| Title | Human as Points: Explicit Point-based 3D Human Reconstruction from Single-view RGB Images |
|---|---|
| Author | Yingzhi Tang, Qijian Zhang, Junhui Hou, and Yebin Liu |
| Conf/Jour | arXiv |
| Year | 2023 |
| Project | yztang4/HaP (github.com) |
| Paper | Human as Points—— Explicit Point-based 3D Human Reconstruction from Single-view RGB Images.pdf (readpaper.com) |
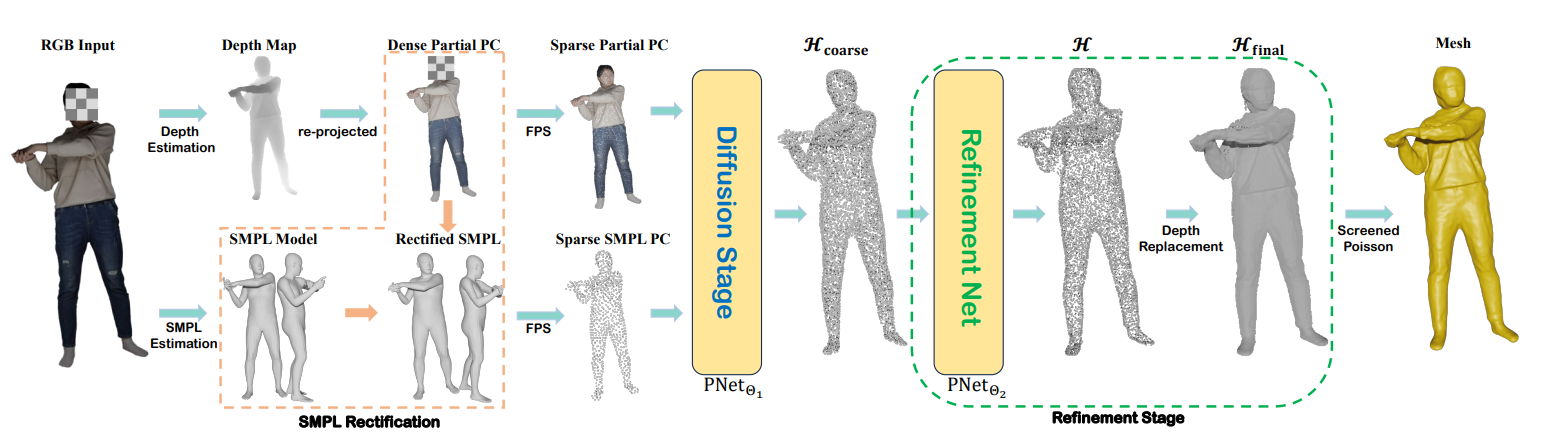
深度估计+SMPL 估计+Diffusion Model 精细化(PointNet++)
缺陷:依赖于深度估计方法和 SMPL 估计方法的精度
为了保护隐私不对人脸进行重建
AIR
Abstract
单视图人体重构研究的最新趋势是学习受外显形体先验约束的深层隐式函数。尽管与传统的处理管道相比,现有的学习方法有了显著的性能改进,但在灵活性、泛化性、鲁棒性和/或表示能力方面,现有的学习方法仍然表现出不同方面的局限性。为了全面解决上述问题,本文研究了一种基于点的显式人体重建框架 HaP,该框架采用点云作为目标几何结构的中间表示。从技术上讲,我们的方法的特点是在3D 几何空间中进行完全显式的点云估计,操作,生成和细化,而不是隐式的学习过程,可能是模糊的和不太可控的。整个工作流程是精心组织的,并专门设计了相应的专业学习组件和处理程序。广泛的实验表明,我们的框架比当前最先进的方法实现了20%到40%的定量性能改进,并获得了更好的定性结果。我们有希望的结果可能表明范式回滚到完全显式和以几何为中心的算法设计,这使得能够利用各种强大的点云建模架构和处理技术。我们将在 https://github.com/yztang4/HaP 上公开我们的代码和数据。
Introduction
基于图像的人体重建:
- 单视图:PIFu、ICON
- 多视图:DoubleField、DiffuStereo
已有大量基于优化的和基于学习的方法被提出用于单视图人体估计
- 基于优化:
- Detailed Human Shape and Pose from Images
- Keep it SMPL
- Estimating human shape and pose from a single image
- Expressive Body Capture:i.e. SMPL-X
- Parametric reshaping of human bodies in images
- 基于学习:
- Hierarchical Kinematic Human Mesh Recovery
- Coherent Reconstruction of Multiple Humans From a Single Image
- End-to-end Recovery of Human Shape and Pose
- Learning to Reconstruct 3D Human Pose and Shape via Model-Fitting in the Loop
近年来,由于深层隐式函数(Learning Implicit Fields for Generative Shape Modeling,Occupancy Network,DeepSDF)在表示具有精细几何细节的无约束拓扑三维形状方面的效率和灵活性,像素对齐的隐式重建管道 PIFu, PIFuHD 因其能够恢复穿著人体的高保真几何形状而成为主导的处理范式。然而,由于缺乏人体先验,这些方法通常会过度拟合有限的训练数据,在面对看不见的姿势/服装时,会产生退化的身体结构和断肢。
为了克服这些限制,最近的趋势 ICON,PaMIR 是通过引入参数化人体模型(如 SMPL[30],SMPL-X[41])作为显式形状先验来约束全隐式学习过程。然而,这种隐式重构和显式正则化的结合也会带来新的问题
