本项目yq010105/NeRF-Mine (github.com)基于Instant-nsr-pl(NSR,NGP,PytorchLightning)代码构建
- 保留 omegaconf、nerfacc、Mip-nerf_loss,类似文件结构
- 去除 pytorch-lightning 框架,使用 pytorch
NeRF 主要部分:
- 神经网络结构 —> 训练出来模型,即 3D 模型的隐式表达
- 网络类型一般为 MLP,相当于训练一个函数,输入采样点的位置,可以输出该点的信息(eg: density, sdf, color…)
- 采样方式:沿着光线进行采样获取采样点
- 位置编码:对采样点的位置 xyz 和方向 dir 进行编码,使得 MLP 的输入为高频的信息
- 数学相关:光线的生成、坐标变换、体渲染公式、BRDF……
- 体渲染函数:
- NeRF:$\mathrm{C}(r)=\int_{\mathrm{t}_{\mathrm{n}}}^{\mathrm{t}_{\mathrm{f}}} \mathrm{T}(\mathrm{t}) \sigma(\mathrm{r}(\mathrm{t})) \mathrm{c}(\mathrm{r}(\mathrm{t}), \mathrm{d}) \mathrm{dt} =\sum_{i=1}^{N} T_{i}\left(1-\exp \left(-\sigma_{i} \delta_{i}\right)\right) \mathbf{c}_{i}$
- 不透明度$\sigma$,累计透光率 —> 权重
- 颜色值
- Neus:$C(\mathbf{o},\mathbf{v})=\int_{0}^{+\infty}w(t)c(\mathbf{p}(t),\mathbf{v})\mathrm{d}t$
- sdf, dirs, gradients, invs —> $\alpha$ —> 权重
- 颜色值
- NeRO:$\mathbf{c}(\omega_{0})=\mathbf{c}_{\mathrm{diffuse}}+\mathbf{c}_{\mathrm{specular}} =\int_{\Omega}(1-m)\frac{\mathbf{a}}{\pi}L(\omega_{i})(\omega_{i}\cdot\mathbf{n})d\omega_{i} + \int_{\Omega}\frac{DFG}{4(\omega_{i}\cdot\mathbf{n})(\omega_{0}\cdot\mathbf{n})}L(\omega_{i})(\omega_{i}\cdot\mathbf{n})d\omega_{i}$
- 漫反射颜色:Light(直射光),金属度 m、反照率 a
- 镜面反射颜色:Light(直射光+间接光),金属度 m、反照率 a、粗糙度$\rho$ ,碰撞概率 occ_prob,间接光碰撞 human 的 human_light
- 详情见NeRO Code
