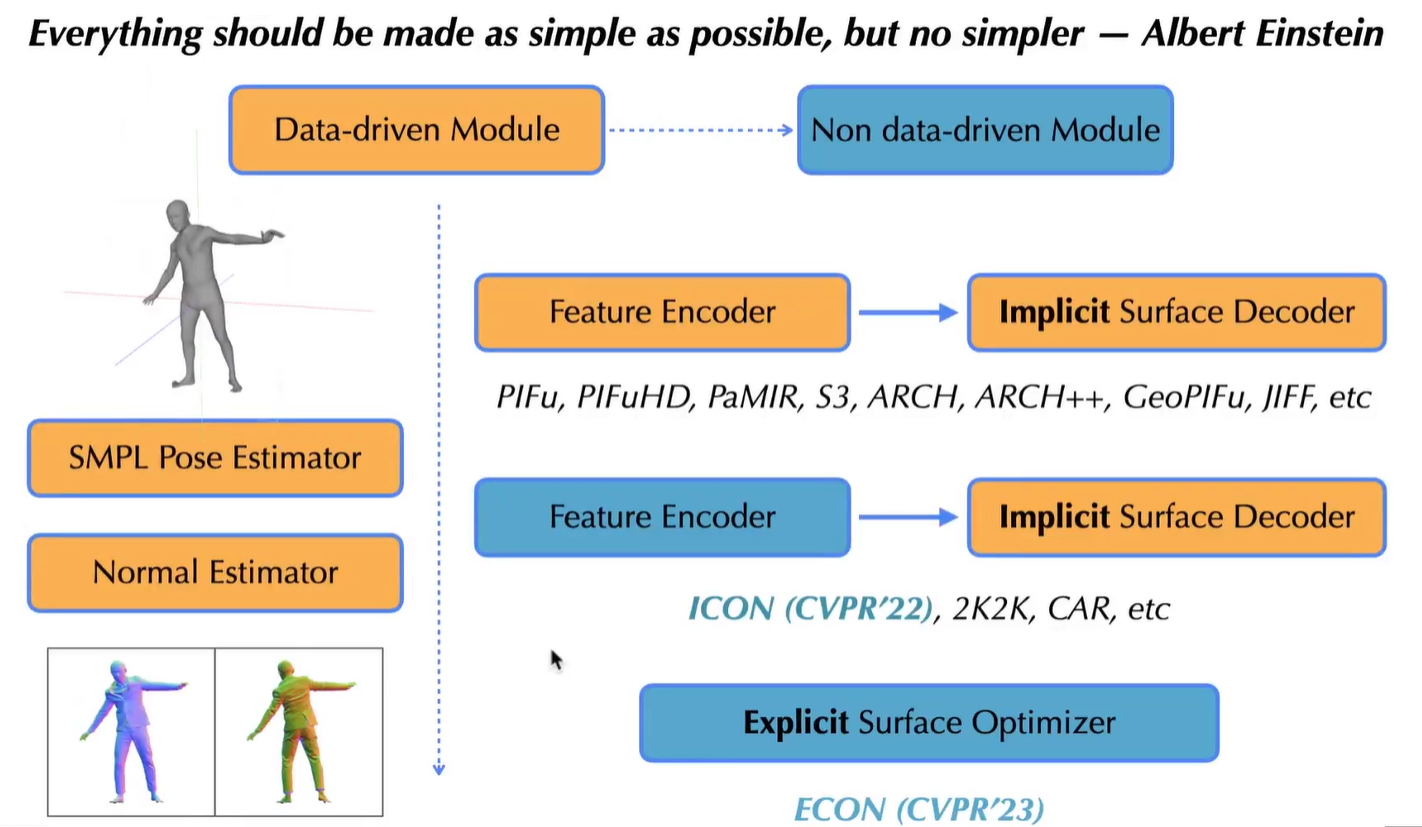
ICON
ICON: Implicit Clothed humans Obtained from Normals
ICON (mpg.de)
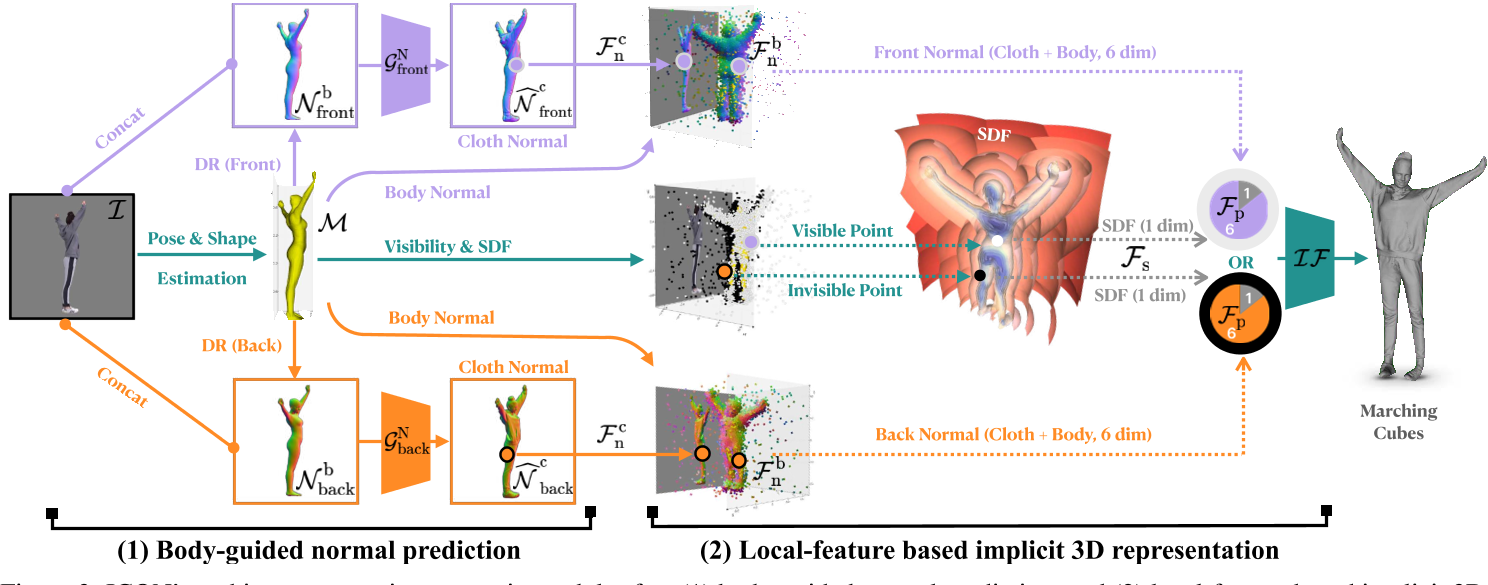
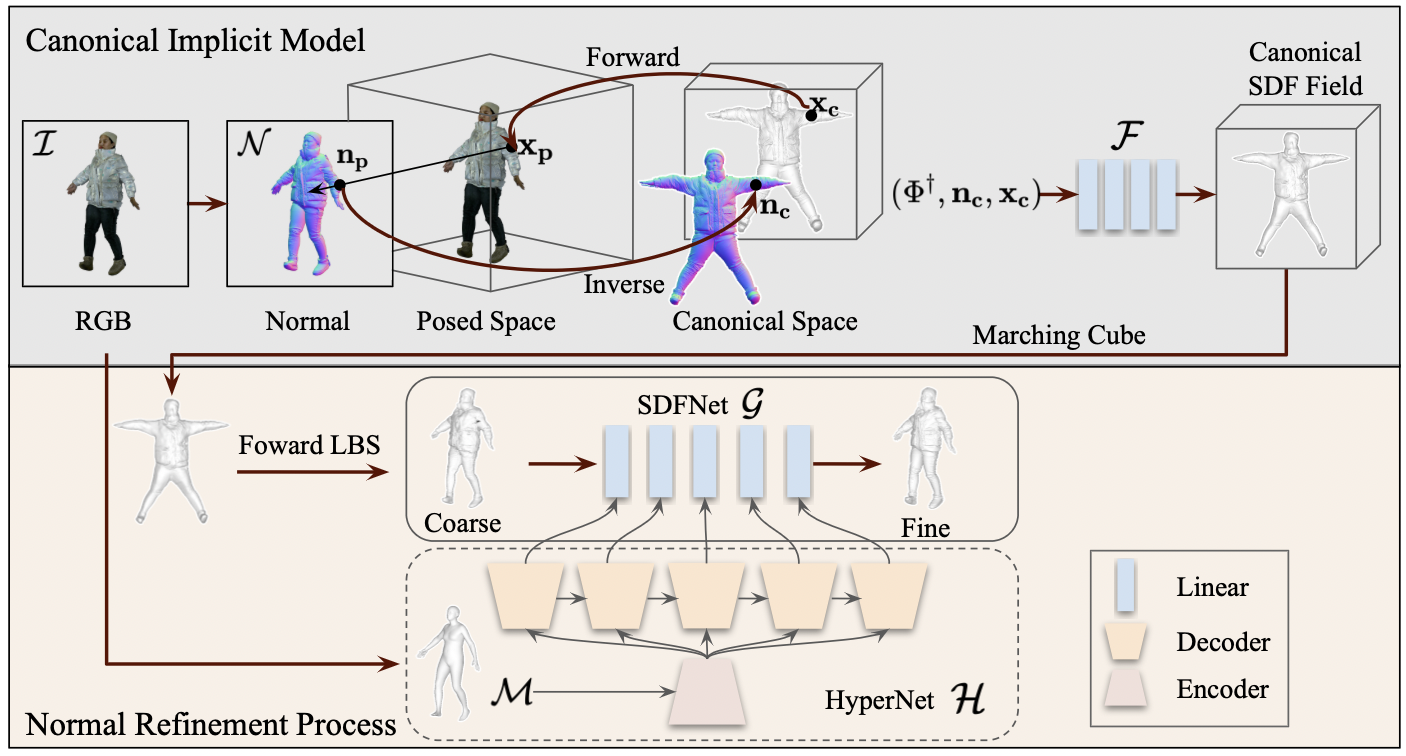
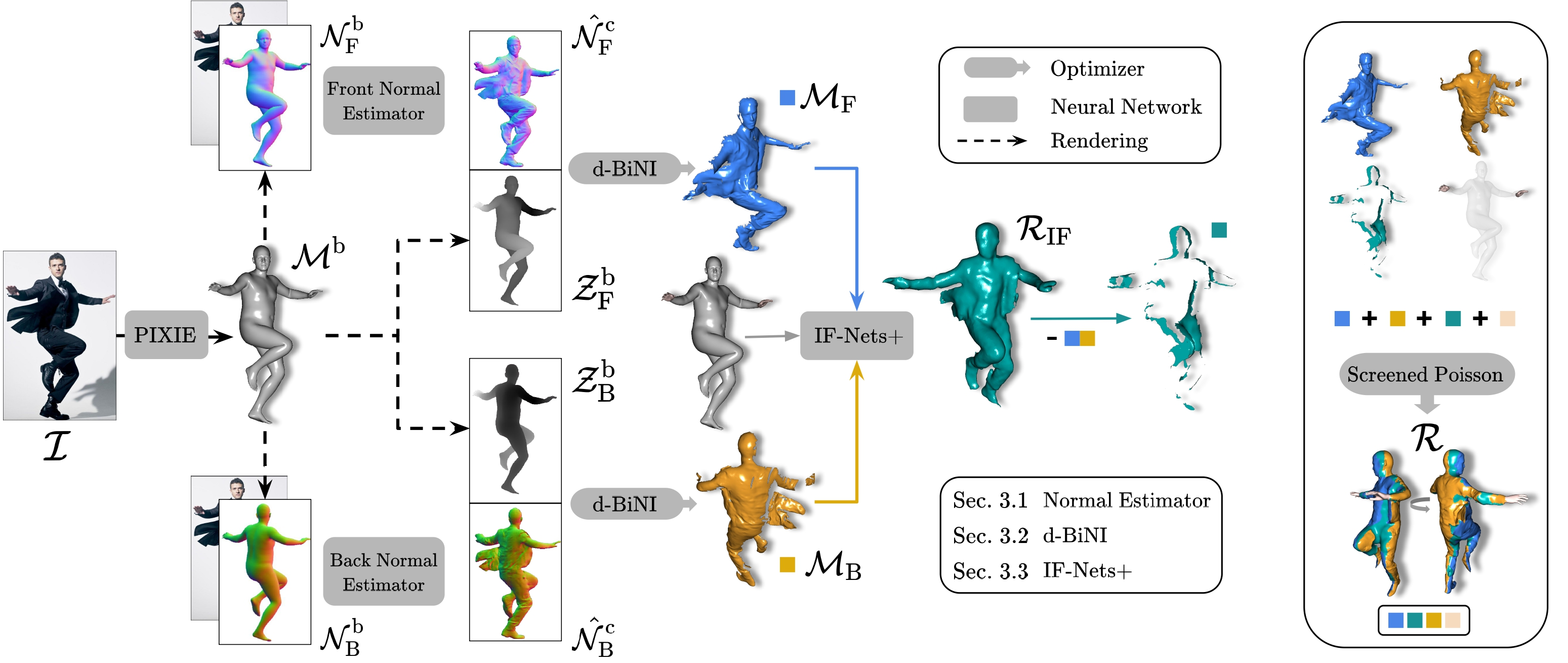
ECON
ECON: Explicit Clothed humans Obtained from Normals
ECON: Explicit Clothed humans Optimized via Normal integration (xiuyuliang.cn)
2K2K
DepthEstimation
2K2K:High-fidelity 3D Human Digitization from Single 2K Resolution Images
High-fidelity 3D Human Digitization from Single 2K Resolution Images Project Page (sanghunhan92.github.io)
