| Title | TransHuman: A Transformer-based Human Representation for Generalizable Neural Human Rendering |
|---|---|
| Author | Xiao Pan1,2,∗, Zongxin Yang1, Jianxin Ma2, Chang Zhou2, Yi Yang1,† |
| Conf/Jour | ICCV |
| Year | 2023 |
| Project | TransHuman: A Transformer-based Human Representation for Generalizable Neural Human Rendering (pansanity666.github.io) |
| Paper | TransHuman: A Transformer-based Human Representation for Generalizable Neural Human Rendering (readpaper.com) |
Abstract
在本文中,我们重点研究了广义神经人体渲染的任务,即从不同角色的多视点视频中训练条件神经辐射场(NeRF)。为了处理动态的人体运动,以前的方法主要是使用基于 SparseConvNet (SPC)的人类表征来处理绘制的 SMPL。然而,这种基于 spc 的表示,
I)在不稳定的观察空间下进行优化,导致训练和推理阶段之间的正对齐,
Ii)缺乏人体各部分之间的全局关系,这对于处理不完整的绘制 SMPL 至关重要。
针对这些问题,我们提出了一个全新的框架 TransHuman,该框架在规范空间下学习绘制的 SMPL,并通过变压器捕获人体部位之间的全局关系。具体来说,TransHuman 主要由基于变压器的人类编码(TransHE)、可变形局部辐射场(DPaRF)和细粒度细节集成(FDI)组成。TransHE 首先通过变压器在规范空间下处理绘制的 SMPL,以捕获人体部位之间的全局关系。