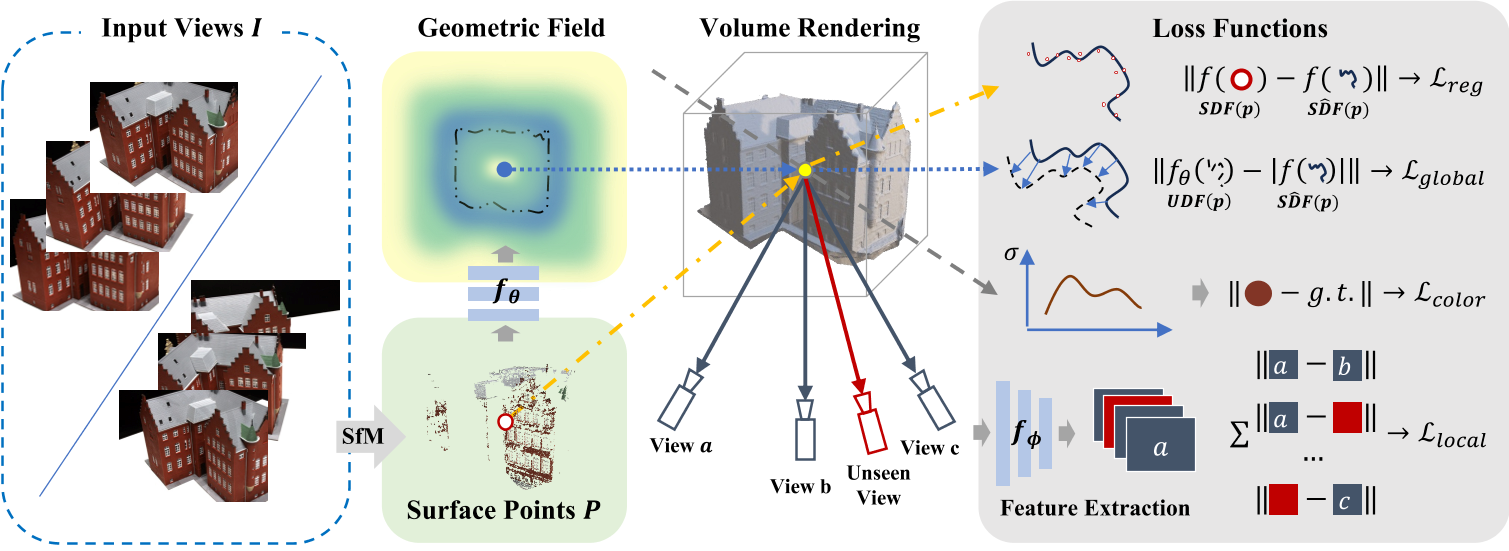
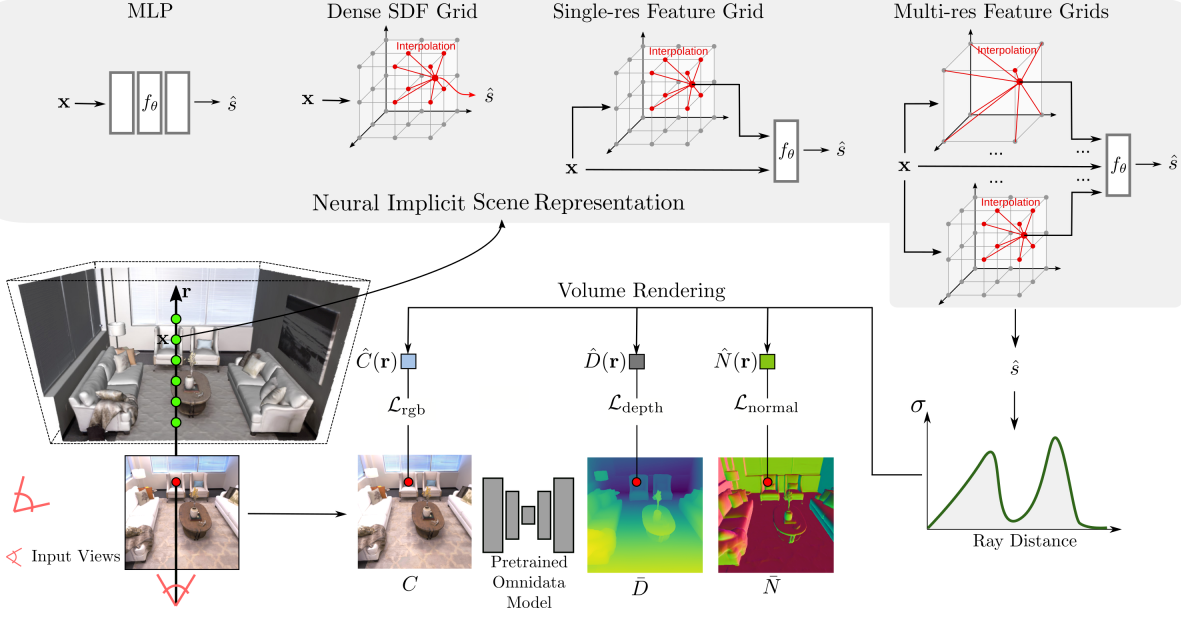
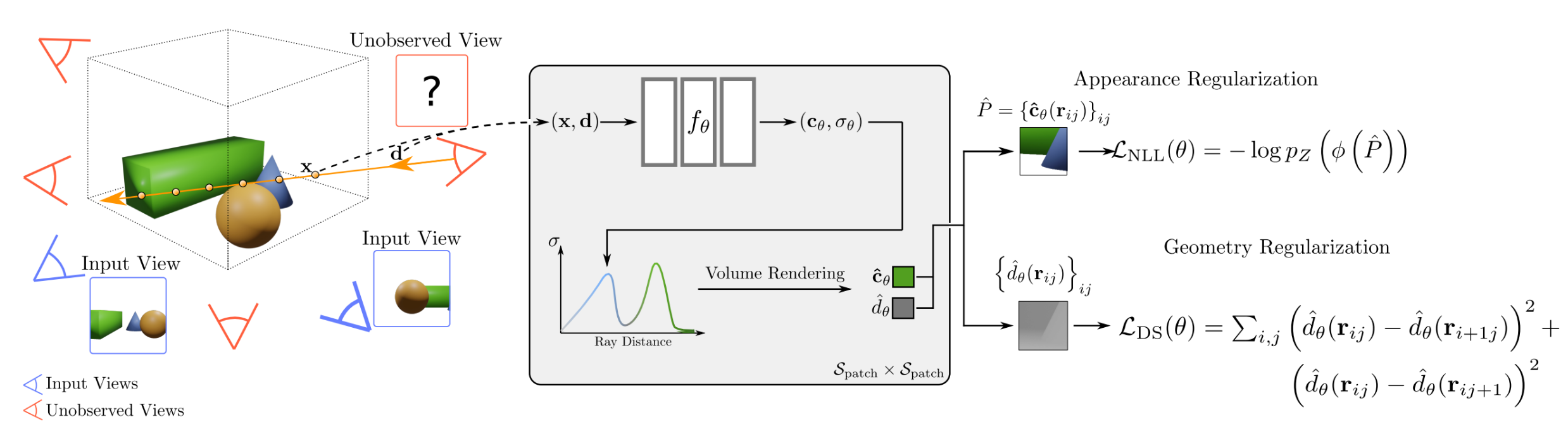
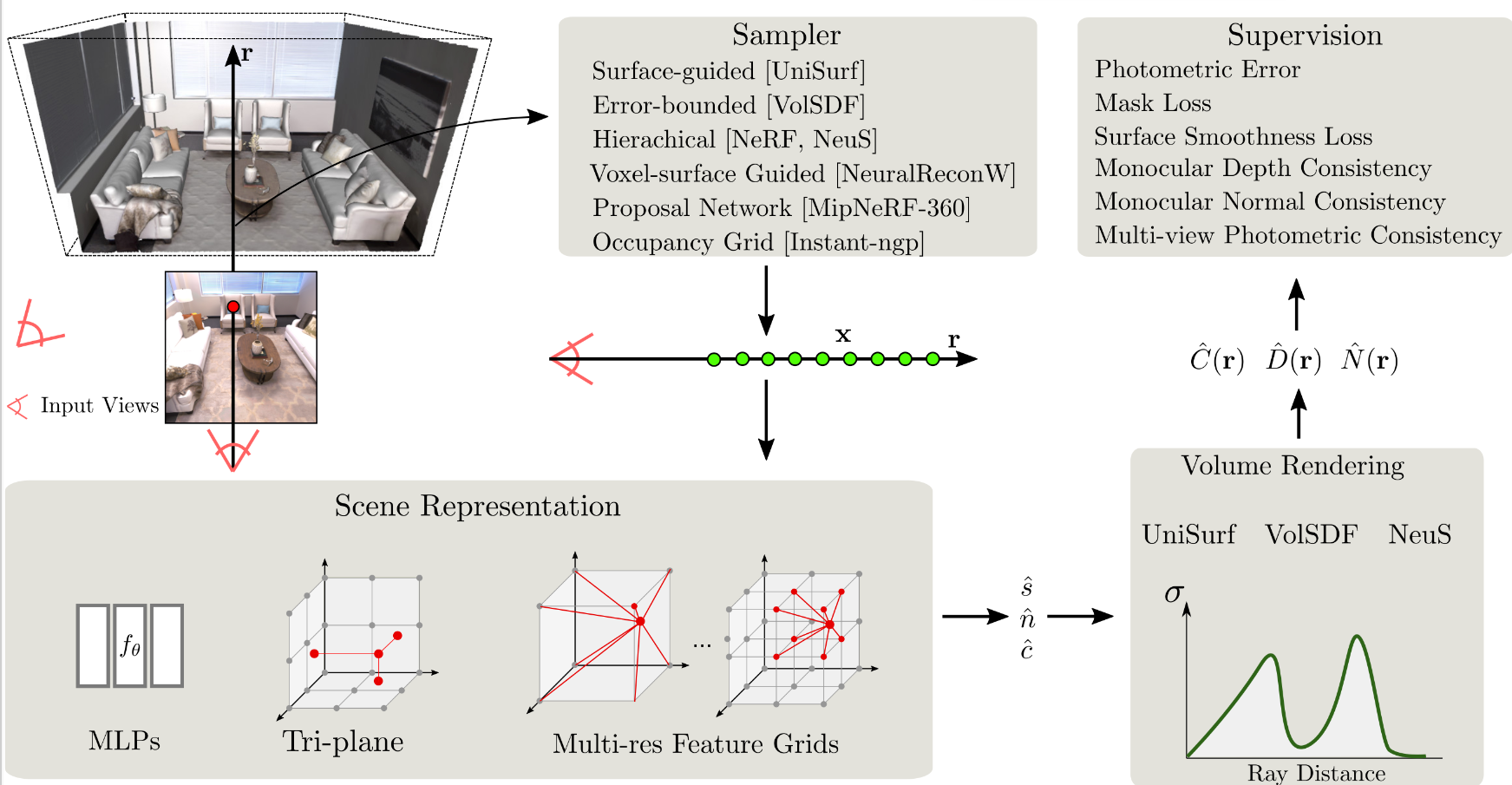
| Title | NeuSurf: On-Surface Priors for Neural Surface Reconstruction from Sparse Input Views |
|---|---|
| Author | Han Huang1,2, Yulun Wu1,2, Junsheng Zhou1,2, Ge Gao1,2*, Ming Gu1,2, Yu-Shen Liu2 |
| Conf/Jour | arXiv |
| Year | 2023 |
| Project | |
| Paper | NeuSurf: On-Surface Priors for Neural Surface Reconstruction from Sparse Input Views (readpaper.com) |