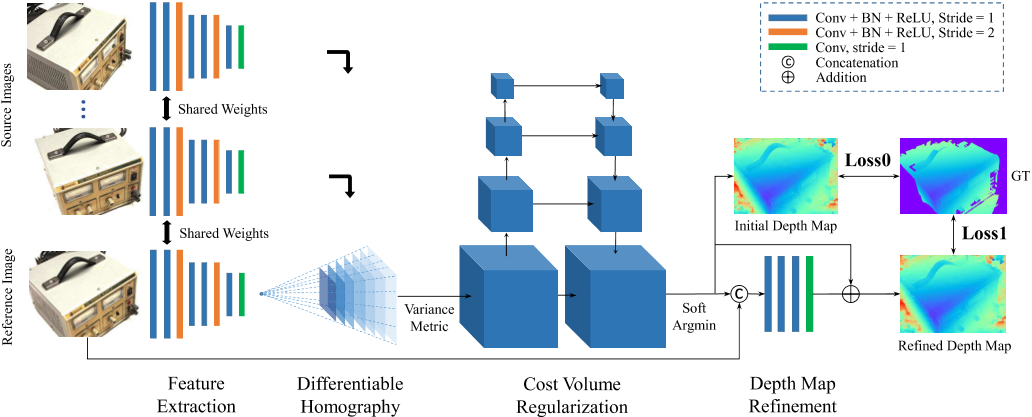
MVSNet
DepthEstimation
MVSNet: Depth Inference for Unstructured Multi-view Stereo
YoYo000/MVSNet: MVSNet (ECCV2018) & R-MVSNet (CVPR2019) (github.com)
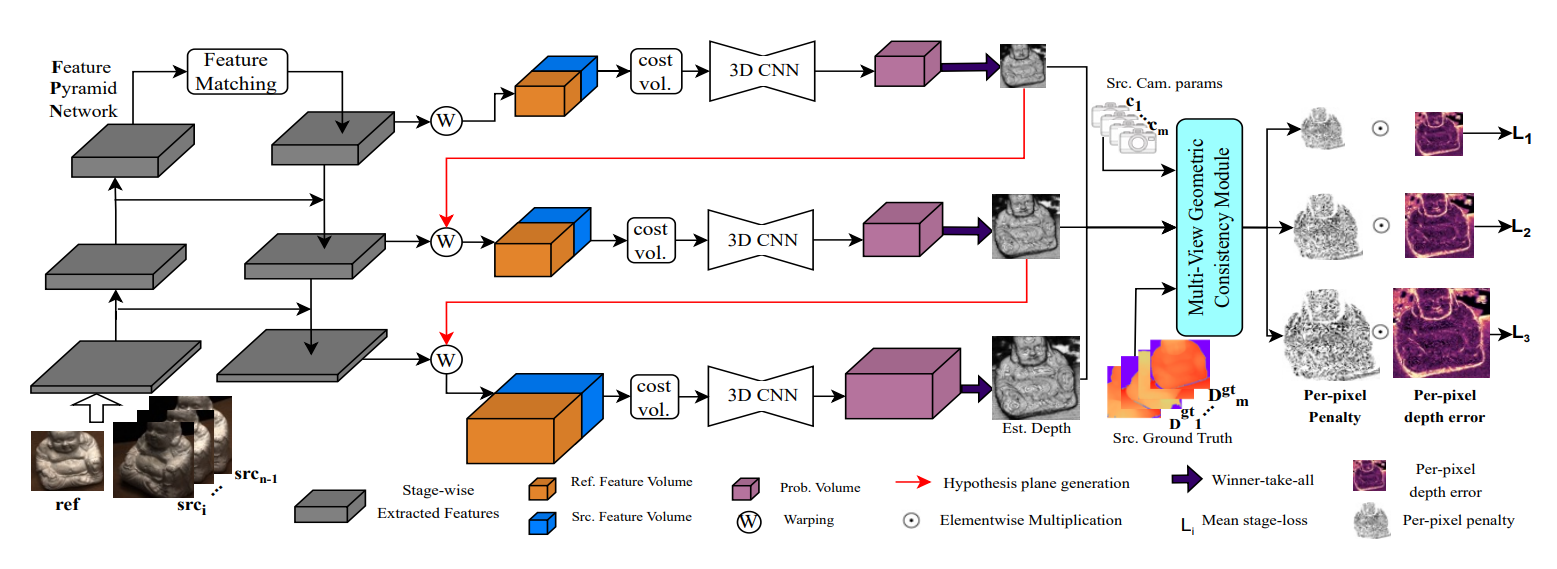
GC-MVSNet
多尺度+多视图几何一致性
GC-MVSNet: Multi-View, Multi-Scale, Geometrically-Consistent Multi-View Stereo (arxiv.org)
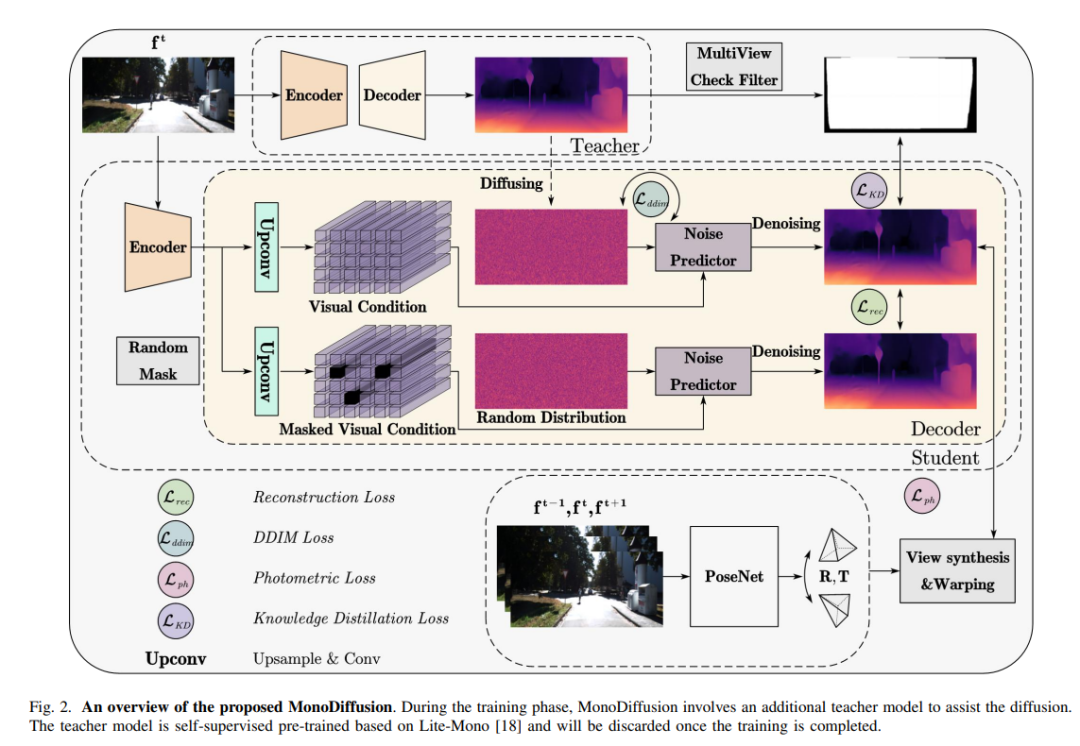
MonoDiffusion
MonoDiffusion: Self-Supervised Monocular Depth Estimation Using Diffusion Model
用 Diffusion Model 进行深度估计(自动驾驶)
