| Title | DoubleField: Bridging the Neural Surface and Radiance Fields for High-fidelity Human Rendering |
|---|---|
| Author | Ruizhi Shao1, Hongwen Zhang1, He Zhang2, Yanpei Cao3, Tao Yu1, and Yebin Liu1 |
| Conf/Jour | CVPR |
| Year | 2022 |
| Project | DoubleField Project Page (liuyebin.com) |
| Paper | DoubleField: Bridging the Neural Surface and Radiance Fields for High-fidelity Human Rendering. (readpaper.com) |
Abstract
我们介绍了一种结合表面场和亮度场优点的高保真人体渲染的新表示方法——DoubleField。在 DoubleField 中,通过共享特征嵌入和表面引导采样策略将表面场和辐射场关联在一起。这样,DoubleField 就为几何和外观建模提供了一个连续但不纠缠的学习空间,支持快速训练、推理和微调。为了实现高保真的自由视点渲染,DoubleField 进一步增强以利用超高分辨率输入,其中引入了视图到视图转换器和迁移学习方案,以便在原始分辨率下从稀疏视图输入进行更有效的学习和微调。通过对多个数据集的定量评估和对真实稀疏多视点系统的定性结果验证了双场算法的有效性,显示了其在真实自由视点人体渲染方面的优越能力。
Introduce
最近,表面场[28,25,2]和辐射场[26,48]作为一种有前途的解决方案,以独立于分辨率和连续的方式建模 3D 几何形状和外观。尽管在详细的几何形状恢复[32,33,50,10]和逼真的纹理恢复和渲染[45,29]方面取得了重大进展,但在考虑几何形状和外观的同时重建时,它们的局限性就变得明显了。
现有表面场和辐射场的局限性源于连续性和解纠缠性之间的权衡。具体而言:
- 基于表面场的重建方法[32,27,20]通常在表面上学习纹理,导致预测纹理的分布高度集中在表面上。这种狭窄的纹理场通常是不连续的,阻碍了可微渲染的优化过程。
- 亮度场[26,48]可以学习连续纹理场,但其几何形状与纹理纠缠,缺乏足够的约束。这种几何外观纠缠不仅会导致几何恢复中的不一致和伪影,特别是在稀疏的多视图设置下,而且会使辐射场的训练和推断非常耗时[1]
为了克服现有神经场表示的局限性,我们提出了一种新的 DoubleField 框架,以桥接表面和辐射场,并为几何和外观学习提供连续但不纠缠的空间。具体来说,我们从网络结构和采样策略方面建立了表面场和辐射场之间的关联。
1)在我们的网络架构中,中间 MLP 学习两个字段的共享双嵌入。共享的学习空间促进了这两个领域的反向传播梯度的更新,从而可以以连续的方式学习几何和外观。
