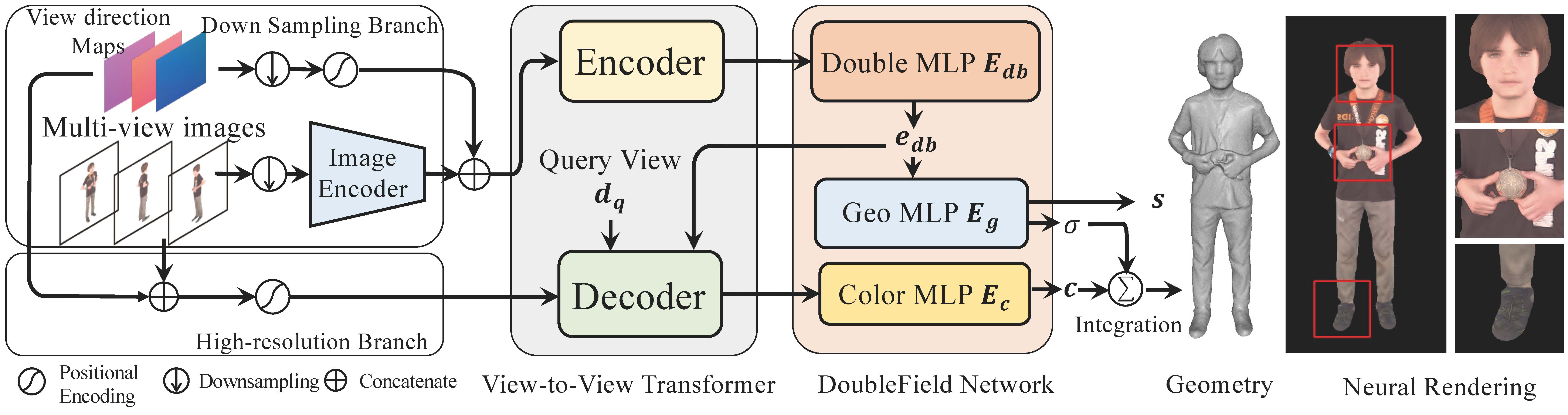
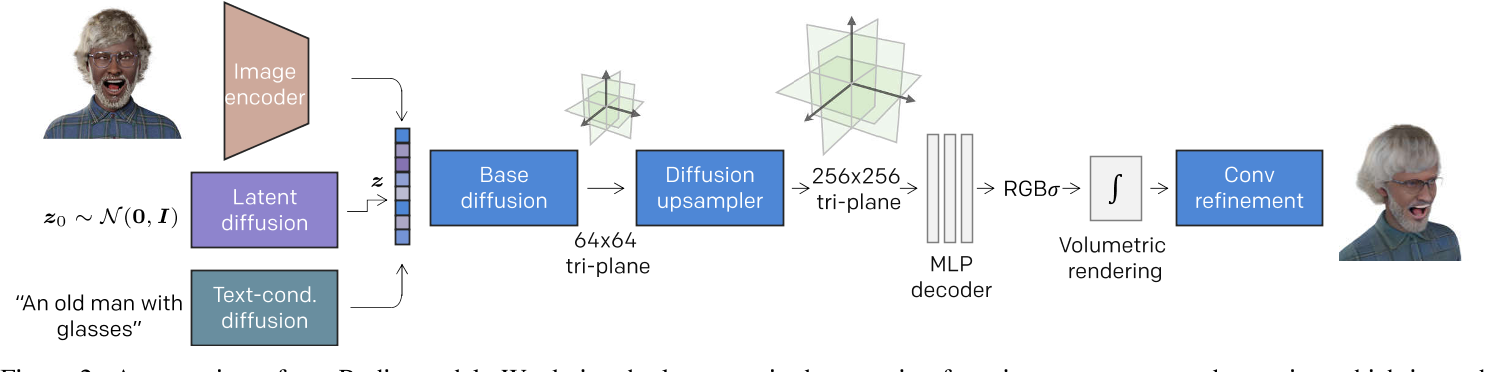
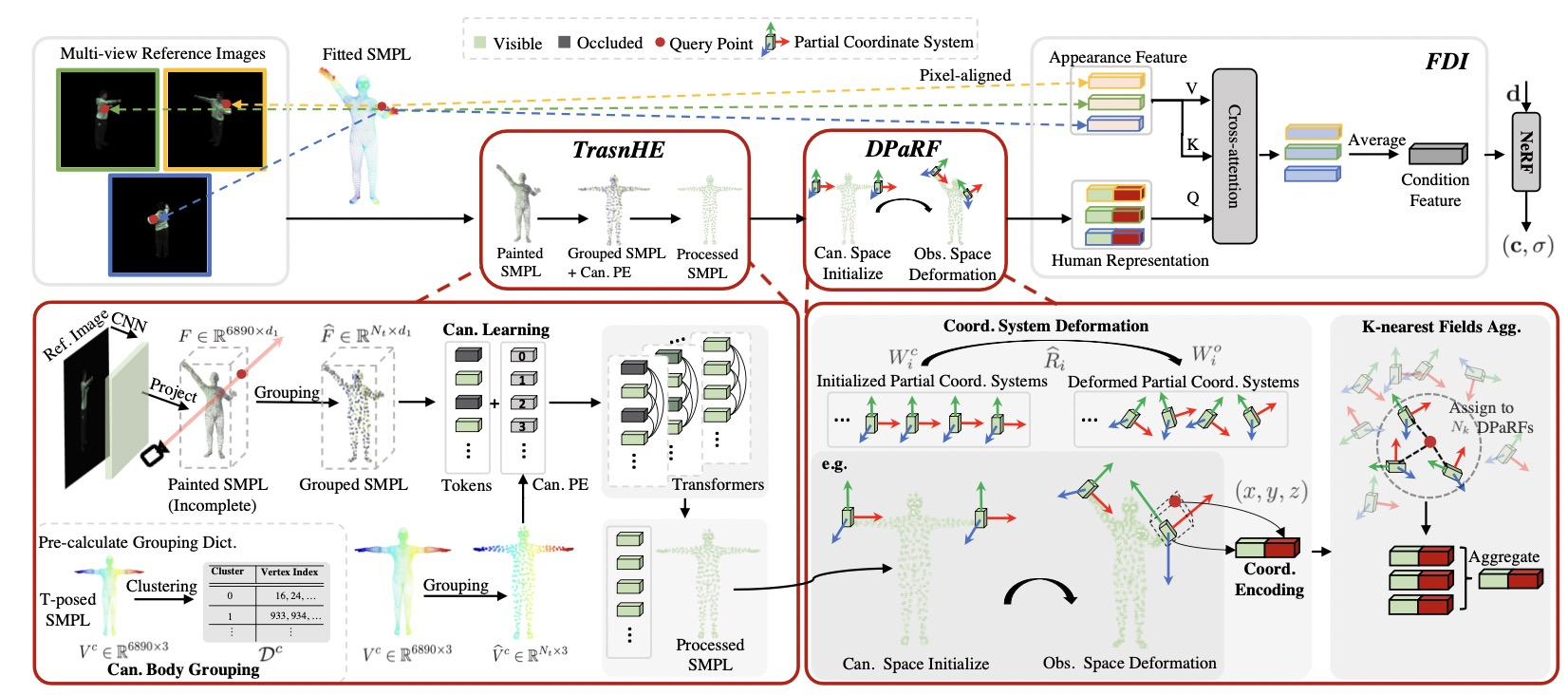
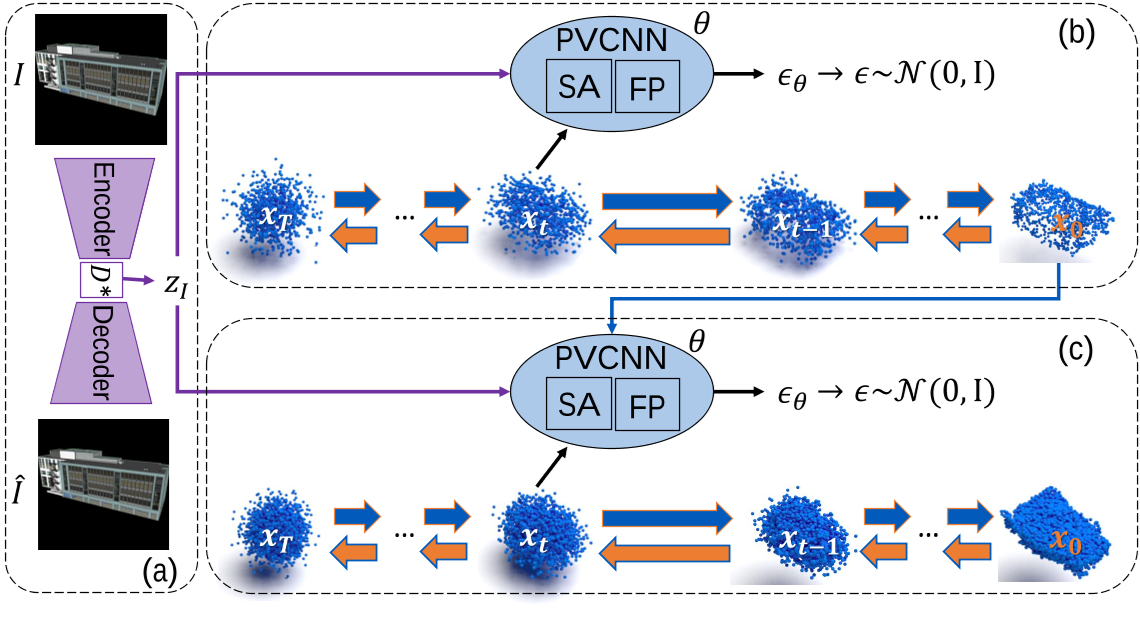
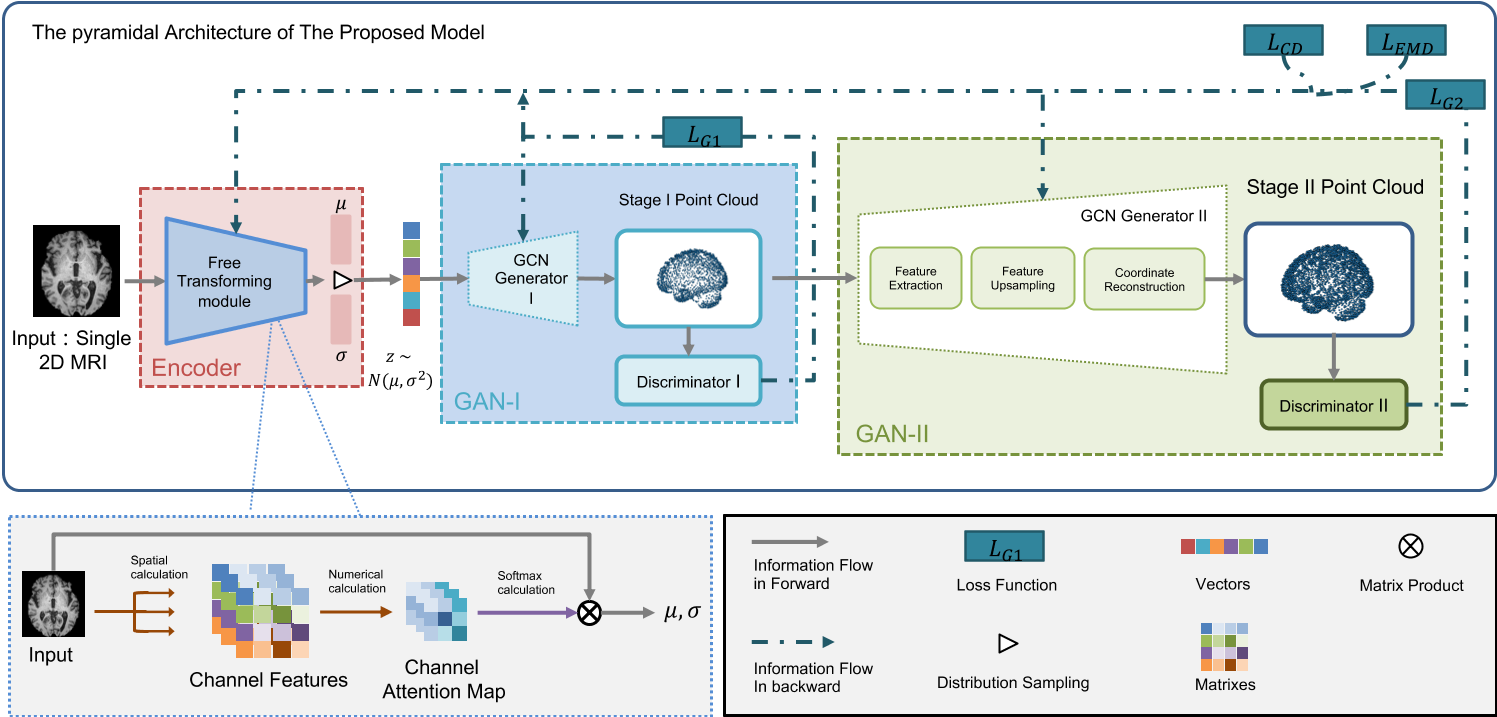
| Title | DoubleField: Bridging the Neural Surface and Radiance Fields for High-fidelity Human Rendering |
|---|---|
| Author | Ruizhi Shao1, Hongwen Zhang1, He Zhang2, Yanpei Cao3, Tao Yu1, and Yebin Liu1 |
| Conf/Jour | CVPR |
| Year | 2022 |
| Project | DoubleField Project Page (liuyebin.com) |
| Paper | DoubleField: Bridging the Neural Surface and Radiance Fields for High-fidelity Human Rendering. (readpaper.com) |