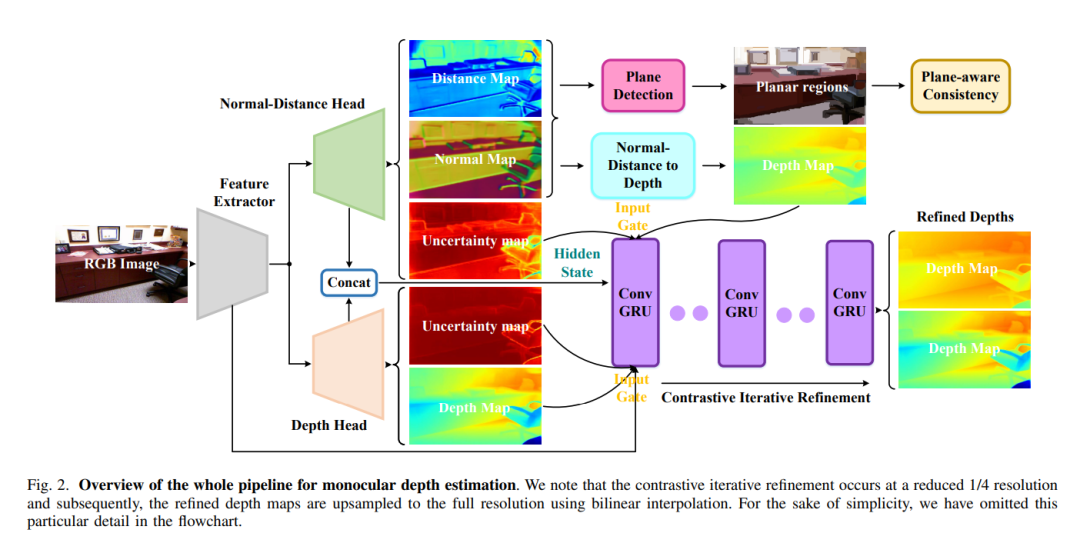
NDDepth
NDDepth: Normal-Distance Assisted Monocular Depth Estimation and Completion
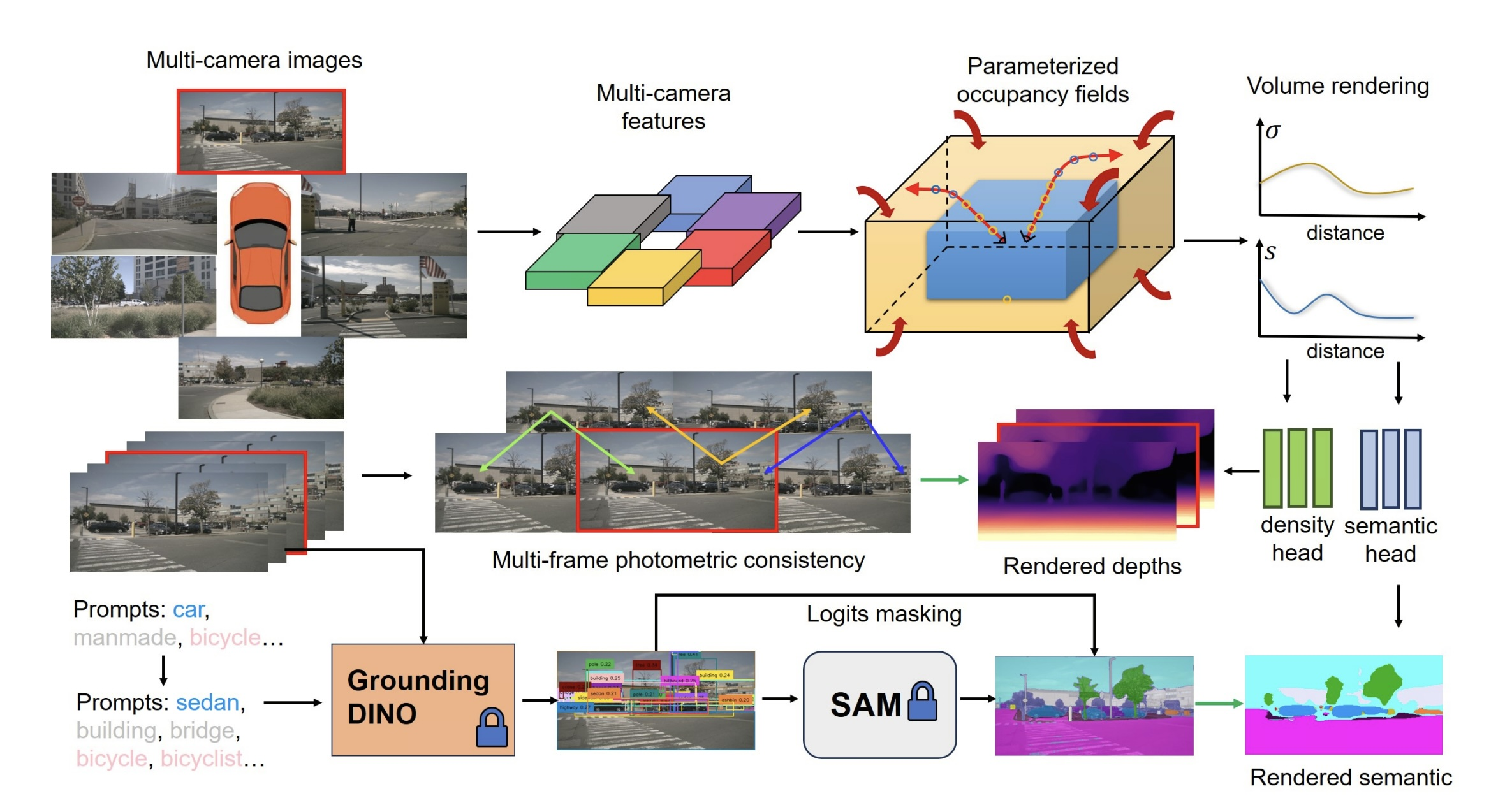
OccNeRF
Other
Texture
Paint3D
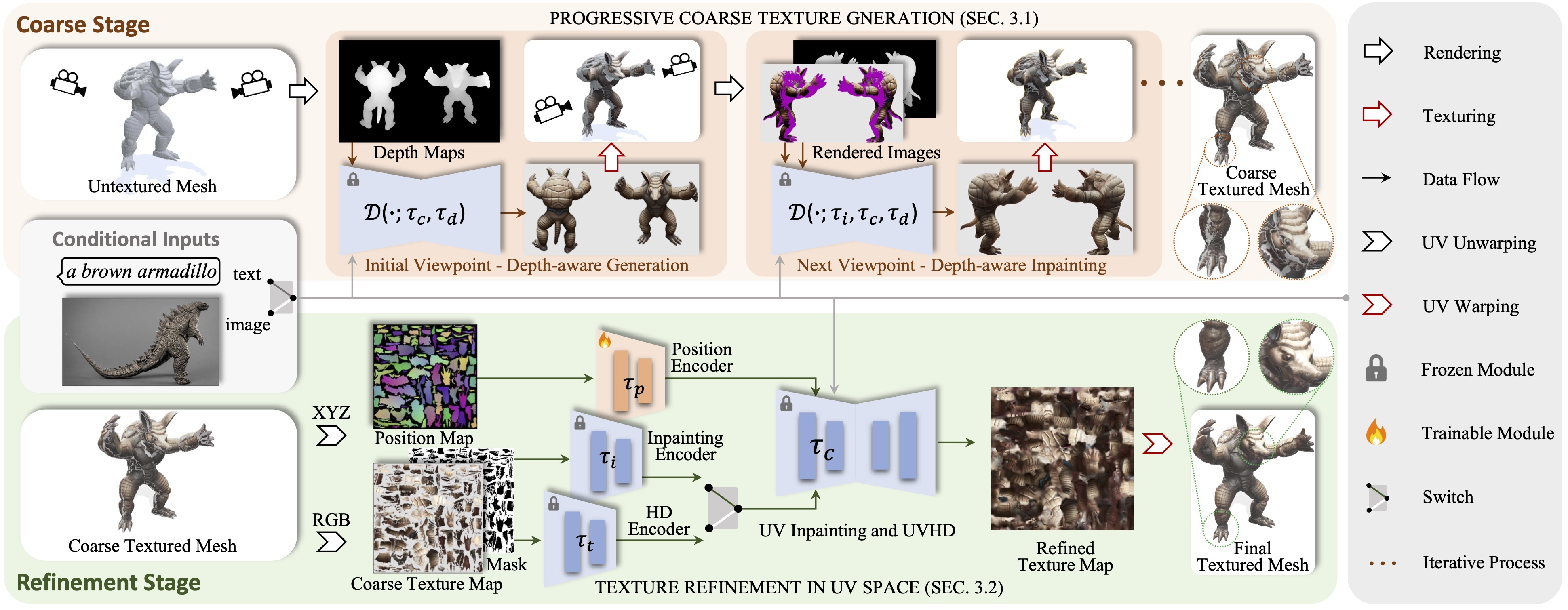
Explicit Template Decomposition
TeCH
TeCH: Text-guided Reconstruction of Lifelike Clothed Humans (huangyangyi.github.io)
DMTet 表示:consists of an explicit body shape grid and an implicit distance field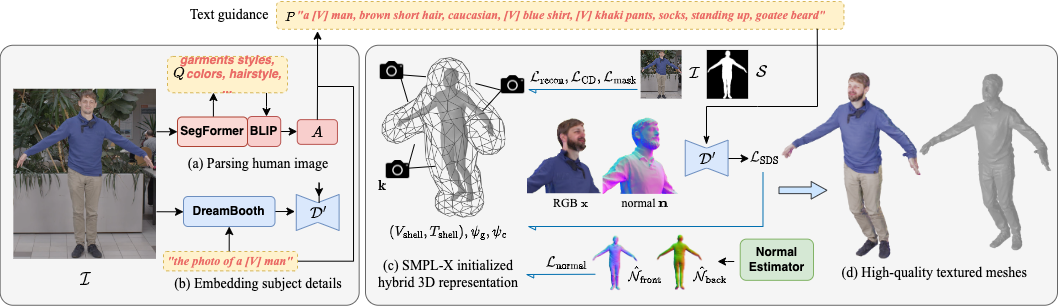
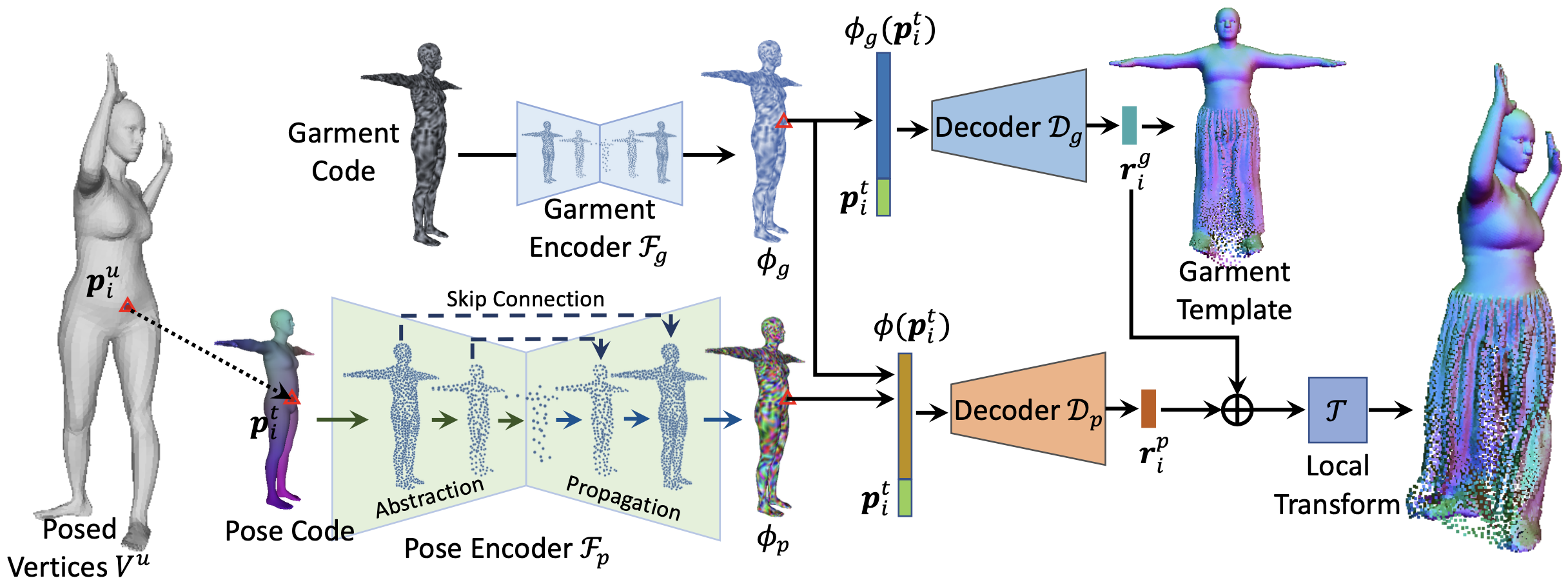
CloSET
