| Title | DiT-3D: Exploring Plain Diffusion Transformers for 3D Shape Generation |
|---|---|
| Author | Shentong Mo 1, Enze Xie 2, Ruihang Chu 3, Lewei Yao 2,Lanqing Hong2, Matthias Nießner4, Zhenguo Li2 |
| Conf/Jour | arXiv |
| Year | 2023 |
| Project | DiT-3D: Exploring Plain Diffusion Transformers for 3D Shape Generation |
| Paper | DiT-3D: Exploring Plain Diffusion Transformers for 3D Shape Generation (readpaper.com) |
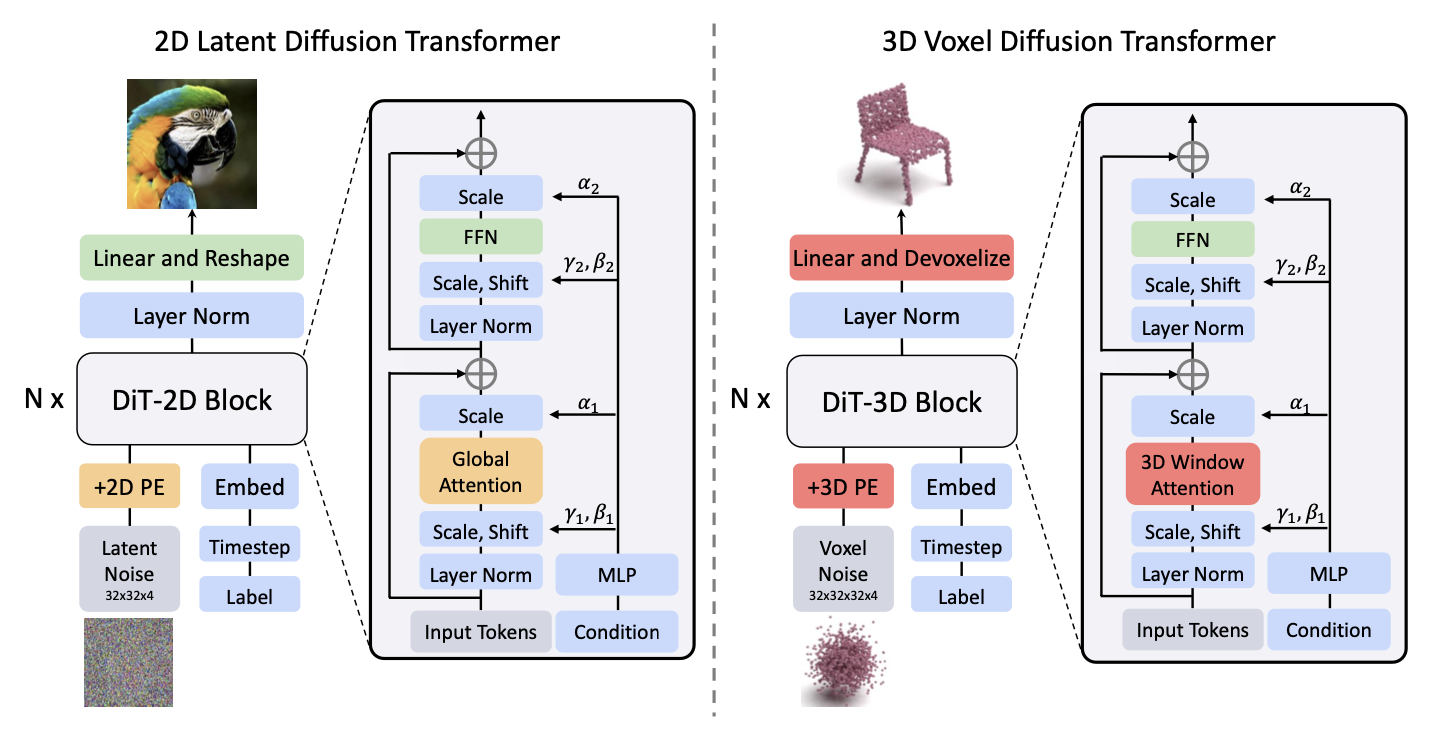
New 3D Diffusion Transformer Model, 在体素化的点云上运行 DDPM(Denoising diffusion probabilistic models) 的去噪过程
Abstract
最近的扩散 Transformers(例如 DiT[1])已经证明了它们在生成高质量 2D 图像方面的强大有效性。然而,Transformer 架构是否在 3D 形状生成中表现得同样好还有待确定,因为之前的 3D 扩散方法大多采用 U-Net 架构。为了弥补这一差距,我们提出了一种新的用于 3D 形状生成的扩散 Transformer,即 DiT-3D,它可以直接使用普通 Transformer 对体素化点云进行去噪处理。与现有的 U-Net 方法相比,我们的 DiT-3D 在模型大小上更具可扩展性,并产生更高质量的 generations。具体来说,DiT-3D 采用了 DiT[1]的设计理念,但对其进行了修改,加入了 3D 位置嵌入和补丁嵌入(3D positional and patch embedding),以自适应地聚合来自体素化点云的输入。为了减少 3D 形状生成中自注意的计算成本,我们将 3D 窗口注意 (3D window attention)合并到 Transformer 块中,因为由于体素的额外维度导致的 3D 令牌长度增加会导致高计算量。最后,利用线性层和去噪层对去噪后的点云进行预测。此外,我们的变压器架构支持从 2D 到 3D 的有效微调,其中 ImageNet 上预训练的 DiT-2D 检查点可以显着改善 ShapeNet 上的 DiT-3D。在 ShapeNet 数据集上的实验结果表明,所提出的 DiT-3D 在高保真度和多样化的三维点云生成方面达到了最先进的性能。特别是,当对倒角距离进行评估时,我们的 DiT-3D 将最先进方法的 1 近邻精度降低了 4.59,并将覆盖度量提高了 3.51。
- 我们提出了 DiT-3D,这是第一个用于点云形状生成的普通扩散 Transformer 架构,可以有效地对体素化点云进行去噪操作。(设计一个基于普通 Transformer 的架构主干来取代 U-Net 主干,以逆转从观测点云到高斯噪声的扩散过程)
- 我们对 DiT-3D 进行了一些简单而有效的修改,包括 3D 位置和补丁嵌入,3D 窗口关注和 ImageNet 上的 2D 预训练。这些改进在保持效率的同时显著提高了 DiT-3D 的性能。
- 在 ShapeNet 数据集上进行的大量实验表明,DiT-3D 在生成高保真形状方面优于以前的非 DDPM 和 DDPM 基线。
Method
Diffusion Transformer for 3D Point Cloud Generation
Efficient Modality/Domain Transfer with Parameter-efficient Fine-tuning
Conclusion
在这项工作中,我们提出了 DiT-3D,一种用于三维形状生成的新型平面扩散变压器,它可以直接对体素化点云进行去噪处理。与现有的 U-Net 方法相比,我们的 DiT-3D 在模型大小上更具可扩展性,并产生更高质量的 generations。具体来说,我们结合了3D 位置和补丁嵌入来聚合来自体素化点云的输入。然后,我们将3D 窗口关注合并到 Transformer 块中,以减少3D Transformer 的计算成本,由于3D 中额外维度导致令牌长度增加,计算成本可能会非常高。最后,我们利用线性层和去噪层来预测去噪后的点云。由于 Transformer 的可扩展性,DiT-3D 可以很容易地支持具有模态和域可转移性的参数高效微调。实验结果证明了所提出的 DiT-3D 在高保真度和多样化的3D 点云生成方面的最先进性能。