| Title | BuilDiff: 3D Building Shape Generation using Single-Image Conditional Point Cloud Diffusion Models |
|---|---|
| Author | Wei, Yao and Vosselman, George and Yang, Michael Ying |
| Conf/Jour | ICCV |
| Year | 2023 |
| Project | weiyao1996/BuilDiff: BuilDiff: 3D Building Shape Generation using Single-Image Conditional Point Cloud Diffusion Models (github.com) |
| Paper | BuilDiff: 3D Building Shape Generation using Single-Image Conditional Point Cloud Diffusion Models (readpaper.com) |
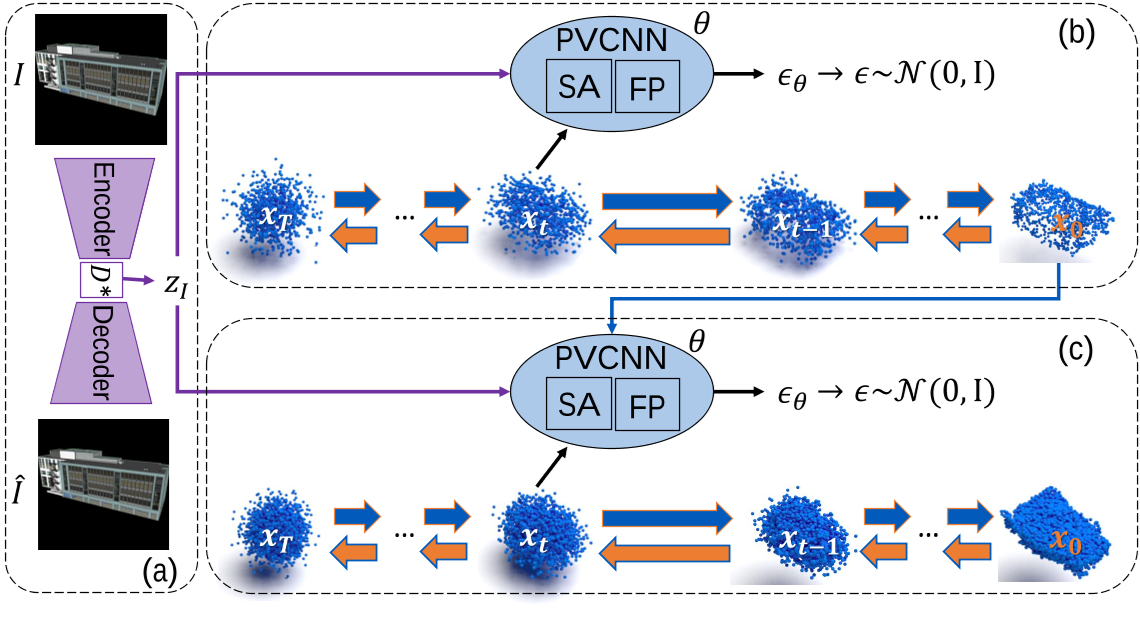
- 关注建筑物的重建,为 3D Diffusion Models 中添加了图片的信息嵌入(预训练了一个图片编码器)
- 两阶段的点云降噪模型,第一阶段关注全局,第二阶段关注细节
- 提出了两个自定义的新数据集,并在数据集上验证了本方法的优点
Abstract
具有低数据采集成本的三维建筑生成,如单图像到三维,变得越来越重要。然而,现有的单图像到 3d 的建筑创作作品大多局限于具有特定视角的图像,因此难以缩放到实际情况中常见的通用视图图像。为了填补这一空白,我们提出了一种新的三维建筑形状生成方法,利用点云扩散模型和图像调节方案,该方法对输入图像具有灵活性。该方法通过两种条件扩散模型的配合,在去噪过程中引入正则化策略,实现了在保持整体结构的前提下对建筑物屋顶进行合成。我们在两个新建立的数据集上验证了我们的框架,大量的实验表明,我们的方法在构建生成质量方面优于以前的工作。
Method
我们的目标是从单一的通用视图图像中生成建筑物的 3D 点云,而不是仅从特定角度(例如最低点或街道视图)获取图像,旨在提高所提出方法的适用性。如图 1 所示,我们引入了一个分层框架 BuilDiff,它由三个部分组成:
(a)图像自编码器 image auto-encoder
(b)image-conditional point cloud base diffusion
(c) image-conditional point cloud upsampler diffusion
Image Auto-encoder Pre-training