CloSET CVPR 2023 (liuyebin.com)
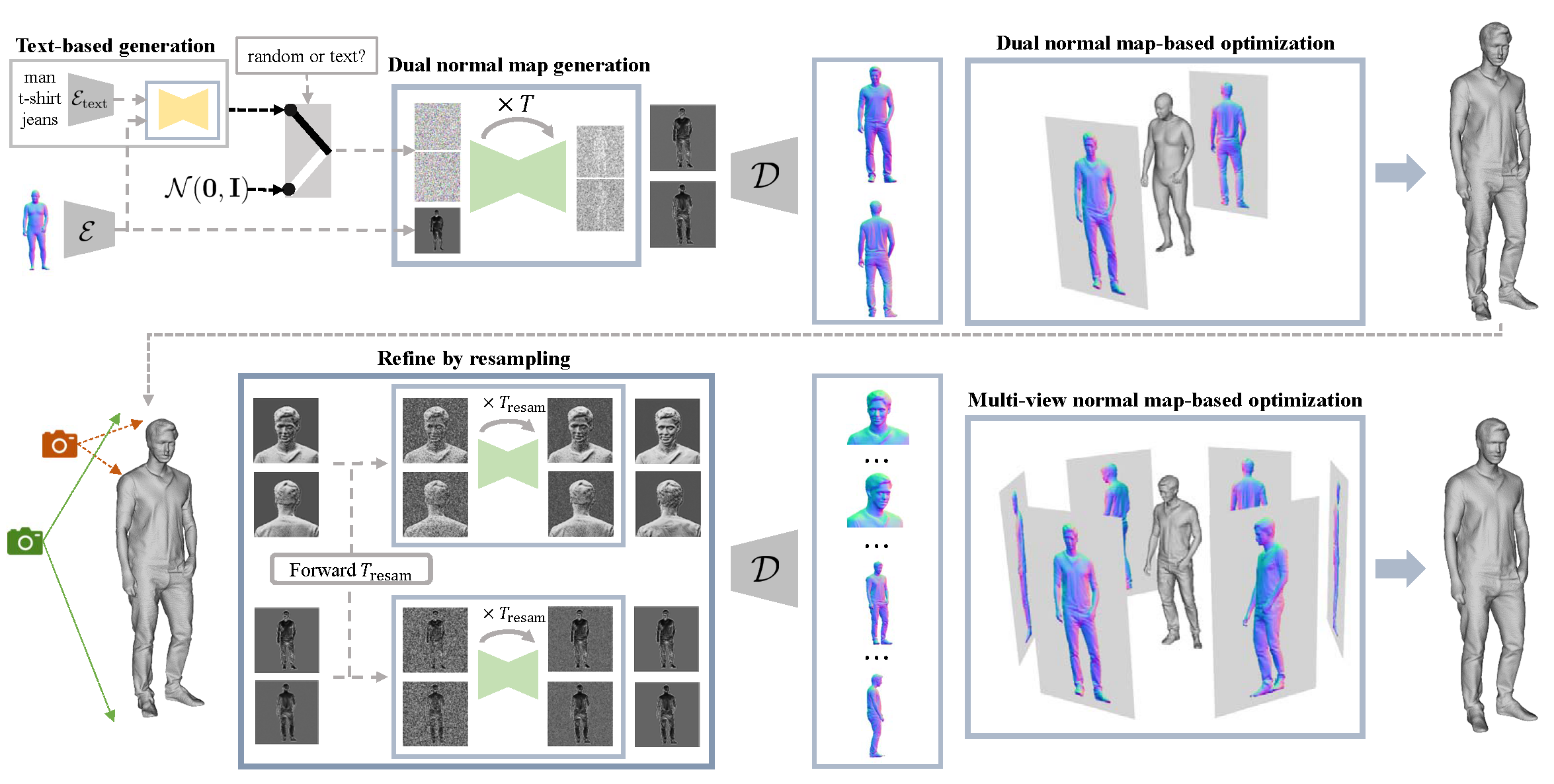
Chupa
Human Face
GPAvatar
xg-chu/GPAvatar: [ICLR 2024] Generalizable and Precise Head Avatar from Image(s) (github.com)
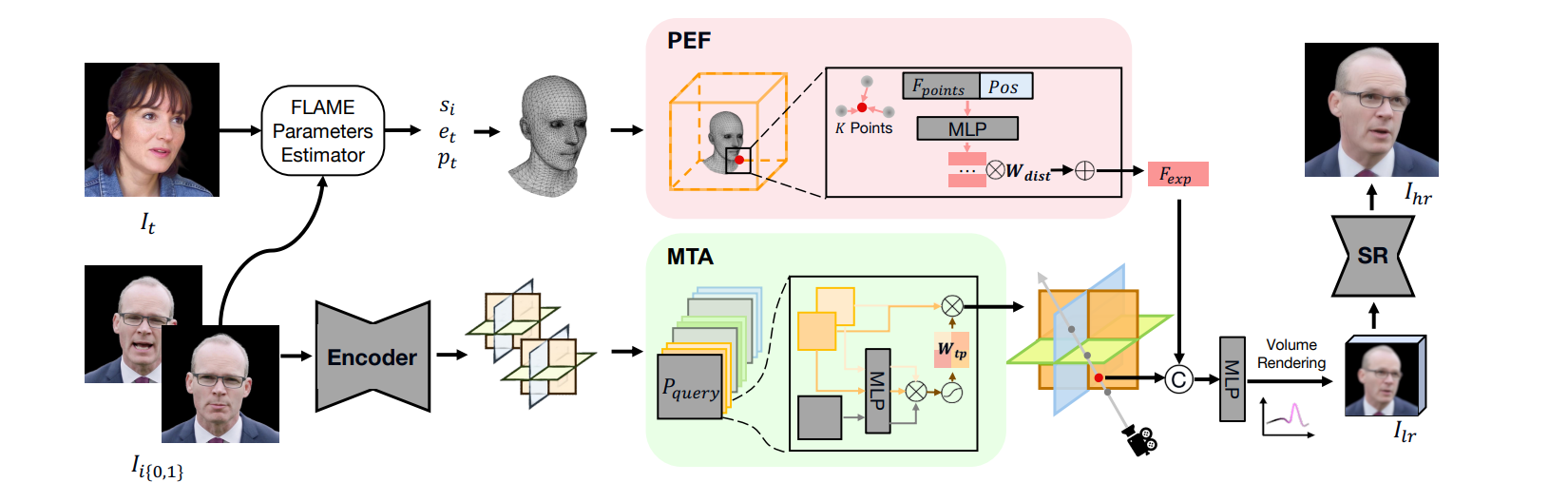
HeadRecon
[2312.08863] HeadRecon: High-Fidelity 3D Head Reconstruction from Monocular Video (arxiv.org)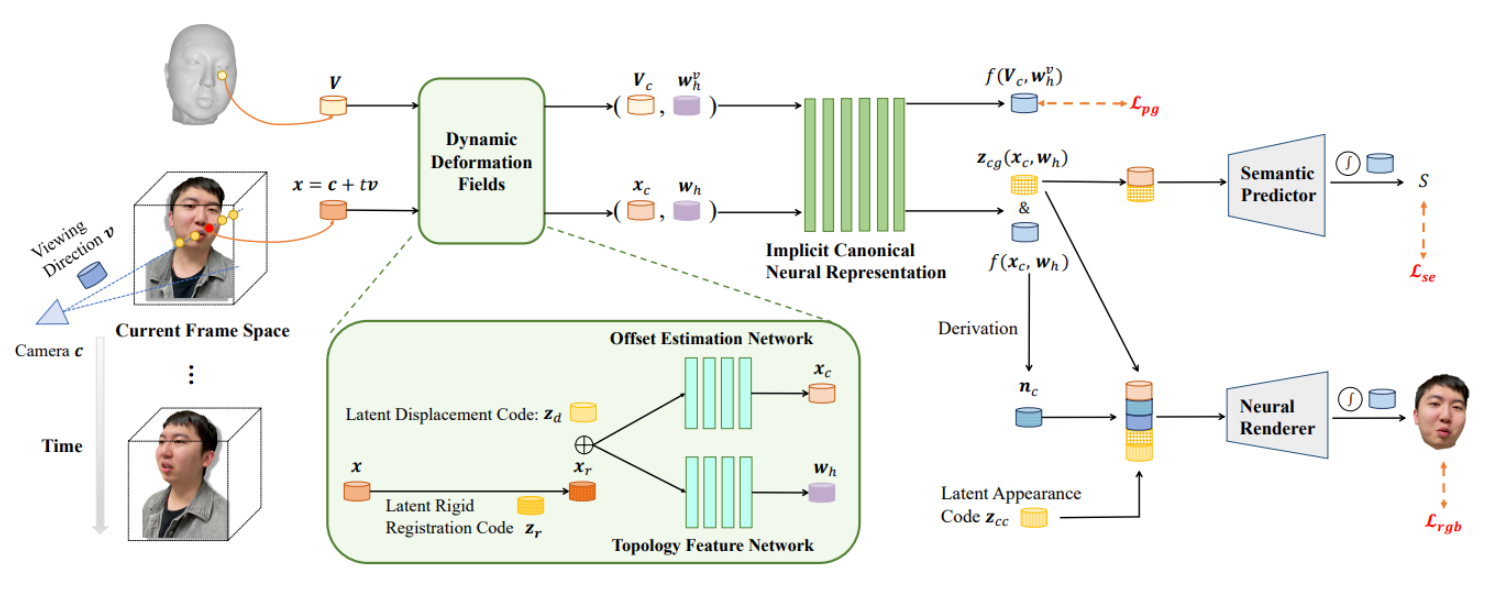
GaussianHead
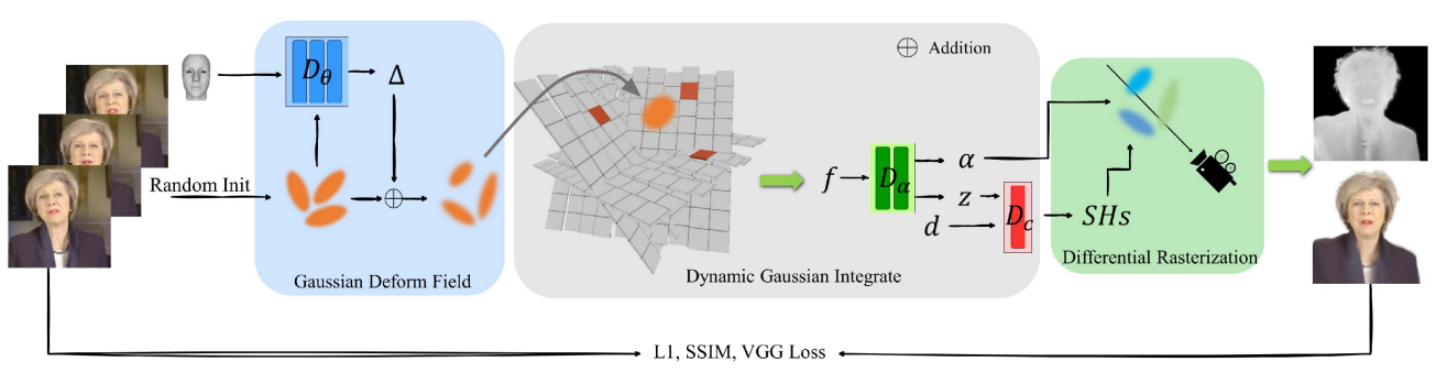
GaussianAvatars
GaussianAvatars: Photorealistic Head Avatars with Rigged 3D Gaussians | Shenhan Qian