通常,从输入图像像素推断的特征或中间结果与估计的参数模型的融合会导致几何过平滑,从而削弱表面细节。更重要的是,所选择的参数化模板模型与目标人体形状(特别是宽松的服装或复杂的配饰)之间的拓扑不一致通常会导致过度约束效果。尽管最近 ECON[58]努力探索更好的方法来共同利用隐式域的表示能力和显式体模型的鲁棒性,但参数体模型 SMPL-X[41]和法线映射的不满意估计仍然会严重降低重建质量。
在实践中,在评价人体全再造管道的潜力和优越性时,有几个方面的关键考虑因素:
1)灵活性,可以对任意穿着的人体形状进行无约束拓扑建模。
2)对看不见的数据分布(例如,新姿势和衣服)的泛化性。
3)鲁棒性,避免非人类重建的结果(例如,不自然的姿势,退化的身体结构,断肢)。
4)在三维空间中表现和捕捉表面几何细节的能力。
在本文中,我们试图开发一种基于学习的单视图人体重建框架,该框架同时满足上述关键要求,与以前的方法相比,它是一种更有前途的处理范式,具有更大的潜力。在架构上,我们构建了 HaP,这是一个完全显式的基于点的建模管道,其特点是在显式 3D 几何空间中直接进行点云估计(来自 2D 图像平面),操作,生成和细化。
更具体地说,给定输入的 RGB 图像,我们的过程从深度估计开始,这使我们能够推断出代表高保真可视几何形状的部分 3D 点云。同时,我们还从二维图像空间估计 SMPL 模型,以提供缺失的人体信息。在估计深度图基本准确的前提下,通过专门的 SMPL 校正程序,进一步利用之前深度推断的部分 3D 点进行位姿校正,使估计的 SMPL 模型与 z 轴方向的点配准良好。将深度推断的部分点的三维信息与估计的 SMPL 模型直接合并,可以粗略地形成具有丰富纹理和皱纹细节的完整的三维人体点云;然而,部分点与估计的 SMPL 模型之间仍然存在明显的差距,这使得它们不自然并且可能存在问题。
为此,我们定制了一个扩散式的点云生成框架,在粗合并三维人体点的基础上学习真实人体的潜在空间分布,目的是生成与深度推导的部分三维点和 SMPL 模型相一致的服装和姿态信息的三维人体。此外,我们提出了一个细化阶段,包括基于学习的流量估计和简单有效的深度替换策略,以进一步提高几何质量。最后,使用典型的曲面重建方法,如筛选泊松曲面重建[23],可以方便地从得到的点云中获得高质量的网格模型。
- 我们采用点云作为中间表示,它对于建模任意拓扑几何结构是灵活的
- 从二维图像平面推断粗糙三维几何信息的过程包括二维深度估计和SMPL 估计。前者作为一项研究丰富、较为成熟的任务,具有较好的通用性。后者通过注入人体先验而不破坏从特定输入图像中挖掘的服装线索来提高重建鲁棒性
- 在原三维几何空间中直接实现基于点的学习过程,姿态校正和表面细节捕捉更为直观有效
贡献:
- 我们提出了一个新的管道,HaP,通过在三维空间中的深度图和 SMPL 模型条件下的扩散过程来明确地在点云中生成人体;
- 我们提出了一个有效的 SMPL 校正 rectification 模块来优化 SMPL 模型以获得准确的姿态;
- 我们提供了一个包含高保真度 3D 人体扫描的新数据集,以促进未来的研究工作,如图 2 所示。

Related Work
Monocular Depth Estimation
- Predicting depth maps from single-view RGB images is a challenging task,
- Make3D[46]将图像分割成均匀的小块,并利用马尔科夫随机场推断平面参数,从而捕获每个小块在三维空间中的位置和方向。
- Eigen 等人提出了一种开创性的基于深度学习的方法来学习 RGB 图像到深度图的端到端映射。(Depth Map Prediction from a Single Image using a Multi-Scale Deep Network)
- BTS[26]设计了新颖的局部平面制导层,以便在解码的多个阶段更有效地利用密集编码的特征(From big to small: Multi-scale local planar guidance for monocular depth estimation)
- P3Depth[39]迭代和选择性地利用共面像素的信息来提高预测深度的质量
- Xie 等人发现,蒙面图像建模(MIM)在深度估计方面也可以达到最先进的性能(Revealing the Dark Secrets of Masked Image Modeling)
- Particularly, various methods have been proposed for estimating human depth maps from single-view images.