对扩散模型进行条件约束的一种常见而直接的方法是将 cue images 压缩到潜在空间中。我们没有使用在公共图像数据库(例如 ImageNet[4])上预训练的编码器直接将输入图像映射到作为建筑物模糊条件的潜在特征向量,而是对编码器进行微调,并使用训练集的建筑物图像训练额外的解码器。
如图 2 所示,整个网络可以看作是一个图像自编码器,它对输入的建筑图像进行学习重构,提取出作为代表性条件的建筑特征。
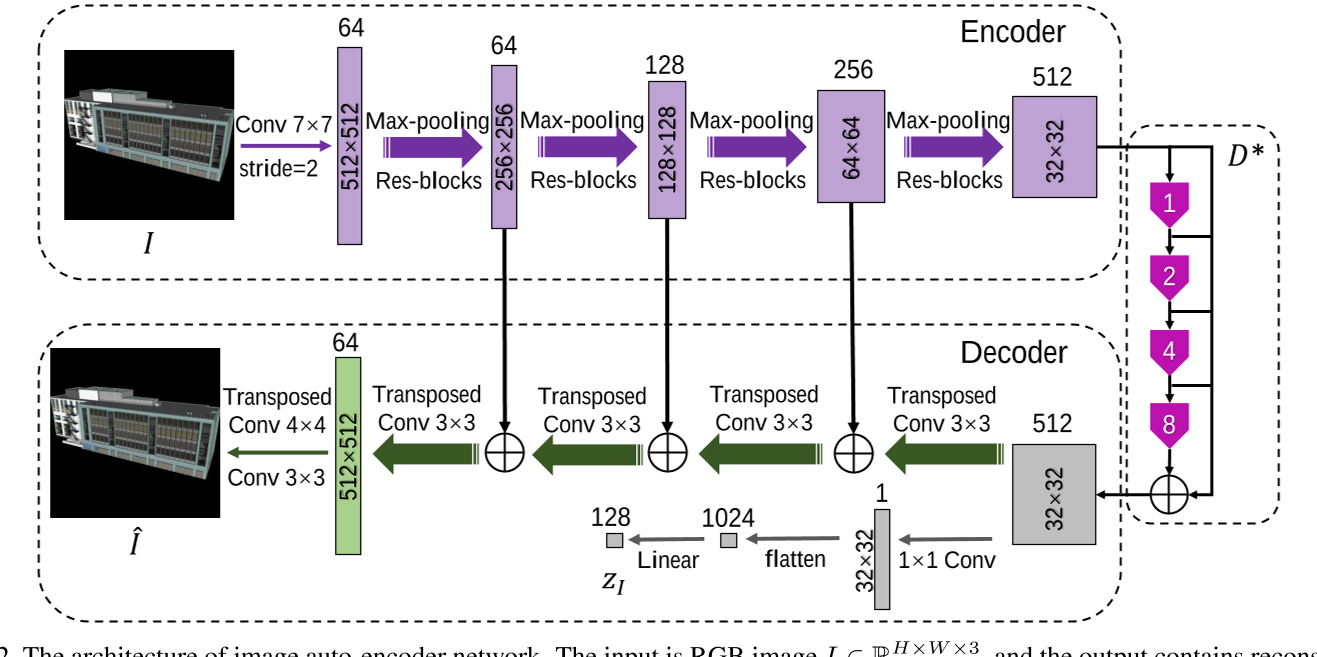
- 输入 HxW 图像,图像自编码器:ResNet-34
- 编码后大小为 H/32 x W/32,然后馈送到 stacked dilated convolution layers ($D^{*}$)
- $D^{*}$ 有四个 dilated convolution layers,膨胀率分别为 1、2、4、8
- 在解码阶段有两种处理方式
- 通过转置卷积层,可以将特征映射上采样到与输入图像 i 大小相同的 i
- 通过 1×1 卷积层和线性层将特征映射线性投影到嵌入 zI 的一维图像中,该图像的维数为 d
图像自编码器损失: $\mathcal L_{AE}=\mathcal L_{rec}(I,\hat{I})+\mathcal L_{con}(z_{I},z_{I}^{a})$
- 图像之间的重建损失 $\mathcal L_{rec}$
- 一致性损失 $\mathcal L_{con}$,它促使图像 I 的嵌入 $z_{I}$ 尽可能接近图像 I 的增广版本 $I^{a}$ 的嵌入 $z_{I}^{a}$。
训练后,我们使用冻结的预训练图像自编码器将图像映射到嵌入 $z_{I}$,这作为以下扩散模型的图像依赖条件。
Image-conditional Point Cloud Diffusion
Forward diffusion process 橙色:GT PointCloud —> Noisy PointCloud
Denoising diffusion process 蓝色:Noisy PointCloud —> GT PointCloud
逐渐加噪 $q(x_t|x_{t-1})$,噪声点云: $x_{t}=\sqrt{\bar{\alpha}_{t}}x_{0}+\sqrt{1-\bar{\alpha}_{t}}\epsilon$
- 包含 K 个点的 GT 点云 : $\begin{aligned}x_0&\sim q(x_0)\end{aligned}$
- $\alpha_{t}:=1-\beta_{t}$ , $\bar{\alpha}_t:=\prod_{s=1}^t\alpha_s$
- $\beta_{t}\in\{\beta_{1},…\beta_{T}\}$ 递增噪声调度序列,T:final time step
