| Title | High-fidelity 3D Human Digitization from Single 2K Resolution Images |
|---|---|
| Author | Sang-Hun Han1, Min-Gyu Park2, Ju Hong Yoon2,Ju-Mi Kang2, Young-Jae Park1, and Hae-Gon Jeon1 |
| Conf/Jour | CVPR 2023 Highlight |
| Year | 2023 |
| Project | High-fidelity 3D Human Digitization from Single 2K Resolution Images Project Page (sanghunhan92.github.io) |
| Paper | High-fidelity 3D Human Digitization from Single 2K Resolution Images (readpaper.com) |
可以看成一种估计深度图的方法
缺点:需要好的数据集
- 需要提供法线图、mask、深度图(低分辨率+高分辨率)
- 需要人体模型的关节点信息
- 无法预测自遮挡部位
- 对低分辨率重建效果不好
Abstract
高质量的3D 人体重建需要高保真度和大规模的训练数据,以及有效利用高分辨率输入图像的适当网络设计。为了解决这些问题,我们提出了一种简单而有效的3D 人体数字化方法,称为2K2K,它构建了一个大规模的2K 人体数据集,并从2K 分辨率图像推断3D 人体模型。所提出的方法分别恢复了人体的全局形状和细节。低分辨率深度网络从低分辨率图像中预测全局结构,而部分图像到法线网络则预测3D 人体结构的细节。高分辨率深度网络合并全局3D 形状和详细结构,以推断高分辨率的前后侧深度图。最后,一个现成的网格生成器重建完整的3D 人体模型,可在获得。此外,我们还提供了2,050个3D 人体模型,包括纹理地图、3D 关节和 SMPL 参数,供研究目的使用。在实验中,我们展示了在各种数据集上与最新工作相比的竞争性性能。https://github.com/SangHunHan92/2K2K
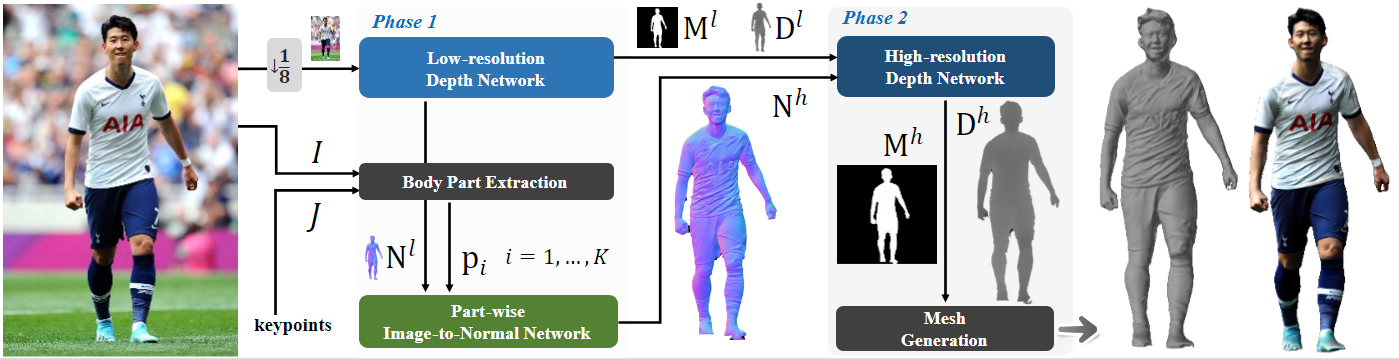
Method
分为两个阶段:
- Stage1 Loss:
- 使用 L1 损失和 LSSIMloss 来优化图像到法线网络
- GT:低分辨率法线图,高分辨率法线图
- 通过最小化平滑 L1 损失 Ls1 和二元交叉熵损失 LBCE 的线性组合来训练深度网络
- GT:低分辨率深度图,低分辨率法线图,低分辨率 Mask
- 使用 L1 损失和 LSSIMloss 来优化图像到法线网络
- Stage2 Loss:冻结阶段 1 训练的网络,并训练高分辨率深度生成器
- 使用 Lsl1 和 LBCE 来优化高分辨率深度网络
- GT:高分辨率深度图,高分辨率法线图,高分辨率 Mask
- 使用 Lsl1 和 LBCE 来优化高分辨率深度网络
最终得到的是双面的高分辨率深度图,通过深度图获取点云,然后预测法线,最后通过 a screened Poisson surface construction 来得到 mesh
具体流程:
预测低分辨率法向量图和深度图,$\hat M$ 为预测出的 mask
$\mathbf{D}^l=\hat{\mathbf{D}}^l\odot\hat{\mathbf{M}}^l$, $\hat{\mathbf{D}}^l,\hat{\mathbf{M}}^l,\mathbf{N}^l=G^l_{\mathbf{D}}(I^l)$