2)提出了一种曲面引导的采样策略,首先对稀疏点进行采样以确定相交表面,然后对表面周围的密集点进行采样,在亮度场中进行体绘制。该策略对辐射场施加几何约束,将几何分量从外观建模中解放出来,不仅加快了学习过程,而且提高了自由视点渲染结果的质量和一致性。
采用所提出的架构和采样策略,DoubleField 结合了两个领域的优点,自然支持基于可微渲染的自监督信号对新数据进行有效微调。
为了充分利用双场的潜在力量,我们又向前迈进了一步,利用超高分辨率输入。与只学习粗糙的图像特征不同,DoubleField 进一步增强了 view-to-view 转换器,直接将原始分辨率下图像的原始 RGB 值作为输入。这是由于观察到自由视点渲染可以被视为一个视图到视图的问题,即在给定稀疏视图图像的情况下生成新视图图像,这让人想起 NLP[31]中典型任务的文本到文本问题。为了更有效地对高保真外观进行建模,我们对网络采用了转导迁移学习方案。具体来说,我们的网络首先在低分辨率的预训练任务上进行训练,以学习一般的多视图先验,然后在处理超高分辨率输入时通过快速微调转移并采用到高保真域。然而,这不是微不足道的,因为在稀疏视图图像上进行微调容易出现过拟合。为了克服这一问题,我们进行了全面的实验来衡量不同模块的影响,并经验地引入了一种自下而上的微调策略,可以避免过度拟合和快速收敛。从稀疏视图输入进行人体重建的实验结果表明,我们的方法具有最先进的性能和高保真的渲染质量。表 1 总结了提出的 DoubleField 表示法与现有表示法的比较。

贡献:
- 我们提出了一种新的双场表示,结合了表面场和辐射场的优点。我们通过共享双嵌入和表面引导采样策略将这两个领域连接起来,以便 DoubleField 具有连续但不纠缠的几何和外观建模学习空间。
- 我们进一步增强了 DoubleField,通过引入一个视图到视图的转换器,将超高分辨率图像的原始 RGB 值作为输入,从而支持高保真渲染。View-to-view 转换器学习超高分辨率域上从已知视点到查询视点的纹理映射。
- 我们利用迁移学习方案和自下而上的微调策略来更有效地训练我们的网络,使其具有快速的收敛速度,同时避免了过拟合问题。通过这种方式,DoubleField 可以在只给出稀疏视图输入的情况下产生高保真的自由视图渲染结果,这在之前的工作中证明了显著的性能改进。
Related Work
Neural implicit field
与传统的网格、体、点云等显式表示相比,神经隐式场通过神经网络对三维模型进行编码,直接将三维位置或视点映射为相应的
- 占用值——Occupancy Networks、Learning Implicit Fields for Generative Shape Modeling[25,2]
- SDF——DeepSDF[28]
- 体积——Neural Volumes[21]
- 辐射——NeRF[26]等属性
- 神经隐式场以空间坐标为条件,而不是以离散体素或顶点为条件,具有连续、分辨率无关、更灵活的特点,可实现更高质量的表面恢复和逼真的渲染。