逐渐降噪 $q(x_{t-1}|x_t,z_I)$,可用降噪网络 $p_\theta(x_{t-1}|x_t,z_I)$ 近似表示
- 从高斯先验中采样 $p(x_{T})\sim\mathcal{N}(0,\mathcal{I}).$
- 对于 $p_\theta(x_{t-1}|x_t,z_I)$ 每个降噪步骤:
- 输入噪声点云 $x_t \in \mathbb{R}^{K \times 3}$,time step t 和图片 embedding $z_I \in \mathbb{R}^d$
- 输出噪声 $\epsilon_\theta(x_t,t,z_I)\in\mathbb{R}^{K\times3}$,并与目标的标准高斯 $\epsilon \sim \mathcal{N}(0,\mathcal{I})$ 做损失
- $\mathcal{L}_{eps}=\left|\epsilon-\epsilon_\theta(x_t,t,z_I)\right|^2$
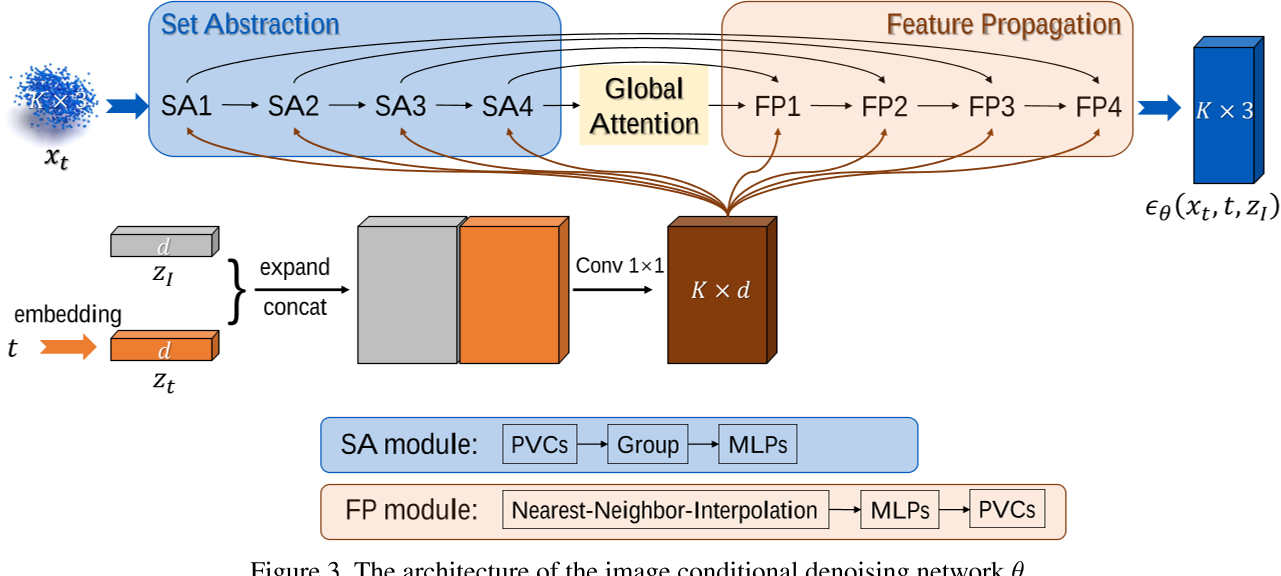
降噪网络 $\theta$ 建立在 PVCNNs 的基础上
PointNet
PointNet++
- PVCNNs Point-Voxel CNN for Efficient 3D Deep Learning (readpaper.com)
- 主要由集合抽象(set abstraction SA)模块和特征传播(feature propagation FP)模块两大部分组成
- 参考 PointNet++ 和 PointNet
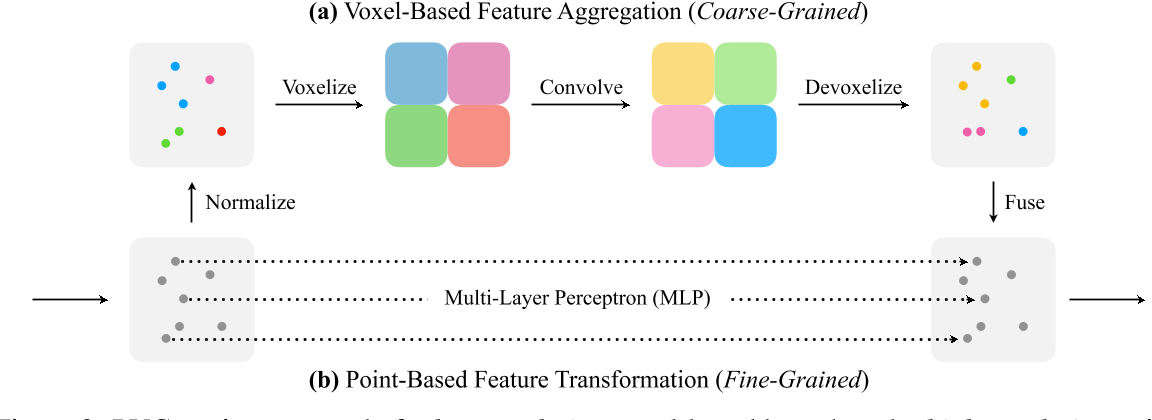
- SA 模块通常由点体素卷积(PVConvs)和多层感知器(mlp)组成
- FP 模块通常由最近邻插值、mlp 和 PVConvs 组成,通过使用基于点和体素的分支,PVConvs 可以捕获点云的全局和局部结构
- 主要由集合抽象(set abstraction SA)模块和特征传播(feature propagation FP)模块两大部分组成
在向 SA 或 FP 模块发送输入之前,将图像嵌入 zI 与由 t 导出的时间嵌入(记为 zt,正弦位置嵌入生成)连接起来,扩展和 concat 后形成 Kx2d,然后输入进两个带 LeakyReLU 激活函数的卷积层,得到一个大小为 K × d 的特征图,然后将其与 SA 和 FP 模块中的点特征连接起来(concatenated)
额外的损失函数:$\mathcal{L}_{reg}=\lambda(t)\Omega(proj(x_0),proj(\hat{x}_0))$
