| Title | A Hierarchical Representation Network for Accurate and Detailed Face Reconstruction from In-The-Wild Images |
|---|---|
| Author | Biwen Lei Jianqiang Ren Mengyang Feng Miaomiao Cui Xuansong Xie |
| Conf/Jour | CVPR |
| Year | 2023 |
| Project | HRN (younglbw.github.io) |
| Paper | A Hierarchical Representation Network for Accurate and Detailed Face Reconstruction from In-The-Wild Images (readpaper.com) |
缺点:
- 需要3D 先验:每张图像的GT变形图和位移图
Idea: - Contour-aware Loss. 新的轮廓感知损失算法,目的是拉动边缘的顶点以对齐面部轮廓
Abstract
由于3DMM的低维表示容量的性质限制,大多数基于3DMM(3D Morphable models)的人脸重建(FR)方法无法恢复高频面部细节,如皱纹、酒窝等。一些尝试通过引入细节映射或非线性操作来解决这个问题,然而结果仍然不够生动。为此,本文提出了一种新的分层表示网络(HRN),以实现从单一图像精确和详细的面部重建。具体而言,我们实施了几何解耦,并引入了分层表示来实现详细的面部建模。同时,还融合了面部细节的3D先验,以提高重建结果的准确性和真实性。我们还提出了一个去除修饰模块,以实现更好地解耦几何和外观。值得注意的是,我们的框架可以通过考虑不同视图的细节一致性扩展为多视图模式。对两个单视图和两个多视图FR基准的大量实验表明,我们的方法在重建准确性和视觉效果方面优于现有方法。最后,我们introduce了一个高质量的3D人脸数据集FaceHD-100,以推动高保真度人脸重建的研究。
Method
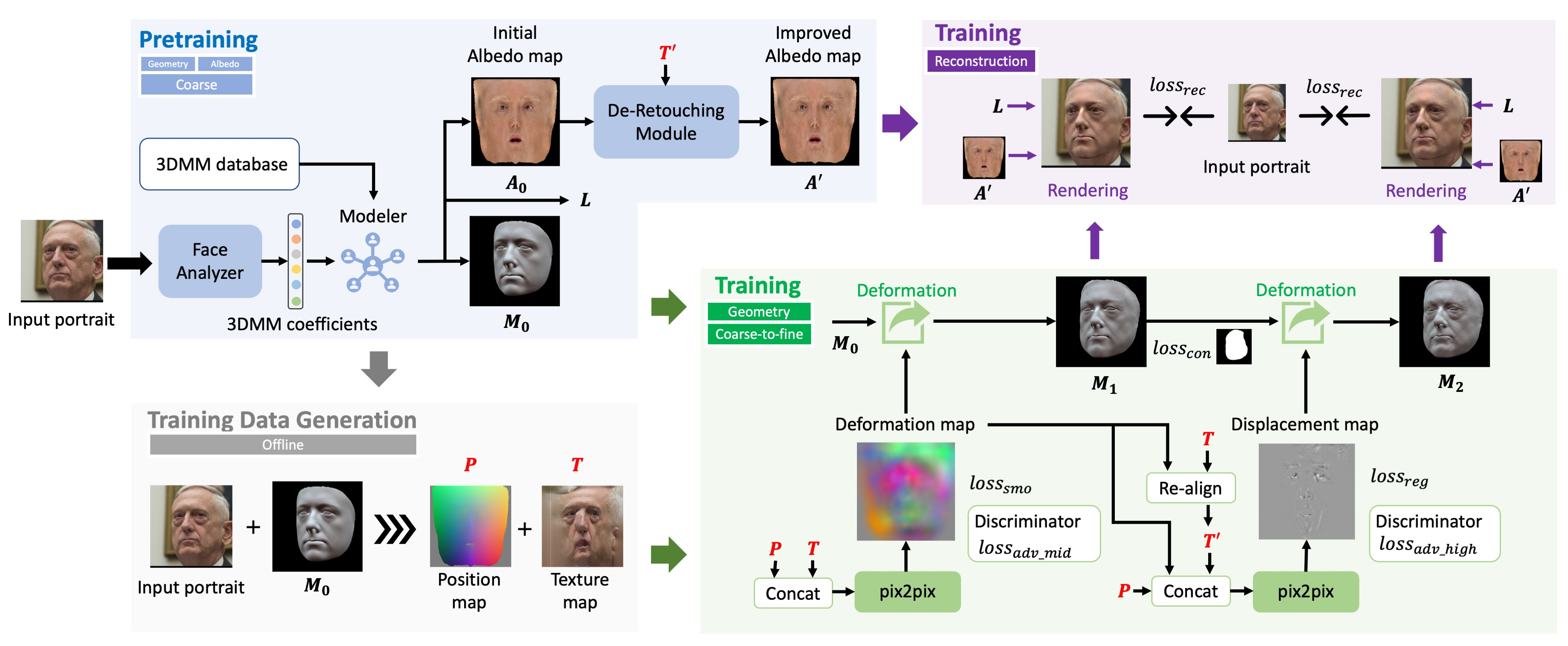
分层建模:
- 低频部分:通过Basel Face Model(BFM是一种用于描述人脸形状和纹理的数学模型)作为基模型,实现输入面粗重构
- 中频细节:然后我们引入一个三通道变形图,它位于UV空间中,表示每个顶点相对于粗结果的偏移量。变形图作为中频细节的表示,提供了一种灵活的几何操作方法
- 高频细节:我们采用了[19]类似的位移图,是一个单通道图,表示沿法线方向的几何变形。位移图以像素的方式转换为渲染过程中使用的详细法线,以展示所有微小的细节,打破了基础模型顶点密度的限制
输入人脸肖像:
- Pretraining + Training Data Generation
- 使用回归网络作为人脸分析器预测BFM系数
- 利用3DMM数据库中的相应基得到粗对齐的meshM0和反照率A0
- 结合I和M0,我们可以通过采用从粗到细的可微渲染策略,在UV空间中获得内嵌纹理T
- De-Retouching Module 将纹理细节烘烤到粗反照率A0中
- Training Geometry 使用两个pix2pix网络依次合成变形图和位移图
- 将P和T concat 起来输入进pix2pix网络得到变形图(中频)
- 考虑到变形图会改变人脸几何,导致T与变形网格不对齐,我们通过将三通道变形图投影到二维空间,并将其转换为反转流F来重新对齐T,从而生成重新对齐的纹理T ‘作为第二个pix2pix网络的输入,得到位移图(高频)
- Training Reconstruction
- 结合光照L和去除触摸模块生成的精细反照率,完成了单幅图像的详细人脸重建
提出了一个新数据集:由来自100个受试者的2000个高清三维网格和相应的多视图图像组成,数据由9个单反相机和8个LED灯组成的多视图3D重建系统捕获。9个摄像头均匀分布在脸部前方和侧面,每个摄像头提供8K图像,用于几何和纹理重建
Conclusion
在本文中,我们提出了一种新的层次表示网络(HRN),用于从野外图像中精确和详细地重建人脸。具体而言,我们通过分层表示学习实现了面部几何解纠缠和建模。进一步结合细节的三维先验,提高重建结果的精度和视觉效果。此外,我们还提出了一个去修饰网络,以减轻几何和外观之间的歧义。此外,我们将HRN扩展到多视图模式,并引入了高质量的3D人脸数据集FaceHD-100,以促进稀疏视图FR的研究。大量实验表明,我们的方法在精度和视觉效果方面都优于现有方法