- NeRF:$\mathrm{C}(r)=\int_{\mathrm{t}_{\mathrm{n}}}^{\mathrm{t}_{\mathrm{f}}} \mathrm{T}(\mathrm{t}) \sigma(\mathrm{r}(\mathrm{t})) \mathrm{c}(\mathrm{r}(\mathrm{t}), \mathrm{d}) \mathrm{dt} =\sum_{i=1}^{N} T_{i}\left(1-\exp \left(-\sigma_{i} \delta_{i}\right)\right) \mathbf{c}_{i}$
- 隐式模型导出(.stl、.obj、.ply 等)显式模型(Marching Cube):利用 trimesh,torchmcubes,mcubes 等库
- 根据 sdf 和 threshold,获取物体表面的 vertices 和 faces(如需还要生成 vertices 对应的 colors)。
- 然后根据 vertices、faces 和 colors,由 trimesh 生成 mesh 并导出模型为 obj 等格式
Future:
- [ ] 消除颜色 or 纹理与几何的歧义,Neus(X—>MLP—>SDF)的方法会将物体的纹理建模到物体的几何中
- [x] 只关注前景物体的建模,可以结合 SAM 将图片中的 interest object 分割出来: Rembg分割后效果也不好
NeRF-Mine 文件结构:
- confs/ 配置文件
- dtu.yaml
- encoder/ 编码方式
- get_encoding.py
- frequency.py
- hashgrid.py
- spherical.py
- process_data/ 处理数据集
- dtu.py
- models/ 放一些网络的结构和网络的运行和方法
- network.py 基本网络结构
- neus.py neus 的网络结构
- utils.py
- systems/ 训练的程序
- neus.py 训练 neus 的程序
- utils/ 工具类函数
- run.py 主程序
- inputs/ 数据集
- outputs/ 输出和 log 文件
- logs filepath: /root/tf-logs/name_in_conf/trial_name
1 | # 训练 |
Question2023.9.17
- mesh 精度:
- 一个可以评价模型质量的指标,目前大部分方法都只能通过定性的观察来判断,而定量的比较只能比较渲染图片,而不能比较模型
- 改进
- x Method1,提高前景 occupy grid 的分辨率,虽然细节颜色更加正确,但同时带来 eikonal 项损失难收敛的问题
- x Method2,将前景和背景的 loss 分开反向传播,loss_fg 只反向传播到 fg 的 MLP。由于无法准确预测光线/像素是背景还是前景,因此重建效果很差。
- x bg 的 loss 只有 L1_rgb 的话,求出来的 loss 没有 grad_fn,无法反向传播,添加条件 if loss_bg.grad_fn is not None,效果不好