基于 $\epsilon_\theta,$ 期望的 $x_{0}$ 为:$\hat{x}_0=\frac{1}{\sqrt{\bar{\alpha}_t}}(x_t-\sqrt{1-\bar{\alpha}_t}\epsilon_\theta(x_t,t,z_I))$,然后将 $x_{0}$ 和 $\hat{x}_0$ 投影到 GT,得到 $proj(x_0),proj(\hat{x}_0)$,采用基于点的度量 $\Omega$ 来测量两个 footprints 的相似性。
- 其中 λ 是依赖于时间步长 t 的权值
- 当 t 趋近 T 时,$x_{T}$ 包含更多的噪声,因此 $\Omega$ 采用更小的权重
- 当 t 趋近 0 时,$x_{0}$ 包含更少的噪声,因此 $\Omega$ 采用更大的权重
$\theta$ 降噪网络的总损失 $\mathcal{L}_\theta=\mathcal{L}_{eps}+\rho\mathcal{L}_{reg}$
整个训练过程在算法 1 中描述。与[23]类似,我们采用了一个无分类器的引导策略[13],它联合学习一个条件模型和一个无条件模型。将嵌入 zI 的条件图像随机丢弃,将条件输出 $\epsilon_\theta(x_t,t,z_I)$ 随机替换为无条件输出 $\epsilon_\theta(x_t,t,\varnothing).$
在采样过程中,去噪扩散从高斯噪声(即 $x_T\sim\mathcal{N}(0,\mathcal{I}))$)开始,逐步用网络 θ 的输出去噪。$x_{T-1}$ 可以预测为: $x_{t-1}=\frac{1}{\sqrt{\alpha_t}}\bigl(x_t-\frac{1-\alpha_t}{\sqrt{1-\bar{\alpha}_t}}\epsilon_{guided}(x_t,t,z_I)\bigr)+\sigma_t\mathbf{z}$
其中 t 从 T 到 1,z 从标准高斯分布中采样,当 t >1 时。利用 guidance 标度 γ,guidance 噪声输出为: $\epsilon_{guided}:=(1+\gamma)\epsilon_\theta(x_t,t,z_I)-\gamma\epsilon_\theta(x_t,t,\varnothing)$ ,最终,当 t = 1时,可以对期望的 $x_0$ 进行采样。
Point Cloud Upsampler Diffusion
- 对于点云基础扩散(Image-conditional Point Cloud Diffusion),关键目标是生成低分辨率点云(K 点),可以粗略地捕捉建筑物的整体结构
- . Point Cloud Upsampler Diffusion 由冷冻预训练的自编码器导出的图像嵌入 zI 和由基础扩散推断的低分辨率点云作为输入,目标在于生成具有细粒度结构的高分辨率点云