对于几何重建,基于表面场的方法[32,33,41]可以从一幅或几幅图像中生成详细的模型,并使用局部隐式场[14,1]实现高保真几何。对于图形渲染,基于隐式域的方法适合于可微渲染[20,44,15,35,26]。其中,最近提出的 NeRF[26]在新颖视图合成和真实感渲染方面取得了重大进展,激发了许多衍生方法[45,24,34,38,19,30]和应用。
Multi-view human reconstruction
基于 template 的人体的多视角相机在不同的层次上进行了大量的研究,包括形状和姿势[12,18],以及布料表面[4,37,8,7,42]。受表示能力的限制,这些方法通常在几何和外观恢复方面的结果质量较低。此外,这些基于模板的算法也难以处理拓扑变化。
其他高质量人体重建的方法需要极其昂贵的依赖关系,如密集视点[16,40],甚至控制照明[3,9]。
最近,隐式域[13,49,32]使稀疏视图的详细几何重建成为可能。基于稀疏 RGB-D 相机,还可以实现高保真的实时几何重建。最近,Peng 等人 Neural Body[29]提出在预定义模板(即 SMPL[22])的指导下学习神经辐射场,并在动态序列的新视图合成方面取得了令人鼓舞的结果。然而,他们的方法假设了身体模板的准确估计的可用性。此外,从稀疏视图输入同时重建高保真几何和外观对于现有的解决方案来说仍然是非常具有挑战性的。我们的工作开辟了高保真人体渲染的新途径,而不需要身体模板。
Transformer
Transformer 的有效性最近在广泛的 NLP 和 CV 问题中得到了证明[5,6,47]。注意机制是 Transformer 的核心,已被大量文献证明可以捕获远程依赖[36,39]。它获得相关性的能力已经应用于许多应用,如视觉问答[17]、纹理传输[43]、多视图立体[23]和手部姿势估计[11]。此外,基于 Transformer[5]的迁移学习在自然语言处理方面取得了重大进展,显示出巨大的泛化潜力。在我们的工作中,我们将自由视点呈现问题视为一个视图到视图的问题,并应用转换器来捕获跨多视图输入的对应关系。受前人工作的启发,我们采用迁移学习方案来解决超高分辨率图像的学习问题。
Method
Preliminary
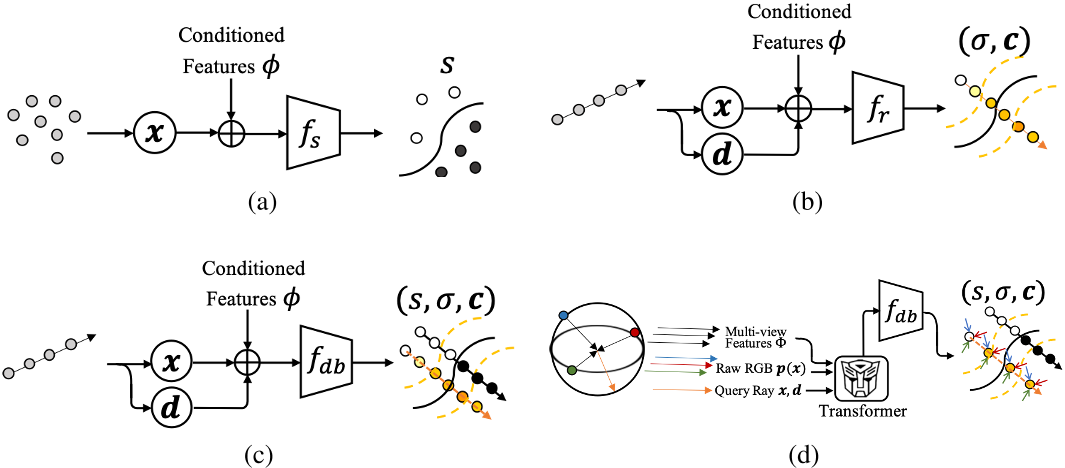
(a)虽然 PIFu 提供了一种直观的几何和外观联合建模的解决方案,但它将几何和纹理隔离开来,使得纹理的学习空间不连续,高度集中在表面周围,这种不连续的纹理空间阻碍了在纹理监督下使用可微渲染技术的优化过程
(b)NeRF,为了从稀疏的多视图输入中实现新颖的视图合成,PixelNeRF[45]扩展了 NeRF,以类似于 PIFu 的方式利用像素对齐的图像特征。由于密度和颜色的纠缠建模为 NeRF 的训练带来了很高的灵活性,在 PixelNeRF 中学习到的表面在只有稀疏视图输入的情况下是不一致的,这会导致在新视图渲染中出现幽灵或模糊结果等伪影。此外,vanilla NeRF 的高度灵活性使得其导数解的训练、推理和微调[45,29]非常耗时。
(c)The proposed DoubleField.
(d) DoubleField with the raw ultra-high-resolution inputs.