- Method3,先用之前方法训练得到一个深度 mask
- mesh 颜色:
- neus 方式逆变换采样训练出来的 color,会分布在整个空间中,因此虽然 render 出来的视频效果很好,但是 mesh 表面点的颜色会被稀释
How to reconstruct texture after generating mesh ? · Issue #48 · Totoro97/NeuS (github.com) >What can we do with our own trained model? · Issue #44 · bmild/nerf (github.com)
Neus: 表面点的颜色

如果采用更快速的 NGP+Neus 的方法,由于使用了占空网格的方式采样,因此不会将表面点的颜色散射到空间背景中,这样在 extract mesh 的时候,使用简单的法向量模拟方向向量,即可得到很好的效果
Instant-nsr-pl 表面点颜色:
实验
环境配置
1 | # conda 技巧 |
EXP
exp1
1 | python imgs2poses.py E:\3\Work\EXP\exp1\dataset\Miku_exp1 |

exp2
1 | python imgs2poses.py E:\3\Work\EXP\exp2\dataset\Miku_exp2 |
Dataset
数据集:
| Paper | Dataset | Link |
|---|---|---|
| NeRF | nerf_synthetic,nerf_llff_data,LINEMOD,deepvoxels | bmild/nerf: Code release for NeRF (Neural Radiance Fields) (github.com) |
| Neus | dtu,BlenderMVS,custom | Totoro97/NeuS: Code release for NeuS (github.com) |
| Point-NeRF | dtu,nerf_synthetic,ScanNet,Tanks and temple | Xharlie/pointnerf: Point-NeRF: Point-based Neural Radiance Fields (github.com) |
自定义数据集:
NeuS/preprocess_custom_data at main · Totoro97/NeuS (github.com) - Neus_custom_data - Neus-Instant-nsr-pl - 大概需要的视图数量 20Simple/40Complex ref: https://arxiv.org/abs/2310.00684
1 | <case_name> |
neuralangelo 提供了 blender 插件可以可视化 colmap 数据,但是会出现 image plane 与 camera plane 不重合的情况
1 | DATA_PATH |
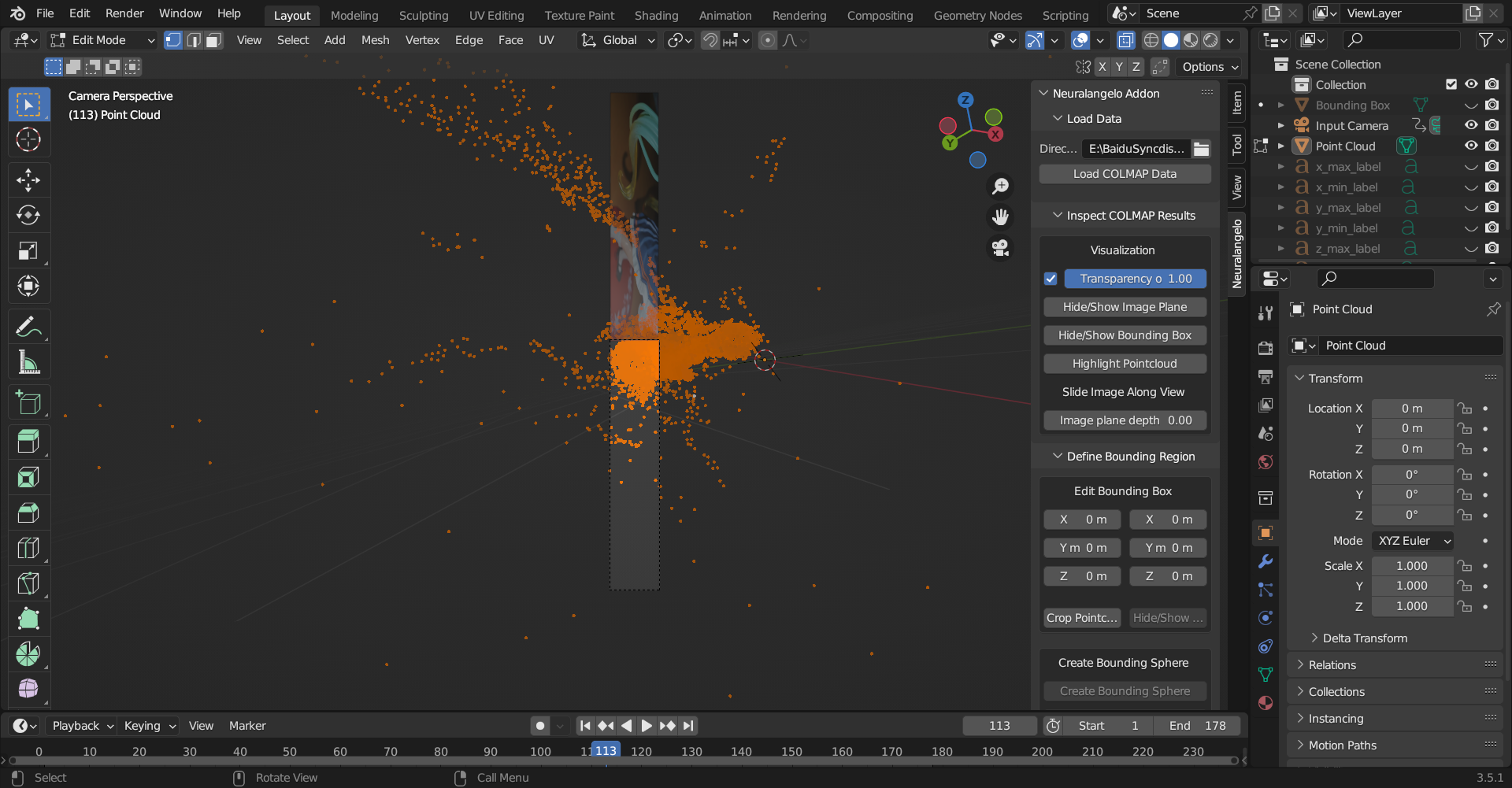