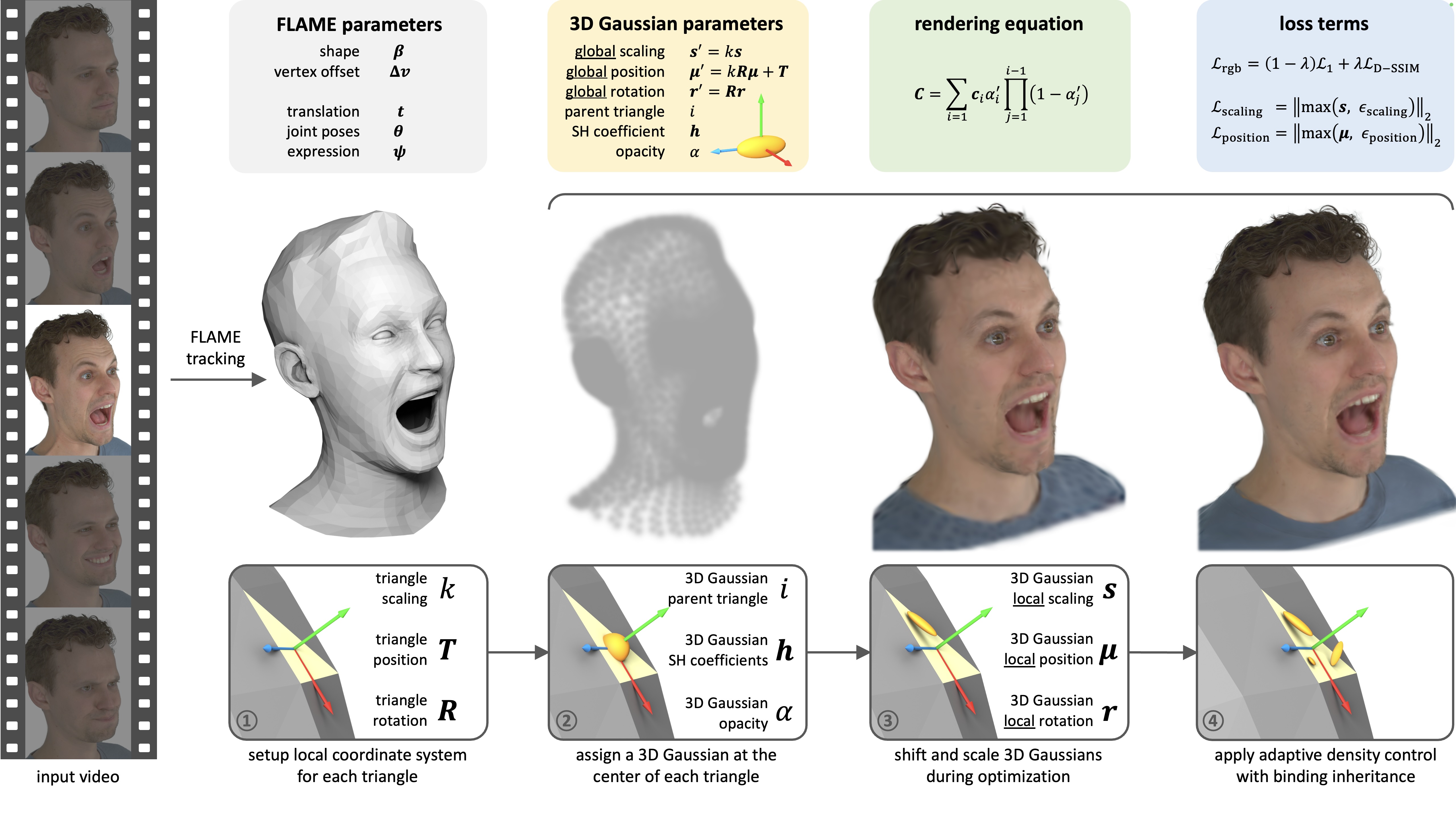
TRAvatar
Towards Practical Capture of High-Fidelity Relightable Avatars (travatar-paper.github.io)
动态人脸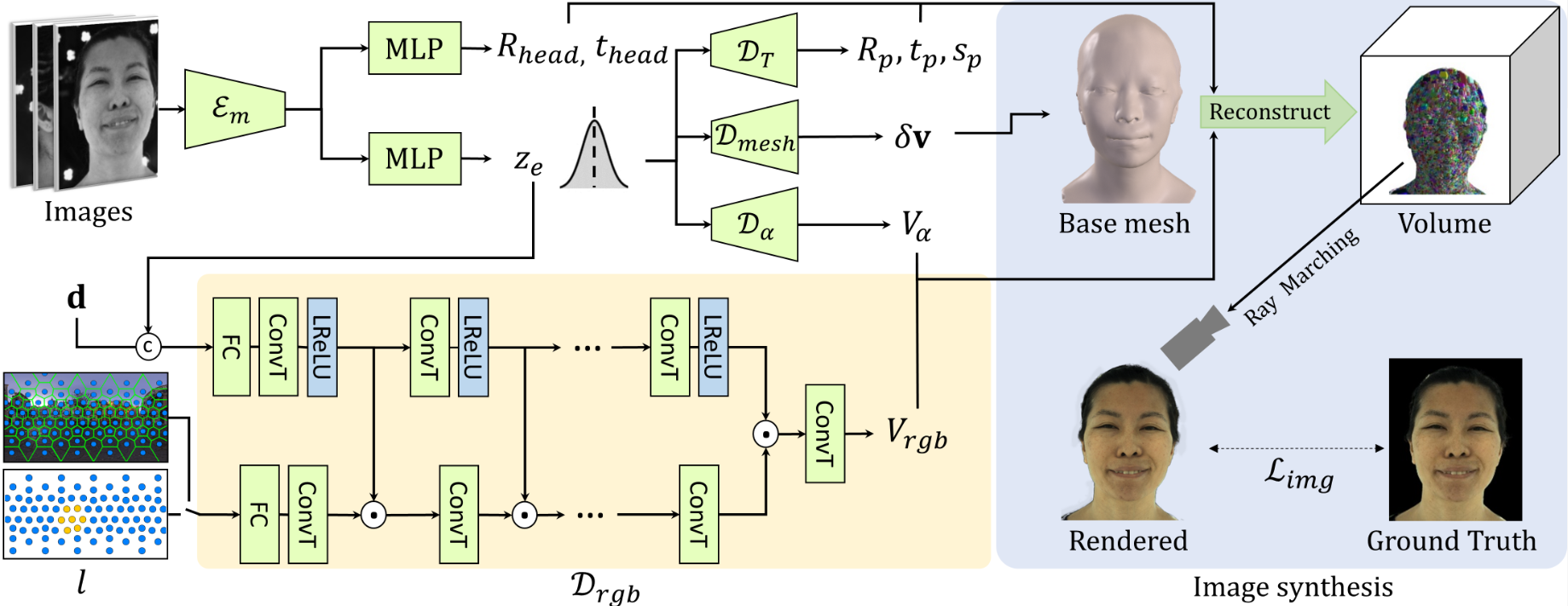
FLARE
FLARE: Fast Learning of Animatable and Relightable Mesh Avatars

HRN
A Hierarchical Representation Network for Accurate and Detailed Face Reconstruction from In-The-Wild Images
HRN (younglbw.github.io)
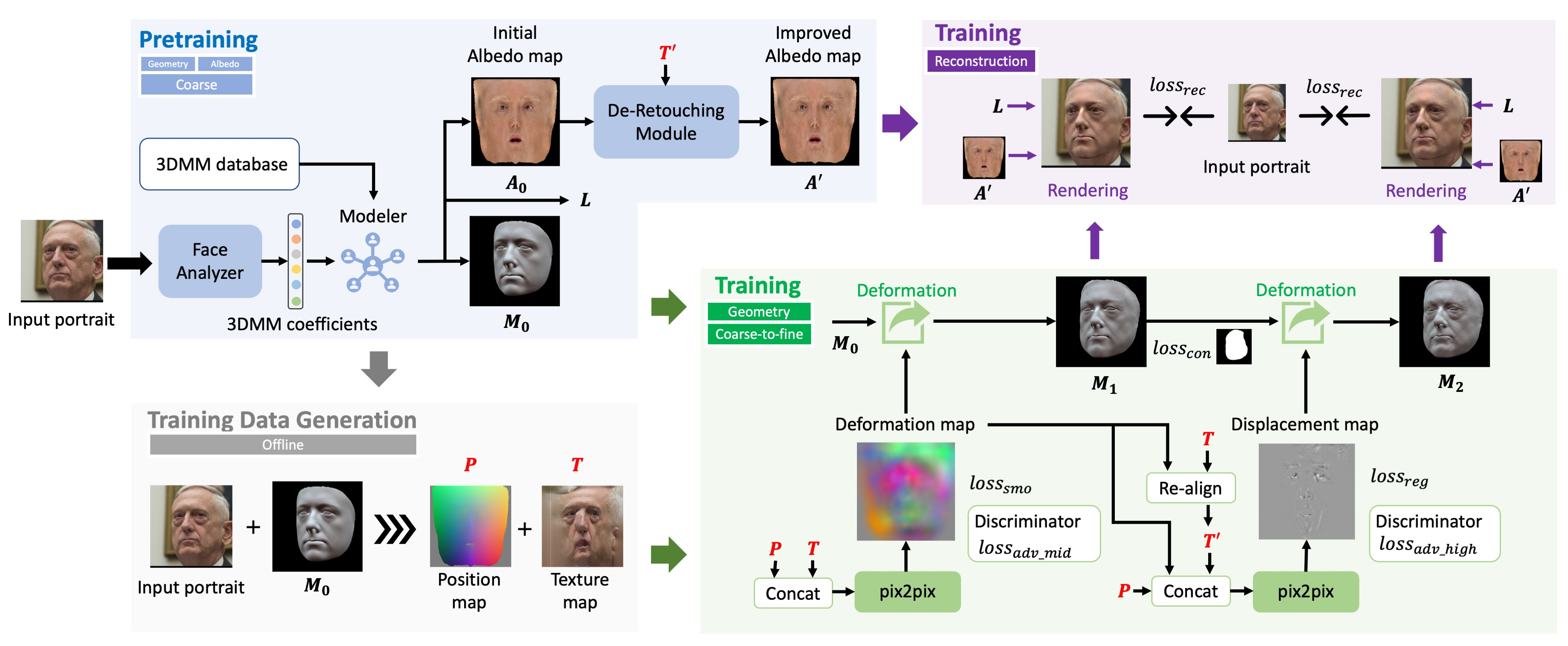
单目 3D 人脸重建
A Perceptual Shape Loss for Monocular 3D Face Reconstruction
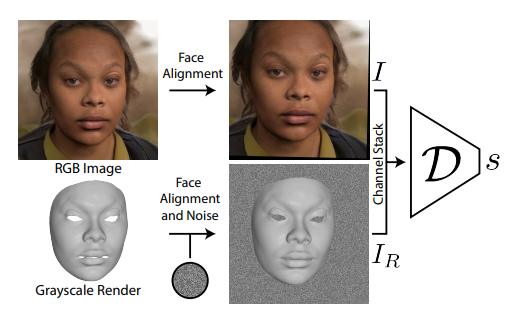