DoubleField Representation
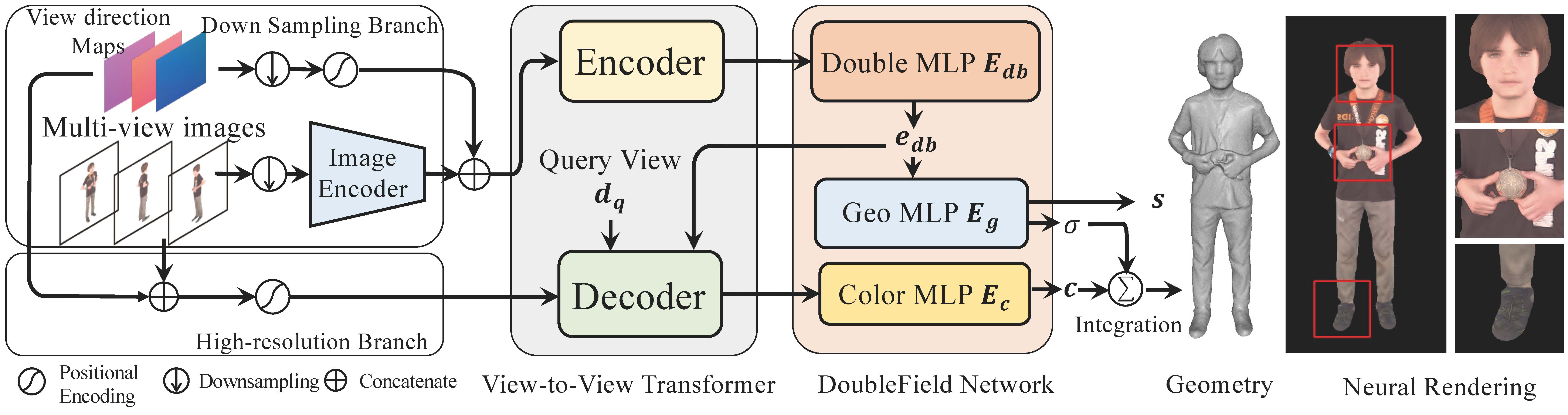
在我们的方法中,提出了一种新的神经场表示 DoubleField 来桥接表面场和辐射场。如图2(c)所示,我们的 DoubleField 可以被表述为一个相互隐式函数 $f_{db}$,由多层感知器(MLP)表示,以拟合表面场和亮度场: $f_{db}(\boldsymbol{x},\boldsymbol{d})=(s,\sigma,\boldsymbol{c}).$。两个场之间共享的 MLP 以隐式方式对亮度场施加几何约束,并鼓励更一致的密度分布以进行神经渲染。
网络架构
DoubleField 由一个用于双嵌入的共享 MLP $E_{db}$ 和两个用于几何和纹理建模的独立 MLP $E_g$ 和 $E_c$ 组成。
Eq. 4
其中γ(x)是 x 的位置编码
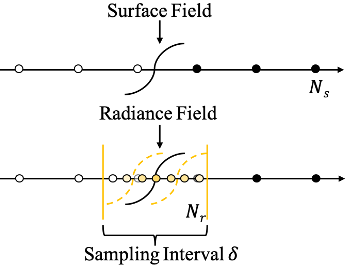
Sampling Strategy
表面引导采样策略首先确定表面场中的交点,然后在交点周围进行细粒度采样
DoubleField with Multi-view Inputs
对于查询的3D 点 x,先得到 x 在每个图像上的投影特征,然后将多视图图像中提取出来的 pixel-aligned features,融合为 $\boldsymbol{\Phi}(\boldsymbol{x})$
Eq. 5
$\begin{gathered}\Phi^i=\oplus(\phi^i(\boldsymbol{x},\boldsymbol{I}^i),\boldsymbol{d}^i)\\\boldsymbol{\Phi}(\boldsymbol{x})=\psi(\Phi^1,…,\Phi^n),\end{gathered}$
其中⊕(…) is a concatenation operator,$\psi(…)$ 是一种特征融合运算,如平均池化 PIFu[32]或自关注 DeepMultiCap。将融合后的 features $\boldsymbol{\Phi}(\boldsymbol{x})$ 作为 DoubleField 的条件特征来预测相应的几何形状和外观: $f_{db}(\boldsymbol{x},\boldsymbol{d}|\boldsymbol{\Phi}(\boldsymbol{x}))=(s,\sigma,\boldsymbol{c}).$
DoubleField on Ultra-high-resolution Domain
