| Title | ICON: Implicit Clothed humans Obtained from Normals |
|---|---|
| Author | Yuliang Xiu1, Jinlong Yang1, Dimitrios Tzionas1,2, Michael J. Black1 |
| Conf/Jour | CVPR |
| Year | 2022 |
| Project | ICON (mpg.de) |
| Paper | ICON: Implicit Clothed humans Obtained from Normals (readpaper.com) |
输入:
- 经过分割的着衣人类的RGB图像
- 从图像估计得到的SMPL身体
- SMPL身体用于指导ICON的两个模块:一个推断着衣人类的详细表面法线(前视图和后视图),另一个推断一个具有可见性感知的隐式表面(占用场的等值表面)
- 迭代反馈循环使用推断出的详细法线来优化SMPL
缺点:
- 宽松的衣服无法重建
- 依赖HPS估计出的SMPL body

Abstract
目前用于学习逼真和可动画化的3D服装化身的方法需要摆姿势的3D扫描或带有精心控制的用户姿势的2D图像。相比之下,我们的目标是仅从不受约束姿势的2D图像中学习化身。给定一组图像,我们的方法从每个图像中估计出一个详细的3D表面,然后将这些图像组合成一个可动画的化身。隐式函数非常适合第一个任务,因为它们可以捕获头发和衣服等细节。然而,目前的方法对不同的人体姿势并不健壮,并且经常产生带有断裂或无实体肢体,缺失细节或非人类形状的3D表面。问题是这些方法使用对全局姿态敏感的全局特征编码器。为了解决这个问题,我们提出了ICON(“从normal获得的隐式穿衣服的人”),它使用了局部特征。
ICON有两个主要模块,它们都利用SMPL(-X)体模型。首先,ICON根据SMPL(-X)法线推断出详细的穿衣服的人法线(前/后)。其次,能见度感知隐式表面回归器(a visibility-aware implicit surface regressor)产生人类占用场的等面。重要的是,在推断时,反馈循环在改进SMPL(-X)网格并精炼法线之间交替进行。在多种姿势下的主体的多个重建帧的情况下,我们使用SCANimate从中生成可动画的化身。在AGORA和CAPE数据集上的评估结果显示,即使在有限的训练数据情况下,ICON在重建方面也超越了现有技术。此外,它对于野外姿势/图像和超出帧范围的剪裁等不同分布的样本更加稳健。ICON迈出了一步,朝着从野外图像中稳健地重建3D着装人物的方向迈进。这使得可以直接从视频中创建具有个性化和自然姿势依赖的服装变形的化身。
Method
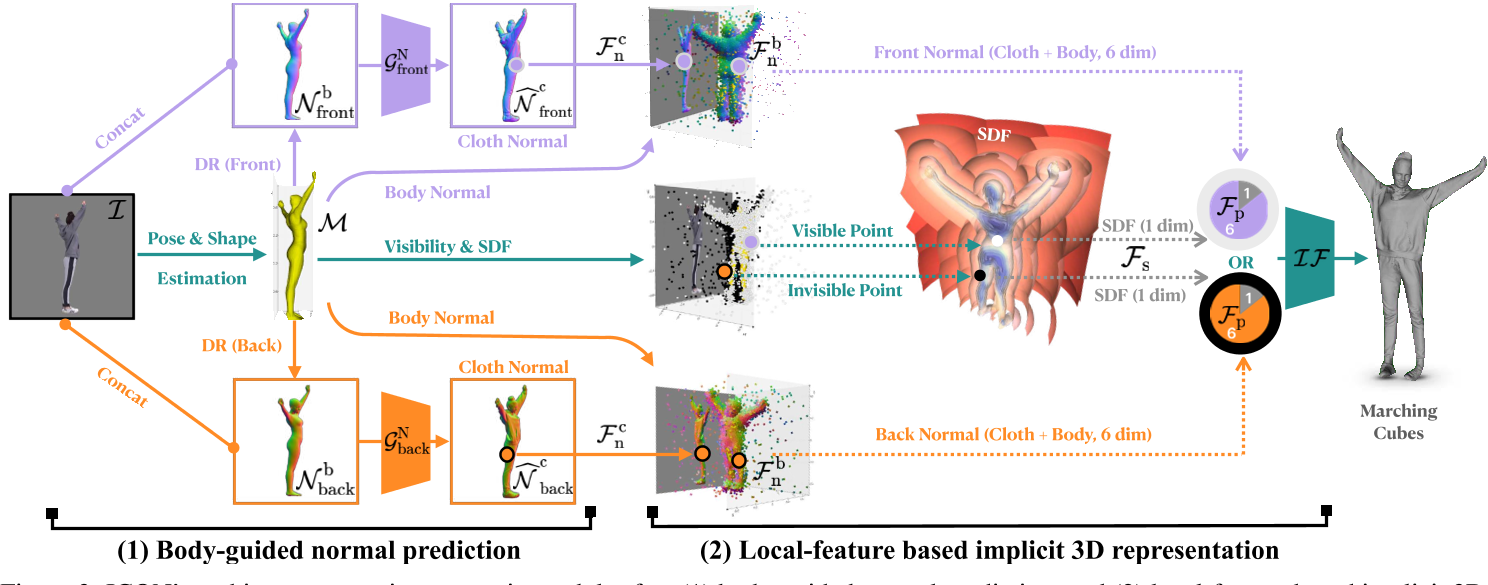
Body-guided normal prediction
PyTorch3D differentiable renderer DR render M(SMPL body) from two opposite views obtaining “front” ( i.e., observable side) and “back” ( i.e. , occluded side)
前后body法向贴图 SMPL-body normal maps: $\mathcal{N}^{\mathrm{b}}=\{\mathcal{N}_{\mathrm{front}}^{\mathrm{b}},\mathcal{N}_{\mathrm{back}}^{\mathrm{b}}\}.$
$\mathcal{N}^{\mathrm{b}}$ 和原始图片$\mathcal{I}$ ,通过法向量网络$\mathcal{G}^{\mathbb{N}}=\{\mathcal{G}_{\mathrm{front}}^{\mathbb{N}},\mathcal{G}_{\mathrm{back}}^{\mathbb{N}}\}$预测带衣服人体法向贴图$\widehat{\mathcal{N}}^{\mathrm{c}}=\{\widehat{\mathcal{N}}_{\mathrm{front}}^{\mathrm{c}},\widehat{\mathcal{N}}_{\mathrm{back}}^{\mathrm{c}}\}$
- 训练法向量网络:$\mathcal{L}_{\mathrm{N}}=\mathcal{L}_{\mathrm{pixel}}+\lambda_{\mathrm{VGG}}\mathcal{L}_{\mathrm{VGG}},$
- $\mathcal{L}_{\mathrm{pixel}}=|\mathcal{N}_{\mathrm{v}}^{\mathrm{c}}-\mathcal{N}_{\mathrm{v}}^{\mathrm{c}}|,\mathrm{v}=\{\mathrm{front},\mathrm{back}\}$是GT与预测法向量图的L1损失