- Tang 等人[51]采用分割网和骨架网生成人体关键点和身体部位热图。这些热图被用来通过深度网计算基本形状和细节形状。Tan 等人提出了一种利用视频中预测的 SMPL 模型的自监督方法。(Self-Supervised Human Depth Estimation from Monocular Videos)
- HDNet[20]预测每张图像对应的密集姿态,而不是 SMPL 模型(Learning High Fidelity Depths of Dressed Humans by Watching Social Media Dance Videos)
- Tan et al.[50]和 Jafarian et al.[20]都将身体部位扭曲到视频的不同帧中,并对深度图进行监督,这导致了照片一致性的损失,因为深度图在不同帧之间不会有太大的变化
Point Cloud Generation 点云生成任务可以大致分为两类:无条件和条件
- Unconditioned
- RGAN[1]是一种经典的无条件点云生成方法,它使用具有多个 mlp 的 GAN 结构来对抗性地生成点云
- WarpingGAN[53]是一个轻量级且高效的网络,它将多个均匀的 3D 网格扭曲成各种分辨率的点云
- ShapeGF[4]首先引入基于分数的网络无条件生成点云,它以噪声为输入,旨在学习三维形状的隐式表面
- Conditioned 条件生成任务通常从 RGB 图像[11]、文本信息[36]或部分点云[31]、[37],[63]中生成点云
- Fan[11]等人提出了一种 PointOutNet,在 RGB 图像条件下预测多个可信的点云
- Point-E[36]首先使用文本到图像的扩散模型合成单视图 RGB 图像,然后使用另一种扩散模型基于生成的图像生成点云。
- VRCNet[37]生成以局部点云为条件的点云,它将补全任务视为一个关系推理问题,学习对点之间的空间关系进行推理,从而补全缺失的部分
- PVD[63]和 PDR[31]是基于扩散的网络,它们也在条件情景下运行,以部分点云为条件补全缺失部分
在本文中,HaP 将重建任务作为一个条件点云生成任务,依赖于 RGB 图像估计的深度图和 SMPL 模型作为条件。
Human Pose and Shape Estimation
- 估计 2D 关键点 OpenPose[6]、AlphaPose[12]或人类 parsing:Beyond Appearance[8]、Deep Human Parsing with Active Template Regression[27]可以提供关于人类结构的有价值的信息,然而,它们缺乏精确三维重建所需的空间信息。
- 从 RGB 图像中预测参数模型,如 SMPL(-X)[30],可以更好地理解人体姿势和形状,作为人体重建的先验信息
- Zhang 等人 PyMAF[61]提出了一种基于回归的方法,该方法使用特征金字塔,通过对齐 SMPL 网格和图像来校正预测参数
- PIXIE[13]引入了一个主持人,它根据专家的置信度权重合并了他们的身体、面部和手的特征
- Kocabas 等人提出了一种对抗性学习框架 VIBE,用于从视频中学习运动学 SMPL 运动序列
- METRO[28]尝试对顶点-顶点和顶点-关节的相互作用进行建模,最终输出人体关节坐标和 SMPL 顶点。然而,预测的 SMPL(-X)[30],[41]模型在三维空间观测时有时会出现不对准问题
为了解决这个问题,我们提出了一种新的 SMPL 校正模块,该模块可以最大限度地减少 SMPL 模型的可见分区与深度推导的部分点云(被认为是准确的)在 3D 空间中的距离,我们生成的 SMPL 模型更准确,更符合给定人体。
Single-View Human Reconstruction
- SiCloPe[35]以 RGB 图像为条件训练生成对抗网络,并合成一致的轮廓来生成纹理三维网格