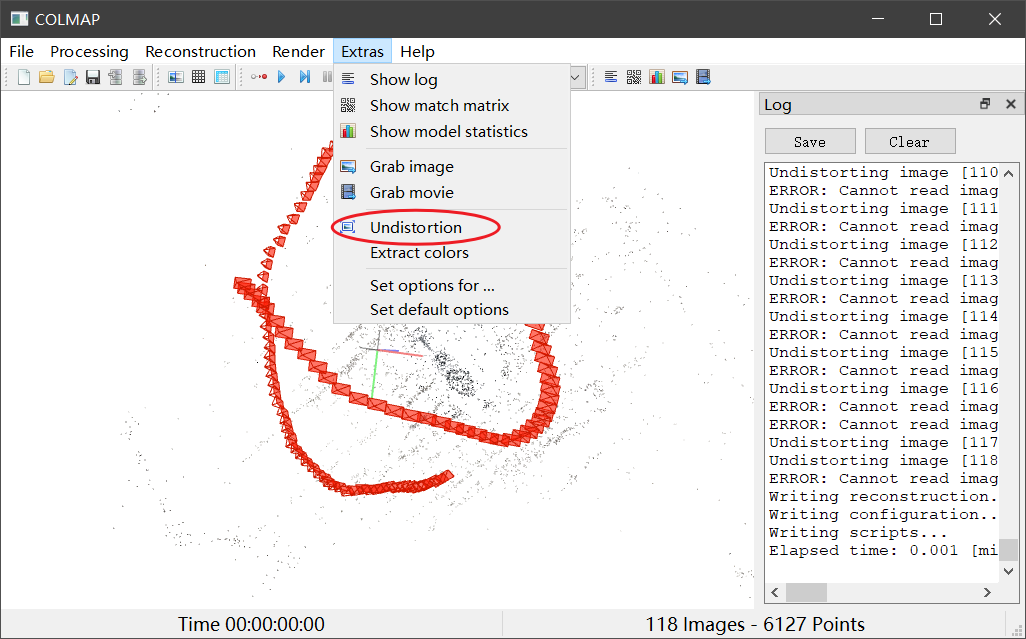
需要对 colmap 数据做(BA and) Undistortion
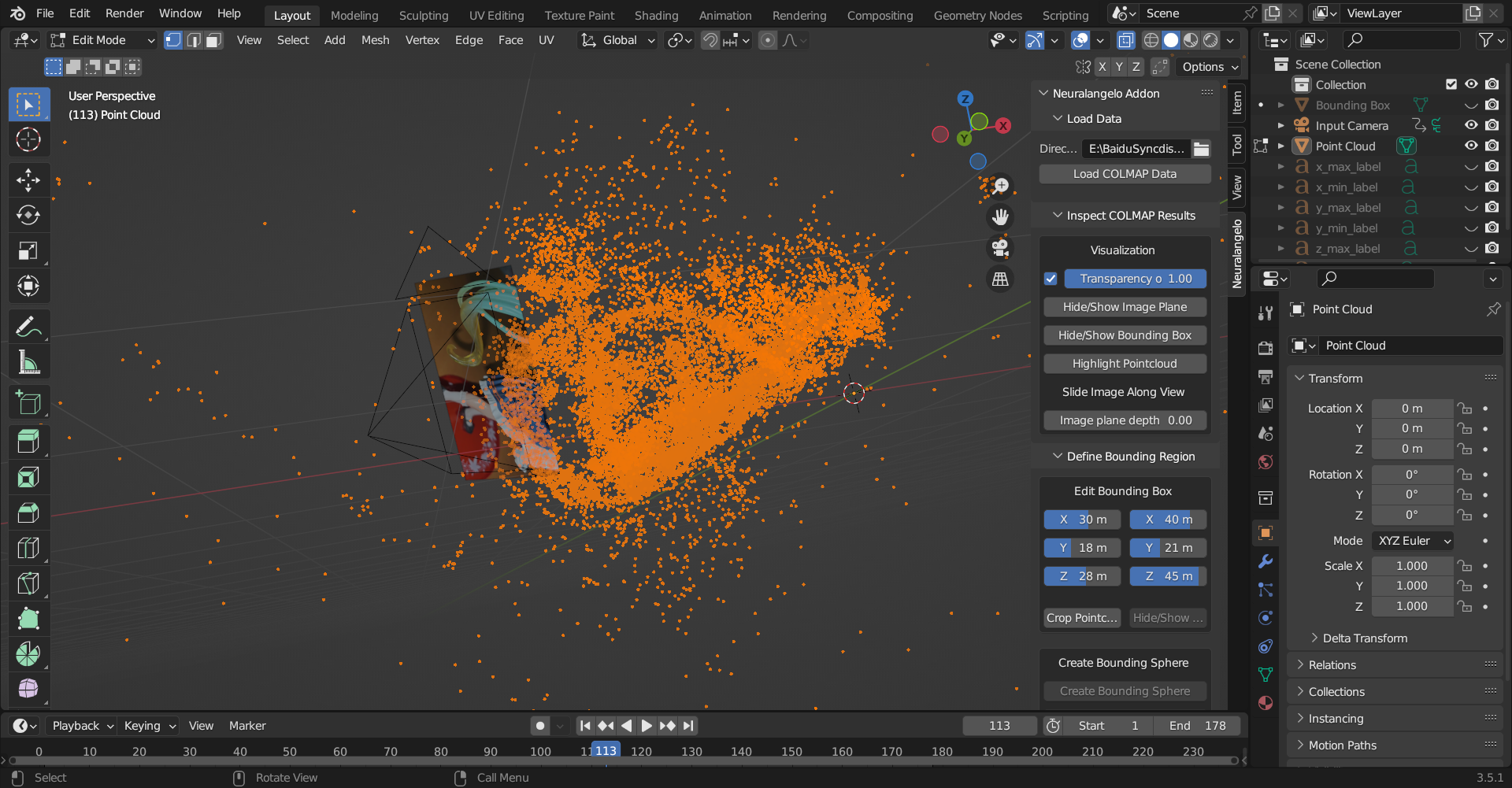
代码结构
confs 配置文件
1 | name: ${model.name}-${dataset.name}-${basename:${dataset.root_dir}} |
omegaconf获取 yaml 中参数
argparse获取终端输入的参数
1 | # ============ Register OmegaConf Recolvers ============= # |
1 | def get_args(): |
run.py 主程序
获取配置文件和终端输入
1 | # extras:其他config_parser中没有添加的arg |
global seed setting
1 | def seed_everything(seed): |
根据配置导入模块
- from models.neus import NeuSModel
- model = NeuSModel(config.model)
- from systems.neus import Trainer
- trainer = Trainer(model, config.trainer, args)
- from process_data.dtu import NeRFDataset
- train_dm = NeRFDataset(config.dataset,stage=’train’)
- train_loader = torch.utils.data.DataLoader(train_dm, batch_size=3, shuffle=True)
- val_dm = NeRFDataset(config.dataset,stage = ‘valid’)
- val_loader = torch.utils.data.DataLoader(val_dm, batch_size=1)
- test_dm = NeRFDataset(config.dataset,stage=’test’)
- test_loader = torch.utils.data.DataLoader(test_dm, batch_size=1)
- train_dm = NeRFDataset(config.dataset,stage=’train’)
运行:
- trainer.train(train_loader, val_loader)
- trainer.test(test_loader)
- trainer.mesh()
process_data
train
for data in train_loader:
data:
- pose: torch.Size([4, 4])
- direction: torch.Size([960, 544, 3])
- index: torch.Size([1])
- H: 960
- W: 544