假设期望点云 $x_0\in\mathbb{R}^{N\times3}$ 由 N 个点(N > K)组成,我们从高斯先验分布 $p(x_T)\sim\mathcal{N}(0,\mathcal{I}).$ 中随机采样噪声张量 $x_T\in\mathbb{R}^{N\times3}$
在训练过程中,去噪网络θ取 K 个点(即低分辨率点云)和从噪声 xT 中采样的(N−K)个点、时间步长 t 和条件化图像嵌入 zI 作为输入,在每一步中,用低分辨率点云替换θ采样的 N 个点中的前 K 个点,更新后的 N 个点作为下一个时间步长的输入。简而言之,为了达到 N 个点,我们对 K 个点进行上采样,并对其余(N−K)个点进行去噪
Experiments
Datasets
为了验证该方法的性能,我们创建了两个数据集,BuildingNet-SVI 和 BuildingNL3D,提供了数千对建筑物的图像- 3d 对。
BuildingNet-SVI:基于 BuildingNet[33]数据集,该数据集涵盖了多种合成三维建筑模型(如教堂、住宅、办公楼),我们收集了相应的建筑单视图 RGB 合成图像,得到 406 对图像-3D 对。此外,我们在像素级手动标注前景对象(即单个建筑物),并裁剪以建筑物为中心的每张图像。每个建筑点云有 10 万个均匀分布的 3D 点。我们遵循 BuildingNet[33]的官方分割规则,因此分别使用 321 和 85 对图像- 3d 对进行训练和测试
BuildingNL3D:我们收集了2,769对位于荷兰某城市市区的建筑物的航空 RGB 图像和机载激光扫描(机载激光扫描)点云。与具有单个建筑物和相对干净背景的合成图像不同,航空图像通常面临更多挑战,例如在一张图像中出现多个建筑物。因此,对建筑物进行手动标记,以便每张图像中只出现一个感兴趣的建筑物。原始 ALS 点云从其真实地理坐标归一化为 $[-1,1]^3$ 范围内的 xyz 坐标。在训练集和测试集中的建筑物不重复的情况下,根据基于 tile 的分割规则,将数据集划分为 2171 个 image3D 训练对和 598 个测试对。
Evaluation Metrics
我们采用 Chamfer distance (CD)[8]、Earth mover’s distance (EMD)[32]和 F1-Score[16]来评价生成建筑与其参考建筑的两两相似性。其中,CD 和 EMD 乘以 $10^2$,F1的阈值τ设为0.001。在计算这些度量之前,将点云归一化为 $[-1,1]^3$ 。三维点云的可视化是通过使用三菱渲染器[22]实现的。
Implementation Details
这些模型是在内存为 45GB 的 NVIDIA A40 GPU 上使用 PyTorch[25]实现的。批量大小设置为 8。图像被调整为 1024×1024 像素,即 H = W = 1024。每个 3D 点云都标准化了 100,000 个点来代表建筑物的形状。