由于对粗糙图像特征的学习限制了最终渲染结果的质量。为了克服这个问题,我们进一步增强 DoubleField,将原始分辨率下的图像作为附加条件输入 $f_{db}(\boldsymbol{x},\boldsymbol{d}|\boldsymbol{\Phi}(\boldsymbol{x}),\boldsymbol{p}(\boldsymbol{x}))=(s,\sigma,\boldsymbol{c}),$ Eq. 6 式中 p(x)表示 x 投影处的像素 RGB 值。
视图到视图转换器在其编码器中融合原始 RGB 值和多视图特征,并通过其解码器在新视图空间产生特征。此外,将原始 RGB 值映射到高维空间作为高频外观变化学习的彩色编码。视图到视图转换器的关键组件如下所示:
- Colored Encoding:类似于位置编码[36,26],使用不同频率[26]的正弦和余弦函数,将超高分辨率图像 I 的每个像素上的原始 RGB 值 p 嵌入为彩色编码γ(p)。这样,每个单独的 RGB 值被映射到更高维度的空间,显著提高了性能,加快了收敛速度。这与之前关于神经场表征[26]和 NLP[36]的工作是一致的。
- Encoder:在我们的视图到视图转换器中,在编码器中使用了一个“完全可见”的注意掩码,这鼓励模型通过自注意机制关注与新视图相关的每个视图。编码器作为 Eq. 5中的特征融合操作ψ来获得融合后的 featuresΦ,该融合后的 featuresΦ将被馈入双 MLP $E_{db}$ 中,用于生成双嵌入 $E_{db}(\gamma(\boldsymbol{x}),\boldsymbol{\Phi}).$。
- Decoder:我们的视图到视图转换器的解码器将在稀疏视图输入上学习到的特征映射到新视点的特征。具体来说,解码器以双嵌入 $\mathbf{e}_{db}$、查询观看方向 d、查询点 x 的位置编码、RGB 值 p(x)的彩色编码作为输入,得到纹理嵌入 $\mathbf{e}_{c}:$$\boldsymbol{e}_c=D_{v2v}(\boldsymbol{e}_{db},\gamma(\boldsymbol{p}(\boldsymbol{x}))|\boldsymbol{d}).$
最后,通过纹理 MLP $E_{c}$ 预测点 x 处的高分辨率颜色。
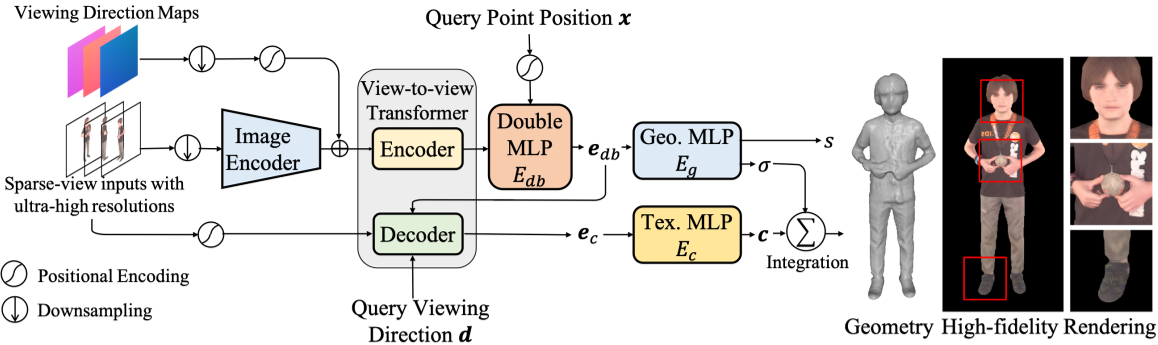
Learning High-fidelity Human Rendering
