| Title | PIFuHD: Multi-Level Pixel-Aligned Implicit Function for High-Resolution 3D Human Digitization |
|---|---|
| Author | Shunsuke Saito1,3 Tomas Simon2 Jason Saragih2 Hanbyul Joo3 |
| Conf/Jour | CVPR |
| Year | 2020 |
| Project | PIFuHD: Multi-Level Pixel-Aligned Implicit Function for High-Resolution 3D Human Digitization (shunsukesaito.github.io) |
| Paper | PIFuHD: Multi-Level Pixel-Aligned Implicit Function for High-Resolution 3D Human Digitization (readpaper.com) |
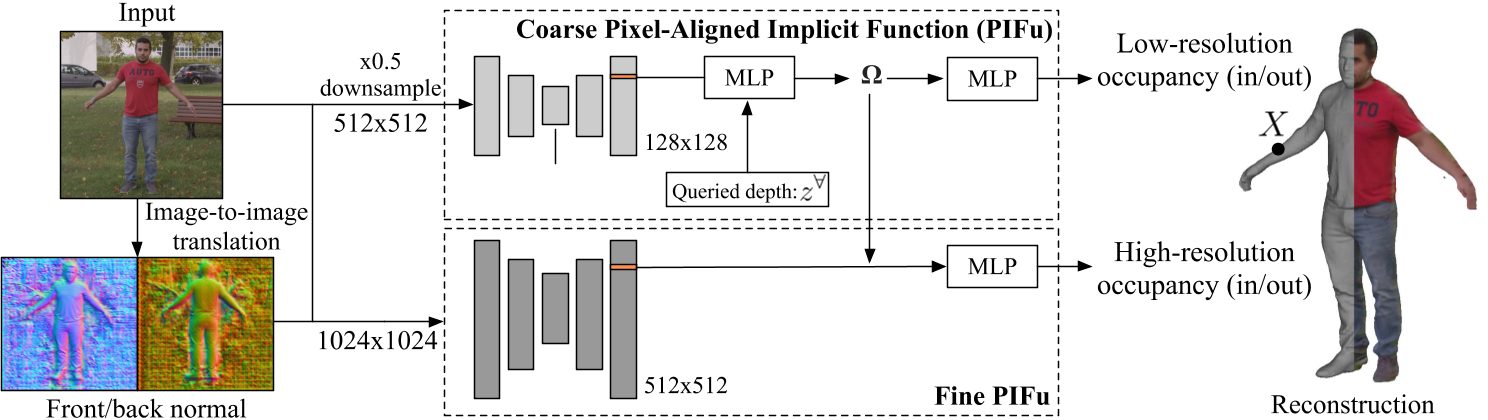
Encoder: stacked hourglass network
MLP
- Coarse L:(257, 1024, 512, 256, 128, 1)
- Fine H:(272, 512, 256, 128, 1),将Coarse MLP的第四层输出$\Omega \in \mathbb{R}^{256}$作为输入
表面法线网络:由9个残差块和4个下采样层组成 - $\mathcal{L}_{N}=\mathcal{L}_{VGG}+\lambda_{l1}\mathcal{L}_{l1},$ 其中$L_{VGG}$为Johnson等人[17]提出的感知损失,$L_{l1}$为预测与真值法向之间的l1距离
Abstract
基于图像的三维人体形状估计的最新进展是由深度神经网络提供的表示能力的显着改进所推动的。尽管目前的方法已经在现实世界中展示了潜力,但它们仍然无法产生具有输入图像中通常存在的细节水平的重建。我们认为这种限制主要源于两个相互冲突的要求; 准确的预测需要大量的背景,但精确的预测需要高分辨率。由于当前硬件的内存限制,以前的方法往往采用低分辨率图像作为输入来覆盖大的空间环境,结果产生不太精确(或低分辨率)的3D估计。我们通过制定端到端可训练的多层次体系结构来解决这一限制。粗级以较低的分辨率观察整个图像,并专注于整体推理。这为通过观察更高分辨率的图像来估计高度详细的几何形状提供了一个精细的水平。我们证明,通过充分利用k分辨率输入图像,我们的方法在单图像人体形状重建方面明显优于现有的最先进技术。
Method
Pixel-Aligned Implicit Function
$f(\mathbf{X},\mathbf{I})=\begin{cases}1&\text{if }\mathbf{X}\text{is inside mesh surface}\\0&\text{otherwise},\end{cases}$
- I为单个RGB图像
- $f(\mathbf{X},\mathbf{I})=g\left(\Phi\left(\mathbf{x},\mathbf{I}\right),Z\right),$
- $\Phi\left(\mathbf{x},\mathbf{I}\right).$表示X的正交投影到x
- $Z = X_{z}$是由二维投影x定义的射线的深度。
请注意,沿着同一条射线的所有3D点具有完全相同的图像特征Φ (x, I),来自相同的投影位置x,因此函数g应该关注不同的输入深度Z,以消除沿射线占用的3D点的歧义。
PIFu中使用的stacked hourglass可以接受整个图片,从而可以采用整体推理进行一致的深度推理,对于实现具有泛化能力的鲁棒3D重建起着重要作用,但是该表示的表达性受到特征分辨率的限制。
