基于Pytorch学习DL时,学习到的一些技巧/code
Tips
Loss (NAN)
损失函数在训练过程中,突然变得很大或者nan
添加 torch.cuda.amp.GradScaler() 解决 loss为nan或inf的问题
环境配置
windows
关于国内conda安装cuda11.6+pytorch的那些事。 – 王大神 (dashen.wang)
使用miniconda创建虚拟环境
- conda create -n mine python=3.8
- conda activate mine
安装cuda
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| 换源:
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/menpo/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/bioconda/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/msys2/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge
conda config --set show_channel_urls true
安装:
conda install pytorch torchvision torchaudio pytorch-cuda=11.6
Found conflicts:
Package pytorch conflicts for:
torchaudio -> pytorch[version='1.10.0|1.10.1|1.10.2|1.11.0|1.12.0|1.12.1|1.13.0|1.13.1|2.0
.0|2.0.1|1.9.1|1.9.0|1.8.1|1.8.0|1.7.1|1.7.0|1.6.0']
torchvision -> pytorch[version='1.10.0|1.10.1|1.10.2|2.0.1|2.0.0|1.13.1|1.13.0|1.12.1|1.12
.0|1.11.0|1.9.1|1.9.0|1.8.1|1.8.0|1.7.1|1.7.0|1.6.0|1.5.1']
...
使用以下命令安装
> conda install -c gpytorch gpytorch
安装带cuda的torch
pip install torch==2.0.0+cu118 torchvision==0.15.1+cu118 torchaudio==2.0.1 --index-url https://download.pytorch.org/whl/cu118 --user
|
GPU
1
2
3
4
5
6
7
8
9
10
11
12
13
| Neus:
torch.set_default_tensor_type('torch.cuda.FloatTensor')
parser.add_argument('--gpu', type=int, default=0)
torch.cuda.set_device(args.gpu)
self.device = torch.device('cuda')
network = Network(**self.conf['model.nerf']).to(self.device)
#################################################################
NeRF:
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = NeRF().to(device)
render_poses = torch.Tensor(render_poses).to(device)
|
1
2
3
4
5
6
7
8
9
| torch.device('cpu'), torch.device('cuda'), torch.device('cuda:1')
如果有多个GPU,我们使用`torch.device(f'cuda:{i}')` 来表示第i块GPU(i从0开始)。 另外,`cuda:0`和`cuda`是等价的。
查询gpu数量
torch.cuda.device_count()
查询张量所在设备
x = torch.tensor([1, 2, 3])
x.device #device(type='cpu') 默认为gpu,也可为cpu
|
两张量相互运算需要在同一台设备上Z = X.cuda(1)
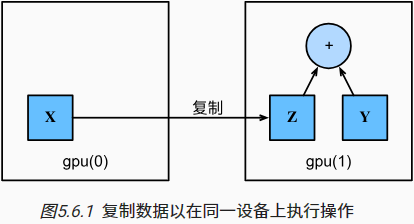
1
2
3
| 给网络指定设备
net = nn.Sequential(nn.Linear(3, 1))
net = net.to(device=try_gpu())
|
==只要所有的数据和参数都在同一个设备上, 我们就可以有效地学习模型==
Autograd
PyTorch 的 Autograd - 知乎 (zhihu.com)
Optimizer
Adam多个model参数,然后更新lr
Adam_in_Neus: params_to_train is a list
1
2
3
4
5
6
7
8
9
10
11
| params_to_train = []
self.nerf_outside = NeRF(**self.conf['model.nerf']).to(self.device) # 创建一个NeRF网络
self.sdf_network = SDFNetwork(**self.conf['model.sdf_network']).to(self.device) # 创建一个SDF网络
self.deviation_network = SingleVarianceNetwork(**self.conf['model.variance_network']).to(self.device)
self.color_network = RenderingNetwork(**self.conf['model.rendering_network']).to(self.device)
params_to_train += list(self.nerf_outside.parameters())
params_to_train += list(self.sdf_network.parameters())
params_to_train += list(self.deviation_network.parameters())
params_to_train += list(self.color_network.parameters())
self.optimizer = torch.optim.Adam(params_to_train, lr=self.learning_rate)
|
然后更新学习率
g = self.optimizer.param_groups[index]
1
2
| for g in self.optimizer.param_groups:
g['lr'] = self.learning_rate * learning_factor
|
from
1
2
3
4
5
6
7
8
9
10
| def update_learning_rate(self):
if self.iter_step < self.warm_up_end:
