Python 调用API结构
Bilibili bilibili 提供的 api 接口(一串 json 字符) 我基于 python 写的几个使用 api 获取信息的例子
1. bilibili 用户基本信息(name,level,关注,粉丝)获取 https://api.bilibili.com/x/space/upstat?mid=UUID&jsonp=jsonp_up 信息,名字,等级,视频总播放量,文章总浏览数_https://api.bilibili.com/x/relation/stat?vmid=UUID&jsonp=jsonp_up 信息,关注数,黑名单,粉丝数_
简单的代码获取 up 信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 import jsonimport requestsmid = input ('输入要查询的up的uid:' ) url_space = 'https://api.bilibili.com/x/space/acc/info?mid=' + mid url_relation = 'https://api.bilibili.com/x/relation/stat?vmid=' +mid space = requests.get(url_space).content.decode() relation =requests.get(url_relation).content.decode() dict_space = json.loads(space) dict_rela = json.loads(relation) up_name = dict_space["data" ]["name" ] up_level = dict_space['data' ]['level' ] up_following_num = dict_rela['data' ]['following' ] up_follower_num = dict_rela['data' ]['follower' ] print (f'up名字是:{up_name} ' )print (f'up等级达到:{up_level} 级' )if int (up_level)>=5 : print ('----哇是个大佬!!!----' ) print (f'up关注了{up_following_num} 个人' )if int (up_following_num)>=700 : print ('----铁定是个dd!!!----' ) print (f'up有{up_follower_num} 个粉丝' )
示例:
1 2 3 4 5 6 输入要查询的up的uid:2 up名字是:碧诗 up等级达到:6 级 ----哇是个大佬!!!---- up关注了191 个人 up有804598 个粉丝
2. bilibili 统计某视频评论区,并生成词云
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 import jsonimport requestsfrom multiprocessing.dummy import Poolimport reimport osav = input ('请输入视频的av号:' ) p_total = input ('请输入评论要几页:' ) def get_urls (): urls = [] p = 1 while p <= int (p_total): url = 'http://api.bilibili.com/x/v2/reply?jsonp=jsonp&;pn=' + str (p) + '&type=1&oid=' + av urls.append(url) p += 1 return urls def get_name_con (url ): html = requests.get(url).content.decode() yh_names = re.findall(r'"uname":"(.*?)","sex":' ,html,re.S) yh_contents = re.findall(r'"message":"(.*?)","plat"' ,html,re.S) del yh_contents[0 ] yh_contents2 = [] for yh_content in yh_contents: yh_contents2.append(yh_content.replace('\\n' ,' ' )) return yh_names,yh_contents2 def get_names_cons (): pool = Pool(5 ) urls = get_urls() namecons = pool.map (get_name_con,urls) names = [] cons = [] for namecon in namecons: name = namecon[0 ] for n in name : names.append(n) con = namecon[1 ] for c in con: cons.append(c) return names,cons def save (): tumple = get_names_cons() namelst = tumple[0 ] conlst = tumple[1 ] if len (namelst) != len (conlst): tot = len (conlst) g = 0 main_path = 'E:\\learn\\py\\git\\spider\\spider_learn\\bilibili\\bilibili_api\\txt' if