(在PIFu中,二维特征嵌入函数Φ使用卷积神经网络(CNN)架构,函数g使用多层感知器(MLP))
Multi-Level Pixel-Aligned Implicit Function
以1024×1024分辨率图像为输入的多级方法
- 以下采样的512 × 512图像为输入,重点整合全局几何信息,生成128 × 128分辨率的骨干图像特征
- 1024×1024分辨率图像作为输入,并产生512×512分辨率的骨干图像特征,从而添加更多细微的细节
$f^L(\mathbf{X})=g^L\left(\Phi^L\left(\mathbf{x}_L,\mathbf{I}_L,\mathbf{F}_L,\mathbf{B}_L,\right),Z\right)$
$f^{H}\left(\mathbf{X}\right)=g^{H}\left(\Phi^{H}\left(\mathbf{x}_{H},\mathbf{I}_{H},\mathbf{F}_{H},\mathbf{B}_{H},\right),\Omega(\mathbf{X})\right),$
$\mathbf{x}_H=2\mathbf{x}_L.$
$Φ^{H}$的接受域不覆盖整个图像,但由于其全卷积架构,网络可以用随机滑动窗口进行训练,并在原始图像分辨率(即1024 × 1024)下进行推断
Note: 精细层模块采用粗层提取的3D嵌入特征,而不是绝对深度值。我们的粗级模块的定义类似于PIFu,进行修改,它也采用预测的正面F和背面B法线映射
- 修改:预测人体背部的精确几何形状是一个不适定问题,因为它不能直接从图像中观察到。因此,背面必须完全由MLP预测网络推断,由于该问题的模糊性和多模态性质,三维重建往往是平滑和无特征的。这部分是由于占用损失(第3.4节)有利于不确定性下的平均重建,但也因为最终的MLP层需要学习复杂的预测函数。我们发现,如果我们将部分推理问题转移到特征提取阶段,网络可以产生更清晰的重构几何。为了做到这一点,我们预测法线映射作为图像空间中3D几何的代理,并将这些法线映射作为特征提供给像素对齐的预测器。然后,3D重建由这些地图引导,以推断特定的3D几何形状,使mlp更容易产生细节。我们使用pix2pixHD[44]网络预测图像空间中的背面和正面法线,从RGB颜色映射到法线贴图
Loss Functions and Surface Sampling
在一组采样点上使用扩展的二进制交叉熵(BCE)损失
- 其中S表示评估损失的样本集,λ是S中表面外点的比率,$f^{∗}(·)$表示该位置的GT占用,$f^{\{L,H\}}(·)$是L、H两个像素对齐隐式函数
如PIFu中所述,我们使用均匀体积样本和均匀采样表面周围的重要性采样的混合采样点,在均匀采样的表面周围使用高斯扰动。我们发现这种采样方案产生的结果比采样点与表面的距离成反比的结果更清晰
Experiments
Datasets:RenderPeople、HDRI Haven1中的163个二阶球面谐波,使用预先计算的辐射传输来渲染网格、使用COCO增强随机背景图像,不需要分割作为预处理
Discussion & Future Work
我们提出了一个多层次框架,该框架对整体信息和局部细节进行联合推理,从而在没有任何额外后处理或侧信息的情况下,从单幅图像中获得穿衣服的人的高分辨率3D重建。我们的多层次像素对齐隐式函数通过规模金字塔作为隐式3D嵌入增量传播全局上下文来实现这一点。这就避免了对具有有限先验方法的显式几何做出过早的决定。我们的实验表明,将这种3d感知环境纳入准确和精确的重建是很重要的。此外,我们表明,在图像域规避模糊大大提高了遮挡区域的三维重建细节的一致性。
由于多层方法依赖于提取3D嵌入的前几个阶段的成功,因此提高基线模型的鲁棒性有望直接提高我们的整体重建精度。未来的工作可能包括纳入人类特定的先验(例如,语义分割、姿态和参数化3D面部模型),并增加对隐式表面的2D监督[37,25],以进一步支持野外输入。