然后,DPaRF 将每个输出标记与一个可变形的亮度字段绑定,用于对观测空间下的查询点进行编码。最后,利用 FDI 进一步整合参考图像中的细粒度信息。在 ZJUMoCap 和 H36M 上进行的大量实验表明,我们的 TransHuman 以高效率实现了最先进的新性能。
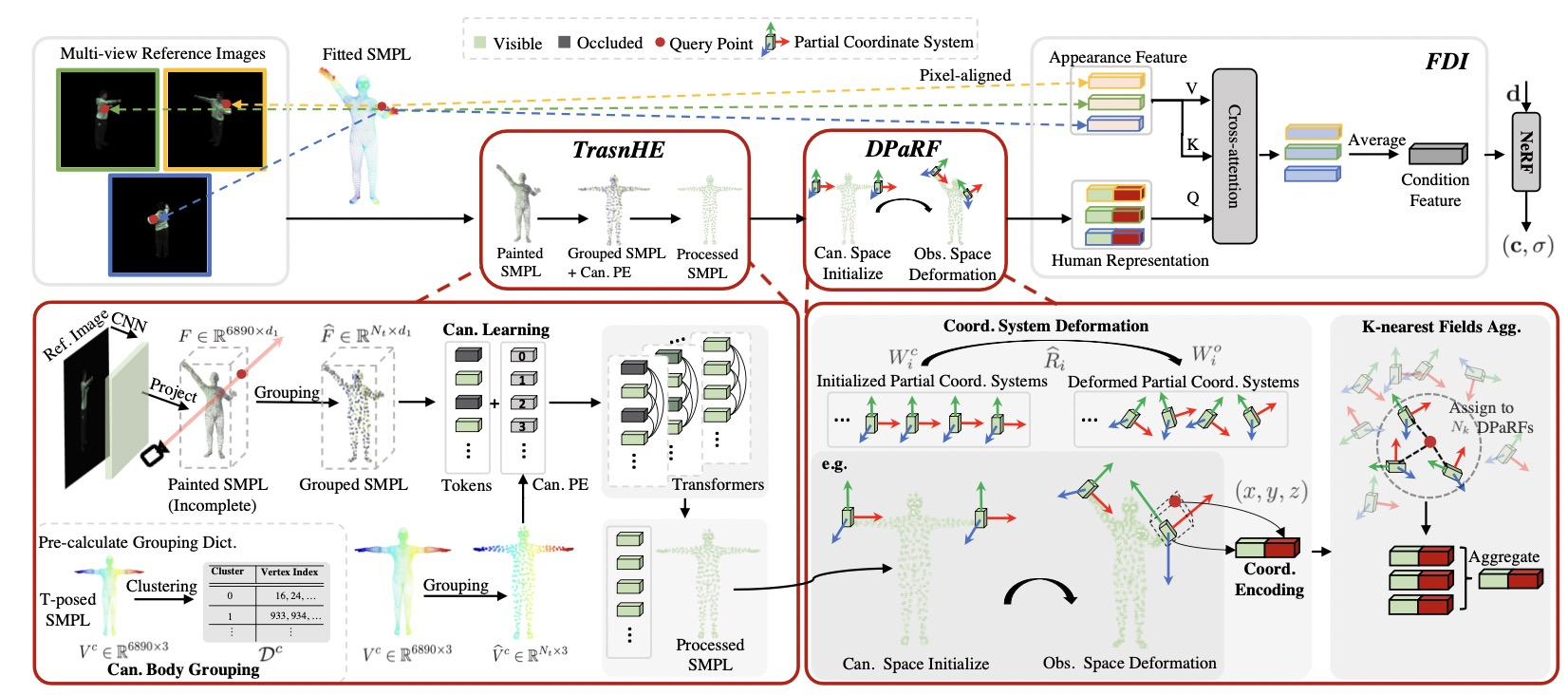
Method
TransHE 首先建立了一个管道,通过规范空间下的变压器捕获人体各部分之间的全局关系。然后,DPaRF 将坐标系统从规范空间变形回观测空间,并将查询点编码为坐标和条件特征的集合。最后,FDI 在人类表征的指导下,从像素对齐的外观特征中进一步收集观察空间的细粒度信息
Transformer-based Human Encoding
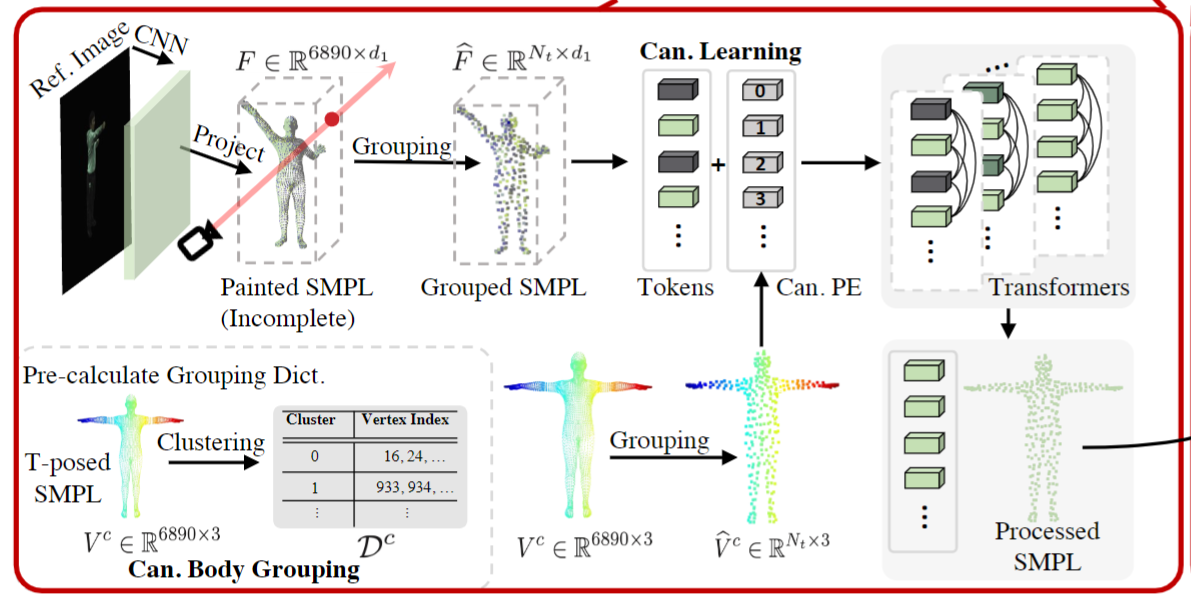
给定某一时间步长的参考图像 I 及其在观测姿态†下对应的预拟 SMPL 模型 $V^o∈\mathbb{R}^{6890×3}$,我们首先根据摄像机信息将 CNN 提取的 I 的一维深度特征投影到 V 的顶点上,得到绘制好的 SMPL : $F∈\mathbb{R}^{6890×d_1}$
以前的方法[18,5]主要是利用 Sparse CNN(SPC)[21]将painted的 SMPL 扩散到附近的空间(图1)。然而,它们在不同的观察空间下进行优化,导致训练和推理阶段之间的位姿不一致,并且三维卷积块的有限接受域使其对由于人体严重的自我遮挡而导致的未完全绘制的 SMPL 输入敏感。为了解决这些问题,我们提出了一个名为基于转换器的人体编码(TransHE)的管道,它在规范空间下捕获人体各部分之间的全局关系。TranHE 的核心包括避免语义模糊的规范化主体分组策略和简化优化和提高泛化能力的规范化学习方案。
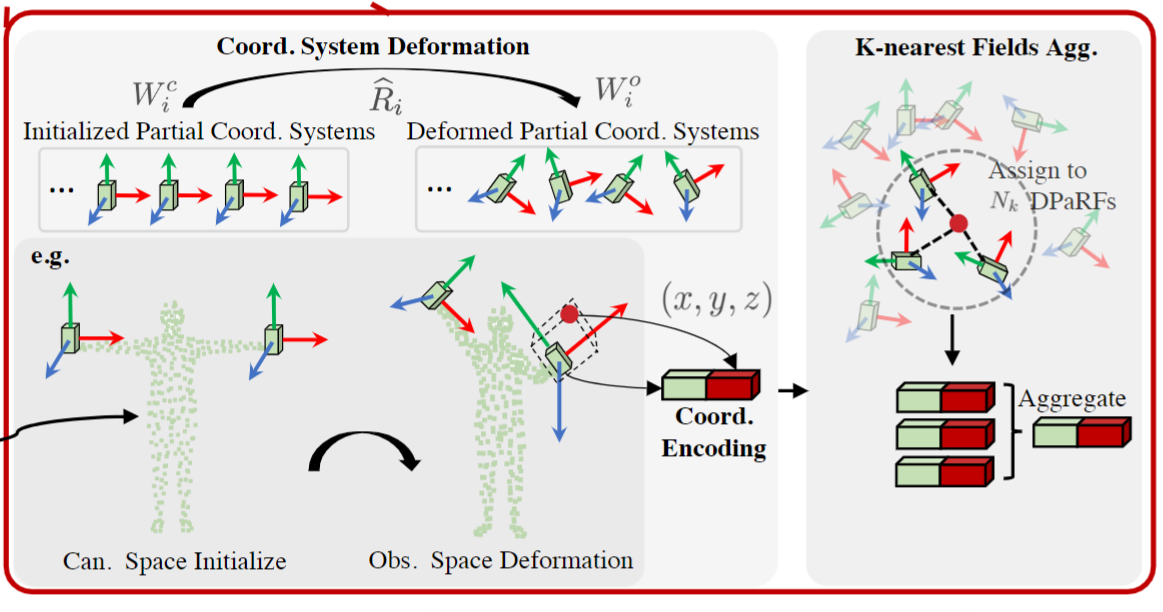
Deformable Partial Radiance Fields