预测高分辨率 part 法向量图,M 为变换矩阵
$\bar{\mathbf{n}}_i=G_{\mathbf{N},i}(\bar{\mathbf{p}}_i,\mathbf{M}_i^{-1}\mathbf{N}^l)$, $\bar{\mathbf{p}}_i=\mathbf{M}_i\mathbf{p}_i,$
拼接为高分辨率整体法向量图
$\mathbf{N}^h=\sum\limits_{i=1}^K\left(\mathbf{W}_i\odot\mathbf{n}_i\right)$ ,$\mathbf{n}_i=\mathbf{M}_i^{-1}\bar{\mathbf{n}}_i$
预测高分辨率深度图
$\mathbf{D}^h=\hat{\mathbf{D}}^h\odot\hat{\mathbf{M}}^h$,$\hat{\mathbf{D}}^h,\hat{\mathbf{M}}^h=G^h_{\mathbf{D}}(\mathbf{N}^h,\mathbf{D}^l)$
深度图转点云
低分辨率深度网络
低分辨率深度网络分别预测低分辨率深度和法向图,使用 dual-encoder AU-Net (D-AU-Net)网络, ref: Monocular Human Digitization via Implicit Re-projection Networks (readpaper.com)
Body part extraction和Part-wise normal prediction
Body part extraction 和 Part-wise normal prediction预测高分辨率双面法向 map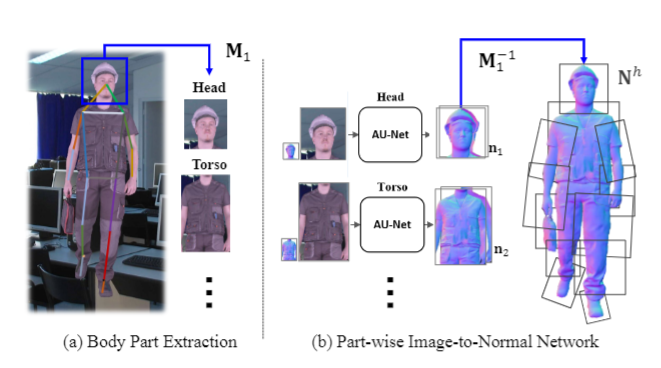
- 将人体按照 keypoint 关节分成 patches,每个 patches 和 low 分辨率法线图来预测 high 分辨率双面法线 map
- 只需训练头、躯干、手臂、腿和脚这 5 个法线预测网络 AU-Net,然后即可预测每个 patch
- Attention U-Net: Learning Where to Look for the Pancreas (readpaper.com)
高分辨率深度预测网络
高分辨率深度预测网络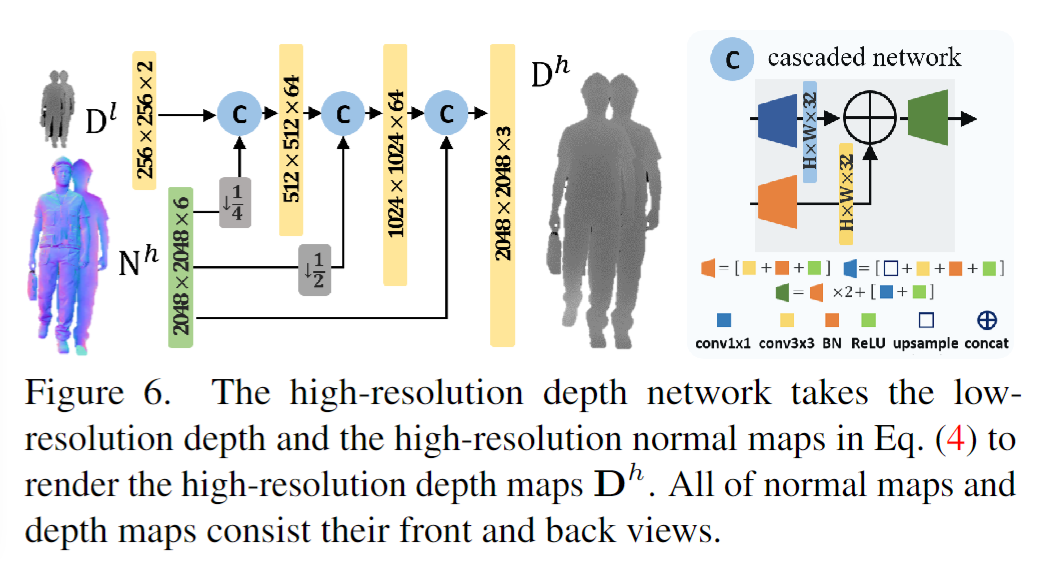
网格生成:从深度图生成 3D 模型有多种方法。在这项工作中。我们采用与[13]类似的方法。我们将深度图转换为 3D 点云,然后从相邻点计算每个点的表面法线。之后,我们运行一个筛选的泊松曲面构造[22]来获得平滑的人体网格 V。
权重计算方法
来源:2K2K Code
目的:part 法向量图 —> 原图大小对应法向量图
根据 part 法向量图逆仿射变换回原图空间 $\mathbf{n}_{i}=\mathbf{M}_{i}^{-1}\mathbf{\bar{n}}_{i}$
要将 part 法向量图融合为原图空间法向量图,每个法向量图有不同的权重$\mathbf{N}^h\quad=\sum\limits_{i=1}^K\left(\mathbf{W}_i\odot\mathbf{n}_i\right)$
权重的计算方法:
- 同时与 part 法向量图逆仿射变换的还有一个 Occupancy Grid Map O,表示在原图空间中每个 part 的占用值 0 或者 1,i.e. $\left.\phi_i(x,y)=\left\{\begin{array}{cc}1&\text{if}&\sum\mathbf{n}_i(x,y)\neq\mathbf{0}^\top\\0&\text{otherwise}\end{array}\right.\right.$