not os.path.exists(main_path): os.makedirs(main_path) dir1 = 'E:\\learn\\py\\git\\spider\\spider_learn\\bilibili\\bilibili_api\\txt\\' + 'comment' + '.txt' with open (dir1,'w' ,encoding='utf-8' ) as fb: for g in range (tot): fb.write(conlst[g]) g += 1 if __name__ == '__main__' : save() print ('----已完成----' ,end='\t' ) print (f'此视频已获得 {p_total} 页的评论' )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 from wordcloud import WordCloudimport PIL .Image as imageimport jiebadef trans_cn (text ): word_list = jieba.cut(text) result = ' ' .join(word_list) return result def wc (): dir1 = './txt/comment.txt' with open (dir1,encoding='utf-8' ) as f: text = f.read() text = trans_cn(text) WordCloud2 = WordCloud( font_path = 'C:\\windows\\Fonts\\simfang.ttf' ).generate(text) image_produce = WordCloud2.to_image() image_produce.show() WordCloud2.to_file('./txt/comment.png' ) wc()
3. 获取 bilibili 主页各个分区的视频封面和 av 号 https://www.bilibili.com/index/ding.json_首页 api,每刷新一次,信息就会改变一次_
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 import requestsimport reimport osimport jsonprint ('-douga-teleplay-kichiku-dance-bangumi-fashion-life-ad-guochuang-movie-music-technology-game-ent--' )fenqu = input ('请输入爬取分区:' ) if fenqu == '' : fenqu1 = 'shuma' else : fenqu1 = fenqu html = requests.get( 'https://www.bilibili.com/index/ding.json' ).content.decode() dict_html = json.loads(html) i = 0 aids = [] pics = [] for i in range (10 ): aid = dict_html[fenqu][str (i)]['aid' ] pic = dict_html[fenqu][str (i)]['pic' ] aids.append(aid) pics.append(pic) j = 1 h = j-1 for h in range (10 ): main_path = 'E:\\learn\\py\\git\\spider\\spider_learn\\bilibili\\bilibili_api\\pic\\' +fenqu1 if not os.path.exists(main_path): os.makedirs(main_path) try : piccc = requests.get(pics[h]) except requests.exceptions.ConnectionError: print ('图片无法下载' ) continue except requests.exceptions.ReadTimeout: print ('requests.exceptions.ReadTimeout' ) continue dir = 'E:\\learn\\py\\git\\spider\\spider_learn\\bilibili\\bilibili_api\\pic\\' + \ fenqu1 + '\\' +'av' + str (aids[h]) + '.jpg' with open (dir , 'wb' ) as f: print (f'正在爬取第{j} 张图' ) f.write(piccc.content) j += 1 h += 1 print ('----完成图片爬取----' )
_略微修改后_不管了反正这个爬虫也没什么用 hhh