learning_factor = self.iter_step / self.warm_up_end
else:
alpha = self.learning_rate_alpha
progress = (self.iter_step - self.warm_up_end) / (self.end_iter - self.warm_up_end)
learning_factor = (np.cos(np.pi * progress) + 1.0) * 0.5 * (1 - alpha) + alpha
for g in self.optimizer.param_groups:
g['lr'] = self.learning_rate * learning_factor
|
lr学习率
lr scheduler介绍和可视化 - 知乎 (zhihu.com)
lr_scheduler.nameLR
| nameLR |
Brief |
| ConstantLR |
init_lr乘以factor持续total_iters |
| CosineAnnealingLR |
构造一个cos函数,周期为2T_max,学习率区间为[init_lr,eta_min],cos向左平移last_epoch个iter |
| CyclicLR |
三种mode:triangular三角波amplitude不变,triangular2每个cycle的amplitude减半,exp_range每个cycle iteration将amplitude缩放为$gamma^{iteration}$ |
| ExponentialLR |
指数减小lr:$gamma^{iter}$ |
| LambdaLR |
使用自定义的lambda来处理lr |
| StepLR |
阶梯每step_size步将lr乘以gamma |
| MultiStepLR |
在milestones = [30,80]处将lr乘以gamma |
| OneCycleLR |
not chainable,lr先上升到max_lr,然后减小。最大值处的step为total_step * pct_start = epochs * steps_per_epoch * pct_start |
| ConstantLR |
前total_iters的lr为init_lr * factor |
| LinearLR |
从init_lr * start_factor开始线性增长total_iters步到 init_lr * end_factor |
| MultiplicativeLR |
学习率从init_lr 根据lr_lambda = lambda step: factor非线性衰减:$lr = factor^{step}$ |
连接多个lr
| nameLR |
Brief |
| SequentialLR |
milestones前为scheduler1,后为scheduler2 |
| ChainedScheduler |
多个scheduler叠加 |
|
Tips
在使用SequentialLR将多个scheduler连接起来时,SequentialLR的每个milestones都会从每个scheduler的0处开始,因此Step_scheduler的milestones要设置成milestones=[1],这样设置会导致当Exp_scheduler结束时,先跳一下到ori_lr,然后step到ori_lr * 0.4
1
2
3
4
| Con_scheduler = optim.lr_scheduler.ConstantLR(optimizer, factor=1.0, total_iters=total_iters)
Exp_scheduler = optim.lr_scheduler.ExponentialLR(optimizer, gamma=gamma)
Step_scheduler = optim.lr_scheduler.MultiStepLR(optimizer, milestones=[1], gamma=0.4)
scheduler = optim.lr_scheduler.SequentialLR(optimizer, schedulers=[Con_scheduler,Exp_scheduler, Step_scheduler], milestones=[total_iters,total_iters+exp_iters])
|
EMA指数移动平均
【炼丹技巧】指数移动平均(EMA)的原理及PyTorch实现 - 知乎
在深度学习中,经常会使用EMA(指数移动平均)这个方法对模型的参数做平均,以求提高测试指标并增加模型鲁棒。
普通的平均:
EMA:$v_t=\beta\cdot v_{t-1}+(1-\beta)\cdot\theta_t$ $v_{t}$前t条数据的平均值,$\beta$是加权权重值 (一般设为0.9-0.999)。
上面讲的是广义的ema定义和计算方法,特别的,在深度学习的优化过程中, $\theta_{t}$ 是t时刻的模型权重weights, $v_{t}$是t时刻的影子权重(shadow weights)。在梯度下降的过程中,会一直维护着这个影子权重,但是这个影子权重并不会参与训练。基本的假设是,模型权重在最后的n步内,会在实际的最优点处抖动,所以我们取最后n步的平均,能使得模型更加的鲁棒。
1
2
3
4
5
6
7
8
9
10
11
12
| ema:
decay: 0.995
update_interval: 10
from ema_pytorch import EMA
self.ema = EMA(self.model, beta=ema_decay, update_every=ema_update_every).to(self.device)
self.ema.update()
sample = self.ema.ema_model.generate_mts(batch_size=size_every)
|
私有成员
带双下划线函数
| function |
brief description |
nn.module.__repr__ |
当print(model)时会运行该函数 |
__del__ |
当del object时运行该函数 |
torch.cuda
cuda事件计算程序运行时间
1
2
3
4
5
6
7
| iter_start = torch.cuda.Event(enable_timing = True)
iter_end = torch.cuda.Event(enable_timing = True)
iter_start.record()
iter_end.record()
print(f'iter time: {iter_start.elapsed_time(iter_end)}')
|
eg:
1
2
3
4
5
6
7
8
9
10
11
12
| import torch
iter_start = torch.cuda.Event(enable_timing = True)
iter_end = torch.cuda.Event(enable_timing = True)
iter_start.record()
a = torch.tensor([1,2,3,4,5,6,7,8,9,10]).cuda()
iter_end.record()
timestamp = iter_start.elapsed_time(iter_end)
print(f'iter time: {timestamp:03f}')
|