- Ma et al.[32]提出了一种 POP 模型,用于生成三维点云的衣层参数模型
- PIFu[44]是一项开创性的工作,将隐式函数引入人类重建任务。
- PIFuHD[45]通过采用前后法线贴图训练的多层次架构来增强高分辨率图像的性能
- Xiu et al.ICON[59],PaMIR[62],也使用 SMPL 模型来提供关于人体的先验信息
- Xiu 等人提出了 ECON 来隐式和显式地解决重建问题。他们从学习到的正面和背面法线贴图中重建 2.5D 网格,最后使用隐式函数和筛选的泊松方法实现全网格。然而,ECON 仍然依赖于基于渲染的 SMPL 细化方法,限制了其性能
- Han 等人(2K2K)引入了一种基于不同身体部位学习深度图的两阶段深度估计网络。在获得正面和背面深度图后,将其转换为点云,并使用筛选后的泊松方法重建人体。尽管该方法遵循基于显式的方法,但其主要重点是学习二维平面上的精确深度图。
- Tang et al.[52]设计了一个两阶段的三维卷积网络来明确学习人体的 TSDF 体积。(High-Resolution Volumetric Reconstruction for Clothed Humans)
- 已经提出了[5],[20],[56],[57]等多种方法来探索深度在三维重建中的潜力。
- Wang[54] 等人训练了一个对抗网络NormalGAN来对 RGB-D 相机采集的深度进行降噪,并生成后视图的几何细节。
- Xiong et al.[57]提出了一种深度引导自监督学习策略PIFu for the Real World,该策略使用有符号距离函数(signed distance function, SDF)值代替占用值来学习隐式曲面。
- Chan[7] 等人IntegratedPIFu设计了一种面向深度的采样方案来学习高保真的几何细节。他们还提出了一种具有少量参数的高分辨率积分器来学习 RGB 图像的全局信息。
- [7],[57]这些方法通常利用网络来预测给定 RGB 图像的法线图和深度图。Xiong et al.[57]和 Chan et al.[7]都利用深度图作为隐式函数二维平面上的额外特征。
Method
提出的单视图三维人体重建框架的整体处理流程包括两个子任务:
(1)从输入的二维 RGB 图像中推断和校正三维几何信息;
(2)根据生成的三维几何信息生成高质量的三维人体点云,然后直接进行网格重建。
如图 3 所示,流程:
- HaP 从深度和 SMPL 估计的两个平行分支开始,这两个分支在推断人体几何的三维信息方面显示出互补的特征。具体来说,深度估计能够捕获前视图的详细几何图案,但需要额外的努力来恢复看不见的身体部位;不同的是,估计的 SMPL 提供了强大的人体先验,避免了非人类结构(例如,不自然的姿势,退化的身体,断裂的肢体),但存在固定拓扑和过度光滑的表面细节。因此,我们有动力共同利用这两个三维信息来源。特别地,我们提出了一个基于优化的 SMPL 校正 Rectification 模块,将初始估计的 SMPL 模型与深度推导的部分三维点云对齐。
- 在将深度和 SMPL 的几何信息统一为三维点云之后,我们提出了一种条件点扩散模型,该模型将深度和 SMPL 的几何信息同时作为输入,以产生更精确的完整人体的三维点云。
- 此外,在推理过程中,探索另一个细化阶段,以进一步提高得到的三维点云的质量。
- 最后,我们使用经典的表面重建算法[23]直接提取网格表示。Screened poisson surface reconstruction
Estimating 3D Information from Single 2D Images
从单个 RGB 图像 $\mathcal{I}$ 中:深度估计+SMPL 估计,为了解决 P 和 S 估计对不齐,假设深度估计通常具有较高的精度,提出了一种新的 SMPL rectification 模块