- 对 O 做高斯模糊 GaussianBlur,使得 O map 的值到边缘逐渐减小
- 如下图,face part 脖子上方中心处 O 值做完高斯模糊后依然近似 1(假设 1),而 body part 上部分脖子中心处做完高斯模糊后 O 值<1(假设 1/2),这会导致对于脖子这部分多 part 融合时,face part normal 的权重相对于 body part normal 的权重会更大一点(2/3 > 1/3)
Datasets
- 新的数据集:我们的数据集提供了高保真的 3D 人体模型,由 80 个 DSLR 相机、纹理贴图、3D 姿势(openpifpafw 全身)和 SMPL 模型参数捕获。
- 2,050 个 scan 3D 模型
- Skinned Multi-Person Linear (SMPL)
Booth 中一共 80 个 DSLR:每个条上 5 个相机,从上到下依次对齐:人头、上身、中部、下身、膝盖。
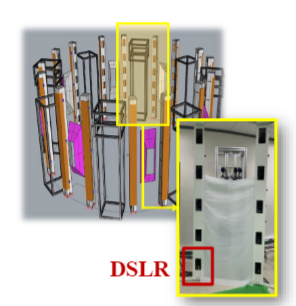
使用商业化软件 RealityCapture 生成初始粗糙的人体模型,然后专家手动对模型进行后处理(填充孔洞、头发几何细节)。已发布模型的顶点数约为 1M,其示例如图 2 (b) 所示。扫描模型正确地保留了手指和皱纹等几何细节,主要是因为在受控环境中捕获的高质量图像。

合成的 Rendered Image(使用 Unity、Unreal 等软件)
Experiments
在四个 RTX A6000 GPU 上训练3天
Ubuntu 20.04 with Python 3.8, PyTorch 1.9.1 and CUDA 11.11
2
3apt-get install -y freeglut3-dev libglib2.0-0 libsm6 libxrender1 libxext6 openexr libopenexr-dev libjpeg-dev zlib1g-dev
apt install -y libgl1-mesa-dri libegl1-mesa libgbm1 libgl1-mesa-glx libglib2.0-0
pip install -r requirements.txt
Fast test
1 | cd checkpoints && wget https://github.com/SangHunHan92/2K2K/releases/download/Checkpoint/ckpt_bg_mask.pth.tar && cd .. |
1 | python test_02_model.py --load_ckpt ckpt_bg_mask.pth.tar --save_path ./exp |
Custom test1
2
3
4
5
6
7
8bin\OpenPoseDemo.exe --image_dir test_folder --write_json test_folder --hand --write_images test_folder\test --write_images_format jpg
python test_02_model.py --load_ckpt ckpt_bg_mask.pth.tar --save_path ./exp --data_path ./test_folder --save_name ???