- $\mathcal{L}_{\mathrm{VGG}}$是perceptual loss感知损失,有助于恢复细节
由于HPS回归器不能给出像素对齐的SMPL拟合,需要在训练中优化SMPL body的生成$\mathcal{L}_{\mathrm{SMPL}}=\min_{\theta,\beta,t}(\lambda_{\mathrm{N_diff}}\mathcal{L}_{\mathrm{N_diff}}+\mathcal{L}_{\mathrm{S_iff}}),$
- 优化形状β,姿态θ和平移t
- $\mathcal{L}_{\mathrm{N_diff}}=|\mathcal{N}^{\flat}-\widehat{\mathcal{N}^{c}}|,\quad\mathcal{L}_{\mathrm{S_diff}}=|\mathcal{S}^{\flat}-\widehat{\mathcal{S}^{c}}|,$
- $\mathcal{L}_{\mathrm{N_diff}}$:a normal-map loss (L1)
- $\mathcal{L}_\mathrm{S_diff}$ :SMPL人体法线图与人体掩模轮廓

在推理过程中,ICON交替进行:(1)使用推断的$\hat{\mathcal{N}^{\mathrm{c}}}$法线来精炼SMPL网格,(2)使用精炼的SMPL来重新推理$\hat{\mathcal{N}^{\mathrm{c}}}$
Local-feature based implicit 3D reconstruction
给定predicted clothed-body normal maps和the SMPL-body mesh,我们基于局部特征对穿衣服的人的隐式三维表面进行回归$\mathcal{F}_\mathrm{P}=[\mathcal{F}_\mathrm{s}(\mathrm{P}),\mathcal{F}_\mathrm{n}^\mathrm{b}(\mathrm{P}),\mathcal{F}_\mathrm{n}^\mathrm{c}(\mathrm{P})],$
- $\mathcal{F}_{\mathrm{s}}$是查询点P到最近身体点$\mathrm{P^{b}\in\mathcal{M}}$ 的符号距离
- $\mathcal{F}_{\mathrm{n}}^{\mathrm{b}}$是$\mathrm{P^{b}}$的质心面法线barycentric surface normal,两者都提供了针对自身遮挡的强正则化。
- $\mathcal{F}_{\mathrm{n}}^{\mathrm{c}}$是根据$\mathrm{P^{b}}$可见度,从$\widehat{\mathcal{N}}_\mathrm{front}^\mathrm{c}\operatorname{or}\widehat{\mathcal{N}}_\mathrm{back}^\mathrm{c}$提取的法向量
- $\mathcal{F}_{\mathrm{n}}^{\mathrm{c}}(\mathrm{P})=\begin{cases}\widehat{\mathcal{N}}_{\mathrm{front}}^{\mathrm{c}}(\pi(\mathrm{P}))&\text{if P}^{\mathrm{b}}\text{is visible}\\\widehat{\mathcal{N}}_{\mathrm{back}}^{\mathrm{c}}(\pi(\mathrm{P}))&\text{else},\end{cases}$
最后将$\mathcal{F}_\mathrm{P}$输入implicit function,通过MLP估计the occupancy at point P: $\widehat{o}(\mathbf{P}).$
Experiments
将ICON与PIFu[54]和PaMIR[70]进行比较
Conclusion
我们展示了ICON,它可以从单个图像中健壮地恢复3D穿衣服的人,其准确性和真实感超过了现有技术。其中有两个关键:(1)利用三维体模型对解进行正则化,同时迭代优化该体模型。(2)利用局部特征消除与全局姿态的伪相关。彻底的消融研究证实了这些选择。结果的质量足以从单目图像序列中构建3D化身
Limitations and future work.
由于ICON先前利用了强壮的身体,远离身体的宽松衣服可能难以重建;见图7。尽管ICON对体拟合的小误差具有鲁棒性,但体拟合的重大失效将导致重构失败。因为它是在正视视图上训练的,ICON在强烈的透视效果上有问题,产生不对称的肢体或解剖学上不可能的形状。一个关键的未来应用是单独使用图像来创建一个穿着衣服的化身数据集。这样的数据集可以推进人体形状生成的研究[15],对时尚行业有价值,并促进图形应用。