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 import requestsimport reimport osimport jsondef get_pic (): if fenqu == '' : fenqu1 = 'shuma' else : fenqu1 = fenqu html = requests.get( 'https://www.bilibili.com/index/ding.json' ).content.decode() dict_html = json.loads(html) i = 0 aids = [] pics = [] for i in range (10 ): aid = dict_html[fenqu][str (i)]['aid' ] pic = dict_html[fenqu][str (i)]['pic' ] aids.append(aid) pics.append(pic) j = 1 h = j-1 for h in range (10 ): main_path = 'E:\\learn\\py\\git\\spider\\spider_learn\\bilibili\\bilibili_api\\pic\\' +fenqu1 if not os.path.exists(main_path): os.makedirs(main_path) try : piccc = requests.get(pics[h]) except requests.exceptions.ConnectionError: print ('图片无法下载' ) continue except requests.exceptions.ReadTimeout: print ('requests.exceptions.ReadTimeout' ) continue dir = 'E:\\learn\\py\\git\\spider\\spider_learn\\bilibili\\bilibili_api\\pic\\' + \ fenqu1 + '\\' +'av' + str (aids[h]) + '.jpg' with open (dir , 'wb' ) as f: print (f'正在爬取第{j} 张图' ) f.write(piccc.content) j += 1 h += 1 to = int (input ('请输入你要爬多少次---一次最多十张:' )) print ('-douga-teleplay-kichiku-dance-bangumi-fashion-life-ad-guochuang-movie-music-technology-game-ent--' )fenqu = input ('请输入爬取分区:' ) for i in range (to): get_pic() print (f'----完成第{i} 次图片爬取----' )
Github 源码链接
4. 主站上的实时人数 _所用 api 接口_https://api.bilibili.com/x/web-interface/online?&;jsonp=jsonp
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 import requestsimport jsonimport timedef print_num (): index = requests.get( 'https://api.bilibili.com/x/web-interface/online?&;jsonp=jsonp' ).content.decode() dict_index = json.loads(index) all_count = dict_index['data' ]['all_count' ] web_online = dict_index['data' ]['web_online' ] play_online = dict_index['data' ]['play_online' ] print (f'all_count:{all_count} ' ) print (f'web_online:{web_online} ' ) print (f'play_online:{play_online} ' ) for i in range (100 ): print (f'第{i+1 } 次计数' ) print_num() time.sleep(2 )
5. 用户的粉丝数 _只能获取一页,b 站最多是五页,多了就会有限制_
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 import requestsimport jsonimport csvimport osimport timeuid = input ('请输入查找的up主的uid:' ) url = 'https://api.bilibili.com/x/relation/followers?vmid=' + \ uid + '&ps=0&order=desc&jsonp=jsonp' html = requests.get(url).content.decode() dic_html = json.loads(html) index_order = dic_html['data' ]['list' ] mids, mtimes, unames, signs = [], [], [], [] for i in index_order: mid = i['mid' ] mids.append(mid) mtime = i['mtime' ] mmtime = time.asctime(time.localtime(mtime)) mtimes.append(mmtime) uname = i['uname' ] unames.append(uname) sign = i['sign' ] signs.append(sign) headers = ['uid' , '注册时间' , 'up姓名' , '个性签名' ] rows = [] j = 0 for j in range (len (mids)): rows.append([mids[j], mtimes[j], unames[j], signs[j]]) main_path = 'E:\\learn\\py\\git\\spider\\spider_learn\\bilibili\\bilibili_api\\csv' if not os.path.exists(main_path): os.makedirs(main_path) dir = 'E:\\learn\\py\\git\\spider\\spider_learn\\bilibili\\bilibili_api\\csv\\' + \ 'follers' + '.csv' with open (dir , 'w' , encoding='utf-8' ) as f: fb = csv.writer(f) fb.writerow(headers) fb.writerows(rows) print ('----最多只显示一页的粉丝数,也就是50个----' )print (f'共有{len (mids)} 个粉丝' )
LOL LOL提供了丰富的接口,可以利用这些接口来完成一些操作。使用Python来调用LOL提供的API,可以使用一些大佬造的轮子。
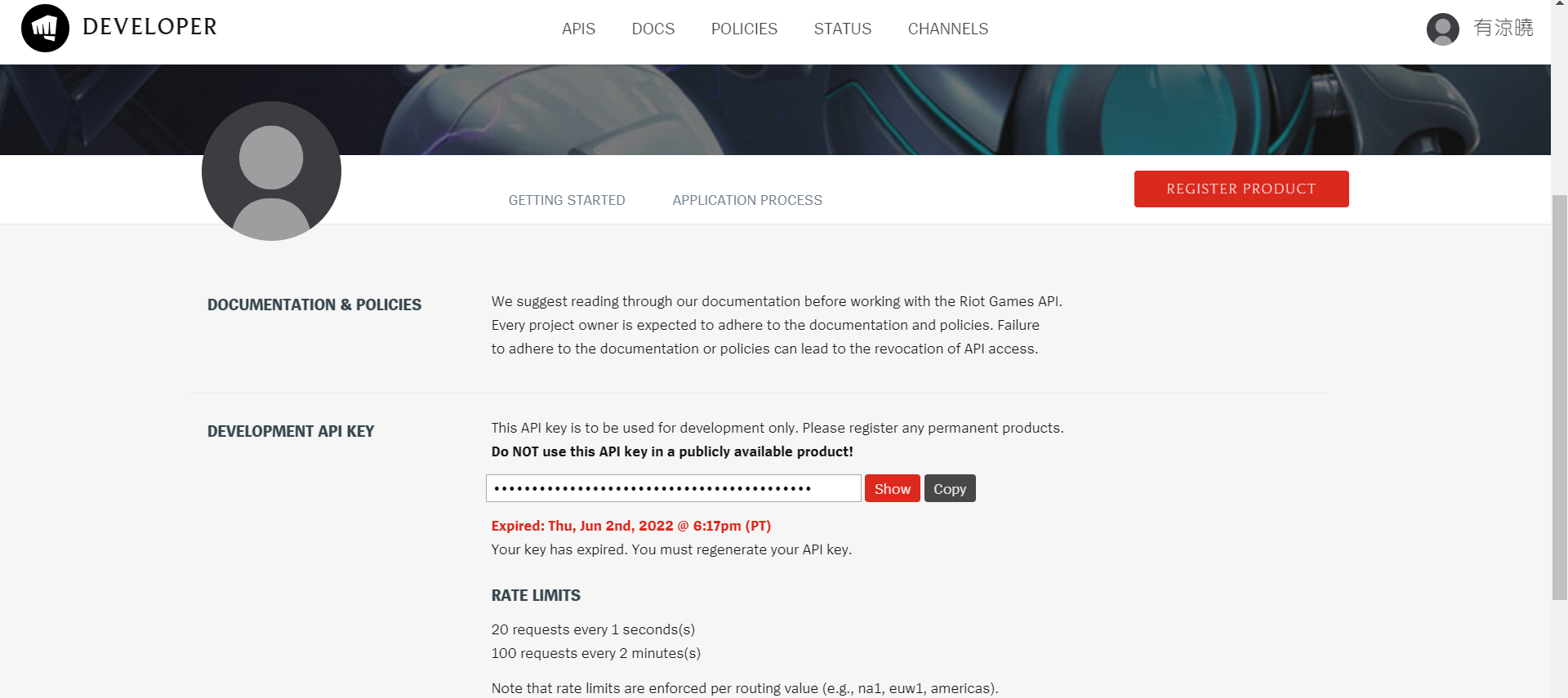
拳头提供的API接口说明可以在开发者网站 中查看,可以使用拳头账号获得一个api key来调用api,且key需要每天进行更换。
网站API
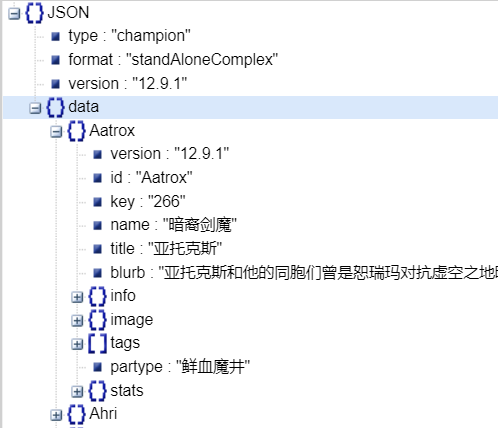
拳头的开发者网站文档:开发者网站doc 可以得到一些json数据,如当前版本全部英雄的信息,全部装备的信息等等
1.RiotWatcher RiotWatcher 参考知乎大佬京暮研Shinra 的教程 来进行初步学习
1.1 使用方式
安装pip install riotwatcher
使用
1 2 3 from riotwatcher import LolWatcherlol_watcher = LolWatcher('<your-api-key>' )
定义完成后,就可以使用lol_watcher来调用其他的类库
League of Legends Watcher Legends Of Runeterra Watcher
Riot Watcher
Team Fight Tactics Watcher
Valorant Watcher
Handlers
Testing
每个类下拥有很多个函数,调用不同的API
1.2 League of Legends Watcher champion:英雄
获得某个区服的免费英雄 champion
使用ChampionInfo = lol_watcher.champion.rotations(region: str)
1 2 3 4 5 6 7 region = ['kr' ,'jp1' ,'br1' ,'eun1' ,'euw1' ,'la1' ,'la2' ,'na1' ,'oc1' ,'tr1' ,'ru' ] lol_region = region[1 ] champion_kr = lol_watcher.champion.rotations(lol_region) print (champion_kr){'freeChampionIds' : [21 , 33 , 50 , 57 , 80 , 81 , 107 , 111 , 113 , 202 , 240 , 246 , 350 , 497 , 518 , 875 ], 'freeChampionIdsForNewPlayers' : [222 , 254 , 427 , 82 , 131 , 147 , 54 , 17 , 18 , 37 ], 'maxNewPlayerLevel' : 10 }
返回的ChampionInfo中
freeChampionIds 免费英雄的ID
freeChampionIdsForNewPlayers 给新手玩家的免费英雄
可以通过ID来查看英雄的名字,使用拳头官网的json文件
实现思路:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 import requestsimport pandas as pdchampion_json_url = "http://ddragon.leagueoflegends.com/cdn/12.9.1/data/zh_CN/champion.json" r1 = requests.get(champion_json_url) champ_data = r1.json()["data" ] champ_df = pd.json_normalize(champ_data.values(),sep='' ) champions_kr_free = champion_kr['freeChampionIds' ] champions_kr_free_str = [] for champion_kr_free in champions_kr_free: champion_kr_free_str = str (champion_kr_free) champions_kr_free_str.append(champion_kr_free_str) print (champ_df[champ_df['key' ].isin(champions_kr_free_str)][['name' ,'title' ]]) name title 28 探险家 伊泽瑞尔48 戏命师 烬61 暴怒骑士 克烈73 扭曲树精 茂凯75 赏金猎人 厄运小姐81 深海泰坦 诺提勒斯82 万花通灵 妮蔻89 不屈之枪 潘森92 元素女皇 奇亚娜94 幻翎 洛95 披甲龙龟 拉莫斯100 傲之追猎者 雷恩加尔105 北地之怒 瑟庄妮108 腕豪 瑟提118 诺克萨斯统领 斯维因151 魔法猫咪 悠米