python test_03_poisson.py --save_path ./exp --save_name ???
bin\OpenPoseDemo.exe --image_dir test_2 --write_json test_2 --hand --write_images test_2\test --write_images_format jpg
...
Render
1 | data |
Data folder
- Obj
- 2K2K
- 00003
- 00003.Ply
- 00003
- 2K2K
- PERS
- COLOR
- NOSHADING
2K2K_0_y_-30_x- 00003_front.Png
- 00003_back.Png
2K2K*0_y*-20_x- …
2K2K_0_y_30_x
- SHADED
2K2K_0_y_-30_x- 00003_front.Png
- …
- NOSHADING
- DEPTH
2K2K_0_y_-30_x- 00003_front.Png
- 00003_back.Png
- …
- COLOR
- ORTH
- COLOR
- NOSHADING
- SHADED
- DEPTH
- COLOR
如果不算 ORTH:共 21+14=35 张图片
Render image
1 | pers2pc(image_front, front_depth.astype(np.float64) / 32.0, 2048, 50) |
1 | python render/render.py --data_path ./data --data_name 2K2K |
Get : PERS/COLOR and PERS/DEPTH
Render keypoint
1 | unzip data/Joint3D.zip -d data/Joint3D/ |
Get : PERS/keypoint
Train
Phase1 大概需要 7 天, (单张 3090)
1 | python train.py --data_path ./data --phase 1 --batch_size 1 |
Limitations
由于我们明确地预测每个身体部位的法线贴图,我们的方法没有考虑严重的自遮挡,例如,when a lower arm is behind the back。我们声称这种现象本质上是模棱两可的,可能的补救措施要么是预测遮挡像素的语义,要么是在[34]之前使用人体来指导深度预测。由于空间限制,我们在补充材料中提供了几个失败案例。
Conclusion
我们提出了 2K2K,这是一个从高分辨率单幅图像中数字化人类的有效框架。为此,我们首先通过扫描 2,050 个人体模型构建了一个大规模的人体模型数据集,并使用它们来训练我们的网络,由部分正态预测、低分辨率和高分辨率深度预测网络组成。为了有效地处理高分辨率输入,我们裁剪和弱对齐每个身体部位不仅可以处理姿势变化,还可以更好地恢复人体的精细细节,如面部表情。我们证明了所提出的方法适用于各种数据集的高分辨率图像有效工作。
Code
Human Body Part(2K2K)
将人体分为 12 个部分,可以只用头、躯干、手臂(4 part)、腿(4 part)和脚(2 part) 五个网络来预测
- openpose … To get keypoint(json) ,then convert json to npy (shape: 31,3)
- 输入原图 image,根据 pose(.Npy)得到仿射变换矩阵(init_affine_2048),仿射变换矩阵将目标部位移动到相机中心,然后通过 centercrop 得到 part image
- 原图 image 下采样后通过网络得到低分辨率法向量图,low normal 插值到 2k 后同样变换得到 part low normal
- Part image 和 part low normal 通过 5 个 part network 得到每个部分的 part high normal
- Part high normal 通过 occupy 方式得到的权重,求和拼接成 high normal

Note:pose 中脸部只有 2eye、2ear 和 1nose,手部为 4 个 finger
1 | [0, 1, 2, 3, 4] = [nose, L eye, R eye, L ear, R ear] |
根据 pose 将人体分为 12 个部分用 5 个网络预测:
1 | Face[4, 3] |