| Title | Flow-based GAN for 3D Point Cloud Generation from a Single Image |
|---|---|
| Author | Yao Wei (University of Twente), George Vosselman (“University of Twente, the Netherlands”), Michael Ying Yang (University of Twente)* |
| Conf/Jour | BMVA |
| Year | 2022 |
| Project | Flow-based GAN for 3D Point Cloud Generation from a Single Image (mpg.de) |
| Paper | Flow-based GAN for 3D Point Cloud Generation from a Single Image (readpaper.com) |
- flow-based explicit generative models for sampling point clouds with arbitrary resolutions
- Improving the detailed 3D structures of point clouds by leveraging the implicit generative adversarial networks (GANs).
Abstract
从单幅二维图像生成三维点云对于三维场景理解应用具有重要意义。为了重建图像中显示的物体的整个 3D 形状,现有的基于深度学习的方法使用显式或隐式的点云生成 modeling,然而,这些方法的质量有限。在这项工作中,我们的目标是通过引入一种混合显式-隐式生成建模方案来缓解这一问题,该方案继承了基于流的显式生成模型,用于任意分辨率的采样点云,同时通过利用隐式生成对抗网络(gan)改善点云的详细 3D 结构。在大规模合成数据集 ShapeNet 上进行了测试,实验结果证明了该方法的优越性能。此外,通过对 PASCAL3D+数据集的跨类别合成图像和真实图像进行测试,证明了该方法的泛化能力
Method
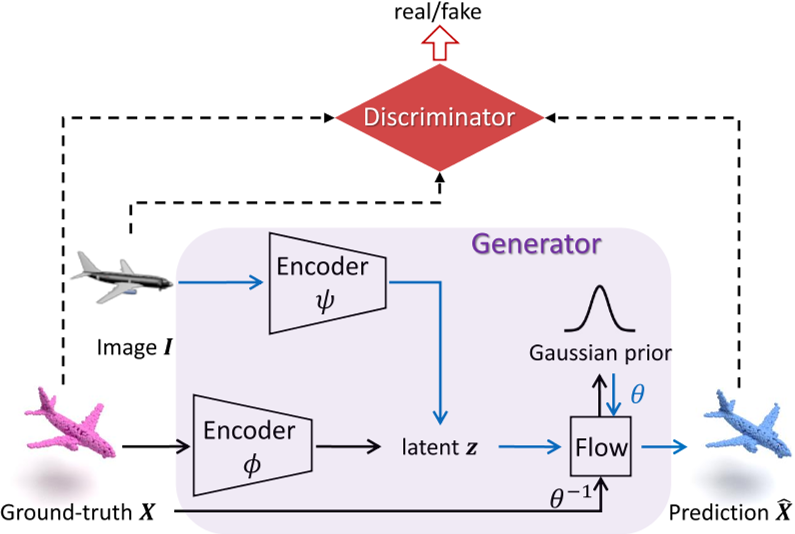
Framework
- Generator built on normalizing flows
- VAEs with a flow-based decoder
- Discriminator from cross-modal perspective
_蓝色是训练过程也是推理过程_
Flow-based Generator
- Encoder
- $\psi$ ResNet18 —> 图像 I 映射到潜在空间,图像条件分布用于在推理过程中对潜在 z 进行采样
- $\phi$ PointNet —> d-dimensional latent vector Z (d=512)
- Decoder (built on NFs)
- 在形状潜 z (编码点云 X 到 Z) 的条件下,应用包含 F 个 (F = 63)仿射耦合层的流动模型来学习简单先验分布,从 p(X)到高斯 p ~ N(0,1)的变换是反向模式 θ−1,从 p ~ N(0,1)到 p(X)的变换是正向模式 θ
Cross -modal Discriminator
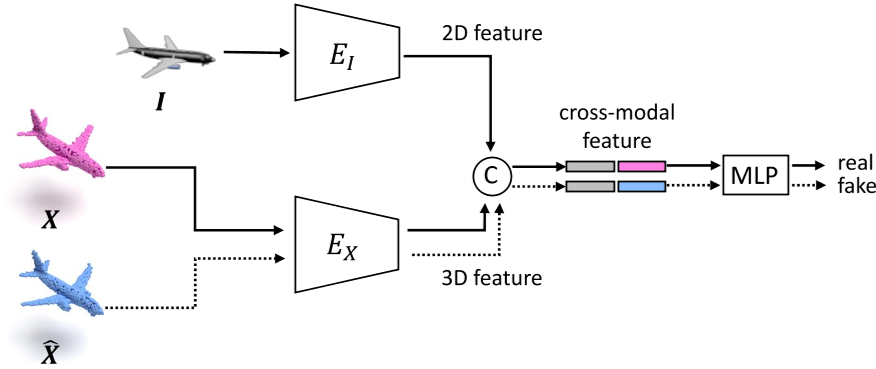
- 编码器 EX 用于分别提取预测点云和真实点云的 3D 特征 (PointNet)
- 编码器 EI 对输入图像的 2D 特征进行编码 (ResNet18)
将融合的跨模态特征输入 MLP 层以输出值, 以 I 和 X 作为输入,该值预计为 1(真实样本);当以 I 和 $\hat{X}$ 作为输入时,该值预计会为 0(假样本)
Conclusion
在本文中,我们提出了一种混合的显式-隐式生成建模方案,用于从单幅图像重建三维点云。为了解决生成固定分辨率的点云所带来的限制,我们引入了一个基于单流的生成器来近似3D点的分布,这使得我们可以对任意数量的点进行采样。此外,开发了一个跨模态鉴别器来引导生成器生成高质量的点云,这些点云既符合输入图像的合理条件,又具有与地面真实情况相似的三维结构。在ShapeNet和PASCAL3D+数据集上的实验结果证明了该方法的有效性和泛化能力。