- Image auto-encoder details。我们采用增强技术,包括以 90°角度旋转图像和在色调-饱和度-值(HSV)空间范围从-255 到 255 的颜色移动。这些都是基于建筑物可能在图像中出现颠倒和建筑物图像可能表现出很大的颜色变化的考虑。图像嵌入 zI 的维数 d 为 128。我们训练了 30 个 epoch 的自编码器,并使用学习率为 0.0002 的 Adam 优化器。利用均方误差(MSE)实现图像重构损失 Lrec 和嵌入一致性 lossLcon。在训练以下图像条件扩散模型时,我们冻结预训练的自编码器以导出 zI。
- Base diffusion details. 给定每个建筑100,000个点,我们随机采样 K = 1024个点(表示低分辨率点云)用于训练和测试。我们设β0 = 0.0001, βT = 0.02,并对其他βs 进行线性插值。与已有作品[48,46]相似,对基础扩散设置总时间步数为 T = 1000。时间嵌入的维数 d = 128。倒角距离[8]作为基于点的距离度量Ω来度量两个投影之间的相似性。正则化权值ρ设为0.001。对于无分类器的制导策略,我们在训练阶段使用下降概率0.1,在采样阶段使用制导尺度γ = 4。扩散模型经过700次训练,由 Adam 进行优化,学习率为0.0002。具体来说,λ(t)定义为: $\lambda(t)=\begin{cases}1,&t=1\\ 0.75,&1<t\leq\frac{1}{4}T\\ 0.50,&\frac{1}{4}T<t\leq\frac{1}{2}T\\ 0.25,&\frac{1}{2}T<t\leq\frac{3}{4}T\\ 0,&\frac{3}{4}T<t\leq T\end{cases}$
- Upsampler diffusion details. 对于训练和测试阶段,我们随机抽取 N = 4096 个点作为每个建筑的样本。上采样器的去噪网络训练 200 次,总时间步长 T 设为 500。
Conclusion
本文提出了一种基于扩散的 buildiff 方法,用于从单幅通用视图图像中生成建筑物的三维点云。
为了控制扩散模型生成与输入图像一致的三维形状,通过预训练基于 cnn 的图像自编码器,提取建筑物的多尺度特征,并使用增强约束潜在一致性,得到图像嵌入。
然后,以图像嵌入为输入,在加权建筑足迹正则化的辅助下,学习从高斯噪声分布中逐步去除噪声的条件去噪扩散网络;
最后利用点云上采样器扩散产生高分辨率点云,条件是从基础扩散采样的低分辨率点云。
实验结果证明了该方法的有效性。我们相信我们的工作可以弥合快速发展的生成建模技术和 3D 建筑生成的紧迫问题。