问题
pandas在pycharm中使用时,在打印列表式,单元格内容会显示不全,采用如下方法来处理1 2 3 4 pd.set_option('display.max_columns' , None ) pd.set_option('display.max_rows' , None ) pd.set_option('display.expand_frame_repr' , False ) pd.set_option('display.max_colwidth' , 200 )
获得某个召唤师的英雄熟练度等信息 champion_mastery
有三种获取方法可以选择
Ⅰ.by_summoner 获得所有英雄的熟练度信息
使用:lol_watcher.champion_mastery.by_summoner(region,summoner_id)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 faker_champion_master = lol_watcher.champion_mastery.by_summoner(region,faker_id) print (faker_champion_master)[ { "championId" : 7 , "championLevel" : 7 , "championPoints" : 493741 , "lastPlayTime" : 1653499775000 , "championPointsSinceLastLevel" : 472141 , "championPointsUntilNextLevel" : 0 , "chestGranted" : true, "tokensEarned" : 0 , "summonerId" : "ht4SB4hyU2CyiERUxtIE6ZD4bQbG4Djo0Hbrl2hU0ilBxg" }, {},...{ } ]
返回数据包括
英雄id
英雄熟练度等级
英雄分数
最后使用时间
是否有战利品奖励(使用该英雄的对局中有人获得S-以上评分)
Ⅱ.by_summoner_by_champion 获得特定英雄的熟练度信息
使用:lol_watcher.champion_mastery.by_summoner_by_champion(region,summoner_id,champion_id)
1 2 3 4 5 faker_champion_master_7 = lol_watcher.champion_mastery.by_summoner_by_champion(region,faker_id,7 ) print (faker_champion_master_7){'championId' : 7 , 'championLevel' : 7 , 'championPoints' : 493741 , 'lastPlayTime' : 1653499775000 , 'championPointsSinceLastLevel' : 472141 , 'championPointsUntilNextLevel' : 0 , 'chestGranted' : True , 'tokensEarned' : 0 , 'summonerId' : 'ht4SB4hyU2CyiERUxtIE6ZD4bQbG4Djo0Hbrl2hU0ilBxg' }
Ⅲ.scores_by_summoner 获得玩家的总冠军精通分数,即每个冠军精通等级的总和
使用:lol_watcher.champion_mastery.scores_by_summoner(region,summoner_id)
1 2 3 4 5 faker_champion_master_scores = lol_watcher.champion_mastery.scores_by_summoner(region,faker_id) print (faker_champion_master_scores)675
查询一名召唤师的信息 summoner
可以通过四种方式查询
使用:summonerDTO = lol_watcher.summoner.by_xxxx(region,xxxx)
Ⅰ.by_account Ⅱ.by_id Ⅲ.by_name
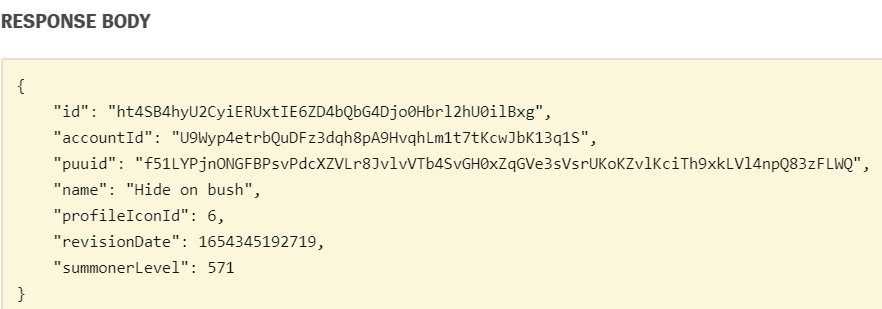
1 2 3 4 5 6 7 8 region = "kr" summoner_name = 'Hide on bush' summoner_faker = lol_watcher.summoner.by_name(region, summoner_name) print (summoner_faker){'id' : 'ht4SB4hyU2CyiERUxtIE6ZD4bQbG4Djo0Hbrl2hU0ilBxg' , 'accountId' : 'U9Wyp4etrbQuDFz3dqh8pA9HvqhLm1t7tKcwJbK13q1S' , 'puuid' : 'f51LYPjnONGFBPsvPdcXZVLr8JvlvVTb4SvGH0xZqGVe3sVsrUKoKZvlKciTh9xkLVl4npQ83zFLWQ' , 'name' : 'Hide on bush' , 'profileIconId' : 6 , 'revisionDate' : 1654345192719 , 'summonerLevel' : 571 }
Ⅳ.by_puuid 2.lcu-driver lcu-driver