BakedAvatar
BakedAvatar: Baking Neural Fields for Real-Time Head Avatar Synthesis (arxiv.org)
头部实时新视图生成
Video
- 3D-Aware Talking-Head Video Motion Transfer https://arxiv.org/abs/2311.02549
- Portrait4D: Learning One-Shot 4D Head Avatar Synthesis using Synthetic Data (yudeng.github.io)
- DiffusionAvatars: Deferred Diffusion for High-fidelity 3D Head Avatars (tobias-kirschstein.github.io)
- CosAvatar (ustc3dv.github.io)
Segmented Instance/Object
Registered and Segmented Deformable Object Reconstruction from a Single View Point Cloud
Registered and Segmented Deformable Object Reconstruction from a Single View Point Cloud
配准 + 分割物体重建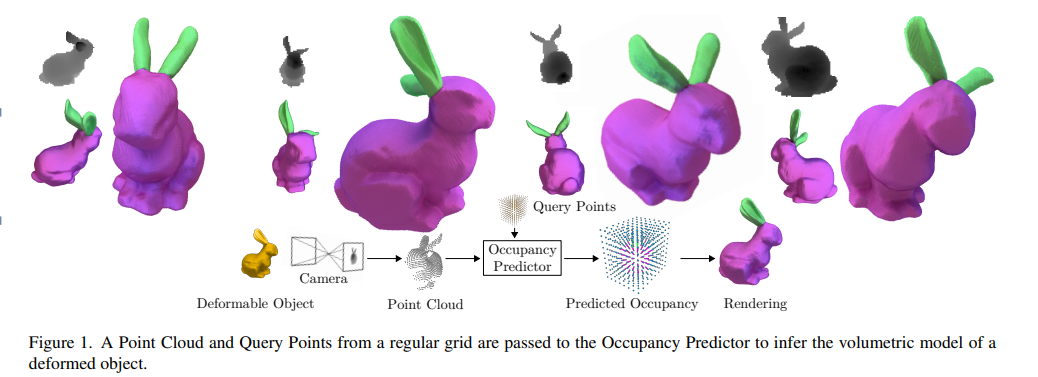
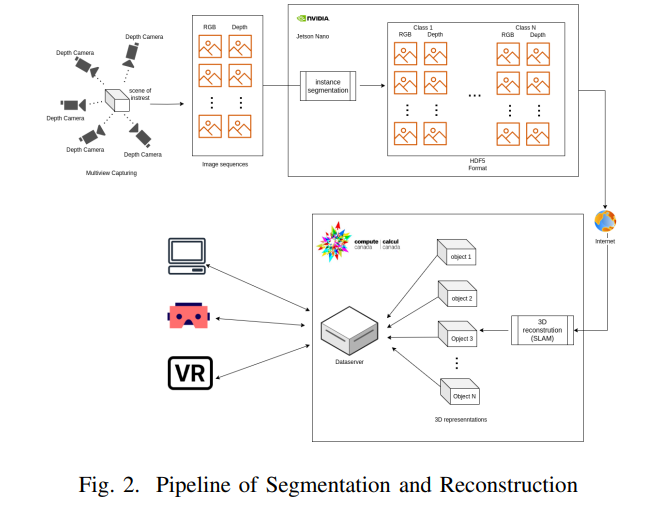
3DFusion, A real-time 3D object reconstruction pipeline based on streamed instance segmented data
3DFusion, A real-time 3D object reconstruction pipeline based on streamed instance segmented data
Human Body Shape Completion
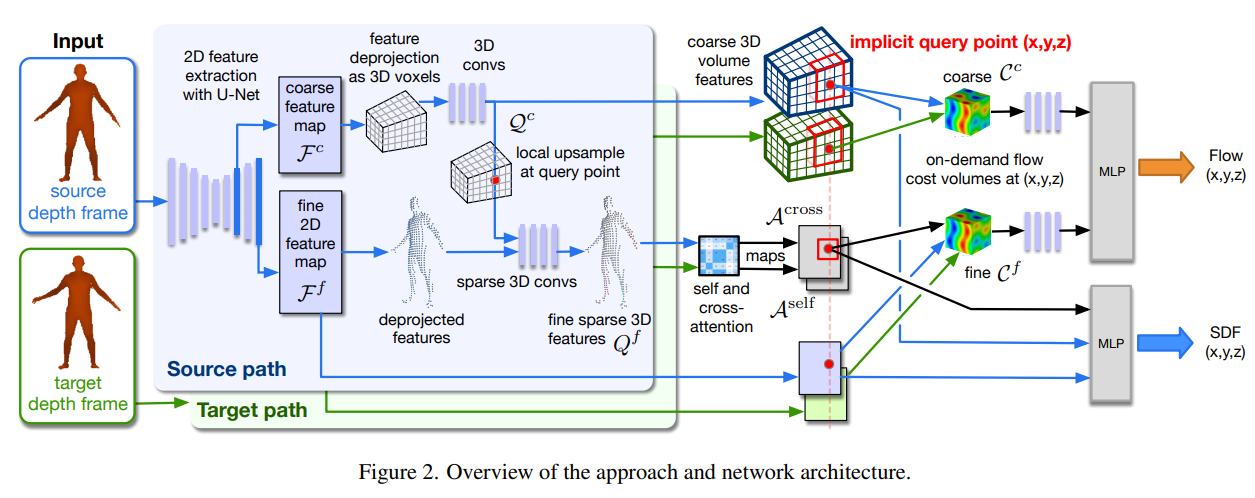
Human Body Shape Completion With Implicit Shape and Flow Learning (thecvf.com)
Incomplete Image
