| Title | Vid2Avatar: 3D Avatar Reconstruction from Videos in the Wild via Self-supervised Scene Decomposition |
|---|---|
| Author | Chen Guo1, Tianjian Jiang1, Xu Chen1,2, Jie Song1, Otmar Hilliges1 |
| Conf/Jour | CVPR 2023 |
| Year | 2023 |
| Project | Vid2Avatar: 3D Avatar Reconstruction from Videos in the Wild via Self-supervised Scene Decomposition (moygcc.github.io) |
| Paper | Vid2Avatar: 3D Avatar Reconstruction from Videos in the Wild via Self-supervised Scene Decomposition (readpaper.com) |
Idea:$\mathcal{L}_\mathrm{dec}=\lambda_\mathrm{BCE}\mathcal{L}_\mathrm{BCE}+\lambda_\mathrm{sparse}\mathcal{L}_\mathrm{sparse}.$
- 不透明度稀疏正则化$\mathcal{L}_{\mathrm{sparse}}^i=\frac1{|\mathcal{R}_{\mathrm{off}}^i|}\sum_{\mathbf{r}\in\mathcal{R}_{\mathrm{off}}^i}|\alpha^H(\mathbf{r})|.$惩罚与subject不相交的光线的非零光线不透明度
- 自监督射线分类$\begin{aligned}\mathcal{L}_\mathrm{BCE}^i&=-\frac{1}{|\mathcal{R}^i|}\sum_{\mathrm{r}\in\mathcal{R}^i}(\alpha^H(\mathbf{r})\log(\alpha^H(\mathbf{r}))\\&+(1-\alpha^H(\mathbf{r}))\log(1-\alpha^H(\mathbf{r}))),\end{aligned}$鼓励包含完全透明或不透明光线的光线分布
Abstract