Depth estimation: 使用最新的最先进的单目深度估计器 MIM 56 来预测图片 $\mathcal{I}$ 的相应深度图,然后我们根据相机的内在参数将每个 2D 像素坐标(u, v)的深度值投影到 3D 点(x, y, z)。此外,我们还附加了每个像素的原始 RGB 值,推导出一个彩色的三维点,记为 $\mathbf{p} = (x, y, z, r, g, b)$。这样,通过屏蔽掉无效的背景像素,我们可以得到一个三维部分人体点云,记为 $\mathcal{P}=\{\mathbf{p}\}.$。
SMPL Estimation and Rectification: 为了提供明确的人体形状先验,并补充部分深度推断的点云 P 中缺失的身体部位,与[13],PyMAF[61]类似,我们从 $\mathcal{I}$ SMPL 模型中估计 S。然而,正如之前的研究 PaMIR[62]所分析的那样,由于 z 轴深度模糊,不可避免地会导致 S 和 P 之间的不对齐,特别是在单图像设置下,这会直接降低整个人体重建管道的质量。为了解决这一问题,假设深度估计通常具有较高的精度,因此可以以令人满意的质量推断 P,我们提出了一种新的 SMPL rectification 模块,通过更新 SMPL 参数进一步促进 S 与 P 的对齐。
SMPL rectification
SMPL 估计出来的点云:$\mathcal{S}=\mathcal{S}_{v}\cup\overline{\mathcal{S}}_{v}$
- $\mathcal{S}_v=(\mathcal{V}_v,\mathcal{F}_v)$ 可见部分
- $\begin{aligned}\overline{\mathcal{S}}_v=(\overline{\mathcal{V}}_v,\overline{\mathcal{F}}_v)\end{aligned}$ 不可见部分
修正后的 SMPL 点云 $\widehat{\mathcal{S}}$
一般情况下,以最小化 $\mathcal{S}_{v}$ 与 P 之间的距离为目标,通过对 S 的形状参数β和位姿参数θ进行迭代校正即可实现该问题。
- 为了避免不可见部分不自然地靠近 P 而导致位姿不自然的情况,我们增加了正则化项来提高 P 与 $\mathcal{S}_{v}$ 之间的距离。
- 我们还正则化形状参数β,由于其固有的零均值性质,如 Keep it SMPL[3]中提出。
- 优化还受到两个约束:
- (1) $\widehat{\mathcal{S}}$ 的 2D 关键点与 S 的不一致,避免了 $\widehat{\mathcal{S}}$ 在二维平面上姿态的过度变化;
- (2) $\widehat{\mathcal{S}}$ 的掩模(即 $\mathcal{M}_{\widehat{\mathcal{S}}}$)投影到二维平面上时与 ${\mathcal{I}}$ (即 $\mathcal{M}_{h}$)的人体掩模之间的轮廓差异,保持了 $\widehat{\mathcal{S}}$ 的整体人体形状。
总之,我们明确地将问题表述为:
式中,P2F(·,·)和 CD(·,·)分别表示点到面距离(P2F)和倒角距离(CD) $\mathcal{K}\mathrm{~and~}\mathcal{K}_0$ 分别为每次迭代和 S 的 SMPL 2D 关键点;非负超参数λ1, λ2, λ3 和λ4 平衡了不同的正则化项。
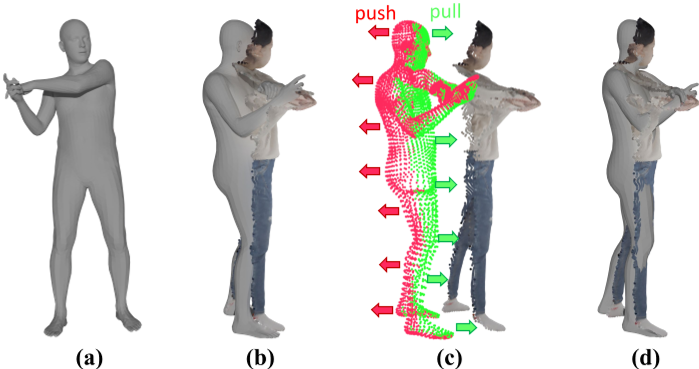
SMPL rectification process.
(a) Initially estimated SMPL model.
(b) Registration before rectification.
(c) Rectification process.
(d) Registration after rectification.