Complete 3D Human Reconstruction from a Single Incomplete Image
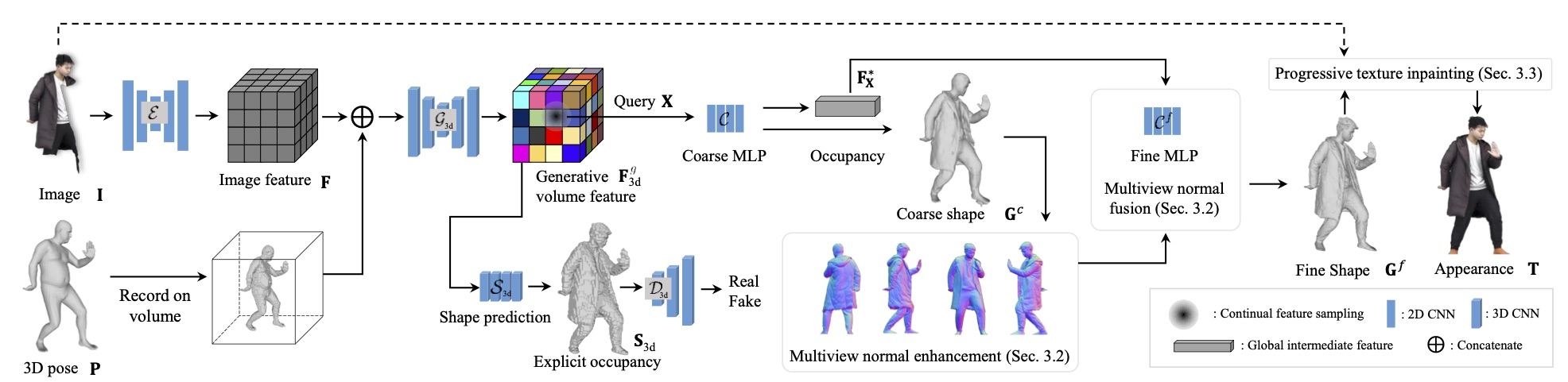
Complete 3D Human Reconstruction from a Single Incomplete Image (junyingw.github.io)
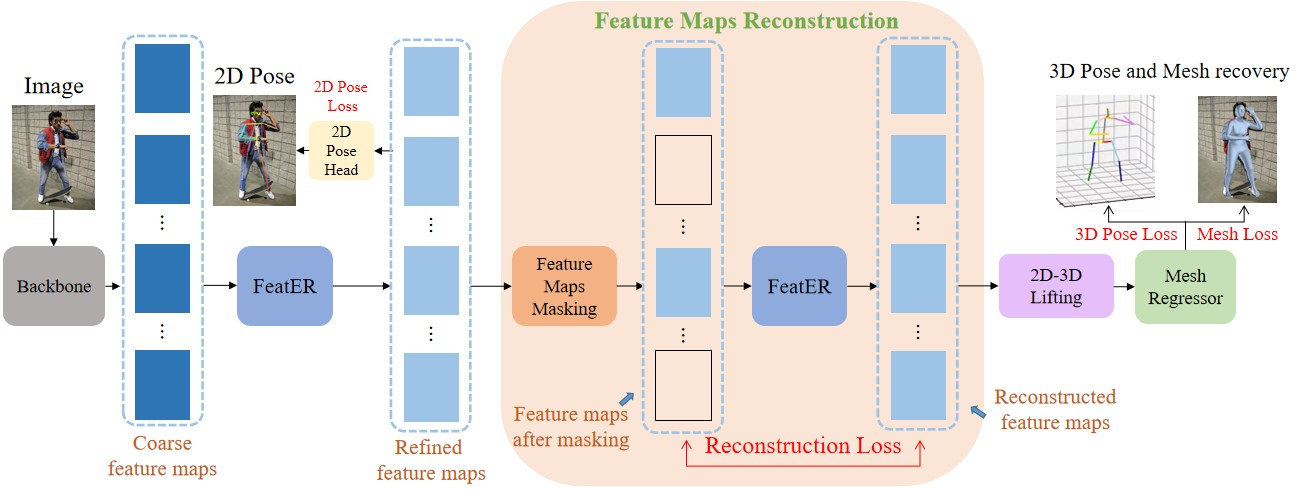
New NetWork FeatER
HF-Avatar
hzhao1997/HF-Avatar (github.com)
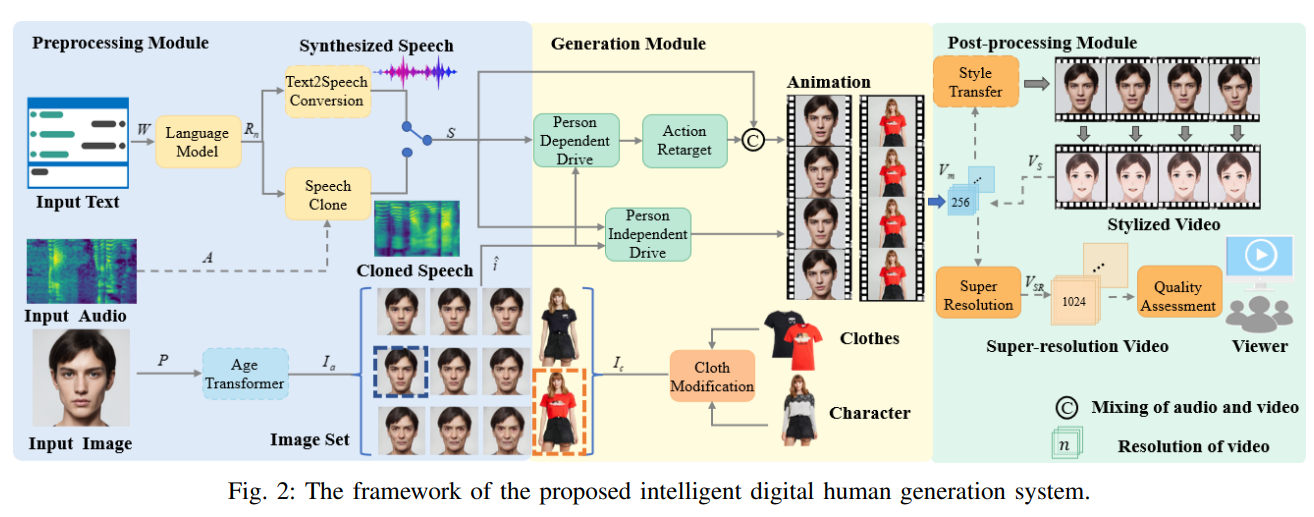
多模态数字人生成(数字人视频)
An Implementation of Multimodal Fusion System for Intelligent Digital Human Generation
输入:文本、音频、图片
输出:自定义人物视频(图片/+修改/+风格化)+音频(文本合成+音频音色参考)
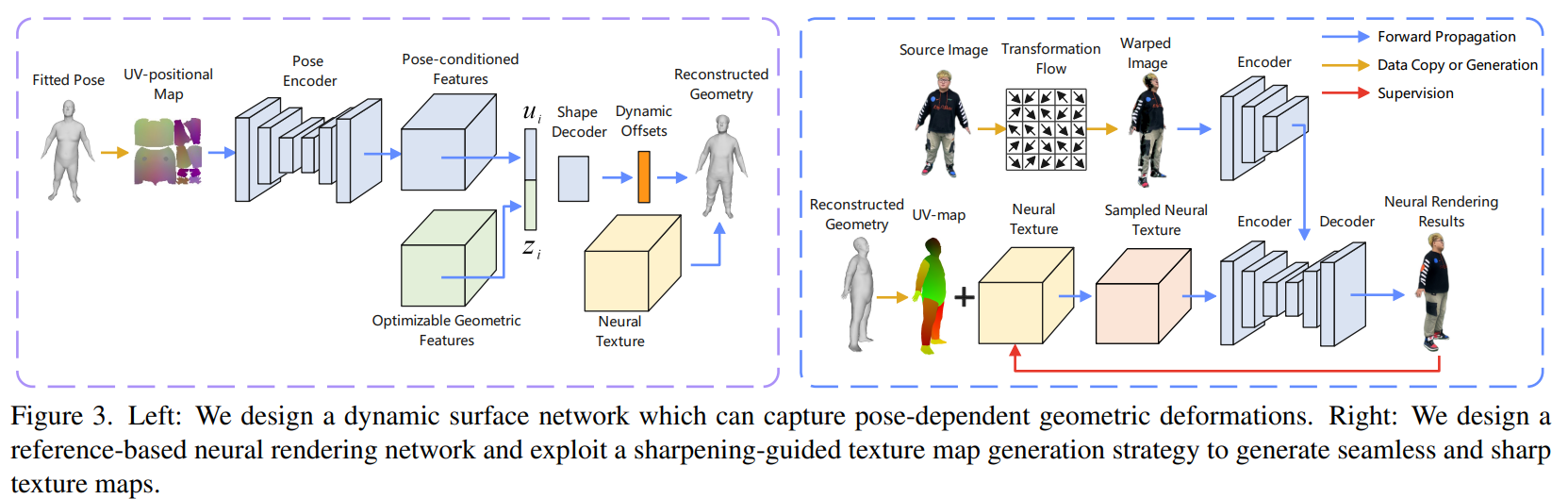
IPVNet