在稀疏视图人体图像的几何和外观重建上验证了双场算法的有效性。如图4所示,给定稀疏的多视图图像和相应的射线方向,我们的视点到视点转换器的编码器作为操作ψ来融合来自不同视点的低分辨率图像特征,并使用Eq. 5输出融合后的特征。该方法以融合后的特征为输入,生成双嵌入特征,并利用几何MLP预测表面场s和密度值σ。对于高保真纹理的预测,解码器以超高分辨率图像的双嵌入$e_{db}$、查询观看方向d和彩色编码p(x)为输入,生成用于预测颜色值c的纹理嵌入$e_{c}$。
虽然我们的网络可以直接在超高分辨率图像上进行训练,但是在如此高保真度的域上,昂贵的训练时间开销仍然是一个问题。为了更可行的解决方案,我们采用了一种传导迁移学习方案,将问题分为两个阶段: 低分辨率预训练和高保真微调。
在预训练阶段,网络学习下采样图像的两个粗先验:
1)人体的一般几何和外观先验
2)多视图特征与原始RGB值的融合先验
具体来说,为了训练我们的模型,我们从3D扫描数据集(如Twindom1)中收集人体模型,并渲染512 × 512大小的低分辨率图像。在微调阶段,网络以特定人类稀疏多视图的超高分辨率图像作为输入,利用多视图自监督进行微调。这样,在低分辨率图像上预训练的模型就可以适应超高分辨率领域。关于迁移学习方案的更多细节可以在手册中找到。
Experiment
我们在几个数据集上评估了我们的DoubleField表示和视图到视图转换器:
- Twindom dataset我们将1700个人体模型分成1500个用于训练的模型和200个用于评估的模型。
- THuman2.0 dataset[46],这是一个由500个高质量人体模型组成的公开数据集。
我们首先从训练、推理和微调方面验证了所提出的DoubleField。在此基础上,给出了不同调整策略的实验结果。最后,我们将我们的解决方案与先前最先进的方法进行比较。
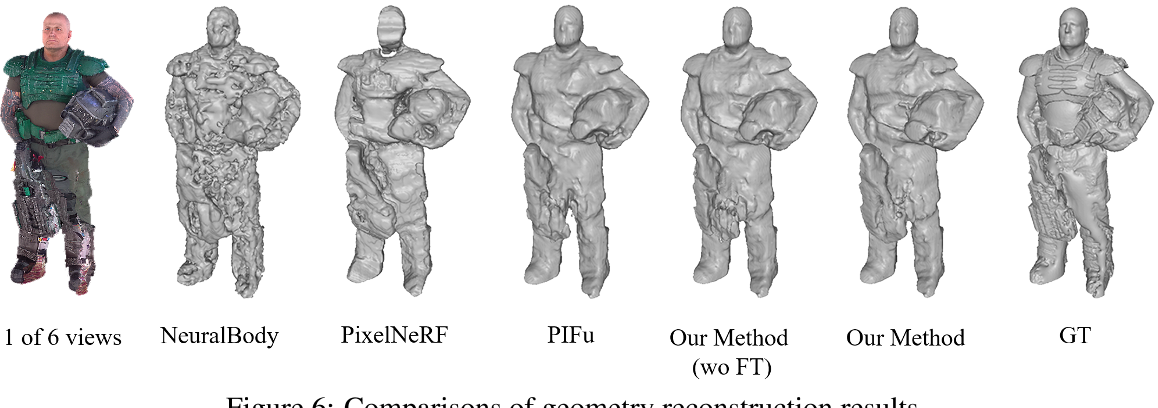
Discussion & Future Works
我们提出了双场表示,以结合几何和外观场的优点,以实现高保真的人体渲染。虽然我们的方法在稀疏视图超高分辨率输入的重建上取得了优异的性能,但高质量的3D人体模型仍然是学习几何之前必不可少的。此外,对几何优化微调的努力是有限的,这阻碍了我们的方法来处理极具挑战性的姿势。
在我们的工作中,两个领域之间的关联是以隐式的方式建立的。一个更加统一和明确的表述仍然值得探索。此外,提出的视图到视图转换器和迁移学习方案为高保真渲染提供了新的解决方案。我们希望我们的方法能够对自由视点人体渲染领域的后续工作有所启发。