直接估计的 SMPL 模型与部分点云的配准不太好,经过整改后情况得到明显缓解。
Diffusion-based Explicit Generation of Human Body
Depth-deduced 的部分人体点云 P 提供了自由而精细的几何结构,如衣服正面的褶皱,而完全忽略了背面和遮挡部分。而修正后的 SMPL 参数化人体形状面 $\widehat{S}$ 则保证了完整的体表,姿态和形状合理,但其固定的拓扑结构在处理宽松复杂的服装时造成了本质上的困难。这些互补的特性促使我们共同利用 P 和 $\widehat{S}$ 来重建高保真的三维人体几何。然而,直接将深度 deduced 和 SMPL-deduced 的三维几何信息合并在一起可能会有问题,因为 P 和 $\widehat{S}$ 之间通常存在不可忽略的间隙。
为此,我们进一步提出训练条件去噪扩散概率模型(conditional denoising diffusion probabilistic model, DDPM)来生成高质量的3D 人体点云,目的是将 P 和 $\widehat{S}$ 自然融合并消除间隙。扩散模型的主干是一个双分支的 PointNet++体系结构 31,42 参数化为 $\Theta_{1}$,表示为 $\operatorname{PNet}_{\Theta_1}(\cdot)$。
在扩散阶段之后,我们进一步提出了细化阶段来提高生成点云的质量。具体来说,我们使用与 $\Theta_{2}$ (即 $\operatorname{PNet}_{\Theta_2}(\cdot)$)参数化的相同架构,通过学习每个点的位移来细化生成的人体点云。
然后采用深度替换策略depth replacement strategy对生成的点云进行密度化处理。
- Diffusion Stage: 在这个阶段,我们训练一个条件扩散模型来生成一个人体点云。
由于有限的 GPU 内存和计算时间的限制,我们配置 $\operatorname{PNet}_{\Theta_1}(\cdot)$ 来生成一个具有 10,000 个点的相对稀疏的 $\mathcal{H}_{\mathrm{coarse}}$。在训练过程中,我们使用最远点采样操作分别从 $\mathcal{P}\mathrm{~and~}\widehat{\mathcal{S}}$ 中采样点,并将其作为扩散模型的条件。一个条件 DDPM 由两个相反方向的马尔可夫链组成,即正向过程和反向过程,这两个过程的采样步长 T 相同。在前向过程中,在每个采样步长 t 处加入高斯噪声 $\mathcal{H}_{\mathrm{gt}}$,当 t 足够大时,前向过程的输出应与高斯分布 $\mathcal{N}(\mathbf{0},\boldsymbol{I})$ 接近,前向过程从初始步长 $\mathcal{H}_{\mathbf{gt}}^{\boldsymbol{0}}$ 到最后一步步长 $\mathcal{H}_{\mathrm{gt}}^T.$。注意,条件 $(\mathcal{P},\widehat{\mathcal{S}})$ 不包括在正向过程中。
前向的采样过程是迭代的,但是我们不能在每个时间步都训练 DDPM,因为这需要花费大量的时间。根据 DDPM[18],我们可以通过定义 $\begin{aligned}1-\gamma_t=\alpha_t,\bar{\alpha_t}=\prod_{i=1}^t\alpha_i,\end{aligned}$ 来实现任意步长 $\mathcal{H}_{\mathrm{gt}}^t$,其中γ是一个预定义的超参数。因此,公式 $q(\mathcal{H}_{\mathrm{gt}}^t|\mathcal{H}_{\mathrm{gt}}^0)=\mathcal{N}(\mathcal{H}_{\mathrm{gt}}^t;\sqrt{\bar{\alpha}_{t}}\mathcal{H}_{\mathrm{gt}}^0,(1-\bar{\alpha}_{t})\boldsymbol{I}),$,和 $\mathcal{H}_{\mathrm{gt}}^t$ 可以通过: $\mathcal{H}_{\mathrm{gt}}^{t}=\sqrt{\bar{\alpha_{t}}}\mathcal{H}_{\mathrm{gt}}^{0}+\sqrt{1-\bar{\alpha_{t}}}\boldsymbol{\epsilon},$