我们提出了Vid2Avatar,一种从野外单目视频中学习人类Avatar的方法。从野外单目视频中重建自然移动的人类是困难的。解决这个问题需要准确地将人类与任意背景分离开来。此外,它需要从短视频序列中重建详细的3D表面,使问题变得更加具有挑战性。尽管面临这些挑战,我们的方法不需要任何来自大规模服装人体扫描数据集的地面真值监督或先验知识,也不依赖于任何外部分割模块。相反,它通过在三维中直接对场景中的人类和背景建模,通过两个分开的神经场参数化来解决场景分解和表面重建任务。具体来说,我们在规范空间中定义了一个时间一致的人类表示,并制定了一个全局优化,涵盖了背景模型、规范人体形状和纹理,以及每帧人体姿势参数。引入了一种粗到细的体积渲染采样策略和新的目标,用于清晰分离动态人体和静态背景,从而产生详细且稳健的3D人体几何重建。我们在公开可用的数据集上评估了我们的方法,并展示了相对于先前技术的改进。
Method
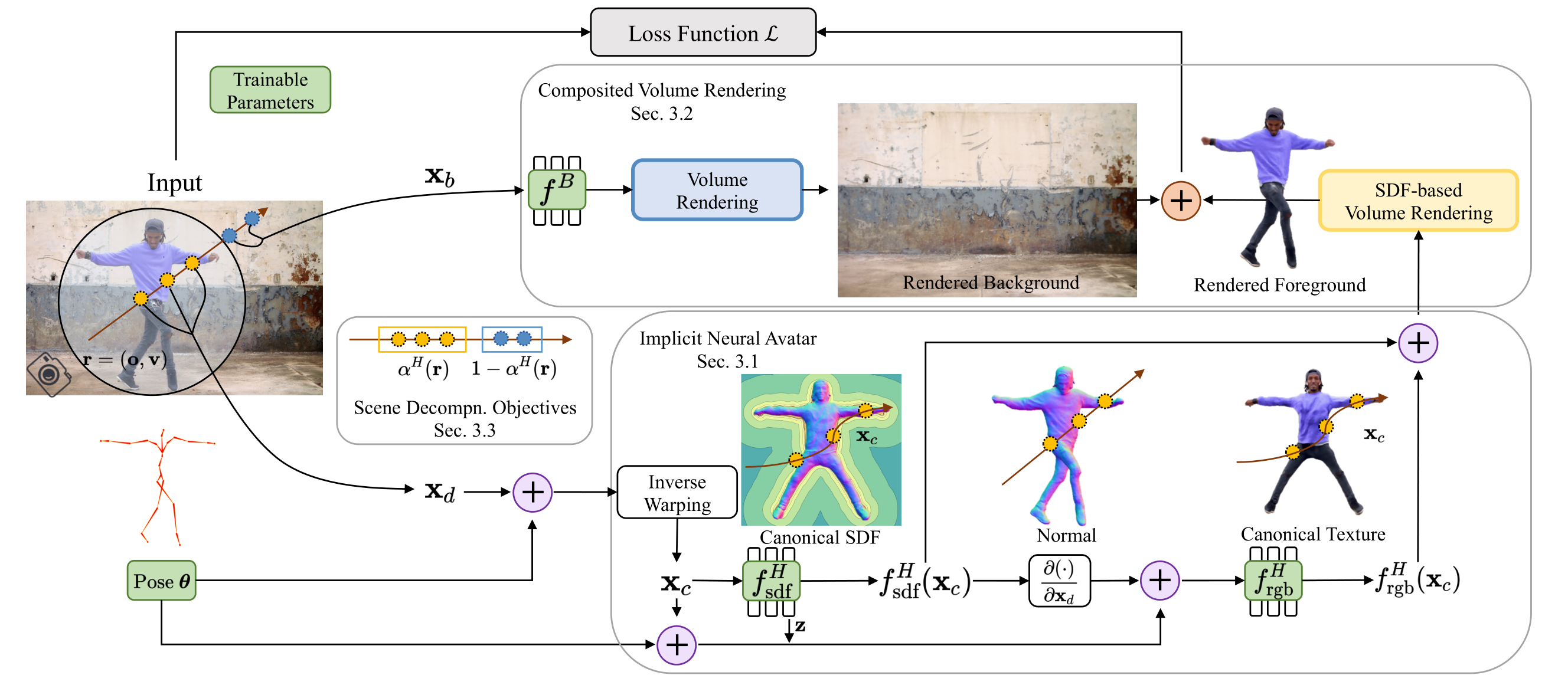
与前背景分离思想相同,一个网络用来预测背景,另一个网络用来预测前景(人体)的SDF和Color,然后预测背景+前景与输入视频帧的Loss用来优化网络
使用了人体姿势参数Pose(类似SMPL的定义),在前景球内将人体warp到规范空间,预测人体的Canonical Shape Representation SDF,在变形空间中计算采样点的空间梯度。对动态前景采用基于表面的体绘制(NeuS),对背景采用标准体绘制(NeRF)
我们扩展了 NeRF++ [66] 的倒置球体参数化来表示场景:外部体积(即背景)覆盖球内体积(即假设被人类占据的空间)的补,两者都由单独的网络建模。然后通过合成得到最终的像素值。
Experiments
The training usually takes 24-48 hours.
Limitations
虽然很容易获得,但Vid2Avatar 依赖于合理的姿态估计作为输入。此外,裙子或自由流动的服装等宽松的衣服由于其快速的动态而带来了重大挑战。我们参考Supp。Mat 对限制和社会影响进行更详细的讨论。
Conclusion
在本文中,我们提出了Vid2Avatar,通过自监督场景分解从单目野外视频中重建详细的3DAvatar。我们的方法不需要任何从穿着衣服的人体扫描的大型数据集中提取的groundtruth监督或先验,我们也不依赖于任何外部分割模块。通过精心设计的背景建模和时间一致的规范人类表示,建立了具有新颖场景分解目标的全局优化,通过可微复合体绘制联合优化背景场、规范人体形状和外观的参数,以及整个序列的人体姿态估计。我们的方法从单目视频中实现了鲁棒和高保真的人体重建。