- image: torch.Size([960, 544, 3])
- mask: torch.Size([960, 544])
1 | {'pose': tensor([[[-0.0898, 0.8295, -0.5512, 1.3804], |
other ref code
DTU 提取 mesh 后,通过 object masks 移除背景NeuralWarp/evaluation/mesh_filtering.py at main · fdarmon/NeuralWarp (github.com)
DTU 数据集的深度图数据可视化,
调整可视化时的v_min和v_maxMVS/utils/read_and_visualize_pfm.py at master · doubleZ0108/MVS (github.com)
Results
Excel Function
将 C5:23.98 22.79 25.21 26.03 28.32 29.80 27.45 28.89 26.03 28.93 32.47 30.78 29.37 34.23 33.95,按空格拆分填入 C3 到 Q3=TRIM(MID(SUBSTITUTE($C$5," ",REPT(" ",LEN($C$5))),(COLUMN()-COLUMN($C$3))*LEN($C$5)+1,LEN($C$5)))
Code BUG
- [x] tf-logs 在测试时会新加一个文件夹问题
- [x] 训练过程中出现的 loss 错误
1 | Error |
- [x] 导出 mesh 区域错误

- 可能是 mesh 网格的 ijk 区域大小设置有问题
- 或没有将 bound 进行坐标变换到训练时的世界坐标系
Add
Floaters No More
- OOM
1 | 0% 0/60 [00:00<?, ?it/s]Traceback (most recent call last): |
Update
Nerfacc
0.3.5 —> 0.5.3
error1:loss_eikonal 一直增大
- 在 fg 中添加了 def alpha_fn(t_starts,t_ends,ray_indices):
- 在 fg 中使用 ray_aabb_intersect 计算 near 和 far
效果差原因:
- 0.5.3 由于 Contraction 在射线遍历时低效,不再使用 ContractionType,因此对于背景 bg 使用 self.scene_aabb 会出现问题
解决 test:
- 对于背景的 unbounded 采用 prop 网格
error1.5:
- loss_rgb_mse 和 l1 损失为 nan
- 解决:背景 color 值为负数
error2: 对 unbounded 采用 prop 网格后,由于网络参数太多,出现 OOM
1 | OOM |
- max_split_size_mb 设置后,显存也不足
- 调小 prop 的网格参数,prop_network 主要由 Hash Table 和 MLP 两部分组成,调小 HashTable 的 n_levels