其中ε为高斯噪声。利用 DDPM[18]中提出的参数化技术,我们可以通过最小化来训练 $\Theta_{1}$:
$\mathcal{L}_{\mathrm{ddpm}}=\mathbb{E}_{t,\mathcal{H}_{\mathrm{gt}}^{t},\epsilon}|\epsilon-\mathrm{PNet}_{\Theta_{1}}(\mathcal{H}_{\mathrm{gt}}^{t},\mathcal{P},\widehat{\mathcal{S}},t)|^{2}$,PointNet++以 $\mathcal{P}\mathrm{~and~}\widehat{\mathcal{S}}$ 作为条件来预测 $\mathcal{H}_{\mathrm{gt}}^t$ 中的噪声
在训练过程中,每个时间步骤都将 $\mathcal{P}\mathrm{~and~}\widehat{\mathcal{S}}$ 作为条件,对服装信息和人体信息进行监督。在推理过程中,我们按照相反的过程生成 $\mathcal{H}_{\mathrm{coarse}}$,即从 T 开始,从 $\mathcal{H}_{\mathrm{gt}}^t$ 逐步采样 $\mathcal{H}_{\mathrm{gt}}^{t-1}$。生成的 $\mathcal{H}_{\mathrm{coarse}}$ 与提供的 P 具有相同的服装信息,其姿态与 $\widehat{\mathcal{S}}$ 提供的姿态保持一致。
- Refinement Stage:
在推理过程中,我们观察到 $\operatorname{PNet}_{\Theta_1}(\cdot)$ 通常不可能消除 $\mathcal{H}_{\mathrm{coarse}}$ 中的所有噪声。因此,我们只能从 $\mathcal{H}_{\mathrm{coarse}}$ 中恢复一个粗糙的表面。为了克服这个问题,我们用 $\Theta_{2}$ 参数化 $\operatorname{PNet}_{\Theta_2}(\cdot)$ 来训练学习 $\mathcal{H}_{\mathrm{coarse}}$ 中每个点的位移,即 $\Delta=\mathrm{PNet}_{\Theta_2}(\mathcal{H}_{\mathrm{coarse}},\mathcal{P},\widehat{\mathcal{S}}),$,以光滑 $\mathcal{H}_{\mathrm{coarse}}$ 的表面。我们用 $\mathcal{H}=\mathcal{H}_{\mathrm{coarse}}+\Delta.$ 到人体点云 $\mathcal{H}$。我们把这个问题表述为:
$\min_{\Theta_2}\text{D}(\mathcal{H},\mathcal{H}_{\mathrm{gt}})+\alpha\text{R}_{\mathrm{smooth}}(\Delta),$
- D(·,·)表示 43 实现的距离度量,
- $R_{smooth}(·)$ 是空间平滑正则化项,表示为: $\mathrm{R}_{\mathrm{smooth}}(\Delta)=\frac1{3N_{\mathrm{src}}K_s}\sum_{x\in\mathcal{H}_{\mathrm{coarse}}}\sum_{x^{\prime}\in\mathcal{N}(x)}|\delta_x-\delta_{x^{\prime}}|_2^2,$
- 式中 N(·)返回 the K-NN(k-nearest neighbors) points,$\delta_{x}\in\Delta$ 为一个典型点的位移。
此外,在前面的扩散阶段,我们对一组相对稀疏的 3D 点进行采样,作为 DDPM 的输入,以节省内存和计算成本,这决定了 $\dot{\mathcal{H}_{\mathrm{coarse}}}$ 的稀疏性,与 $\mathcal{H}$ 类似,为了产生具有增强几何细节的密集点云,我们专门采用了一种简单而有效的深度替换策略,该策略充分利用了前面深度推断的部分点云 P 的密度,如图 5 所示。我们的策略首先使用球查询操作 PointNet++[42]来定位 P 在 $\mathcal{H}$ 内的最近点;这些最近的点随后被移除并记为 $s_{1}$。在此基础上,我们确定了 P 内 $\mathcal{H}−s_{1}$ 的最近点,并将其命名为 $s_{2}$。最后,我们确定 P 内离 $s_2$ 最近的点,并将它们标记为 $s_{3 }$。最终点云记为 $\mathcal{H}_{\mathrm{final}}$,由 $\mathcal{H}-s_1$ 和 $s_{3}$ 组合而成。
TLDR. 从 H 中选取离 P 最近的点 $s_{1}$,然后从 P 中选取离 $s_{1}$ 最近的点 $s_{2}$ ,再从 P 中选取离 $s_{2}$ 最近的点 $s_{3}$ ,最后将 $s_{3}$ 与 $\mathcal{H}-s_1$ 组合起来
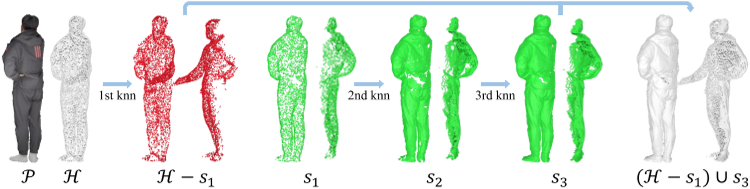
在得到替换后的点云 $\mathcal{H}_{\mathrm{final}}$ 后,我们直接采用筛选过的泊松[23]进行网格提取。
EXPERIMENTS
我们为 CityUHuman 数据集新收集的人体模型显示出相对更平滑和更精确的表面结构
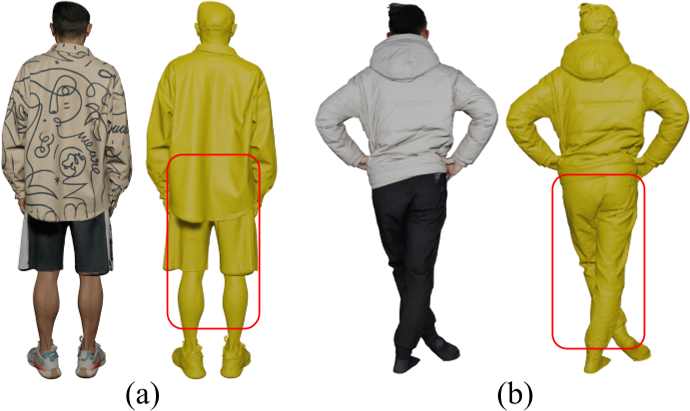
(a) 本文 CityUHuman
(b) Thuman
具体来说,我们使用名为 Artec Eva2 的高精度便携式 3D 扫描仪获得了高质量的 3D 人体扫描。每次扫描的完整集合包括超过 1000 万个点。我们一共邀请了 10 个志愿者,每个志愿者展示了大约 10 个不同的姿势。秉承道德原则和尊重个人信息的所有权,我们在收集数据之前获得了每位志愿者的同意。志愿者被告知,他们的 3d 扫描数据将专门用于非商业研究应用。为了保护志愿者的隐私,我们恳请用户在任何准备发表的材料中对面部进行模糊处理,比如论文、视频、海报等等。我们从图 2 的数据集中提供了大约 60 个不同衣服和姿势的样本扫描,以展示其在研究中的质量和潜力
1)训练数据:在我们的实验中,我们统一采用 Thuman2.0[60]对我们提出的 HaP 学习架构进行训练。一方面,我们从每个模型中提取 10000 个三维点作为地面真点云。另一方面,我们使用了 Blender 软件来渲染真实的深度图和 photo-realistic 的图像,间隔为 10 度。因此,对于每个作为输入的 RGB 图像,我们有三个方面的监督信号,即深度图,smpl 推导的点云和人的点云。得到的训练样本总数为 18000。特别是,为了与 IntegratedPIFu[7]进行公平的比较,我们进一步从我们的训练样本中创建了一个子集,通过保留 IntegratedPIFu 训练过程中使用的相同扫描索引来训练我们的 HaP,同时从每次扫描中均匀地选择 10 个视图。
2)测试数据:我们从 Thuman3.0[49]和我们收集的 CityUHuman 数据集中生成测试数据,以评估不同方法的性能。我们使用 8 个视图在偏航轴上每 45 度渲染一次扫描,然后从 Thuman3.0 中随机选择 459 张 RGB 图像,从 CityUHuman 中随机选择 40 张 RGB 图像。此外,我们还从互联网上收集了几张真实的图像,并推断出相应的人体。
Implementation Details
所采用的深度估计方法 MIM 以分辨率为 512 × 512 的 RGB 图像为输入。在 MIM 的训练过程中,我们采用了 swin-v2-base 架构[29]作为骨干。学习率设置为 0.3 × 10e−4,批大小设置为 8,epoch 数设置为 30。其余参数与原 MIM 中的参数保持一致。训练在 4 块 RTX 3090 Ti gpu 上进行。
Conclusion
我们提出了一种新的基于点的学习管道,用于单视图三维人体重建。在从 2D 图像域粗略推断 3D 信息之后,我们的方法的特点是在原始 3D 几何空间中进行显式的点云操作,生成和细化。与以往主流的隐式基于场的方法相比,该方法具有高度的灵活性、通用性、鲁棒性和精细几何细节建模能力。大量的实验证明了我们的 HaP 优于目前最先进的方法。然而,必须承认,在处理 RGB 图像时,HaP 的性能仍然取决于深度估计模块和 SMPL 估计模块的有效性。因此,我们未来的努力将集中在提高这些关键模块的性能上